TensorFlow Slim 工具包使用
TensorFlow Slim是Google提供的图像分类工具包,不仅提供一些方便接口,包含使用tf_slim训练和评估几个广泛使用于图像识别的卷积神经网络 (CNN) 图像分类模型的代码 ,还包含允许您从头开始训练模型或根据预先训练的网络权重对其进行微调的脚本,是一个简洁、方便的图像分类模型库。
环境:python3.7 TensorFlow-1.15.0rc0 TensorFlow Models-v1.13.0
目录
一、安装配置TensorFlow Slim
1、下载TensorFlow源代码和TensorFlow_Models源代码文件
2、配置环境
二、slim文件夹解读
三、使用TensorFlow Slim微调模型
1.微调模型的原理
2、准备数据集
3、数据集转化成tfrecord格式
4、下载预训练模型
5、训练模型
6、验证模型准确率
7、导出模型
8、使用导出来的模型进行识别图像
一、安装配置TensorFlow Slim
1、下载TensorFlow源代码和TensorFlow_Models源代码文件
tensorflow/tensorflow: An Open Source Machine Learning Framework for Everyone (github.com)
tensorflow/models: Models and examples built with TensorFlow (github.com)
这里不建议安装TensorFlow2.x版本
TensorFlow2.x版本没有contrib库,也就无法使用tf_slim库
2、配置环境
Slim源代码在models\research\slim文件夹中
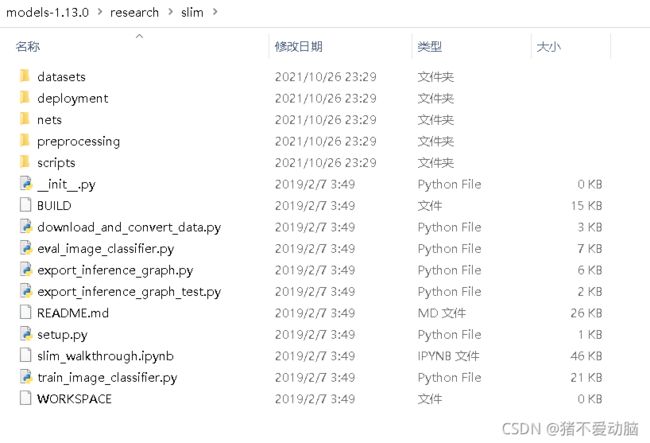
在该目录下打开cmd,输入
python setup.py build
python setup.py install
![]()

没有报错,就是配置成功了
二、slim文件夹解读
datasets:定义了一些训练时使用的数据集,并预设了一些常用数据集,定义自己数据集时,也必须在datasets文件夹中进行定义
net:定义了一些常用的图像识别网络结构
preprocessing:针对不同网络结构,定义了对图像进行预处理方法
scripts:包含了一些训练的案例脚本
deployment:部署,通过创建clone方式实现跨机器的分布训练,可以在多CPU和多GPU上实现运算的同步或者异步。
train_image_classifier.py:训练模型的入口代码
eval_image_classifier.py:验证模型性能的入口代码
download_and_convert_data.py:下载并传换数据集格式的入口代码
export_inference_graph.py:导出网络结构的入口代码
setup.py:slim运行所需环境配置的入口代码
slim_walkthrough.ipynb:tf_slim演示代码,可在jupyter-notebook上打开
README.md:slim使用说明文件
BUILD:用于建立包含用于加载、训练和评估基于TF Slim的模型的文件
WORKSPACE:用于建立运行slim的依赖项
使用之前建议先看下README.md和slim_walkthrough.ipynb文件
三、使用TensorFlow Slim微调模型
1.微调模型的原理
属于迁移学习的一种技术,采用预训练模型应用到自己的数据集上,无需再修改其网络结构,对模型输出层进行修改,并随机初始化该层的模型参数。
2、准备数据集
这里采用Garbage Classification (12 classes) | Kaggle
这个垃圾分类数据集提供了12个类别
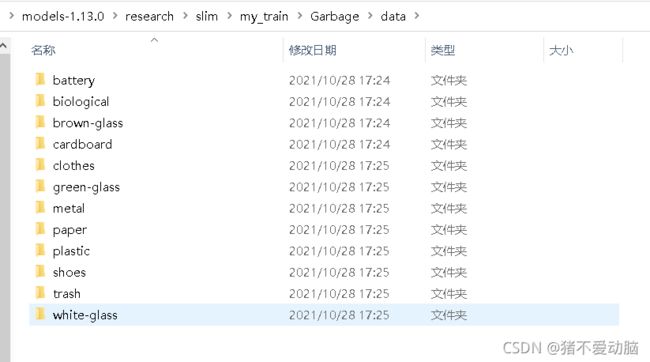
建立自己的训练文件夹,放入下载好的数据集,这里在slim目录下,建立my_train/Garbage/data:
3、数据集转化成tfrecord格式
进入到slim/datasets文件夹下
新建garbage.py,将flower.py内容复制进去,修改以下部分
_FILE_PATTERN = 'flowers_%s_*.tfrecord' #flowers改为garbage
SPLITS_TO_SIZES = {'train': 3320, 'validation': 350}
_NUM_CLASSES = 5 #5改为12打开dataset_factory.py,修改以下部分
新建download_and_convert_garbage.py 将download_and_convert_flowers.py内容复制过去,修改以下部分
# The number of images in the validation set.
_NUM_VALIDATION = 350 #分割验证集数据量,这里我改为3100
def _get_filenames_and_classes(dataset_dir):
"""Returns a list of filenames and inferred class names.
Args:
dataset_dir: A directory containing a set of subdirectories representing
class names. Each subdirectory should contain PNG or JPG encoded images.
Returns:
A list of image file paths, relative to `dataset_dir` and the list of
subdirectories, representing class names.
"""
flower_root = os.path.join(dataset_dir, 'flower_photos') #这里因为我的数据集照片在data目录下,所以这里的flower_photos改为data
directories = []
class_names = []
for filename in os.listdir(flower_root):
path = os.path.join(flower_root, filename)
if os.path.isdir(path):
directories.append(path)
class_names.append(filename)
def _get_dataset_filename(dataset_dir, split_name, shard_id):
output_filename = 'flowers_%s_%05d-of-%05d.tfrecord' % (
split_name, shard_id, _NUM_SHARDS) #这里的flowers改为garbage
return os.path.join(dataset_dir, output_filename)
dataset_utils.download_and_uncompress_tarball(_DATA_URL, dataset_dir) #不用下载,这一行注释掉,
_clean_up_temporary_files(dataset_dir) #注释掉这一行,否则会清理掉数据集最后在slim目录下打开download_and_convert_data.py
#在前面加入
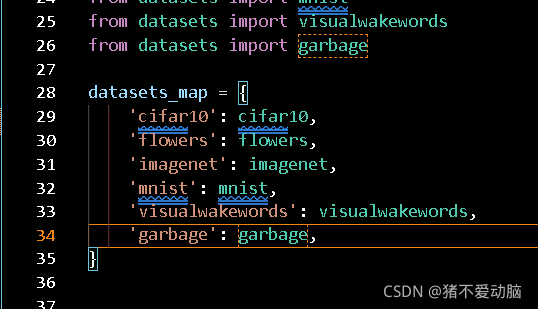
from datasets import download_and_convert_garbage
elif FLAGS.dataset_name == 'cifar10':
download_and_convert_cifar10.run(FLAGS.dataset_dir)
elif FLAGS.dataset_name == 'mnist':
download_and_convert_mnist.run(FLAGS.dataset_dir)
#加入以下两行
elif FLAGS.dataset_name == 'garbage':
download_and_convert_garbage.run(FLAGS.dataset_dir)
在slim目录下打开cmd ,输入python download_and_convert_data.py --dataset_name=garbage --dataset_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\
具体参数可以进入download_and_convert_data.py查看
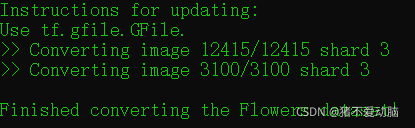 12415是我的训练集,3100是验证集
12415是我的训练集,3100是验证集
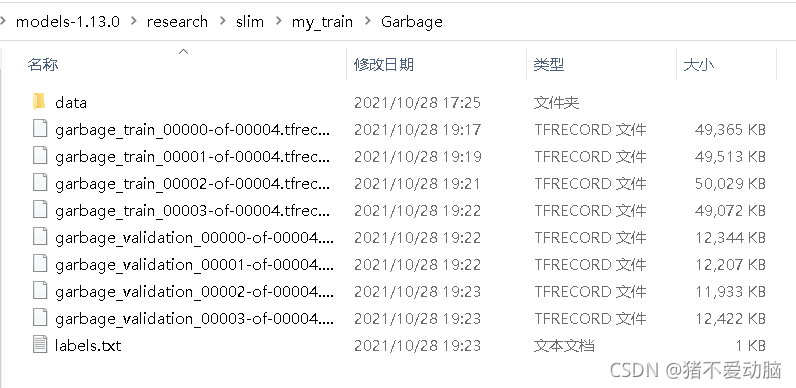
在Garbage目录下可以看到生成的tfrecord格式文件和labels.txt,可以进入labels.txt看看有没有正确生成
4、下载预训练模型
在README.md里面可以看到
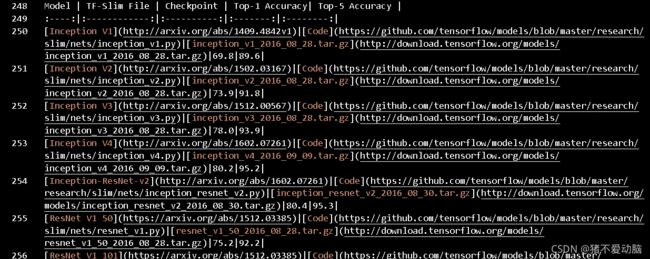
这里使用到Inception V3所以到以下地址进行下载
http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
训练会用到压缩包里的inception_v3.ckpt
5、训练模型
在Garbage目录下,新建文件夹train_dir:待会儿放置训练过程中的文件,eval_dir:放置验证模型的文件,datasets:将之前生成的tfrecord格式文件放进去
回到slim目录下,打开cmd
输入python train_image_classifier.py --train_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\train_dir --dataset_name=garbage --dataset_split_name=train --dataset_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\datasets --model_name=inception_v3 --checkpoint_path=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\inception_v3_2016_08_28\inception_v3.ckpt --checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits --trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits --max_number_of_steps=3000 --batch_size=32 --learning_rate=0.005 --learning_rate_decay_type=fixed --save_interval_secs=300 --save_summaries_secs=3 --log_every_n_steps=10 --optimizer=rmsprop --weight_decay=0.00004
--train_dir:保存训练日志
--dataset_name、--dataset_split_name:指定训练集--dataset_dir:指定训练数据集保存位置
--model_name:使用模型名称 --checkpoint_path:预训练模型保存位置
--checkpoint_exclude_scopes:恢复预训练模型时,指定不恢复的层(可以在net文件夹中对应网络查看)
--trainable_scopes:指定模型中微调的层,不设定就是对所有层训练
--max_number_of_steps:最大训练次数 --batch_size:每步使用的batch数量
--learning_rate:学习率 --learning_rate_decay_type:学习率是否自动下降,此处使用固定的学习率
--save_interval_secs:设定每次间隔保存当前模型的时间
--save_summaries_secs:设定每次写入日志的间隔时间(可以用TensorBoard打开)
--log_every_n_steps:设定间隔步数在屏幕上显示
--optimizer:指定优化器 --weight_decay:设定模型中所有参数的二次正则化超参数
具体参数解释进入 train_image_classifier.py中查看

如果报以上错误:tensorflow.python.framework.errors_impl.InvalidArgumentError:说明输入参数有误,这里是使用CPU训练,这里还提示了was explicitly assigned to /device:GPU:0 but available devices are [ /job:localhost/replica:0/task:0/device:CPU:0 ]
所以进入到train_image_classifier.py查看
tf.app.flags.DEFINE_boolean('clone_on_cpu', False,
'Use CPUs to deploy clones.') #因为我是用CPU训练,这里的False改为True再次运行,出现以下状况,说明开始正常训练,等就完事。
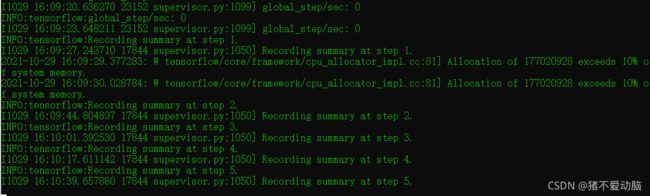
训练结束

6、验证模型准确率
在slim目录下打开cmd,输入:python eval_image_classifier.py --checkpoint_path=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\train_dir --eval_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\eval_dir --dataset_name=garbage --dataset_split_name=validation --dataset_dir=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\datasets --model_name=inception_v3
具体参数解释进入 eval_image_classifier.py中查看
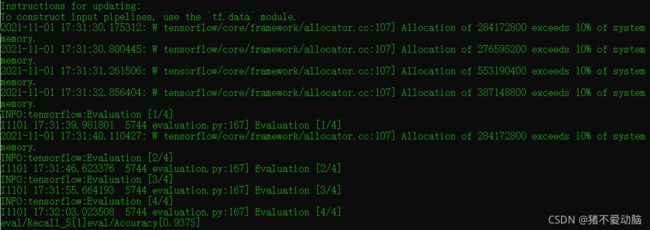
Recall_5表示Top 5的准确率,也就是分类前五个就算是对的,Accuray表示模型的分类准确率
7、导出模型
导出网络模型结构:
在slim目录下打开cmd,输入:python export_inference_graph.py --alsologtostderr --model_name=inception_v3 --output_file=C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\inception_v3_inf_graph.pb --dataset_name=garbage
运行结束后,会在slim\my_train\Garbage目录下生成inception_v3_inf_graph.pb
保存模型参数:
这里使用到freeze_graph.py,这个文件在下载好的TensorFlow源代码tensorflow\python\tools目录下,在其目录下打开cmd,输入:python freeze_graph.py --input_graph C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\inception_v3_inf_graph.pb --input_checkpoint C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\train_dir\model.ckpt-3000 --input_binary true --output_node_names InceptionV3/Predictions/Reshape_1 --output_graph C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\frozen_graph.pb
--input_checkpoint:指定将哪个checkpoint参数载入网络结构中,这里建议指定训练文件下checkpoint最大的步数
--output_graph:在导出的模型中,指定一个输出结点
具体参数解释进入 freeze_graph.py中查看
运行结束后,会在slim\my_train\Garbage目录下生成frozen_graph.pb
8、使用导出来的模型进行识别图像
这里如果支持C++编译的话,可以采用README.md里的方法
这里提供了何之源大神的代码:
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os.path
import re
import sys
import tarfile
import numpy as np
from six.moves import urllib
import tensorflow as tf
FLAGS = None
class NodeLookup(object):
def __init__(self, label_lookup_path=None):
self.node_lookup = self.load(label_lookup_path)
def load(self, label_lookup_path):
node_id_to_name = {}
with open(label_lookup_path) as f:
for index, line in enumerate(f):
node_id_to_name[index] = line.strip()
return node_id_to_name
def id_to_string(self, node_id):
if node_id not in self.node_lookup:
return ''
return self.node_lookup[node_id]
def create_graph():
"""Creates a graph from saved GraphDef file and returns a saver."""
# Creates graph from saved graph_def.pb.
with tf.gfile.FastGFile(FLAGS.model_path, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')
def preprocess_for_eval(image, height, width,
central_fraction=0.875, scope=None):
with tf.name_scope(scope, 'eval_image', [image, height, width]):
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Crop the central region of the image with an area containing 87.5% of
# the original image.
if central_fraction:
image = tf.image.central_crop(image, central_fraction=central_fraction)
if height and width:
# Resize the image to the specified height and width.
image = tf.expand_dims(image, 0)
image = tf.image.resize_bilinear(image, [height, width],
align_corners=False)
image = tf.squeeze(image, [0])
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
return image
def run_inference_on_image(image):
"""Runs inference on an image.
Args:
image: Image file name.
Returns:
Nothing
"""
with tf.Graph().as_default():
image_data = tf.gfile.FastGFile(image, 'rb').read()
image_data = tf.image.decode_jpeg(image_data)
image_data = preprocess_for_eval(image_data, 299, 299)
image_data = tf.expand_dims(image_data, 0)
with tf.Session() as sess:
image_data = sess.run(image_data)
# Creates graph from saved GraphDef.
create_graph()
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('InceptionV3/Logits/SpatialSqueeze:0')
predictions = sess.run(softmax_tensor,
{'input:0': image_data})
predictions = np.squeeze(predictions)
# Creates node ID --> English string lookup.
node_lookup = NodeLookup(FLAGS.label_path)
top_k = predictions.argsort()[-FLAGS.num_top_predictions:][::-1]
for node_id in top_k:
human_string = node_lookup.id_to_string(node_id)
score = predictions[node_id]
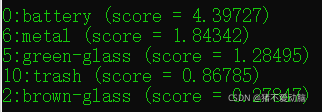
print('%s (score = %.5f)' % (human_string, score))
def main(_):
image = FLAGS.image_file
run_inference_on_image(image)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--model_path',
type=str,
)
parser.add_argument(
'--label_path',
type=str,
)
parser.add_argument(
'--image_file',
type=str,
default='battery1.jpg',
help='Absolute path to image file.'
)
parser.add_argument(
'--num_top_predictions',
type=int,
default=5,
help='Display this many predictions.'
)
FLAGS, unparsed = parser.parse_known_args()
tf.compat.v1.app.run(main=main, argv=[sys.argv[0]] + unparsed)
新建一个classify_image_inception_v3.py文件,copy以上代码进去,在该文件目录下打开cmd,输入:python classify_image_inception_v3.py --model_path C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\frozen_graph.pb --label_path C:\Users\User\Desktop\models-1.13.0\research\slim\my_train\Garbage\labels.txt --image_file test.jpg