鸟哥的Linux私房菜基础学习篇 第7章的重点探索
目录
- 前言
- 一、文件系统初识
-
- 1.文件系统特性
- 2.ext2文件系统
-
- (1).基本概念
- (2).使用dumpe2fs查询(ext系列适用)
- 3.与目录树的关系
- 4.文件系统的运行
-
- (1).新增文件的常规操作
- (2).数据的不一致(inconsistent)状态与日志式文件系统
- (3).异步处理
- (4).Linux支持的文件系统与VFS
- 5.XFS文件系统
- 二、实践操作
-
- 1.文件系统的简单操作
-
- (1)df
- (2)du
- (3)ln
- 2.高级操作
-
- (1)lsblk与blkid
- (2)gdisk/fdisk
- (3)mkfs.xfs/ext4与mkfs
- (4)xfs_repair与fsck.ext4
- (5)mount与umount(见下篇)
- 总结
前言
终于进入到Linux的文件系统啦,掌握好文件系统是成为一个合格的系统管理员的前提。合理管理自己磁盘的第一步,从本章正式开始探索。
一、文件系统初识
1.文件系统特性
1.磁盘组成与分区复习:仿佛学习磁盘的组成,已经过了许久,不要忘记它的圆形碟片(记录数据)、机械手臂与磁头(擦写数据)、主轴马达(转动碟片),还有扇区(有512B和4KB两种)、柱面、MBR与GPT这两种分区格式的概念。
2.为何格式化:磁盘分区之后操作这个是因为每种操作系统所设置的文件属性/权限并不相同,为了存放这些文件所需的数据,因此需要将分区格式化成为操作系统能够利用的文件系统格式(filesystem)
3.格式化的进步:传统的磁盘与文件系统应用中,一个分区就只能被格式化成为一个文件系统,现在我们常听到的LVM与软件磁盘阵列(software raid),这些技术可以将一个分区格式u哈成多个文件系统,也能将多个分区合成一个文件系统,目前我们在格式化时已经不再说成针对硬盘分区了,我们成一个可被挂载的数据为一个文件系统而非一个分区。
4.文件系统的运行:权限与属性放置到inode中(一个文件一个inode,inode还记录文件数据所在区块号码),实际数据放置到数据区块中(文件大占的区块就多),还有一个超级区块会记录整个文件系统的整体信息,包括inode与数据区块的总量、使用量、剩余量,以及文件系统的格式与相关信息等。
5.文件系统类型差异:4中描写的是索引式文件系统(indexed allocation),像ext2便是,我们还常用的有FAT文件系统,U盘常用,这种格式的文件系统没有inode,因此没办法将这个文件的所有区块在一开始就读出来,它要一个一个读,读了上一个才知道下一个区块在何处。
6.碎片整理:需要它的原因是文件写入的区块太过于离散,此使文件读取的性能会变得很差,可以借此将同一个文件所属的区块集合起来,这样使数据更易读。ext2其实基本不需要碎片整理,但如果文件系统使用太久,数据太过离散,可能也会需要。

2.ext2文件系统
(1).基本概念
1.区块群组(block group):因为文件系统一开始就将inode与数据区块规划好了,若是将所有的inode与数据区块放置一起,它们数量庞大,不容易管理,所以实际中ext2格式化时会分出多个区块群组,每个区块有独立的inode、数据区块、超级区块。
2.文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装启动引导程序,如此一来在这里安装启动引导程序便不必覆盖整块磁盘唯一的MBR,多重引导的环境才成为可能。
3.数据区块(data block):用于存放文件数据,ext2文件系统中有1K、2K、4K三种,在格式化时大小就固定了,之后除非重新格式化否则其大小和数量都是固定的,且每个区块都有编号,区块大小会对最大单一文件和最大文件系统总容量有限制(某些应用程序依然使用旧的限制,不支持大于2GB以上的单一文件容量,这时好像只能更换软件了)。每个区块内最多只能放一个文件的数据,小文件会浪费区块,大文件会多占几个区块。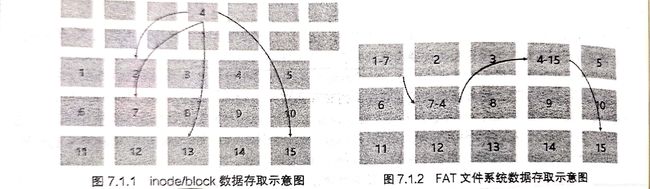
4.所谓区块大小:如果区块太小,大型文件会占非常多的区块,inode就要记录更多的号码,此时文件系统读写性能不佳,如果区块太大,多个小文件又会浪费多个区块的容量。进行文件系统格式化之前,先想好该文件系统预计使用的情况。当然现在磁盘容量大,大家可能都选4K的区块大小了。
5.inode table(inode table):记录文件的读写属性,该文件的拥有者与用户组,该文件的大小,该文件建立或状态改变的时间(ctime),最近一次的读取时间(atime),最近修改的时间(mtime),定义文件特性的标识(flag),如SetUID,该文件真正内容的指向(pointer)。每个inode大小均固定为128B(ext4和xfs可设置到256B),每个文件占用一个inode,理论上文件系统能够建立文件的数量与inode数量应是一致的,当然数据区块肯定也限制了这个。
6.inode到数据区块:系统读取文件时。先找到inode,分析inode所记录的权限与用户是否符合,若符合再去按记录的号码查询相应数据区块的内容。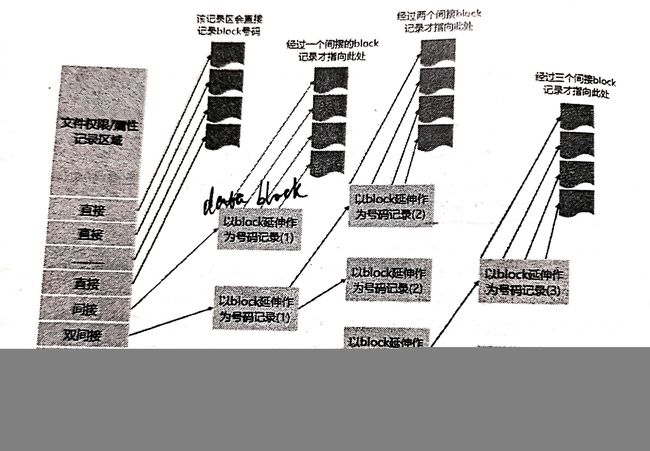
7.间接、双间接与三间接:inode记录区块号码的区域定义为12个直接、一个间接、一个双间接、一个三间接,双间接和三间接的部分,会指向数据区块,让其存放号码,再由这些号码去寻找相应的数据区块(对于1K的数据区块,可以存256条号码,这整个inode可存放单一文件大小上限为12+256+256256+256256*256(K)=16GB,这个方法对还另有限制的2K与4K大小的区块不适用)。对于更大的inode,自然可以记录跟多的文件系统信息。
8.Superblock(超级区块):记录数据区块与inode的总量,未使用与已使用的inode与数据区块数量,数据区块与inode的大小(block:1K\2K\4K,inode:128B\256B),文件系统的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等文件系统的相关信息、一个有效位数值(若此文件系统已被挂载为0,若未被挂载为1),一般超级区块的大小为1024B。
9.超级区块的特殊性:因为文件系统的基本信息都存于此,因此非常重要。而按理说每个区块群组都可能有超级区块,但一个文件系统应该仅有一个超级区块,这种矛盾似的说法事实上除了第一个区块群组内会含有超级区块之外,后面的群组是不一定有的,要是有也主要是为第一个区块群组内超级区块做备份,便于超级区块的恢复。
10.文件系统描述说明(Filesystem Description):描述每个区块群组的开始与结束的区块,以及说明每个区段(超级区块、对照表、inode对照表、数据区块)分别结与哪一个区块之间
11.区块对照表(block bitmap):告知区块的占用情况,让系统能很快地找到可使用的空间来处理文件,删除文件时,那些区块号码释放出来,区块对照表中这些号码的区块变成未使用中
12.inode对照表(inode bitmap):区块对照表记录的是使用与未使用的区块号码,inode对照表相应记录使用与未使用的inode号码
(2).使用dumpe2fs查询(ext系列适用)
CentOS 7现在是以xfs为默认文件系统,可以找一台是ext4等(如优麒麟)的来进行查询,也可以按照后面讲的自己划分一个ext4文件系统去查询看看。
[root@study ~]# dumpe2fs [-bh] 设备文件名
#-b:保留坏道
#-h:仅列出superblock的数据,有head之意
#现在的dumpe2fs提供了更多的选项和参数
#实际操作比如 dumpe2fs /dev/sda5这样的命令时往往要加管道 | more或者less方便翻页查看
[root@study ~]# blkid
#显示目前系统被格式化的设备,同样可以查看CentOS 7
利用dumpe2fs可以查询到非常多的信息,不过依内容可以划分为上半部分的超级区块内容,下半部分的每个区块群组的信息。
3.与目录树的关系
其实刚开始笔者也感觉这块有些混乱了,总的流程应该是先划分硬盘分区,然后格式化它成为某个文件系统,再把这个文件系统挂载到目录树上,这样才能进入其中,而根目录像是树干,无论如何一定要挂载好,才能在它的树枝上去挂载别的文件系统。
1.我们知道每个文件(不管是一般文件还是目录文件)都会占用一个inode,且可依据文件内容的大小来分配多个区块给该文件使用。
2.想要观察文件所占的inode号码可以在ls命令时加上-i的选项。使用-d这个选项,可以看到文件大小(B)。
3.当然每个人计算机不同,同一个文件显示出来的inode号码自然不同。
4.一个目录不会只占用一个区块,目录下面的文件数太多时,一个区块无法放下,Linux会多给该目录一个区块
5.inode本身不记录文件名,文件名本身记录在目录的数据区块当中,也因此新增、修改、删除文件名与目录的w权限有关。
6.系统通过挂载的信息可以找到根目录挂载点的inode号码,此时就能够得到根目录的inode内容,并依据该inode读取根目录的区块内的文件名数据,再一层一层的往下读取到正确的文件名。
7.如果文件写入的区块真的很分散,此时就会有所谓的文件数据离散的问题发生了,进而读取效率下降,磁头还是得在整个文件系统中来来去去地频繁读取。–解决:可以将整个文件系统内的数据全部复制出来,将该文件系统重新格式化,再将数据给它复制回去
8.当一个文件分别记录在文件系统的最前面与最后面的区块号码中,会造成磁盘的机械手臂移动幅度过大,读取性能也会下降。–磁盘分区的规划不是越大越好
9.挂载点的重点:挂载点一定是目录,该目录为进入该文件系统的入口,并不是有任何文件系统都能使用,必须要挂载到目录树的某个目录后,才能够使用该文件系统
10.同一个文件系统的某个inode只会对应到一个文件内容而已(因为一个文件占用一个inode),我们可以通过判断inode号码来确认不同文件名是否为相同的文件(/ /. /…就是同一个文件)(/ /home /boot就是不同文件,这是三个不同的文件系统)
4.文件系统的运行
(1).新增文件的常规操作
1.先确定用户对于欲新增文件的目录是否具有w与x权限,有才可新增
2.根据inode对照表找到没有使用的inode号码,并将新文件的权限/属性写入
3.根据区块对照表找到没有使用的区块号码,并将实际的数据写入区块中,且更新inode的区块指向数据
4.将刚刚写入的inode与区块数据同步更新inode对照表与区块对照表,并更新超级区块的内容
(2).数据的不一致(inconsistent)状态与日志式文件系统
数据存放区域:inode与数据区块
元数据(metadata):超级区块、区块对照表、inode对照表,其数据经常变动,每次新增、删除、编辑时都可能会影响着三个部分的数据
不一致的发生:在新增操作时,因为某些原因系统突然中断,最后一个同步更新元数据的步骤并没有完成,此时就会发生元数据的内容与实际数据存放区产生不一致的情况。需要检查时,用e2fsck这个程序,这个针对元数据区域与实际数据存放区一一检查的过程极为缓慢,因此催生了后来的日志式文件系统的兴起。
日志式文件系统:在文件系统当中规划出一个区块,该区块专门记录写入或修改文件时的步骤,也就是在新增文件的操作时最前面加上了一个预备工作,告诉日志记录区块要新增文件,在结束一切更新完元数据后,再到日志记录区块当中告诉它这个文件已经记录完成。这样只需检查日志记录区块,而不必针对整个文件系统进行检查。
(3).异步处理
为解决编辑大文件过程中磁盘写入与内存运作速度不一致的问题,Linux使用异步处理(asynchronously)的方式,如果该文件没有被修改过,则在内存区段的文件数据会被设置为clean,但如果改过了就会设置为Dirty,此时所有操作仍在内存中执行,并没有写入到磁盘中,系统会不定时的将内存中设置为Dirty的数据写回磁盘,以保持磁盘与内存数据的一致性。系统会将常用的文件数据放置到内存的缓冲区,以加速文件系统的读写操作,最后Linux的物理内存都被用光了,这很正常可以加速系统性能。
手动强制写入磁盘的命令:sync
(4).Linux支持的文件系统与VFS
[root@study ~]# ls -l /lib/modeles/$(uname -r)/kernel/fs
#查看Linux支持的文件系统
[root@study ~]# cat /proc/filesystem
#系统目前已加载到内存中支持的文件系统
传统文件系统:ext2、minix、FAT(用vfat模块)、iso9660(光盘)
日志式文件系统:ext3、ext4、ReiserFS、Windows‘NTFS、IBM’s JFS、SGI‘s XFS、ZFS
网络文件系统:NFS、SMBFS
其他值得参考的ext2相关文件系统文章:
Design and Implementation of the Second Extended Filesystem
The Second Extended File System-An introduction
维基百科有关文件系统比较的说明
ext2/ext3文件系统
5.XFS文件系统
1.ext系列的首要问题:支持度最广,但格式化超慢,因为采取的是预先规划好所有inode,区块,元数据等,不够动态灵活(性能并不是主要改变文件系统的考虑,文件系统的恢复速度、创建速度才可能是原因)
2.xfs简介:最初就是被开发来用于高容量磁盘以及高性能文件系统之用,是一个日志式文件系统,在数据的分布上,它主要规划为三个部分,一个数据区(data section)、一个文件系统活动登录区(log section)、一个实时运行区(realtime section)
3.数据区:类似ext系列的区块群组,每个存储区群组都包含了(1)整个文件系统的超级区块、(2)剩余空间的管理机制、(3)inode的分配与追踪,此外,inode与区块都是系统需要用到时才动态配置产生,所以格式化操作超快,虽然其区块容量可在512B~64KB调整,但Linux最高可用区块大小还是4K,设置大了之后Linux不给挂载
4.文件系统活动登录区:像是日志区,系统会在文件系统因为某些缘故损坏时拿这个登录区块来进行检验,当然可以指定外部的磁盘来作为xfs文件系统的日志区块,这样可能工作会更快速
5.实时运行区:这个有点像缓冲的工作区,文件先放到这里的一到数个extent区块,等数据区分配好再放到数据区,这个extent区块的大小要再格式化时指定好,(4K~1G)一般非磁盘阵列的磁盘默认64K容量,而具有类似磁盘阵列的stripe情况,建议extent与stripe一样大,并且extent大小不要乱动,会影响磁盘性能
[root@study ~]# xfs_info /dev/sda2
#这是属于xfs的命令区观察超级区块内容
meta-data=/dev/sda2 isize=256 agcount=4,agsize=65536 blks
……
= sunit=0 swidth=0 blks
log =internal ……
#isize指inode容量,agcount即存储区群组,前面说像区块群组的那个
#sunit与swidth与磁盘阵列的stripe相关性较高
#internal指这个登录区的位置在文件系统内,刚刚说到xfs可以指定外部设备为文件系统活动登录区
二、实践操作
1.文件系统的简单操作
(1)df
列出文件系统的整体磁盘使用量,主要读取的数据几乎都是针对一整个文件系统,因此读取的范围主要是在超级区块内的信息,所以这个命令显示结果的速度非常快
[root@study ~]# df [-ahikHTm] [目录或文件名]
-a:列出所有的文件系统,包括系统特有的/proc等文件系统,系统里这样的特殊的文件系统有很多,几乎都在内存当中,/proc这样的里面都是0,因为挂载在内存当中,当然不占任何磁盘空间
-h:以人们更易读的GBytes、MBytes、KBytes等格式自行显示
-i:不用磁盘容量,而以inode的数量显示
#默认输出的结果是以1K-Blocks的大小来显示的
#输出的Available是剩下的磁盘空间大小
#输出的Use是磁盘的使用率,超90%的要注意了,像容易被占满的/var/spool/mail这个保存邮件的目录
#输出的Mounted On便是磁盘的挂载目录
#输出的Mounted On中有个/dev/shm/目录,是利用内存虚拟出来的磁盘空间,通常是总物理内存的一半,在这个目录下建立任何数据文件,访问速度非常快
(2)du
查看文件系统的磁盘使用量(常用在查看目录所占磁盘空间)
[root@study ~]# du [-ahskm] 文件或目录名称
-s:仅列出总量,而不列出每个个别的目录占用容量
#默认列出目前目录下所有文件容量,目录里的文件不列
#实际显示时,仅会显示目录容量(不含文件),里面的文件不会列出,所有全部的目录相加不会等于(.)的容量
#默认输出的数值数据为1K大小的容量单位
[root@study ~]# du -sm /*
#利用通配符加-s选项可以看到每个目录的总情况,刚安装好Linux的话可以看到整个系统容量最大的应该是/usr,至于/proc里会列出一堆错误,因为程序执行结束就会消失,因此有些目录找不到是正确的
#用-m还是为了以MBytes显示
#用-S可以看到分开的情况,但不会对子目录容量进行累加
(3)ln
还记得两种链接方式吗,符号链接与硬链接,这里详细介绍下后者,它是通过文件系统的inode链接来产生新文件名,而不是产生新文件,其实文件名只与目录有关,但文件内容则与inode有关,简言之硬链接只是在某个目录下新增一条文件名链接到某inode号码的关联记录,如果你将任何一个文件名删除(不管是原文件名还是硬链接的新文件名),其实inode与区块都还是存在的,都可以通过另一个文件名来读到正确的文件数据,不论你使用哪个文件名来编辑,最终的结果都会写入到相同的inode与区块中,因此均能进行数据修改。相当于在通向同一个目的地的路上新架了了一座桥。
[root@study ~]# ll -i /etc/crontab
……/etc/crontab
[root@study ~]# ln /etc/crontab .
#默认建立硬链接
[root@study ~]# ll -i /etc/crontab crontab
……crontab
……/etc/crontab
[root@study ~]# ln -s /etc/crontab crontab2
#建立的是符号链接,新文件大小取决于原文件名
#用-f选项,是主动的将如果存在的目标文件删除后再建立
[root@study ~]# ll -i /etc/crontab /root/crontab2
……/etc/crontab
……/root/crontab2 ->/etc/crontab
硬链接制作一般不改变系统的区块、inode与磁盘空间大小,除非你新增这条数据时刚好将目录的区块填满了,只能新加一个区块来记录文件名关联性。
注意:硬链接不能跨文件系统,不能链接目录(环境复杂度太大,目前尚未支持)
符号链接的两个文件指向不同的inode,当然就是两个独立的文件存在,由符号链接所建立的文件为一个独立的新文件,所以会占用inode与区块,但这个链接文件只相当于一个指路牌,原文件名删掉后单靠它是读不到文件内容的,相当于中间唯一的桥梁断了,有了指路也到不了目的地。(如果符号链接的目标文件不存在,其文件名会有特殊的颜色显示)
不要轻易修改符号链接文件,按下保存源文件随之改动。
这么看来硬链接似乎更安全。
另外,建立一个新目录时的默认的链接数量是2,而上层目录的链接数则会增加1。
2.高级操作
想要在系统里新增一块磁盘时,操作:1.对磁盘进行划分,以建立可用的硬盘分区;2.对该硬盘分区进行格式化(format),以建立系统可用的文件系统;3.想要仔细的话,可对刚刚建立好的文件系统进行检验;4.在Linux系统上,需要建立挂载点(亦即是目录),并将它挂载上来;5.像硬盘分区有多大,是否需要日志功能,inode与区块的数量如何规划等问题将来需要以经验来考虑了
(1)lsblk与blkid
lsblk:列出所有存储设备(列出系统上的所有磁盘列表)
[root@study ~]# lsblk [-dfimpt] [device]
#-p:列出该设备的完整文件名,而不是仅列出最后的名字,会以目录的格式,如/dev/sda1,默认显示会省略/dev等前导目录
#MAJ:MIN是主要与次要设备代码,内核识别设备靠它俩
#RM判断是否为可卸载设备,RO判断是否为只读设备
#TYPE是磁盘disk、分区partition、还是只读存储器rom
#MOUNTPOINT是挂载点
blkid:列出设备的UUID(全局唯一标识符,设备独一无二有的,挂载用)等参数
[root@study ~]# blkid
/dev/sda2:UUID="……" TYPE="xfs"
/dev/sda3:UUID="……" TYPE="LVM2_member"
……
#每一行代表一个文件系统,主要列出设备名称、UUID名称以及文件系统的类型
parted:列出磁盘的分区表类型与分区信息
[root@study ~]# parted device_name print
#显示出来的Partition Table可以看分区表格式(msdos(MBR)/GPT)
(2)gdisk/fdisk
MBR分区表用fdisk分区,GPT分区表用gdisk分区,务必不要在MBR上使用gdisk,反之亦然。
[root@study ~]# gdisk /dev/sda <==不要加上数字,因为磁盘分区是针对整个磁盘设备,不是已经存在的某个分区
……
Command(?for help)<==按下?可以查看各命令
……
d delete a partition #删除一个分区
l list known partition types #新增分区不知道文件系统的ID时常用
p print the partition table
q quit without saving changes
w write table to disk and exit
#使用p后信息的上半部分在显示整体磁盘的状态,下半部分的分区表信息主要在列出每个分区的信息,其中Code栏是在分区内的可能的文件系统类型,可用l对应起来,Linux为8300,swap为8200,不过这个项目只是一个提示,不代表此分区内的文件系统
#使用n后,第一步是partition number,可回车默认
#第二步是first sector的位置确定,也可回车默认
#第三步是last sector的位置确定,万不可回车也不可用浮点数,可以换单位表示,回车则把剩下的容量全用光了,鸟哥书里采用了+1G的表示
#第四步Hex Code or GUID是选择未来这个分区预计使用的文件系统,可回车默认Linux的8300,忘记了还是按l查询
#第五步可以按下w写入了,按下y确定进程
#第六步是partprobe -s更新显示,因为内核还没有更新,当然也可重启更新
#使用d自然是删除分区,用partition number实现,w完成后别忘了更新显示
不要去处理一个正在使用中的分区,要先卸载后操作,否则直接删除该分区的话,虽然磁盘还是会写入正确的分区信息,但内核无法更新分区表,Linux的稳定性会受影响。
用fdisk时别忘了MBR是有限制的(Primary、Extended、Logical……)。
(3)mkfs.xfs/ext4与mkfs
刚才创建了分区之后便要对分区进行格式化,即创建文件系统。
[root@study ~]# mkfs.xfs [-b bsize] [-d parms] [-i parms] [-l parms] [-L parms] [-L label] [-f] [-r parms] 设备名称
#-b后面接区块容量
#-d后面接重要的data section,agcount,agsize,file,size,su,sw,sunit,swidth可以设置,file指的是格式化的设备是个文件而不是设备,例如虚拟磁盘
#-f是如果设备内有文件系统了,加这个强制格式化
#-L后面接文件系统的标头名称Label name
#-r指定realtime section的相关设置值,extsize的值一般不需设置,有磁盘阵列时,最好设置与swidth数值相同
#格式化后可以用blkid检查一下
[root@study ~]# grep 'processor' /proc/cpuinfo
#找出系统的CPU数并根据加以设置agcount的值,下面举例设置一下
[root@study ~]# mkfs.xfs -f -d agcount=2,sunit=512,swidth=3584 -r extsize=1792k /dev/sda4
#sunit和swidth的单位全是扇区数量,不是容量单位
使用默认的xfs文件系统参数来创建系统即可,速度非常快,有其他需求,才会加上参数设置。
关于磁盘阵列的一点叙述:就是通过将文件先细分为数个小型的分区区块(stripe),然后将众多的stripes分别放到磁盘阵列里的所有磁盘,即一个文件是被同时写入到多个磁盘中,性能会更好,为了文件的安全性,在这些磁盘里面会保留数个校验磁盘,以及可能会保留一个以上的备用磁盘,这些区块基本上会占用掉磁盘阵列的容量,但数据更安全。
[root@study ~]# mkfs.ext4 [-b size] [-L label] 设备名称
[root@study ~]# mkfs [tab] [tab]
#看看mkfs还支持哪种文件系统的格式化功能
[root@study ~]# mkfs -t vfat /dec/sda5
#这是另一种格式化的方式,把种类当作选项而非命令本身的格式化操作
(4)xfs_repair与fsck.ext4
文件系统发生错乱时的挽救命令。一般是root用户时采用,正常情况下可能会对系统造成危害,通常使用这个命令的场合都是系统出现极大问题,导致Linux启动时进入单人单机模式进行维护操作。
[root@study ~]# xfs_repair [-fnd] 设备名称
#-f:接文件名而不是实体设备
#-n:单纯检查并不修改
#-d:单人维护模式下,针对根目录(/)进行检查与修复操作,危险!!!
#修复已挂载的文件系统会出现问题,记得先卸载再处理
#无法被卸载掉根目录用-d处理,系统会强制检验该设备,检验完毕后就会自动重新启动
[root@study ~]# fsck.ext4 [-pf] [-b 超级区块] 设备名称
#文件系统状态正常便不会进入强制检查,会告诉你文件系统没问题
(5)mount与umount(见下篇)
鸟哥的Linux私房菜基础学习篇 第7章的重点探索(2)
总结
第7章是很长的一章,笔者弄明白它们都花了很久,总结下来真的也是处处是重点,总之还是一句话实践实践再实践。下篇接着说。