Java正则表达式
介绍:
正则表达式,就是用某种模式去匹配字符串的一个公式。正则表达式不是只有Java才有,很多语言都支持正则表达式进行字符串操作。javascript,php...
为什么要学习正则表达式?
(1)传统方法。使用遍历方式,代码量大,效率不高
(2)正则表达式技术可以快速找到所搜寻文本中的内容,专门用于处理类似文本处理问题
简单来说,正则表达式是对字符串执行模式匹配的技术。
(3)正则表达式:regular expression =>RegExp

//4.开始匹配
/*
* matcher.find()完成的任务
* 1.根据指定的规则,定位满足规则的子字符串(比如1)
* 2.找到后,将子字符串的开始的索引记录到matcher对象的属性int[] groups中
* group[0] = 0,把该字符串的结束的索引+1的值记录到groups[1]中
* 3.同时记录oldLast的值为子字符串的结束的索引+1的值,即下次执行find时,就从2开始匹配
* 下一次循环执行时,find的groups数组就清空,寻找下一个满足规则的子字符串,即groups[0]=10,groups[1]=12;
* 源码:
* public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
* 1.根据groups[0]=0,和groups[1]的记录的位置,从content开始截取子字符串返回,
就是[0,3)包含0但是不包含索引为3的位置
*/在while处设置断点,debug运行一下,groups[0]=0,groups[0]=2,如下图所示。

循环执行到下一次运行时,发现groups[0]=10,groups[0]=12,是因为匹配器matcher的find方法会清空上一次的记录

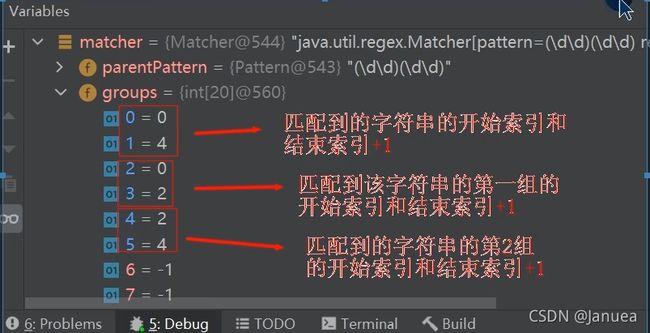
/*
* matcher.find()完成的任务(考虑分组)
* 什么是分组,比如(\d\d)(\d\d),正则表达式中有(),第1个()表示第1组,第2个()表示第2组...
* 1.根据指定的规则,定位满足规则的子字符串(比如(19)(98))
* 2.找到后,将子字符串的开始的索引记录到mather对象的属性int[] groups;
* 2.1 groups[0] = 0 ,把该子字符串的结束的索引+1的值记录到groups[1] = 4
* 2.2 记录1组()匹配到的字符串 groups[2] = 0 groups[3] = 2
* 2.3 记录2组()匹配到的字符串 groups[4] = 2 groups[5] = 4
* 2.4 如果有更多的分组......
* 3.同时记录oldLast的值为子字符串的结束的索引+1的值即为4,即下次执行find时,就从4开始匹配
*/ 
小结:
1.如果正则表达式有() 即分组
2.取出匹配的字符串规则如下
3.groups(0)表示匹配的到的子字符串
4.groups(1)表示匹配的到的子字符串的第1组字串
5.groups(2)表示匹配的到的子字符串的第2组字串
6...但是分组的数不能越界
正则表达式语法
如果想要灵活的运用正则表达式,必须了解其中各种元字符的功能,元字符从功能上大致分为:
1.限定符
2.选择匹配符
3.分组组合和反向引用符
4.特殊字符
5.字符匹配符
6.定位符
元字符(Metacharacter)- 转义号\\
\\符号说明:在我们使用正则表达式去检索某些特殊字符的时候,需要用到转移符号,否则会检索不到结果,甚至会报错。在Java中的正则表达式,两个\\代表其他语言中的一个\
需要用到转义符号的字符有以下:. * + ( ) $ / \ ? [ ] ^ { }

元字符-字符匹配符
| 符号 | 含义 | 示例 | 解释 |
| [] | 可接收的字符列表 | [abcd] | a、b、c、d中的任意1个字符 |
| [^] | 不可接收的字符列表 | [^abc] | 除a、b、c以外的任意一个字符,包括数字和特殊字符 |
| - | 连字符 | a-z | 任意单个小写字母 |
| . | 匹配除\n以外的任何字符 | a..b | 以a开头,b结尾,中间包括2个任意字符的长度为4的字符串 |
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
| . | 匹配除\n以外的任何字符 | a..b | 以a开头,b结尾,中间包括2个任意字符的长度为4的字符串 | aaab,aefb,a35b,a#*b |
| \\d | 匹配单个数字字符,相当于[0-9] | \\d{3}(\\d)? | 包含3个或4个数字的字符串 | 123,7896 |
| \\D | 匹配单个非数字字符,相当于[^0-9] | \\D(\\d)* | 以单个非数字字符开头,后接任意个数字字符串 | a,A342 |
| \\w | 匹配单个数字、大小写字母字符和下划线,相当于[0-9a-zA-Z_] | \\d{3}\\w{4} | 以3个数字字符开头,长度为7的数字字母字符和下划线 | 3333an_,3456789 |
| \\W | 匹配单个非数字、大小写字母字符和下划线,相当于[^0-9a-zA-Z_] | \\W+\\d{2} | 以至少1个非数字字母字符开头,2个数字字符结尾的字符串 | #29、#?@1 |
应用实例:
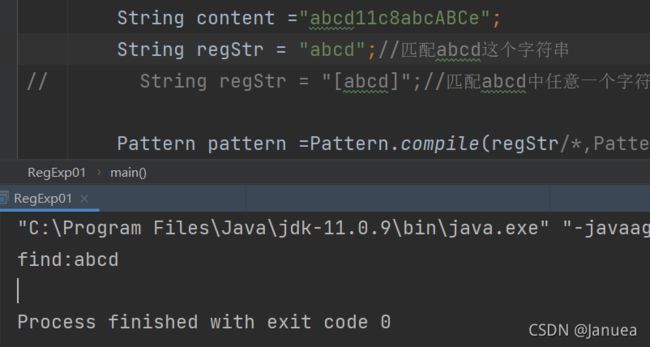
1.[a-z]说明:
[a-z]表示可以匹配a-z中的任意一个字符
2.java正则表达式默认是区分字母大小写的,不区分大小写如下:
(?!)abc表示abc都不区分大小写
a(?!)bc表示bc不区分大小写
a((?!)b)c表示只有b不区分大小写
Pattern pattern = Pattern.compile(regExp,Pattern.CASE_INSENSITIVE);
元字符-字符匹配符
\\s匹配任何空白字符(空格,制表符等)
\\S匹配任何非空白符,和\s刚好相反
.匹配出\n之外的所有字符,如果要匹配.本身则需要使用\\.

元字符-限定符:用于指定其前面的字符和组合项连续出现多少次
? 表示0或者1
+ 表示1-多
* 表示0-多
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
| ? | 指定字符重复0次或1次(最多一次) | m+abc? | 以至少1个m开头,后接ab或abc的字符 | mab,mmmabc |
| + | 指定字符重复1次或n次(至少一次) | m+(abc)* | 以至少1个m开头,后接任意个abc的字符串 | m,mmmabcabc |
| * | 指定字符重复0次或n次(无要求) | (abc)* | 仅包含任意个abc的字符串,等效于\w* | abc, ,abcabc |
| {n} | 只能输入n个字符 | [abcd]{3} | 由abcd中字母组成的任意长度为3的字符串 | abc,bcd,dab |
| {n,} | 指定至少n个匹配 | [abcd]{3,} | 由abcd字母组成的任意长度不小于3的字符串 | abc,abcda,aaabcd |
| {n,m} | 指定至少n个但不多于m个匹配 | [abcd]{3,5} | 由abcd字母组成的任意长度不小于3,不大于5的字符串 | abc,ancd,abcdb |
举例说明:
1.{n}说明:n表示出现的次数

//a{3,4},1{4,5},\\d{2,3}
Java匹配默认贪婪匹配,尽可能匹配多的,所以a{3,4}先匹配aaaa,1{4,5}先匹配11111,\\d{2,3}先匹配三位任意的数字元字符-定位符
定位符:规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
| ^ | 指定起始字符 | ^[0-9]+[a-z]* | 以至少一个数字开头,后接任意个小写字母的字符串 | 123a,1 |
| $ | 指定结束字符 | ^[0-9]\\-[a-z]+$ | 以1个数字开头后连接字符“-”,并以至少一个小写字母结尾的字符串 | 1-a,3-xm |
| \\b | 匹配目标字符串的边界 | an\\b | 这里说的字符串的边界指的是子串间有空格,或者是目标字符串的结束位置 | hanhan hanhan |
| \\B | 匹配目标字符串的非边界 | an\\B | 和\b的含义相反 | anhan |
这里的边界是指:被匹配的字符串最后,也可以是空格的子字符串的后面
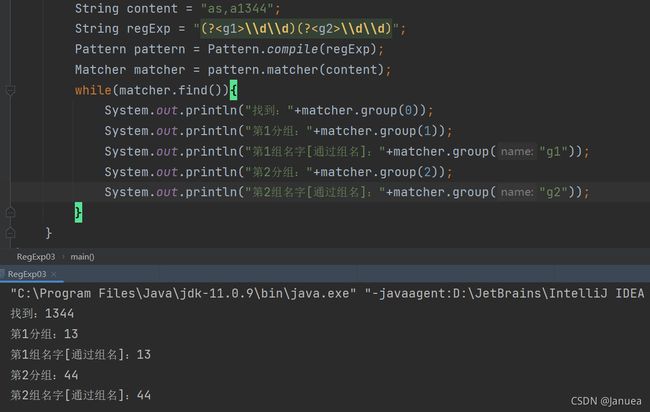
分组
| 常用分组构造形式 | 说明 |
| (pattern) | 非命名捕获。捕获匹配的子字符串。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其他捕获结果则根据左括号的顺序从1开始自动编号。 |
| (? |
命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。用于name的字符串不能包含任何的标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如(?'name') |
演练及结果
| 常用分组构造形式 | 说明 |
| (?:pattern) | 匹配pattern但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用“or”字符(|)组合模式部件的情况很有用。例如,'industr(?:y|lies)'是比'industry|industries'更经济的表达式。 |
| (?=pattern) | 它是一个非捕获匹配。例如,'Windows(?=95|98|NT|2000)'匹配“Windows 2000”中的“Windows”,但不匹配“Windows 3.1”中的“Windows”。 |
| (?!pattern) | 该表达式匹配不处于匹配pattern的字符串的起始点的搜索字符串。它是一个非捕获匹配。例如'Windows(?=95|98|NT|2000)'匹配“Windows 3.1”中的“Windows”,但不匹配“Windows 2000”中的“Windows”。 |


练习:
汉字,邮政编码,手机号码,qq号码,url地址

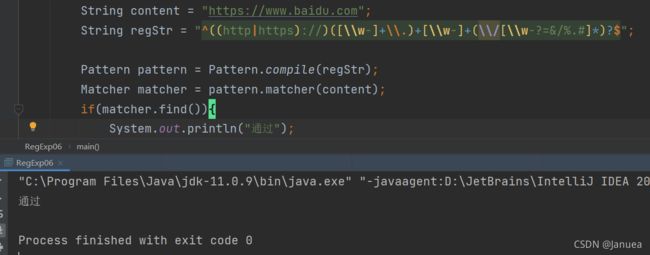
url地址验证:
跟着韩顺平老师写的
/*
* 思路:
* 1.先确定url的开始部分https://|http://
* 2.然后通过([\w-]+\.)+[\w-]+匹配www.baidu.com
* 3.(\/[\w-?=&/%.#]*)?匹配/video/cka%kmc
* */
String regStr = "^(((http|https)://))?([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?$";