BERT+CRF命名实体识别的主动学习实现,支持中英文(基于Keras)
命名实体识别主动学习
- 1. 什么是主动学习
- 2. 主动学习的指标计算
- 3. 代码实现
-
- 3.1 环境
- 3.2 数据的格式
- 3.3 建立tokenizer和model
- 3.4 数据生成器和数据预处理
- 3.5 建立数据池
- 3.6 定义模型训练相关类和方法
- 3.7 开启主动学习的流程
- 4. 关于其它任务的主动学习
1. 什么是主动学习
在机器学习中,主动学习(active learning)一般指,在标注数据的过程中,采用一定的方法,使得模型能够自主分辨未标注的样本中哪些更值得标注,进而通过更少的标注样本量达到相同或近似质量的模型的目的,从而降低人工标注的成本。
经过多年的发展,主动学习的方法越来越多样,今天介绍的是最基础的一种方法,并通过keras实现主动学习的功能。我在设计和实现这一过程的时候有参考别人的总结介绍,也有加入自己的理解,其中可能有不准确的地方。如果有读者发现这篇文章有什么明显的错误或问题,还请联系我,或在评论区指出。
2. 主动学习的指标计算
这篇文章主要参考了http://www.woshipm.com/kol/1020880.html其中所述的论文。
其中将计算用于NER的主动学习的指标归为了以下4种。本文应用到了其中的前两种,LC置信度指标和MNLP置信度指标。感兴趣的同学可以去阅读原文。
第一种即 Least Confidence(简称 LC),计算预测中最大概率序列的对应概率值。
第二种,Maximum Normalized Log-Probality(MNLP),基于 LC 并且考虑到生成中的序列长度对于不确定性的影响,我们做一个 normalization(即除以每个句子的长度),概率则是用每一个点概率输出的 log 值求和来代替。
第三种是一个基于 Disagreement 的主动学习方法,主要利用 dropout 在深度学习中的另一个作用(dropout 本来的作用是在训练中为了让模型 generalize 得更好)。去年 Gal et al. 的一篇文章就告诉我们:如果在做 inference 的时候也用 dropout 实际上是等价于来计算模型的不确定性的。这里我们也就需要在做 inference 的过程中也要同时做 dropout,在得到的 M 种结果中计算有多少是不一致的。
第四种方法是基于每一个点是否具有代表性的采样方法,除去考虑每一个点的不确定性外,通过计算样本与样本之间的相似度,来进一步判断该选择那些样本更具有代表性。这样的方法在大量数据的情况下需要更加有效的计算方法。我们重新把它处理成一个 submodular maximization 的问题,并利用 streaming algorithm 得到近似最优解。
3. 代码实现
3.1 环境
这篇博客将介绍如何利用keras实现主动学习的功能。
建议使用notebook运行下面的代码,方便调试。
主要用到的工具是bert4keras。由于3090要求CUDA11.2以上,所以无奈将TensorFlow升级到了2以上。而我用的bert4keras还是旧版的,所以做了一点点修改,使之可以在tf2的环境下进行。
修改后的bert4keras的链接:
链接:pan
提取码:r0gk
下载之后放在当前目录,从当前目录import即可。
|--your_notebook.ipynb
|--bert4keras
|--models.py
|--xxxxxx.py
接下来打开创建的notebook,加载它
import os
import re
import json
import random
import copy
import math
import numpy as np
import unicodedata, re
from bert4keras.backend import keras, K, batch_gather
from bert4keras.layers import Loss
from bert4keras.layers import LayerNormalization
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam, extend_with_exponential_moving_average
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import ViterbiDecoder
from keras.layers import Input, Dense, Lambda, Reshape, Dropout
from keras.models import Model
from bert4keras.optimizers import Adam
from tqdm.notebook import tqdm
from bert4keras.layers import ConditionalRandomField
# 设置使用显卡0
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
另外,接下来会用到的几个辅助函数提前写在这里。
def to_array(*args):
"""批量转numpy的array
"""
results = [np.array(a) for a in args]
if len(args) == 1:
return results[0]
else:
return results
# 这个函数也是bert4keras中实现的
# 在英文的场景中用来匹配token和character
# 返回每个token对应哪些character
def rematch(text, tokens, do_lower_case=do_lower_case):
if do_lower_case:
text = text.lower()
def is_control(ch):
return unicodedata.category(ch) in ('Cc', 'Cf')
def is_special(ch):
return bool(ch) and (ch[0] == '[') and (ch[-1] == ']')
def stem(token):
if token[:2] == '##':
return token[2:]
else:
return token
normalized_text, char_mapping = '', []
for i, ch in enumerate(text):
if do_lower_case:
ch = unicodedata.normalize('NFD', ch)
ch = ''.join([c for c in ch if unicodedata.category(c) != 'mn'])
ch = ''.join([c for c in ch if not (ord(c) == 0 or ord(c) == 0xfffd or is_control(c))])
normalized_text += ch
char_mapping.extend([i] * len(ch))
text, token_mapping, offset = normalized_text, [], 0
for token in tokens:
if is_special(token):
token_mapping.append([])
else:
token = stem(token)
if do_lower_case:
token = token.lower()
start = text[offset:].index(token) + offset
end = start + len(token)
token_mapping.append(char_mapping[start: end])
offset = end
return token_mapping
3.2 数据的格式
在这里我将数据处理成了以下格式,如果想参考这篇博客的话,最好也将数据处理一下。由于我使用的数据集为ACE2005,是非公开的数据集,没有办法把数据分享出来。下面手写了一个例子来说明数据的格式。
# 所有数据组织在一个list中,每一条数据是一个dict
# dict有3个键值对,数据的id,原文内容,以及包含的实体
# 包含的实体是一个list,其中的每一条实体是一个dict
# 每一个实体包含了实体的id,实体的类型,实体的原文内容,以及起止位置
[
{
"id": 1,
"text": 'ISIS宣称对爆炸负责。',
"entities": [
{
"entity_id": 1,
"entity_type": ORG,
"words": 'ISIS',
"start_pos": 0,
"end_pos": 4,
}
],
},
]
假设生成的数据(全部数据,还没有进行train和valid的划分)赋给变量data。
3.3 建立tokenizer和model
设置一下基本的参数。对于英文的情形,我采用的是cased model,中文的情形,采用的是全词掩码的wwm的模型。模型都可以在bert官方的GitHub上找到下载。
bert_layers = 12
learning_rate = 1e-5
crf_lr_multiplier = 1000
do_lower_case = True
maxlen = 512
train_batch_size = 16
# 场景是中文还是英文
lang = 'zh'
# 模型的本地路径
if lang == 'en':
config_path = 'your_path_to/cased_L-12_H-768_A-12/bert_config.json'
checkpoint_path = 'your_path_to/cased_L-12_H-768_A-12/bert_model.ckpt'
dict_path = 'your_path_to/cased_L-12_H-768_A-12/vocab.txt'
elif lang == 'zh':
config_path = 'your_path_to/bert_wwm_ext/bert_config.json'
checkpoint_path = 'your_path_to/bert_wwm_ext/bert_model.ckpt'
dict_path = 'your_path_to/bert_wwm_ext/vocab.txt'
分情况考虑中文和英文的情形,建立对应的tokenizer。
if lang == 'en':
tokenizer = Tokenizer(dict_path, do_lower_case=do_lower_case)
elif lang == 'zh':
class ZhTokenizer(Tokenizer):
def _tokenize(self, text):
"""
定义自己的分词器
词典里的直接加入,空格用未经训练标识,其余标记为UNK
:type text:
"""
Res = []
for c in text:
if c == "?":
Res.append('[UNK]')
elif c in self._token_dict:
Res.append(c)
elif self._is_space(c):
Res.append('[unused1]')
else:
Res.append('[UNK]')
return Res
tokenizer = ZhTokenizer(dict_path, do_lower_case=True)
else:
print('Make sure language is "en" or "zh".')
然后建立模型。
# 由于我希望在每轮学习时,从初始参数开始训练,而不受之前标注结果训练的影响
# 所以给Model类增加了一个reset的方法,用来读取初始的权重
# 这里的Model是keras的Model类
class TrainModel(Model):
def reset(self):
self.load_weights('init_ckpt.h5')
def creat_model():
"""
创建bert+crf的模型
创建模型的同时在当前目录下的init_ckpt目录创建初始参数
"""
bert_model = build_transformer_model(
config_path,
checkpoint_path,
)
num_labels = len(label2id)
output_layer = 'Transformer-%s-FeedForward-Norm' % (bert_layers - 1)
output = bert_model.get_layer(output_layer).output
output = Dense(num_labels)(output)
CRF = ConditionalRandomField(lr_multiplier=crf_lr_multiplier)
output = CRF(output)
train_model = TrainModel(bert_model.input, output)
# train_model.summary()
# 在创建模型的开始,把初始参数保存下来,用于后续的每一轮主动学习开始的时候加载
train_model.save('init_ckpt.h5')
train_model.compile(
loss=CRF.sparse_loss,
optimizer=Adam(learning_rate),
metrics=[CRF.sparse_accuracy]
)
return train_model
3.4 数据生成器和数据预处理
熟悉keras的同学应该对keras的数据生成器不陌生,其作用是将数据组织起来,把tokenizer给出的特征和数据对应的label,批量地传给model。在这里我设计的generator比较简单,对应的也就要求传给generator的数据需要是提前处理好的。
class Data_Generator(DataGenerator):
"""
数据生成器
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, d in self.sample(random):
if not d['text']:
continue
token_ids, segment_ids = tokenizer.encode(d['text'], maxlen=maxlen)
labels = d['label']
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append(labels)
if len(batch_token_ids) >= self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
batch_token_ids = batch_token_ids.astype('int64')
batch_segment_ids = batch_segment_ids.astype('int64')
batch_labels = batch_labels.astype('int64')
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
传给generator的每一条数据只有两个字段,text是原文本,label是每个token对应的标签。这也就要求数据需要提前把label生成好,这里编写了一个预处理的方法。
① data是全部的数据集,数据集的格式参考3.2中的样例;
② lang表示是英文还是中文,对中英文有不同的处理方法,简单来说,就是中文每个字符就是一个token,所以无需做特殊的处理,而英文则涉及到token和char的相互转换的问题。因为主动学习是需要与对应的标注系统进行交互的,而标注系统的前端界面展示一般要求以字符为单位,模型训练和预测是的基本单位则是token,所以在拿到char-level的数据时,需要先将其转换成token-level才能传给模型;
③ split_val表示是否将数据data切分成训练集和验证集,如果设置为True,则会随机取20%的数据作为验证集;
④ generate_label2id表示是否生成label2id这个映射,该映射用于将实体的类型转换为实体类型id,如果设置为true,则会在执行preprocess_data的时候创建全局变量label2id和它的逆变换id2label,二者都是dict。label2id是BIO形式标注的,B和实体类型之间用双短线–分隔,例如B- -ORG。
def preprocess_data(data, lang='en', split_val=False, generate_label2id=True):
"""
所有数据层的预处理工作
1. 创建标签label2id
2. 如果是英文,则需要做进一步的转换
:param data: 标注后的数据
:param lang: 语种,如果是英语则需要做span转换
:param split_val: 是否从中分出一部分作为验证集
:param generate_label2id: 是否生成全局的label2id
---------------
ver: 2021-08-28
by: changhongyu
"""
if generate_label2id:
# 遍历整个数据集,统计出全部的实体类型
# 这个label2id是BIO形式的
all_types = []
for d in data:
for ent in d['entities']:
if ent['entity_type'] not in all_types:
all_types.append(ent['entity_type'])
all_type_bi = []
for ent_type in all_types:
all_type_bi.append('B--' + ent_type)
all_type_bi.append('I--' + ent_type)
global label2id
global id2label
id2label = {
}
label2id = {
}
for i, label in enumerate(all_type_bi):
id2label[i+1] = label
label2id[label] = i+1
label2id['O'] = 0
id2label[0] = 'O'
# 统计完之后切分
if split_val:
data = data[: round(len(data) * 0.8)]
val_data = data[round(len(data) * 0.8)+1: ]
else:
val_data = None
def _get_char_span(train_data):
"""
从标准格式的训练数据中获取所有实体的char level格式
"""
char_span = []
for d in train_data:
current = []
for ent in d['entities']:
current.append(([i for i in range(ent['start_pos'], ent['end_pos']+1)], ent['entity_type']))
char_span.append(current)
return char_span
def _convert_char_span_to_input_label(char_span, tokenizer, train_data):
"""
英文数据集时使用
转化为用于训练的数据格式:
{'text': 'xxx', 'label': 'xxx'}
"""
final_res = []
for i, d in enumerate(tqdm(train_data)):
# 首先获取映射关系
try:
match_map = rematch(d['text'], tokenizer.tokenize(d['text'].lower()), do_lower_case=do_lower_case)
except:
labels = np.zeros(len(tokenizer.tokenize(d['text'].lower())))
final_res.append({
'text': d['text'], 'labels': labels})
continue
# print(match_map)
# 然后生成label
labels = np.zeros(len(tokenizer.tokenize(d['text'].lower())))
for cs in char_span[i]:
# 对每一个实体
if not len(cs):
continue
ent_span = cs[0]
ent_label = cs[1]
for char_idx, char_pos in enumerate(ent_span):
# 对每一个字符位置
for token_pos, token_map in enumerate(match_map):
# 对映射表中的每一个映射关系
if char_pos in token_map:
# 如果这个实体的字符存在于第token_pos个实体中
if ent_label in ['Sentence', 'Crime']:
# ACE2005中的比较特殊的类型,可以无视这行
continue
# 把label转换成BIO
if ent_label[:3] not in ['B--']:
# 如果还没有转换成BIO,先统一转换成B
ent_label = 'B--' + ent_label
labels[token_pos] = label2id[ent_label]
# print(labels)
# print(labels)
# 在将BO格式的转换成BIO
for i in range(1, len(labels)):
if labels[i] == 0:
continue
else:
if labels[i] % 2 == 1 and labels[i] == labels[i-1]:
# 1,1,1 变 1,2,1
labels[i] += 1
elif labels[i] % 2 == 1 and labels[i] == labels[i-1] - 1:
# 1,2,1 变 1,2,2
labels[i] += 1
final_res.append({
'text': d['text'], 'labels': labels})
return final_res
def _convert_data_to_input_label(train_data):
"""
中文数据集时使用
转化为用于训练的数据格式:
{'text': 'xxx', 'label': 'xxx'}
"""
final_res = []
for i, d in enumerate(tqdm(train_data)):
labels = np.zeros(len(tokenizer.tokenize(d['text'], maxlen=maxlen)))
for ent in d['entities']:
if ent['end_pos'] > 510:
continue
try:
labels[ent['start_pos'] + 1] = label2id['B--'+ent['entity_type']]
for i in range(ent['start_pos'] + 1, ent['end_pos']):
labels[i + 1] = label2id['I--'+ent['entity_type']]
except Exception as e:
print(e)
# print(ent)
# print(d['text'])
final_res.append(
{
"text": d['text'],
"labels": labels,
}
)
return final_res
# 如果是英文数据集,则转换成token level
if lang == 'en':
char_span = _get_char_span(data)
converted_train = _convert_char_span_to_input_label(char_span=char_span,
tokenizer=tokenizer,
train_data=data)
return converted_train, val_data
elif lang == 'zh':
converted_train = _convert_data_to_input_label(train_data=data)
return converted_train, val_data
else:
raise ValueError("Make sure input attribute lang is either en or zh.")
然后执行它,生成训练集和验证集,以及label2id。
train_data, valid_data = preprocess_data(data, lang=lang, generate_label2id=True, split_val=True)
# 除了label2id,还生成一个id2type,更便捷地在预测的时候获取实体类型,不考虑BIO
id2type = {
}
for i in id2label:
id2type[i] = id2label[i].split('--')[-1]
3.5 建立数据池
有了数据集之后,需要把它放在一个池子里,每轮训练之后,对池子里的数据进行判断,找到最值得标注的数据,然后把这些数据推荐给标注员。
为了实现这个基本的功能,编写了一个数据池的类,用于存放数据,以及按照数据的index取数据。
class DataPool:
"""
数据池
---------------
ver: 2021-07-27
by: changhongyu
"""
def __init__(self, ori_data=None):
if not ori_data:
ori_data = []
self.ori_data = ori_data
self.labeled_data = []
self.unlabeled_data = ori_data
if not self.unlabeled_data:
print("INFO: DataPool empty.")
def __len__(self):
return len(self.ori_data)
def sample_rand(self, num, valid_percent=0.2):
"""
随机采样num条,生成初始训练集和验证集
:param num: int: 采样的数量
:param valid_percent: float: 生成的验证集占比
:return rand_train: list: 生成的训练集
:return rand_valid: list: 生成的验证集
"""
random.shuffle(self.unlabeled_data)
rand_data = [self.unlabeled_data.pop(0) for i in range(num)]
self.labeled_data += rand_data
assert 0 <= valid_percent <= 1, "valid percent must in span [0, 1]."
len_train = round(num * (1-valid_percent))
rand_train = rand_data[: len_train]
rand_valid = rand_data[len_train: ]
return rand_train, rand_valid
def sample_by_idx(self, idxes, valid_percent=0.2):
"""
根据传入的序号采样
:param idxes: 按照置信度升序排列的样本idx列表
:return batch_train: list: 生成的训练集
:return batch_valid: list: 生成的验证集
"""
batch = []
for i, idx in enumerate(idxes):
for d in self.unlabeled_data:
if d['id'] == idx:
batch.append(d)
self.labeled_data.append(d)
self.unlabeled_data.remove(d)
break
assert 0 <= valid_percent <= 1, "valid percent must in span [0, 1]."
len_train = round(len(idxes) * (1-valid_percent))
batch_train = batch[: len_train]
batch_valid = batch[len_train: ]
return batch_train, batch_valid
def upgrade(self):
"""
更新已标注数据和未标注数据
"""
pass
def upload(self, new_data):
"""
向池子里增加数据
:param new_data: list: 新增的数据
"""
self.unlabeled_data += new_data
def clear(self):
"""
清空数据池
"""
self.ori_data = []
self.labeled_data = []
self.unlabeled_data = []
有了数据池之后,还编写了一个方法用来模拟人工标注的过程。因为正常情况下,主动学习应该是与标注系统交互的,将模型确定性不高的数据找到,然后推给标注系统进行人工标注。一开始拿到的数据也是没有标签的。
在这篇博客里,为了调试代码是否可以执行,拿到的数据都是有标签的。但是我们可以假设数据没有标签,然后经过了这个make_label方法之后,数据的标签才是可见的。简单来说就是这个方法假装有人在标注,这个方法出现在流程中的位置也就是用来说明人工标注在什么时候进行。
def make_label(data):
"""
假设这是使用标注系统对数据标注的过程
其实它什么也没有做
:param data: 未标注数据
:return labeled_data: 已标注数据
"""
labeled_data = data
return labeled_data
3.6 定义模型训练相关类和方法
在这里定义了三个组件,一个train方法,用于训练模型,一个evaluate方法,用于评估模型在验证集上的指标,还有一个命名实体识别器,用于从原文中获取实体。
首先来看命名实体识别器,我把主动学习的指标计算也放在了这里边。
简单介绍一下这个类:
① recognize方法用于计算每一个token的labels,以及判定为这些labels的“概率”;
② get_confidence方法用于计算置信度指标,包括了两个指标LC和MNLP;
③ get_entities,get_entities_with_text以及convert_token_to_char是利用labels,针对中英文获取实体的方法;
④ predict方法直接传入一段文本,然后从中获取实体。
关于置信度指标的计算,除了算LC和MNLP之外,我考虑了类别置信度,即每个类型的实体的总体置信度情况,如果某个类型的实体置信度低,则考虑在主动学习的过程中,优先以该类型的实体作为目标进行推荐。
class NamedEntityRecognizer(ViterbiDecoder):
"""
命名实体识别器
只区分start和end,不区分论元类型
"""
def recognize(self, token_ids, segment_ids, return_labels=True):
"""
实体识别
返回label:
[0, 0, 0, 1, 1 ,2]
注意,模型返回的label是token level的
---------------
ver: 2021-07-27
by: changhongyu
"""
while len(token_ids) > 512:
token_ids.pop(-2)
segment_ids.pop(-2)
probs = train_model.predict([to_array([token_ids]), to_array([segment_ids])])[0]
if return_labels:
labels = self.decode(probs)
# print(labels)
else:
labels = None
return labels, probs
@staticmethod
def get_confidence(probs):
"""
获取当前样本的置信度
:param probs: model.predict的结果,shape: (l, num_labels)
:return LC_confidence: LC置信度
:return MNLP_confidence: MNLP置信度(对数归一化)
---------------
ver: 2021-07-27
by: changhongyu
"""
probs = probs[1: ]
# 当前样本的全局置信度
# 等于所有位置上的置信度之和
LC_confidence = 0
MNLP_confidence = 0
# 该样本中每一个类别的实体的置信度
LC_confidence_by_cls = {
}
MNLP_confidence_by_cls = {
}
# 该样本中每一个类别的实体的累计概率
prob_by_cls = {
}
for tok_probs in probs:
# 对每一个位置的token,计算当前位置的置信度
# 置信度越大则该位置的确定性就越高
lc_conf = 1
mnlp_conf = 1
for labelid, prob in enumerate(tok_probs):
# 当前样本下,计算一个类型实体的累计概率
ent_type = id2type[labelid]
if ent_type not in prob_by_cls:
prob_by_cls[ent_type] = prob
else:
prob_by_cls[ent_type] += prob
# 对每一种label,计算确信度,即差值绝对值
abs_tok_probs = [1 - prob if prob < 0.5 else prob for prob in tok_probs]
for labelid, prob in enumerate(abs_tok_probs):
# 当前样本下,计算每一个类型实体的置信度
ent_type = id2type[labelid]
if ent_type not in LC_confidence_by_cls:
LC_confidence_by_cls[ent_type] = prob
else:
LC_confidence_by_cls[ent_type] *= math.log(prob)
if ent_type not in MNLP_confidence_by_cls:
MNLP_confidence_by_cls[ent_type] = prob
else:
MNLP_confidence_by_cls[ent_type] += math.log(prob)
# 当前样本下,计算所有类型的总的置信度
lc_conf *= prob
mnlp_conf += math.log(prob)
LC_confidence += lc_conf
MNLP_confidence += mnlp_conf
MNLP_confidence /= len(probs) # 序列长度归一化
for k in LC_confidence_by_cls:
MNLP_confidence_by_cls[k] /= len(probs)
prob_by_cls[k] /= len(probs)
return LC_confidence, MNLP_confidence, LC_confidence_by_cls, MNLP_confidence_by_cls, prob_by_cls
@staticmethod
def get_entities(labels, text, lang='en'):
"""
获取不带text和ent_id的实体
用于训练过程中的评估
"""
entities = []
ent = None
prev_id = 0
for pos, cur_id in enumerate(labels):
if cur_id % 2 == 1:
# 说明是实体的开始
if ent:
# 添加旧的实体
entities.append(ent)
ent = None
# 初始化新的实体
ent_start = pos
ent_end = pos
ent_type = id2label[cur_id].split('--')[-1]
ent = {
'entity_type': ent_type,
'start_pos': ent_start,
'end_pos': ent_end}
prev_id = cur_id
elif cur_id != 0 and cur_id % 2 == 0:
# 说明是实体的内部
if cur_id != prev_id + 1:
continue
# 更新end pos
ent['end_pos'] = pos
# 不更新prev_id
else:
# 说明是非实体
if ent:
entities.append(ent)
ent = None
prev_id = cur_id
if lang == 'en':
entities = self.get_entities_with_text(text, entities)
elif lang == 'zh':
for ent in entities:
ent["words"] = text[ent['start_pos']: ent['end_pos']]
return entities
@staticmethod
def get_entities_with_text(text, entities):
"""
获取带text和id的实体
用于测试
:param text: 原文
"""
token_res = tokenizer.tokenize(text)
for i, ent in enumerate(entities):
ent_start = ent['start_pos']
ent_end = ent['end_pos']
ent_text = text[ent_start: ent_end]
ent['words'] = ent_text
ent['entity_id'] = i
return entities
@staticmethod
def convert_token_to_char(entities, text):
"""
把token level的实体转化为char level
对带实体text和不带text的实体都可以使用这个方法
:param entities: 标准格式的实体
:param text: 原文
"""
# 先生成映射表
tokens = tokenizer.tokenize(text)
try:
match_map = rematch(text, tokens, do_lower_case=do_lower_case)
except Exception as e:
print('error occurred while creating "match_map"')
print(text)
print(tokens)
print(e)
return []
for ent in entities:
char_spans = []
for i in range(ent['start_pos'], ent['end_pos'] + 1):
char_spans += match_map[i]
if not char_spans:
print(ent)
print(match_map)
ent['start_pos'] = char_spans[0]
ent['end_pos'] = char_spans[-1]
return entities
def predict(self, text, lang='en'):
"""
从输入文本中获取实体
"""
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
while len(token_ids) > maxlen:
token_ids.pop(-2)
segment_ids.pop(-2)
# 注意:此处修改,recognize方法改为两个返回值,labels是第一个
labels = self.recognize(token_ids, segment_ids)[0]
entities = self.get_entities(labels, text, lang)
if lang == 'en':
# 如果是英文,需要把token_level的实体转化为char_level
entities = self.convert_token_to_char(entities, text)
return entities
然后是评估方法,没有什么需要特别说明的。
def evaluate(valid_data, NER):
"""
:param valid_data: 直接读取验证集,而非生成器
:param NER: 实例化的NamedEntityRecognizer类
"""
true_all, pred_all, pred_true = 1e-10, 1e-10, 1e-10
for batch_num, d in enumerate(tqdm(valid_data)):
# true_all += len(d['entities'])
true_ents = [] # 生成一个不带text和id的真实实体集合
for ent in d['entities']:
if ent['end_pos'] > 510:
continue
true_ents.append({
'entity_type': ent['entity_type'],
'start_pos': ent['start_pos'],
'words': ent['words'],
'end_pos': ent['end_pos']})
true_all += len(true_ents)
entities = NER.predict(d['text'], lang=lang)
# if batch_num % 100 == 0:
# print(true_ents)
# print(entities)
# print('\n')
pred_all += len(entities)
for ent in entities:
if ent in true_ents:
pred_true += 1
precision = pred_true / pred_all
recall = pred_true / true_all
f1 = 2 * precision * recall / (precision + recall)
return f1, precision, recall
最后是我们的训练方法,也没有什么需要特别注意的。训练过程中会把f1最高的参数保存在当前路径,名为’best_model.h5’。
def train(model, epoch, train_data, valid_data):
"""
训练
如果存在valid_data,则进行验证并保存最佳模型
:param model: model
:param epoch: epoch
:param train_data: converted train
:param valid_data: valid
---------------
ver: 2021-07-27
by: changhongyu
"""
CRF = model.layers[-1]
NER = NamedEntityRecognizer(trans=K.eval(CRF.trans), starts=[0], ends=[0])
class Evaluator(keras.callbacks.Callback):
def __init__(self, valid, NER):
self.best_val_f1 = 0
self.valid_data = valid
self.NER = NER
def on_epoch_end(self, epoch, logs=None):
trans = K.eval(CRF.trans)
NER.trans = trans
# print(NER.trans)
if self.valid_data:
f1, precision, recall = evaluate(self.valid_data, self.NER)
# 保存最优
if f1 > self.best_val_f1:
self.best_val_f1 = f1
print('saving best weights......')
train_model.save_weights('best_model.h5')
print('done.')
print(
'valid: f1: %.5f, precision: %.5f, recall: %.5f, best f1: %.5f\n' %
(f1, precision, recall, self.best_val_f1)
)
call_back = Evaluator(valid_data, NER)
train_generator = Data_Generator(train_data, batch_size=train_batch_size)
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=epoch,
callbacks=[call_back]
)
return model
3.7 开启主动学习的流程
首先配置一下参数。
start_num = 100 # 初始标注数据
start_epoch = 5 # 初始标注数据训练多少轮
train_epoch = 5 # 主动学习过程中每次训练多少轮
ori_data = data # 全部原始未标注数据
method = 'MNLP' # 主动学习策略
nums_every_round = 40 # 主动学习每一轮推荐多少条数据
max_num_calcu_conf = 500 # 主动学习时在多少条样本中计算置信度并推荐
sort_by_cls = True # 是否按照类别排序
为了帮助读者理解这段代码的流程,我画了一个简单的图:
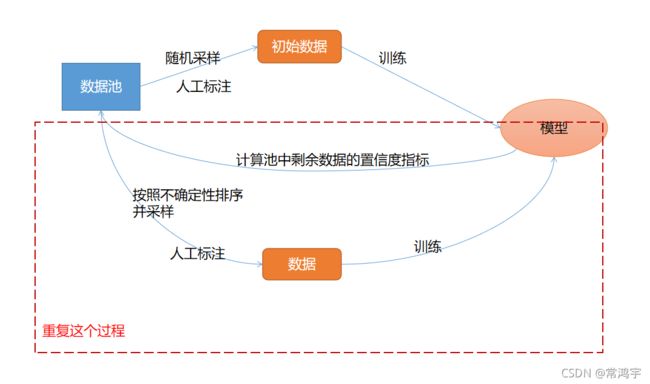
第一步,先建立模型和数据池。
第二步,从池中随机取出 一部分数据,标注并训练出初始的模型。
第三步,利用模型预测剩下的数据,计算各类指标,并推荐出最值得标注的数据。
第四步,按照计算的置信度结果,从池中采样最值得标注的数据。
然后重复第三四步的过程,直到满足某类条件,结束流程。
下面是整个流程的代码:
print("Creating Data Pool.")
data_pool = DataPool(ori_data)
# 冷启动采样
print("Sampling from Data Pool.")
start_train, start_valid = data_pool.sample_rand(num=start_num)
print("Labeling Data.")
start_train = make_label(start_train) # 假设这里是对数据进行标注
start_valid = make_label(start_valid)
print("Preprocessing Data.")
# print(start_train[0:3])
converted_train, _ = preprocess_data(start_train, lang=lang, generate_label2id=False)
train_data = converted_train
valid_data = start_valid
print(len(valid_data))
# 模型初始训练,先建立参数
print("Creating Train Model.")
train_model = creat_model()
print(train_model)
print("Training.")
train_model = train(train_model, start_epoch, train_data, valid_data)
print("对未标注数据进行排序")
# 对未标注数据进行排序
CRF = train_model.layers[-1]
NER = NamedEntityRecognizer(trans=K.eval(CRF.trans), starts=[0], ends=[0])
idxes = []
print("Calculating Confidence.")
random.shuffle(data_pool.unlabeled_data)
# 对每一篇未标注文档计算其置信度,然后重新排列
for d in tqdm(data_pool.unlabeled_data[: max_num_calcu_conf]):
# 对每一篇未标注文档计算其置信度
# 记录所有样本的各个类别的置信度
global_LC_by_cls = {
}
global_MNLP_by_cls = {
}
token_ids, segment_ids = tokenizer.encode(d['text'])
# print(token_ids, segment_ids)
_, probs = NER.recognize(token_ids, segment_ids, return_labels=False)
# print(_, probs)
# print(NER.get_confidence(probs))
LC_confidence, MNLP_confidence, LC_confidence_by_cls, MNLP_confidence_by_cls, prob_by_cls = NER.get_confidence(probs)
# 更新各个类别的全局置信度
for cls in LC_confidence_by_cls:
if cls not in global_LC_by_cls:
global_LC_by_cls[cls] = LC_confidence_by_cls[cls]
else:
global_LC_by_cls[cls] *= LC_confidence_by_cls[cls]
if cls not in global_MNLP_by_cls:
global_MNLP_by_cls[cls] = MNLP_confidence_by_cls[cls]
else:
global_MNLP_by_cls[cls] += math.log(MNLP_confidence_by_cls[cls])
idxes.append((d['id'], LC_confidence, MNLP_confidence, LC_confidence_by_cls, MNLP_confidence_by_cls, prob_by_cls))
if sort_by_cls:
# 如果按照不确定性最高的类别推荐
if method == 'LC':
# 先找到最不确信的类别
min_lc_conf = 1e+5
for cls in LC_confidence_by_cls:
if LC_confidence_by_cls[cls] < min_lc_conf:
uncertain_cls = cls
min_lc_conf = LC_confidence_by_cls[cls]
# 然后根据这个类别进行排序
print("当前不确定性最高的实体类别是:{},将按照该类实体进行推荐".format(uncertain_cls))
idxes = sorted(idxes, key=lambda x: x[3][uncertain_cls] * x[5][uncertain_cls])
else:
min_mnlp_conf = 1.0
for cls in MNLP_confidence_by_cls:
if MNLP_confidence_by_cls[cls] < min_mnlp_conf:
uncertain_cls = cls
min_mnlp_conf = MNLP_confidence_by_cls[cls]
idxes = sorted(idxes, key=lambda x: x[4][uncertain_cls] * x[5][uncertain_cls])
print("当前不确定性最高的实体类别是:{},将按照该类实体进行推荐".format(uncertain_cls))
else:
if method == 'LC':
idxes = sorted(idxes, key=lambda x: x[1])
else:
idxes = sorted(idxes, key=lambda x: x[2])
idxes = [i[0] for i in idxes][: nums_every_round]
# 开始主动学习
print("Start Active Learning.")
while True:
new_train, new_valid = data_pool.sample_by_idx(idxes)
# 标注数据
cur_train = make_label(new_train)
cur_valid = make_label(new_valid)
cur_train, _ = preprocess_data(cur_train, lang='zh', generate_label2id=False)
train_data += cur_train
valid_data += cur_valid
train_model.reset()
print("Training")
train_model = train(train_model, train_epoch, train_data, valid_data)
CRF = train_model.layers[-1]
NER = NamedEntityRecognizer(trans=K.eval(CRF.trans), starts=[0], ends=[0])
idxes = []
random.shuffle(data_pool.unlabeled_data)
print("Calculating Confidence.")
for d in tqdm(data_pool.unlabeled_data[: 1000]):
# 对每一篇未标注文档计算其置信度
global_LC_by_cls = {
}
global_MNLP_by_cls = {
}
token_ids, segment_ids = tokenizer.encode(d['text'])
_, probs = NER.recognize(token_ids, segment_ids, return_labels=False)
LC_confidence, MNLP_confidence, LC_confidence_by_cls, MNLP_confidence_by_cls, prob_by_cls = NER.get_confidence(probs)
# 更新各个类别的全局置信度
for cls in LC_confidence_by_cls:
if cls not in global_LC_by_cls:
global_LC_by_cls[cls] = LC_confidence_by_cls[cls]
else:
global_LC_by_cls[cls] *= LC_confidence_by_cls[cls]
if cls not in global_MNLP_by_cls:
global_MNLP_by_cls[cls] = MNLP_confidence_by_cls[cls]
else:
global_MNLP_by_cls[cls] += math.log(MNLP_confidence_by_cls[cls])
idxes.append((d['id'], LC_confidence, MNLP_confidence, LC_confidence_by_cls, MNLP_confidence_by_cls, prob_by_cls))
if sort_by_cls:
if method == 'LC':
# 先找到最不确信的类别
min_lc_conf = 1e+5
for cls in LC_confidence_by_cls:
if LC_confidence_by_cls[cls] < min_lc_conf:
uncertain_cls = cls
min_lc_conf = LC_confidence_by_cls[cls]
# 然后根据这个类别进行排序
print("当前不确定性最高的实体类别是:{},将按照该类实体进行推荐".format(uncertain_cls))
idxes = sorted(idxes, key=lambda x: x[3][uncertain_cls] * x[5][uncertain_cls])
else:
min_mnlp_conf = 1.0
for cls in MNLP_confidence_by_cls:
if MNLP_confidence_by_cls[cls] < min_mnlp_conf:
uncertain_cls = cls
min_mnlp_conf = MNLP_confidence_by_cls[cls]
print("当前不确定性最高的实体类别是:{},将按照该类实体进行推荐".format(uncertain_cls))
idxes = sorted(idxes, key=lambda x: x[4][uncertain_cls] * x[5][uncertain_cls])
else:
if method == 'LC':
idxes = sorted(idxes, key=lambda x: x[1])
else:
idxes = sorted(idxes, key=lambda x: x[2])
idxes = [i[0] for i in idxes][: nums_every_round]
# 出口
# 如果池中剩余数据量小于数据总量的30%,则停止标注
# 也可以根据自己的实际情况设计其他各种样式的出口
if len(data_pool.unlabeled_data) <= len(data_pool) * 0.3:
break
4. 关于其它任务的主动学习
本篇博客主要介绍了命名实体识别任务的主动学习实现,对于其他任务,只需要做细微的调整即可。例如分类任务,需要对分类器计算的属于某一个类别的“概率”计算指标,即token分类的任务转为了sequence分类的任务,减少了len维度,在此代码的基础上稍作简化即可。至于关系抽取、事件抽取等任务,主要取决于模型的结构是怎样设计的,如果是pipeline的模型,则需要分别计算其中每一步(NER,分类等)的置信度,然后计算一个综合指标,如果是joint模型,则需要直接设计一个总体的置信度得分。
如果有任何相关的问题,欢迎在评论区留言交流讨论,我们下期再见。