一键搭建深度学习平台,基于Docker/Mesos和NVIDIA GPU详细教程
前言
NVIDIA GPU 可以大大加快 Deep Learning 任务的运行速度;同时, GPU 资源又是十分昂贵的,需要尽可能提高 GPU 资源的利用率。为了解决上述问题,一个更合理的思路是利用 Mesos 将 GPU 资源汇聚成资源池来实现资源共享,并借用 Docker 交付深度学习的 runtime 环境,很好的解决了上述问题。
清华大学交叉信息研究院开放计算项目实验室( OCP 实验室)基于以上背景,与数人云合作解决深度学习环境部署繁琐的问题,该平台从 6 月份开始已经为清华大学的师生提供服务。
本文首先介绍了深度学习平台常用的工具包括 CUDA, Caffe, Mesos, Docker 等;接着介绍整个平台的架构;然后给出了平台搭建需要解决的关键性问题及应对策略;最后罗列了未来需要克服的关键性问题。另外,由于 GPU + Docker 还没有通用的标准,在实际操作中,我们使用了一些 Tricky 的做法。
在介绍深度学习平台的工具之前,我们再详细阐述下用户需求。用户本质要解决两个问题:
用户会频繁的批量部署深度学习环境,并在使用完后及时销毁环境以释放资源。遇到的难题是深度学习环境的软件包安装繁琐。
深度学习环境用到的 GPU 资源宝贵,用户需要 GPU 资源共享。
深度学习平台工具
CUDA: CUDA 是 NVIDIA 开发的一个平行计算平台和编程模型。它利用 GPU 来提高计算性能。 CUDA 运行于 NVIDIA 的 GPU 硬件之上。
Caffe: Caffe 是 BVLC 开发的一个深度学习框架。在 GPU mode 下, Caffe 通过 CUDA 调用 GPU 资源。
TensorFlow: TensorFlow 是谷歌开源的一个利用数据流图进行数据运算的软件库,在 GPU mode 下, TensorFlow 也依赖于 CUDA 来使用 GPU 资源。
jupyter: jupyter 是一个进行交互式数据处理,及结果可视化的 Web 应用,其前身是 Python Notebook。 是数据科学家常用的工具之一。
Docker: Docker 是一种轻量的虚拟化技术,在保证基本的环境隔离前提下,它几乎可以达到裸机的性能。
Apache Mesos: Mesos 是一个分布式系统内核,它参考了 Linux kernel 原理,在数据中心层对资源进行了抽象。
平台架构
这里从节点内部和集群两层介绍平台的架构。
在节点内部,我们利用 nvidia-docker ( https://github.com/NVIDIA/nvidia-docker ) 来帮助容器内部的程序调用外面主机上的 CUDA driver。如下图一所示, CUDA Driver 及 GPU Driver 安装在外部 Host 上; CUDA Toolkit、其它深度学习组件及用户应用程序运行在 Docker 容器中。这样既能快速配置环境,又保证了 HOST 不受用户应用程序污染。我会在下一章节介绍具体的设置过程。
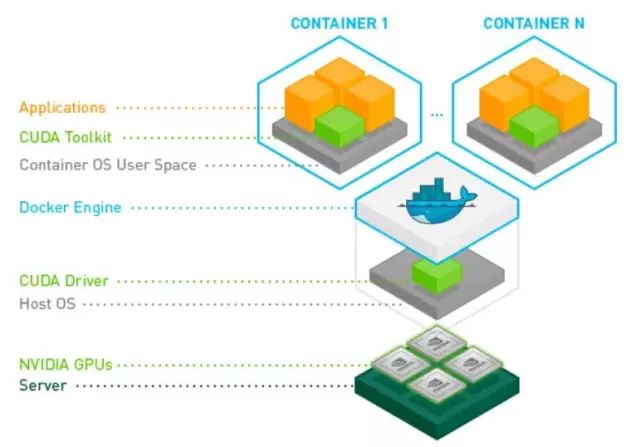
图一 来源 https://github.com/NVIDIA/nvidia-docker/wiki
在整个集群层面,利用 Mesos 将资源池化,用户可通过 Marathon 统一入口部署自己的深度学习 Docker Package。如下图二所示,集群包括 3 个 Mesos 管理( Master)节点和多个工作( slave)节点,任务分发到 slave 后, slave 通过 executor 与 Docker daemon 通信, Docker daemon 按需从内部镜像仓库拉取并加载 Docker image。对应到真实应用场景,带有深度学习依赖组件的 Docker image 将被 pull & run,用户可以通过 ssh 或者 jupyter 的 Web 入口与组件进行交互。
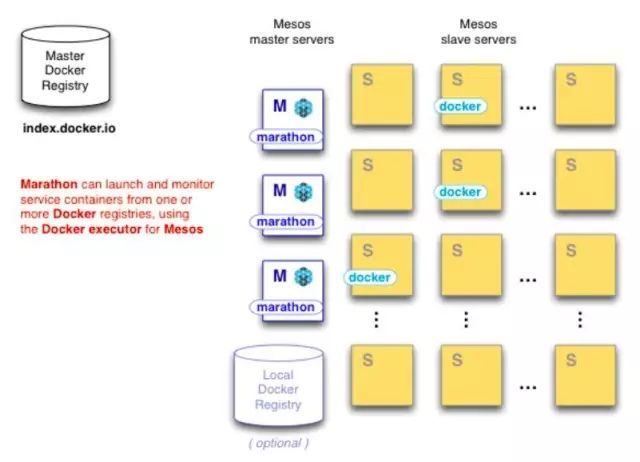
图二 来源 https://mesosphere.com/blog/2013/09/26/docker-on-mesos/
这个方案与 nvidia & mesosphere 合作推出的方案 http://www.nvidia.com/object/apache-mesos.html 不同,后面章节会介绍差异。
基础环境设置
节点设置
第一批机器,我们选用了 CentOS7.2 操作系统和 NVIDIA Tesla K20c 的显卡。具体的设置过程如下:
安装好显卡并 reboot 机器,然后在终端输入命令
lspci | grep –i nvidia
如果显卡安装成功,则可以获得如下类似输出。
84:00.0 3D controller: NVIDIA Corporation GK110GL [Tesla K20c] (rev a1)
安装显卡驱动, 可以在 NVIDIA 官方网站http://www.nvidia.com/Download/index.aspx?lang=en-us 找到相应的显卡驱动,下载并安装。这里需要注意的是,许多的 Linux 发行版已经预装了一个开源的 video driver—Nouveau,而这个 driver 是与 NVIDIA driver 冲突的,需要参考 http://www.dedoimedo.com/computers/centos-7-nvidia.html或
http://www.allaboutlinux.eu/remove-nouveau-and-install-nvidia-driver-in-ubuntu-15-04/ 来禁掉 Nouveau,然后才能成功安装 NVIDIA Driver。
如果 driver 安装成功,可以通过命令 nvidia-smi 获取如下截图三的输出
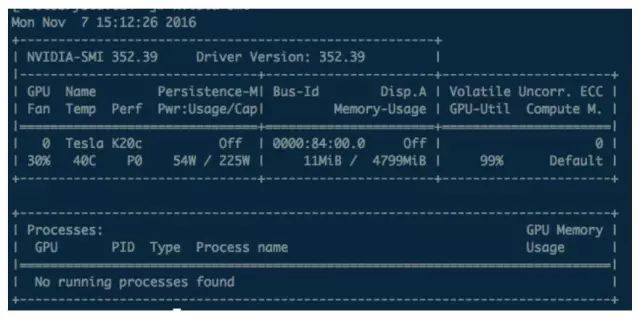
图三
安装 CUDA,在http://docs.nvidia.com/cuda/cuda-getting-started-guide-for-linux/下载CUDA安装包,CUDA 的安装包比较大,依赖也非常多,以及一些必不可少的环境变量设置,这一步需要费些时间。我们在实际环境中安装了 CUDA 7.5,目前 NVIDIA 已经发布了 CUDA 8.0 。安装完成后,尤其需要查看 /dev/nvidia* 是否存在,一般来说,至少 /dev/nvidiactl, /dev/nvidia-uvm 和 /dev/nvidia0 是应该有的,如有缺失,可以使用该链接 http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#runfile-verifications 提供的脚本来创建缺失的文件。
验证 CUDA 安装成功。安装完毕后,可以通过 CUDA 安装包自带的sample进行验证,譬如:
cd /usr/local/cuda-7.5/samples/1_Utilities/deviceQuery
make
./deviceQuery
应该可以得到如下截图四中的内容。
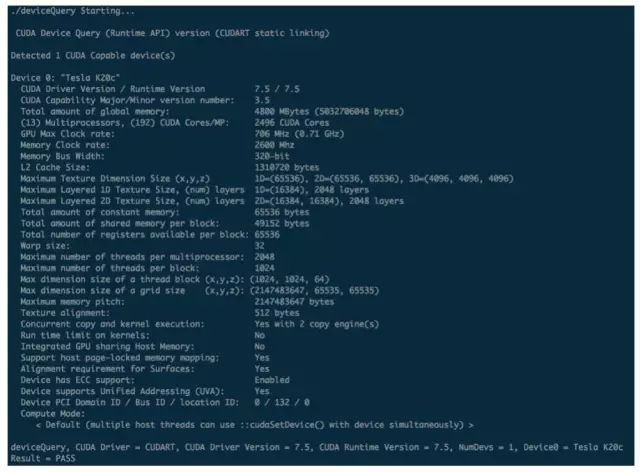
图四
安装 nvidia-docker,nvidia-docker 是 NVIDIA 官方为了让 NVIDIA GPU 与 Docker 容器兼容而封装的 Docker Cli – nvidia-docker。可以在 https://github.com/NVIDIA/nvidia-docker/wiki#quick-start找到nvidia-docker 相应的 Ubuntu,CentOS 和 二进制安装包。对于 CentOS 来说,大致步骤如下:
# Install nvidia-docker and nvidia-docker-plugin
wget –P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.0-rc.3/nvidia-docker-1.0.0.rc.3-1.x86_64.rpm
sudo rpm -i /tmp/nvidia-docker*.rpm && rm /tmp/nvidia-docker*.rpm
sudo systemctl start nvidia-docker
# Test nvidia-smi
nvidia-docker run --rm nvidia/cuda:7.5 nvidia-smi
如果设置正常,会得到与第3步截图同样的内容。
为了环境一致性,需要绕过 nvidia-docker 直接使用原生的 Docker 命令:
docker run `curl -s http://localhost:3476/docker/cli` --rm nvidia/cuda:7.5 nvidia-smi
或者:
docker run --volume-driver=nvidia-docker --volume=nvidia_driver_352.39:/usr/local/nvidia:ro --device=/dev/nvidiactl --device=/dev/nvidia-uvm --device=/dev/nvidia0 --rm nvidia/cuda:7.5 nvidia-smi
这里参考了 https://github.com/NVIDIA/nvidia-docker/wiki/Internals#enabling-gpu-support-in-your-application 。
集群设置
真实环境中,我们为用户部署了企业版数人云,有些技术细节不便展开。但只使用开源的 Apache Mesos 组件丝毫不会影响集群核心功能的使用。在网络上已经有很多 Apache Mesos,Marathon 和 Docker 安装配置的文章,这里不再花费篇幅介绍。
如果想要更多feature的调度器,纯命令行mesos scheduler-- https://github.com/Dataman-Cloud/swan 是个不错的选择。
当然,如果感觉 Mesos 的配置运维繁复,推荐大家尝试 Crane (https://github.com/Dataman-Cloud/crane),它是基于 Swarmkit 的容器控制面板,上手容易,安装操作都非常简捷。
最终我们应该可以得到一个 workable 的 Mesos 集群环境。
两个深度学习的Docker镜像
应用户要求,在https://github.com/NVIDIA/nvidia-docker 的 CUDA docker image 基础之上,我又制作了两个包含更多深度学习组件的 Docker 镜像 2breakfast/caffe-sshd:0.14 和 2breakfast/deeplearning:allinone , 你可以在 https://hub.docker.com/r/2breakfast/caffe-sshd/ 和 https://hub.docker.com/r/2breakfast/deeplearning/ 找到相应的 docker image 及 Dockerfile 链接。
2breakfast/caffe-sshd:0.14
包含 caffe,sshd 服务。用户可以ssh到相应的docker容器里面使用caffe。可以直接通过命令来测试该 image:
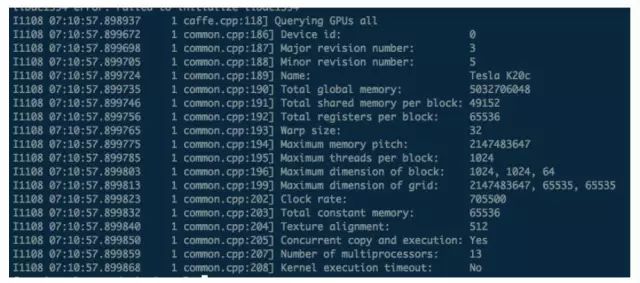
docker run --volume-driver=nvidia-docker --volume=nvidia_driver_352.39:/usr/local/nvidia:ro --device=/dev/nvidiactl --device=/dev/nvidia-uvm --device=/dev/nvidia0 --rm 2breakfast/caffe-sshd:0.14 caffe device_query -gpu all
如果运行正常,可以大致得到如下结果:
2breakfast/deeplearning:allinone
除上述 caffe,sshd 之外,又打包了 Tensorflow, theano, jupyter 等。
通过 Marathon 发布 2breakfast/deeplearning:allinone
下面是获取相应 json 文件并在Marathon 上进行部署的命令。
wget https://raw.githubusercontent.com/vitan/deeplearning-dockerfile/master/deploy-deeplearning.json
curl -k -XPOST -d @deploy-deeplearning.json -H "Content-Type: application/json" http://MARATHON_IP_ADDRESS:8080/v2/apps
部署成功后,可以通过 marathon ui 给出的访问地址,ssh 登录到容器内部来使用深度学习组件。譬如:
ssh –p 13452 [email protected]
密码:password ,即可访问。目前容器的默认 ssh account:root , password:password 。
另外,jupyter web 服务并不是默认启动,需要用户手动启动它。
小结:遗留问题
用户数据存储及隔离
在运行深度学习算法时,不可避免需要操纵数据。目前的方案是:主机目录 /mnt/data 映射到了容器目录 /mnt/data ,用户需要将持久化保持的数据放到该目录的某个文件下。而主机目录 /mnt/data 是个 nfs 目录,集群节点通过nfs将 /mnt/data 中的数据汇聚到了同一台 server,该 server 上的相应目录是一个 ceph block。
该方案最大的问题是 /mnt/data 目录里面的文件没有隔离,只能要求用户建立各自的 home 目录来放置自己的文件。未来计划通过 LDAP 账户集成,将数人云企业版账户和 ceph 目录上的 account 打通,在 ceph 上为不同的 LDAP 账户建立不同的 home 目录并设置相应读写权限,实现隔离。
3476 端口占用
nvidia-docker 会启动一个 web 服务并占用每个节点的端口 3476,这就需要集群保留端口 3476 资源。在我们的场景中,直接使用 localhost:3476 获取信息, 未来考虑将其设置为 unix://**nvidia-docker.sock。
让 Mesos 像管理 CPU 资源一样来管理 GPU 资源
Mesos在1.0版本 https://github.com/apache/mesos/blob/master/docs/gpu-support.md 实现了对GPU资源的管理。其参考了 nvidia-docker 的做法,将许多设置内置到了 mesos 中,未来考虑 enable 这部分功能以简化配置。
数人云 Mesos 调度器 Swan 现已开源,欢迎贡献 Star&Fork,点击“阅读原文”查看源码

高可用架构主办 GIAC 全球互联网架构大会特别推出「容器与云平台」、「大数据及算法」专题,议题方向包括美团、京东、hulu、华为等公司在容器、公有云、人工智能、机器学习方面的实践经验。现在购买还可以享受 7 折早鸟票,双日套票最低仅需 1,260 元,识别二维码了解详细议程。
