MySQL之索引
MySQL之索引
-
- 索引的本质
- 索引的优势和劣势
-
- 优势
- 劣势
- MySQL的索引
-
- Btree 索引
- B+tree 索引
- B+Tree 与 B-Tree 的区别
- B+Tree的优势
- 聚簇索引和非聚簇索引
- 时间复杂度
- 索引的分类
-
- 创建索引
- 查看索引
- 删除索引
- 索引创建的条件
-
- 创建索引
- 无需创建索引
- 推荐博客
索引的本质
索引(Index)是排好序的,能够快速查找数据的数据结构,能够帮助 MySQL 高效获取数据。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
下图是一种可能的索引方式:
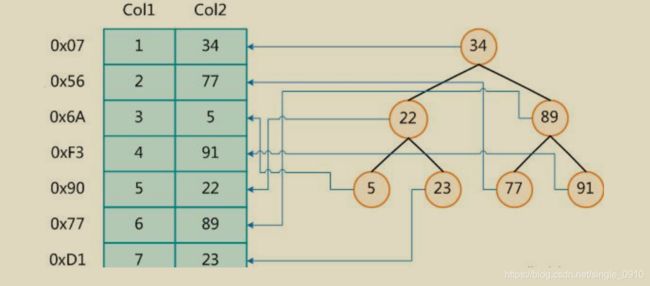
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址。
为了加快 Col2 的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录的地址指针,这样就可以运用 二叉查找在一定的复杂度内获取到相应数据,从而快速检索出符合条件的记录。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
索引如果没有特别指明,都是指B-Tree(多路搜索树,并不一定是二叉树)结构组织的索引。
其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引。
除了B+树索引,还有哈希索引。
索引的优势和劣势
优势
- 提高数据检索的效率,降低磁盘IO成本
- 数据排序,降低CPU消耗
劣势
- 索引本质也是一张表,保存着索引字段和指向实际记录的指针,所以也要占用数据库空间,一般而言,索引表占用的空间是数据表的1.5倍
- 索引虽然能提高查询速度,但是会降低表的更新速度,因为更新数据时,也要更新索引
MySQL的索引
Btree 索引
MySQL 使用的是 Btree 索引。
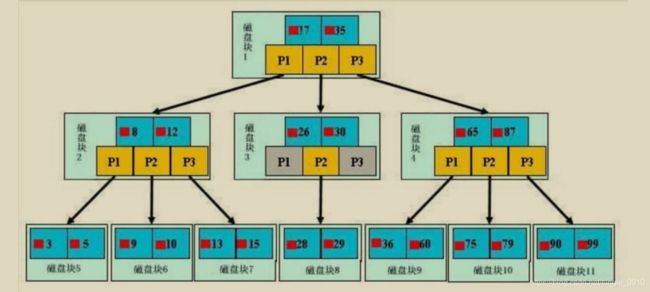
【初始化介绍】
浅蓝色的块称之为磁盘块,由数据项(深蓝色所示)和指针(黄色 所示)组成。
磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3, P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。
真实数据存在于叶子节点即 3、5、9、10、13、15、28、29、36、60、75、79、90、99。
非叶子节点不存储真实数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中。
【查找过程】
如果要查找数据项 29,那么首先把磁盘块 1 由磁盘加载到内存,此时发生一次 IO。
在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间因为非常短(相比磁盘IO)可以忽略不计。通过磁盘块 1 的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次 IO。
29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指 针,通过指针加载磁盘块 8 到内存,发生第三次 IO。
同时内存中做二分查找找到 29,结束查询,总计三次 IO。
B+tree 索引

B+Tree 与 B-Tree 的区别
- B-树的关键字和记录是放在一起的,叶子节点可以看作外部节点,不包含任何信息;B+树的非叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。
- 在 B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在
- B+树中每个记录 的查找时间基本相同,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。从这个角度看 B- 树的性能好像要比 B+树好,而在实际应用中却是 B+树的性能要好些。因为 B+树的非叶子节点不存放实际的数据, 这样每个节点可容纳的元素个数比 B-树多,树高比 B-树小,这样带来的好处是减少磁盘访问次数。尽管 B+树找到 一个记录所需的比较次数要比 B-树多,但是一次磁盘访问的时间相当于成百上千次内存比较的时间,因此实际中 B+树的性能可能还会好些,而且 B+树的叶子节点使用指针连接在一起,方便顺序遍历(例如查看一个目录下的所有 文件,一个表中的所有记录等),这也是很多数据库和文件系统使用 B+树的缘故。
B+Tree的优势
- B+树的磁盘读写代价更低
- B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对 B 树更小。如果把所有同一内部结点 的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就 越多。相对来说 IO 读写次数也就降低了
- B+树的查询效率更加稳定,由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须 走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
聚簇索引和非聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。术语‘聚簇’表示数据行和相邻的键值聚簇的存储 在一起。如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。

聚簇索引的好处
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不不用从多 个数据块中提取数据,所以节省了大量的 io 操作。
聚簇索引的限制
- 对于 mysql 数据库目前只有 innodb 数据引擎支持聚簇索引,而 Myisam 并不支持聚簇索引。 由于数据物理存储排序方式只能有一种,所以每个 Mysql 的表只能有一个聚簇索引。一般情况下就是 该表的主键。 为了充分利用聚簇索引的聚簇的特性,所以 innodb 表的主键列尽量选用有序的顺序 id,而不建议用 无序的 id,比如 uuid。
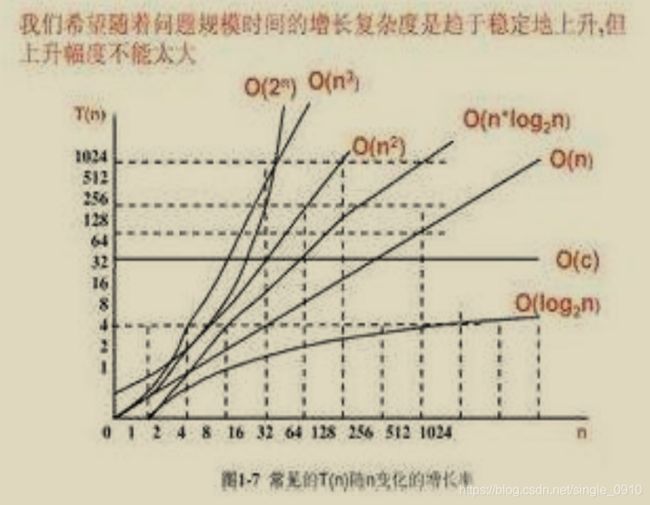
时间复杂度
同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的 目的在于选择合适算法和改进算法。 时间复杂度是指执行算法所需要的计算工作量,用大 O 表示记为:O(…)

索引的分类
常见的索引类型有:主键索引、唯一索引、普通索引、全文索引、组合索引等
创建索引
- 主键索引:根据主键建立的索引,
不允许重复,不允许空值
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
- 唯一索引: 用来建立索引的列的值必须是唯一的,
允许空值
ALTER TABLE 'table_name' ADD UNIQUE index_name('col');
- 普通索引:用表中的普通列构建的索引,没有任何限制
ALTER TABLE 'table_name' ADD INDEX index_name('col');
- 全文索引:用大文本对象的列构建的索引
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
- 组合索引:用多个列组合构建的索引,这多个列中的值不允许有空值
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
查看索引
SHOW INDEX FROM 'table_name'
删除索引
DROP INDEX index_name ON 'table_name'
索引创建的条件
创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 与其他表关联的字段,外键关系应该创建索引
- 查询中排序的字段
- 查询中统计的字段或者分组字段
无需创建索引
- 数据表记录太少
- 频繁更新的字段(如果创建索引,每当更新字段都会更新索引)
- 数据重复且分布平均的字段,不宜创建索引(性别字段,国籍字段等)

推荐博客
- https://blog.csdn.net/tongdanping/article/details/79878302
- https://blog.csdn.net/olizxq/article/details/82313489
- https://blog.csdn.net/weixin_43378396/article/details/90447750