【论文精读46】Attention Is All You Need
贴一下汇总贴:论文阅读记录
论文链接:《Attention Is All You Need》
一、摘要
主导序列转导模型基于包括编码器和解码器的复杂递归或卷积神经网络。性能最好的型号还通过一种注意力机制连接编码器和解码器。我们提出了一个新的简单的网络架构,变压器,完全基于注意力机制,完全免除了递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具可并行性,并且需要更少的训练时间。我们的模型在WMT 2014年英语-德语翻译任务中达到28.4 BLEU,比现有的最佳结果(包括合奏)提高了2 BLEU以上。在WMT 2014年英语到法语翻译任务中,我们的模型在八个图形处理器上训练3.5天后建立了新的单一模型最先进的BLEU评分41.8,这是文献中最佳模型训练成本的一小部分。我们表明,通过将该转换器成功地应用于具有大量和有限训练数据的英语选区解析,它可以很好地推广到其他任务。
二、Introduction
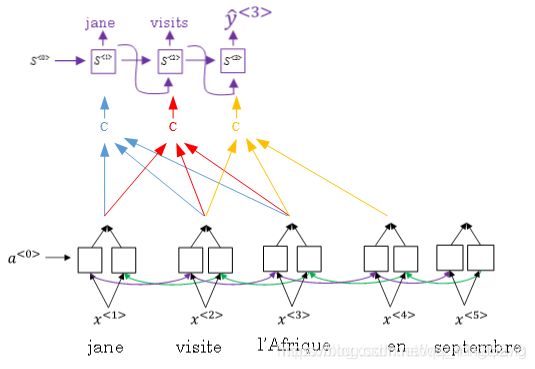
上面的这种结构的弊端: 就是需要递归迭代运行,没法并行化,这样对于很长的句子来说,很可能出现梯度消失的情况,并且计算量也很大,速度比较慢。所以需要改进。
Attention是利用局部聚焦的思想去建立注意力模型,但目前这样的机制都是和RNN连接。(self-attention, 有时也称为内注意,是一种将单个序列的不同位置联系起来以计算序列表示的注意机制。)
所以提出了一种Transformer模型,这种模型不用RNN或者说CNN这种递归机制,而是完全依赖于Attention。
三、模型介绍
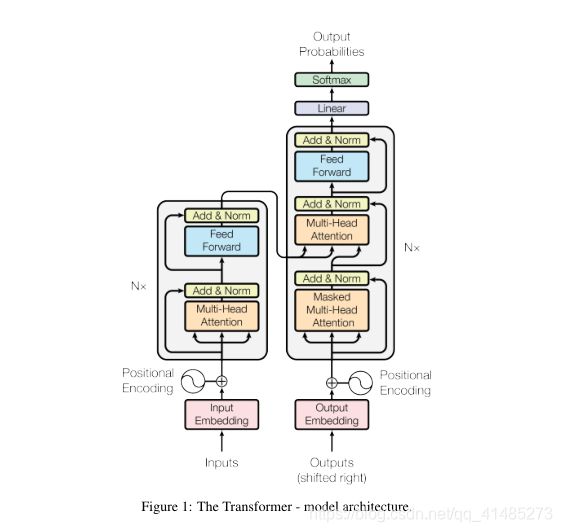
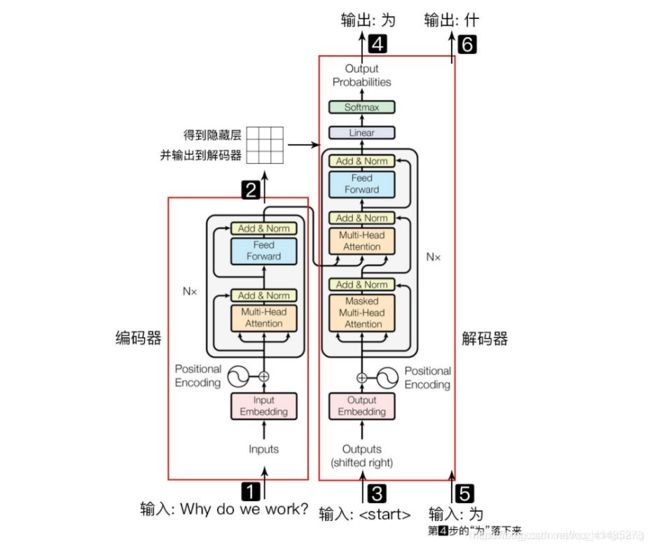
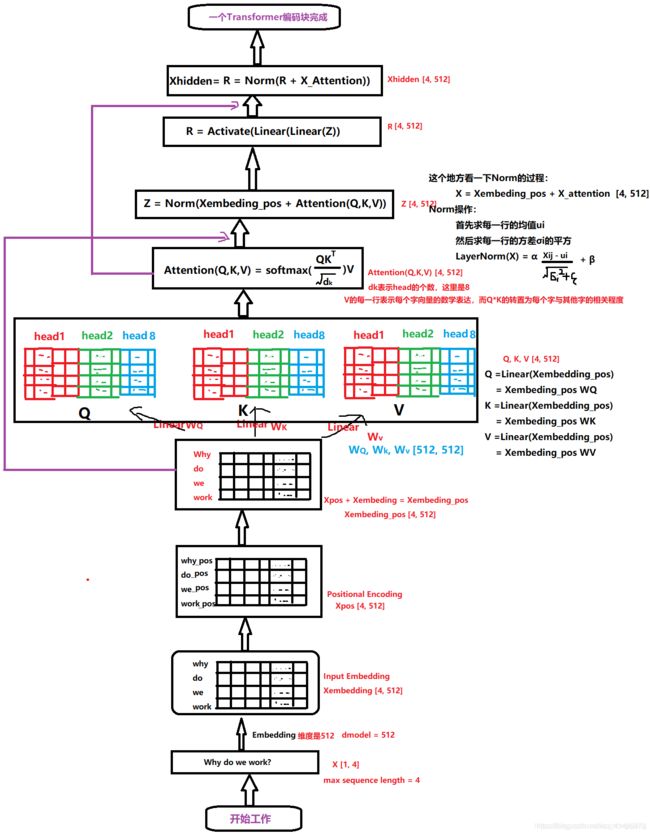
从这个结构的宏观角度上,我们可以看到Transformer模型也是用了Encoder-Decoder结构,编码器部分负责把自然语言序列映射成为隐藏层(就上面那个九宫格),含有自然语言序列的数学表达,然后解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,比如情感分类,命名实体识别,语义关系抽取,机器翻译,摘要生成等等。
先简单说一下上面的结构的工作流程:
比如我做一个机器翻译(Why do we work?) -> 为什么要工作?
- 输入自然语言序列: Why do we work?
- 编码器输出的隐藏层是Why do we work的一种数学表示,类似于提取了每一个词的信息,然后汇总,转换成了这句话的数学向量。然后输入到解码器
- 输入符号到解码器
- 就会得到第一个字“为”
- 将得到的第一个字“为”落下来再输入到编码器
- 得到第二个字“什”
- 将得到的第二个字落下来输入,得到“么”,重复,直到解码器输出, 翻译完成。
(一)编码器部分的工作细节
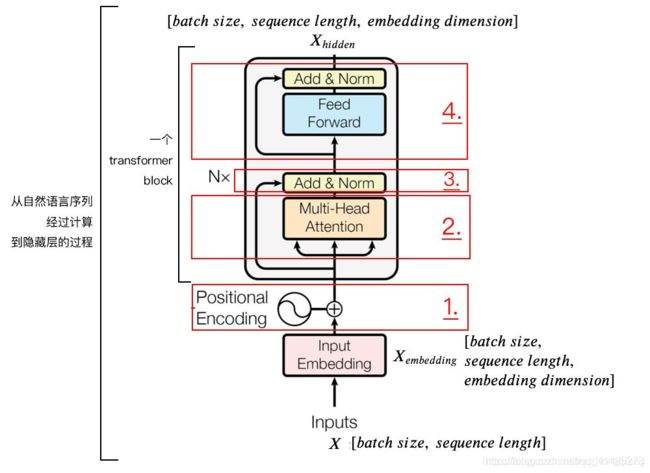
编码器部分是由N个transformer block堆叠而成的,我们就拿一个transformer block来进一步观察,每一个transformer block又有两个子层,第一个是多头注意力部分,第二个是feed-forward部分。
我们输入句子:Why do we work? 的时候,它的编码流程进一步细化:
- 首先输入进来之后,经过Input Embedding层每个字进行embedding编码(这个后面会说),然后再编入位置信息(position Encoding),形成带有位置信息的embedding编码。
- 然后进入多头注意力部分,这部分是多角度的self-attention部分,在里面每个字的信息会依据权重进行交换融合,这样每一个字会带上其他字的信息(信息多少依据权重决定),然后进入feed-forward部分进行进一步的计算,最后就会得到输入句子的数学表示了。
- 位置嵌入
transformer中的位置嵌入
- 多头注意力机制
transformer中的多头注意力机制
- 前馈神经网络(FeedForward)
我们上面通过多头注意力机制得到了Z,下面就是把Z再做两层线性变换,然后relu激活就得到最后的R矩阵了。(相当于一个两层的神经网络)
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=\max (0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
- Layer Normalization和残差连接
-
残差连接
我们在上一步得到了经过注意力矩阵加权之后的 V V V,也就是 A t t e n t i o n ( Q , K , V ) Attention(Q,K,V) Attention(Q,K,V),我们对它进行一下转置, 使其和 X e m b e d d i n g X_{embedding} Xembedding的维度一致, 也就是 [ b a t c h s i z e , s e q u e n c e l e n g t h , e m b e d d i n g d i m e n s i o n ] [batch\;size,sequence\;length,embedding\;dimension] [batchsize,sequencelength,embeddingdimension],然后把他们加起来做残差连接, 直接进行元素相加, 因为他们的维度一致: X e m b e d d i n g + A t t e n t i o n ( A , K , V ) X_{embedding}+Attention(A,K,V) Xembedding+Attention(A,K,V)在之后的运算里, 每经过一个模块的运算, 都要把运算之前的值和运算之后的值相加, 从而得到残差连接, 训练的时候可以使梯度直接走捷径反传到最初始层: X + S u b L a y e r ( X ) X+SubLayer(X) X+SubLayer(X) -
LayerNorm
L a y e r N o r m a l i z a t i o n LayerNormalization LayerNormalization的作用是把神经网络中隐藏层归一为标准正态分布, 也就是 i . i . d i.i.d i.i.d独立同分布, 以起到加快训练速度, 加速收敛的作用: μ j = 1 m ∑ i = 1 m x i j \mu_j=\frac1m\sum_{i=1}^mx_{ij} μj=m1i=1∑mxij上式中以矩阵的行(row)为单位求均值 σ j 2 = 1 m ∑ i = 1 m ( x i j − μ j ) 2 \sigma_j^2=\frac1m\sum_{i=1}^m(x_{ij}-\mu_j)^2 σj2=m1i=1∑m(xij−μj)2上式中以矩阵的行(row)为单位求方差 L a y e r N o r m ( x ) = α ⊙ x i j − μ j σ i 2 + ϵ + β LayerNorm(x)=\alpha \odot\frac{x_{ij}-\mu_j}{\sqrt{\sigma_i^2+\epsilon}}+\beta LayerNorm(x)=α⊙σi2+ϵxij−μj+β然后用每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值, ϵ \epsilon ϵ是为了防止除0;之后引入两个可训练参数 α , β \alpha,\beta α,β来弥补归一化的过程中损失掉的信息, 注意 ⊙ \odot ⊙表示元素相乘而不是点积, 我们一般初始化 α \alpha α为全1,而 β \beta β为全0。
所以一个Transformer编码块做的事情如下:
两个细节
- 第一个细节就是上面只是展示了一句话经过一个Transformer编码块之后的状态和维度,但我们实际工作中,不会只有一句话和一个Transform编码块,所以对于输入来的维度一般是[batch_size, seq_len, embedding_dim], 而编码块的个数一般也是多个,不过每一个的工作过程和上面一致,无非就是第一块的输出作为第二块的输入,然后再操作。
- Attention Mask的问题, 因为如果有多句话的时候,句子都不一定一样长,而我们的seqlen肯定是以最长的那个为标准,不够长的句子一般用0来补充到最大长度,这个过程叫做padding。
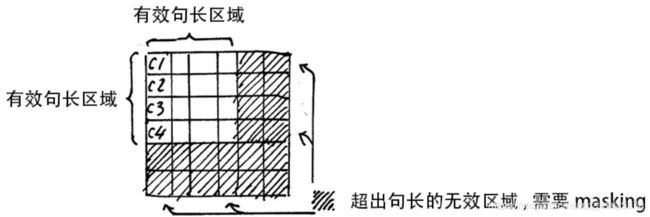
但这时在进行softmax的时候就会产生问题, 回顾softmax函数 σ ( z ) i = e Z i ∑ j = 1 K e Z j \sigma(z)_i=\frac{e^{Z_i}}{\sum_{j=1}^Ke^{Z_j}} σ(z)i=∑j=1KeZjeZi, e 0 e^0 e0是1, 是有值的, 这样的话softmax中被padding的部分就参与了运算, 就等于是让无效的部分参与了运算, 会产生很大隐患, 这时就需要做一个mask让这些无效区域不参与运算, 我们一般给无效区域加一个很大的负数的偏置, 也就是: z i l l e g a l = z i l l e g a l + b i a s i l l e g a l b i a s i l l e g a l → − ∞ e z i l l e g a l → 0 z_{illegal}=z_{illegal}+bias_{illegal}\\bias_{illegal}\rightarrow-\infty\\e^{z_{illegal}}\rightarrow0 zillegal=zillegal+biasillegalbiasillegal→−∞ezillegal→0经过上式的masking我们使无效区域经过softmax计算之后还几乎为0,这样就避免了无效区域参与计算。
最后通过上面的梳理,我们解决了Transformer编码器部分,下面看看Transformer Encoder的整体的计算过程:
- 字向量与位置编码: X = E m b e d d i n g L o o k u p ( X ) + P o s i t i o n a l E n c o d i n g X ∈ R b a t c h s i z e ∗ s e q . l e n . ∗ e m b e d . d i m . X=EmbeddingLookup(X)+PositionalEncoding\\X\in\R^{batch\;size*seq.len.*embed.dim.} X=EmbeddingLookup(X)+PositionalEncodingX∈Rbatchsize∗seq.len.∗embed.dim.
- 自注意力机制: Q = L i n e a r ( X ) = X W Q K = L i n e a r ( X ) = X W K V = L i n e a r ( X ) = X W V X a t t e n t i o n = S e l f A t t e n t i o n ( Q , K , V ) Q=Linear(X)=XW_Q\\K=Linear(X)=XW_K\\V=Linear(X)=XW_V\\X_{attention}=SelfAttention(Q,K,V) Q=Linear(X)=XWQK=Linear(X)=XWKV=Linear(X)=XWVXattention=SelfAttention(Q,K,V)
- 残差连接与 L a y e r N o r m a l i z a t i o n Layer\;Normalization LayerNormalization X a t t e n t i o n = X + X a t t e n t i o n X a t t e n t i o n = L a y e r N o r m ( X a t t e n t i o n ) X_{attention}=X+X_{attention}\\X_{attention}=LayerNorm(X_{attention}) Xattention=X+XattentionXattention=LayerNorm(Xattention)
- F e e d F o r w a r d FeedForward FeedForward,其实就是两层线性映射并用激活函数激活,比如ReLU: X h i d d e n = A c t i v a t e ( L i n e a r ( L i n e a r ( X a t t e n t i o n ) ) ) X_{hidden}=Activate(Linear(Linear(X_{attention}))) Xhidden=Activate(Linear(Linear(Xattention)))
- 重复第3步: X h i d d e n = X a t t e n t i o n + X h i d d e n X h i d d e n = L a y e r N o r m ( X h i d d e n ) X h i d d e n ∈ R b a t c h s i z e ∗ s e q . l e n . ∗ e m b e d . d i m . X_{hidden} = X_{attention}+X_{hidden}\\X_{hidden} = LayerNorm(X_{hidden})\\X_{hidden}\in \R^{batch\;size*seq.len.*embed.dim.} Xhidden=Xattention+XhiddenXhidden=LayerNorm(Xhidden)Xhidden∈Rbatchsize∗seq.len.∗embed.dim.
- 这样一个Transformer编码块就执行完了, 得到了 X h i d d e n X_{hidden} Xhidden之后,就可以作为下一个Transformer编码块的输入,然后重复2-5执行,直到N个编码块。
(二)解码器部分的工作细节

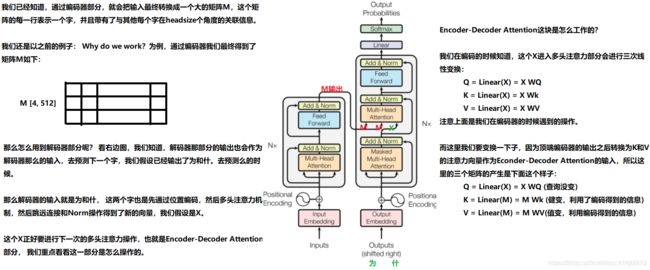
说完了编码器,看上面这张图,我们发现编码器和解码器其实差不多,只不过解码器部分多了一个Encoder-Decoder Attention, 知道编码器是怎么工作的,也基本会解码器了,但是还是来看几个细节。
编码器通过处理输入序列开启工作。顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集(也就是编码器最终输出的那个从多角度集自身与其他各个字关系的矩阵,比如记为M)。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适。
在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素(先输出为,为落下去,输出什, 什落下去输出么)
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
而那些解码器中的自注意力层表现的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置给隐去(把它们设为-inf)。
这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它下面的层来创造查询矩阵,并且从编码器的输出中取得键/值矩阵。这个地方简单说一下细节。
(三)最终的线性变换和softmax层
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
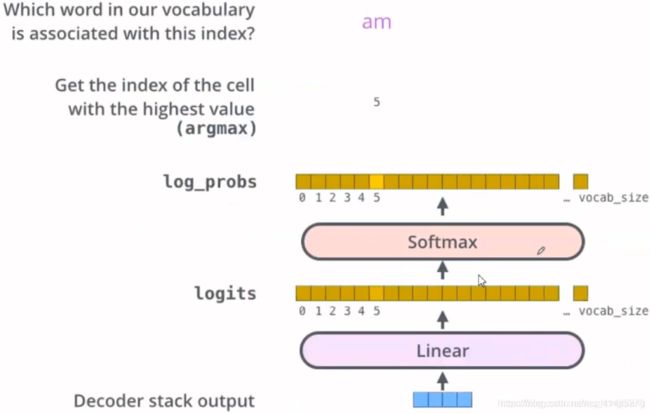
这张图片从底部以解码器组件产生的输出向量开始。之后它会转化出一个输出单词。
四、Training
我们已经过了一遍完整的transformer的前向传播过程,那我们就可以直观感受一下它的训练过程。
在训练过程中,一个未经训练的模型会通过一个完全一样的前向传播。但因为我们用有标记的训练集来训练它,所以我们可以用它的输出去与真实的输出做比较。
为了把这个流程可视化,不妨假设我们的输出词汇仅仅包含六个单词:“a”, “am”, “i”, “thanks”, “student”以及 “”(end of sentence的缩写形式)。
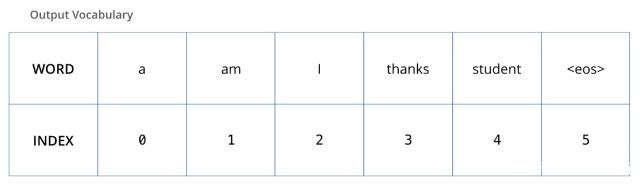
我们模型的输出词表在我们训练之前的预处理流程中就被设定好。
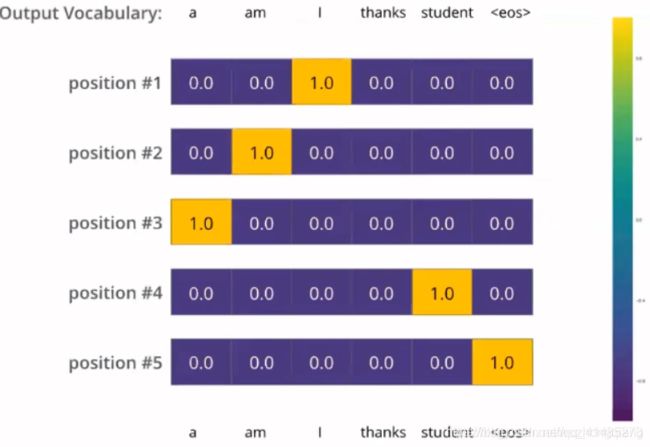
一旦我们定义了我们的输出词表,我们可以使用一个相同宽度的向量来表示我们词汇表中的每一个单词。这也被认为是一个one-hot 编码。所以,我们可以用下面这个向量来表示单词“am”:
(一)损失函数
那么我们的损失函数是什么呢?
这里我们使用的是交叉熵损失函数因为模型的参数(权重)都被随机的生成,(未经训练的)模型产生的概率分布在每个单元格/单词里都赋予了随机的数值。我们可以用真实的输出来比较它,然后用反向传播算法来略微调整所有模型的权重,生成更接近结果的输出。
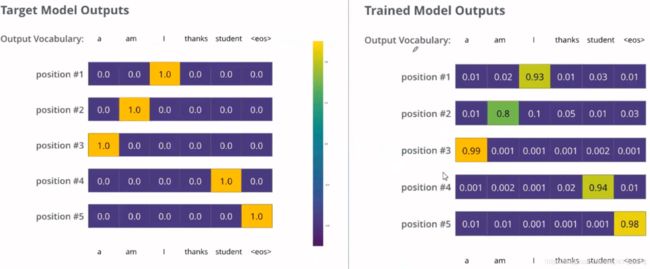
左边就是我们想要的模型输出,右边是我们训练的模型的输出,是一些概率的形式,训练的时候,我们就先采用前向传播得到一个输出,然后采用交叉熵损失比较模型的输出和真实的期望值,得到梯度反向传播回去更新参数。
(二)训练小技巧
- L a b e l S m o o t h i n g ( r e g u l a r i z a t i o n ) LabelSmoothing(regularization) LabelSmoothing(regularization)
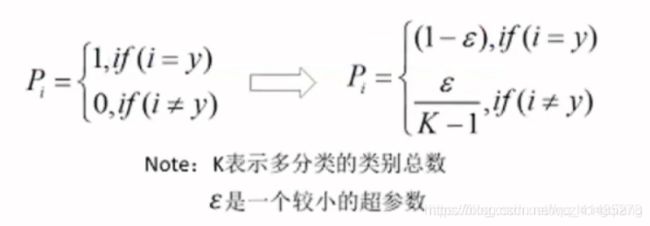
这个是什么意思呢? 就是我们准备我们的真实标签的时候,最好也不要完全标成非0即1的这种情况,而是用一种概率的方式标记我们的答案。这是一种规范化的方式。
比如上面我们的答案
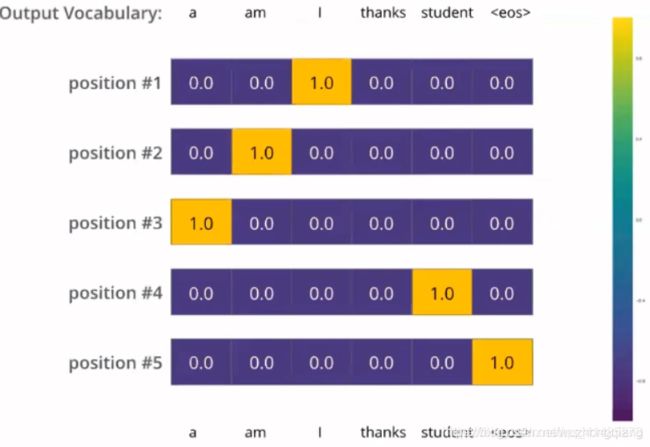
我们最好不要标成这种形式,而是比如position #1这个,我们虽然想让机器输出 I I I
我们可以 I I I对应的位置是0.9, 剩下的0.1其他五个地方平分,也就是
position #1 0.02 0.02 0.9 0.02 0.02 0.02
- Noam Learning Rate Schedule
这是一种非常重要的方式,如果不用这种学习率的话,可能训练不出一个好的Transformer。
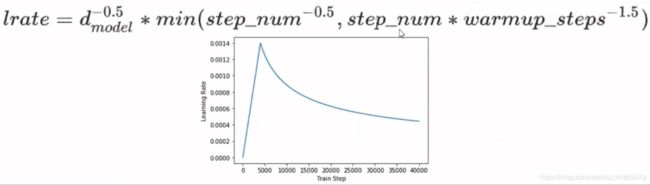
简单的说,就是先让学习率线性增长到某个最大的值,然后再按指数的方式衰减。
五、Conclusion
这篇文章最经典的核心就是transformer结构,这种结构完全依赖于注意力机制,取代了基于Encoder-Decoder的循环层,并且引入了位置嵌入,Multi-Head Attention机制。
下面分析一下Transformer的特性:
- 优点:
(1) 每一层的计算复杂度比较低
(2) 比较利于并行计算
(3) 模型可解释性比较高(不同单词之间的相关性有多大) - 缺点:
(1) 有些RNN轻易可以解决的问题Transformer没做到,比如复制string,或者推理碰到的sequence长度比训练时更长(因为碰到了没见到过的position embedding)
(2) RNN图灵完备,Transformer不是。 图灵完备的系统理论是可以近似任意Turing计算机可以解决的算法。