机器学习:你真的分得清频率、概率、几率和似然吗?
机器学习:你真的分得清频率、概率、几率和似然吗?
- 1 从一个问题开始
- 2 频率和概率
- 3 先验概率和后验概率
- 4 什么是几率?
- 5 回到问题
- 6 什么是似然?
- 7 写在最后
1 从一个问题开始
机器学习中,著名的Logistic分类回归算法,使用概率还是几率建模?
事实上国内没有很好的文章辨析概率和几率的区别,请各位带着问题往下看,相信会有所收获。
2 频率和概率
先给出定义。
频率(frequency)是当前已完成的有限次实验中,事件 X X X发生的次数占总实验次数的比例,是经验值。根据伯努利大数定律:当实验次数足够大时,事件 X X X发生的频率将趋于稳定值,此稳定值称为概率(Probability),概率是给定模型参数后,对样本合理性的度量,而不涉及任何观测数据。
对未来的预测来源于过往经验,而沟通经验与未来的工具就是概率——所谓事件 X X X发生可能性大小,就是事件 X X X在历史中发生的频率大小!
引例1.1:抛掷一枚质地均匀的硬币并统计其向上、向下的次数。统计结果显示该硬币在100次抛掷实验中有60次向上,40次向下,求再掷1次硬币正面朝上的概率。
引例1.1中频率 f = 60 % f=60\% f=60%而概率 P = 50 % P=50\% P=50%。
3 先验概率和后验概率
引例1.2:如图所示,假设每次实验时随机从某个盒子里挑出一个球。随机变量 A A A表示挑出的盒子,且设 P ( A = b l u e ) = 0.6 P\left( A=blue \right) =0.6 P(A=blue)=0.6;随机变量 B B B表示挑中的球,问:
(a) P ( A = r e d ) = ? P\left( A=red \right) =? P(A=red)=? ;
(b) 在挑中蓝色盒子的条件下, P ( B = g r e e n ) = ? P\left( B=green \right) =? P(B=green)=?;
(c) 已知挑出绿色的球,则其是从红色盒子中挑出的概率有多大?
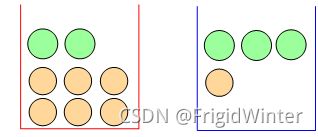
可以得到如下答案:
(a) P ( A = r e d ) = 0.4 P\left( A=red \right) =0.4 P(A=red)=0.4
(b) P ( B = g r e e n ∣ A = b l u e ) = P ( B = g r e e n , A = b l u e ) P ( A = b l u e ) = 3 4 P\left( B=green|A=blue \right) =\frac{P\left( B=green,A=blue \right)}{P\left( A=blue \right)}=\frac{3}{4} P(B=green∣A=blue)=P(A=blue)P(B=green,A=blue)=43
(c) P ( A = r e d ∣ B = g r e e n ) = P ( B = g r e e n ∣ A = r e d ) P ( A = r e d ) P ( B = g r e e n ) = 2 11 P\left( A=red|B=green \right) =\frac{P\left( B=green|A=red \right) P\left( A=red \right)}{P\left( B=green \right)}=\frac{2}{11} P(A=red∣B=green)=P(B=green)P(B=green∣A=red)P(A=red)=112
先验概率也称边缘概率(marginal probability),指根据以往经验和分析,在实验或采样前就可以得到而不依赖于其他任何事件的概率,例如 P ( A = r e d ) = 0.4 P\left( A=red \right) =0.4 P(A=red)=0.4,其不依赖于任何事件(如取出绿球等),在实验前就可得出。
后验概率也称条件概率(conditional probability),指某事件(如实验或采样)已经发生,而与此相因果事件的概率,例如(Ab)(Ac)。
4 什么是几率?
对样本合理性的度量有两种方式:
(1) 以频度为核心的度量方式,关注频率的极限,此时称为概率,记为 P P P;
(2) 以信念(belief)为核心的度量方式,此时称为几率(odds),记为 O O O。所谓信念,是相比于样本不合理而言,有多大把握认为样本合理的直观度量,即
O = P 1 − P O=\frac{P}{1-P} O=1−PP
引例1.1中几率 O = 1 : 1 O=1:1 O=1:1说明无论再投掷多少次,仍然没有把握认为一定正面向上,此时若引入质地不均匀的硬币产生几率 O = 10 : 1 O=10:1 O=10:1,则可以直观地反映硬币正面向上比反面向上的可能性大得多。
概率或几率越大表明事件越有可能发生,因为它们对刻画样本合理性的本质相同。引入几率是因为其具有很多特殊性质,例如:
(1) 概率取值在0到1,但几率取值在0到正无穷,因此对几率取对数可以获得负无穷到正无穷范围的对称定义域,此时称为对数几率(log odds)。这种对称性被广泛应用于统计机器学习中,例如著名的Logistic回归分析;
(2) 几率更直观地反映了样本合理与不合理之间的置信差距,因此博彩行业引入赔率的概念来反应下注者对参赛者获胜的信心。
5 回到问题
Logistic分类回归算法,使用概率还是几率建模?
有了前面的铺垫,这个问题就很显然了。Logistic回归是联系函数取Sigmoid函数时的广义线性模型,化简后即得
f ( x ^ ( i ) ) = g − 1 ( w ^ T x ^ ( i ) ) ⇔ w ^ T x ^ ( i ) = ln f ( x ^ ( i ) ) 1 − f ( x ^ ( i ) ) f\left( \boldsymbol{\hat{x}}^{\left( i \right)} \right) =g^{-1}\left( \boldsymbol{\hat{w}}^T\boldsymbol{\hat{x}}^{\left( i \right)} \right) \Leftrightarrow \boldsymbol{\hat{w}}^T\boldsymbol{\hat{x}}^{\left( i \right)}=\ln \frac{f\left( \boldsymbol{\hat{x}}^{\left( i \right)} \right)}{1-f\left( \boldsymbol{\hat{x}}^{\left( i \right)} \right)} f(x^(i))=g−1(w^Tx^(i))⇔w^Tx^(i)=ln1−f(x^(i))f(x^(i))
对这个式子不熟悉的话可以等我后面进行Logistic分类回归算法的详解。
将上式中的 f ( x ) f(x) f(x)看作后验概率 p ( y i = 1 ∣ x ^ ( i ) ) p\left( y_i=1|\boldsymbol{\hat{x}}^{\left( i \right)} \right) p(yi=1∣x^(i))则等式右边就是对数几率,这是因为用几率可以获得负无穷到正无穷的对称定义域。所以回答文章开始的问题:Logistic分类回归算法,使用几率建模。
6 什么是似然?
概率与似然是站在两个角度上看待问题。假设样本集为 X X X,环境参数为 θ \theta θ
(1) 当环境参数 θ \theta θ已知时为概率问题:概率即是给定模型参数后,对样本合理性的描述,而不涉及任何观测数据。
(2) 当环境参数 θ \theta θ未知时为似然问题:似然即是给定样本观测数据,从而推测可能产生这个结果的环境参数。似然问题也称为逆概(Converse Probability)问题。
引例1.3:(a) 假设掷一枚硬币正面朝上概率为 θ = 0.5 \theta =0.5 θ=0.5,求掷10次硬币中有7次正面朝上的概率;(b) 有一个硬币有 θ \theta θ的概率正面朝上,为确定 θ \theta θ做如下实验:掷10次硬币得到一个正反序列——HHTTHTHHHH。
显然,(Qa)可以不依赖任何观测数据计算出 ,即最终的观测数据在0.117附近则认为是合理的;(Qb)则是通过观测数据构造似然函数来反推环境参数:事实上,这符合人类认识的规律——即在不断地实践中获得观测数据,再从观测数据中总结经验规律(对应于模型参数)。在机器学习中,也往往是需要机器根据已有的数据学到相应的分布——即确定由 θ \theta θ决定的模型。
似然认为 θ \theta θ是随机变量其实是贝叶斯学派的观点,关于贝叶斯方法的具体分析可以参考机器学习:详解贝叶斯网络+例题分析。
7 写在最后
本文完整地辨析了统计机器学习理论中常用的频率、概率、几率、似然概念,帮助各位读者今后学习AI、ML理论知识。另外,本专栏后续会开放Python机器学习实战系列,基于周志华老师的西瓜书,对课后的编程题(例如LDA、DT等)逐一给出完整源码,欢迎订阅本专栏,也欢迎关注作者。