数据科学技能测试:快来看看你能通关吗?
全文共4067字,预计学习时长15分钟
图源:race.agency
是时候展现真正的技术了!
以下是26个数据科学的问题和供参考的答案。这些问题的难度和主题各不相同,但都与机器学习和数据科学相关。不管是大学生还是专业人士,都可以来测试(或更新)一下自己的技能!
你,都能答上来吗?
图源:Giphy
1.如何区分机器学习、人工智能和数据科学?(主题:通识)
人工智能这一术语涵盖范围广泛,主要涉及机器人学和文本分析等应用,并服务于商业和技术领域。机器学习隶属于人工智能,但其涉及领域较狭窄,且只用于技术领域。数据科学并不完全隶属于机器学习,而是利用机器学习来分析并做出预测,可用于商业领域。
2.什么是正态分布?(主题:统计学、词汇)
正态分布,也称为钟形曲线,指大多数实例聚集在中心,且实例数量随着距中心距离的增加而减少这种分布情况。严格来讲,统计学上,正态分布的定义是:66%的数据在平均值的一个标准差内,95%的数据在平均值的两个标准差内,99%的数据在平均值的三个标准差内。
图源:Wikipedia
3.什么是推荐系统?(主题:词汇)
推荐系统是信息过滤系统的一个子类,旨在预测用户对产品的偏好或评级。推荐系统广泛应用于电影、新闻、科研文章、产品、音乐等领域。
4.不看聚类,如何选择k均值聚类算法中的k值?(聚类算法)
k均值聚类算法中,k值的选取有两种方法。一种方法是手肘法,y轴指某个误差函数,x轴指聚类的数量,如果整个图的形状像一个手臂的话,那肘部对应的值就是最佳的聚类数量。
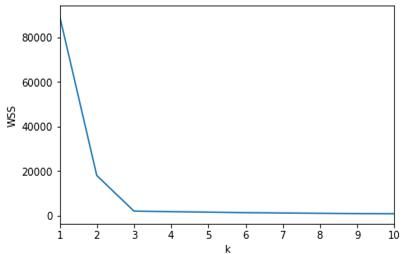
显然,在上图中,肘部对应的k值就是3。然而,如果曲线形状不够清晰,那就只能使用第二种方法,即轮廓系数法。轮廓系数法指用范围在-1到1之间的轮廓系数来描述每个簇的数量,系数越大的聚类通常则为最佳聚类数。
5.线性回归和逻辑回归有什么区别?(主题:回归与分类算法)
线性回归是一种统计技术,指将数据拟合到一条线上(或多元线性回归中的一个多维平面)。当目标值在连续尺度内时,就会发生回归。逻辑回归可由线性回归通过sigmoid函数转换而成,并会给出一组输入值为分类0和1的概率。
6. 一种测试的真阳性率为100%,假阳性率为5%。一个群体有千分之一的概率会在测试中出现这种情况。如果你有一个阳性测试,出现这种情况的概率有多大呢?(主题:分类率)
假设你正在接受一项疾病测试,如果你患有此病,测试结果会显示你已患病。但如果你未患病,5%的情况下,测试结果会显示你患有此病,95%的情况下,会显示你没有患病。
因此,在未患病的情况下,会有5%的误差。在1000人中,有1人会得到真正的阳性结果,而在剩下的999人中,5%的人会得到(假)阳性结果。大约50人会得到该病的阳性结果。

图源:unsplash
也就是说,在1000人中,即使只有1人患病,也会有51人的检测结果呈阳性。但即便如此,你的患病几率也只有2%。
7.梯度下降法总是收敛于同一点吗?(主题:神经网络)
不,梯度下降法并不总是收敛于同一点。由于误差空间中可能存在多个局部极小值,根据其特性(例如动量或权重),梯度下降法可能会在不同的地方结束。
8.如何通过box-cox变换改善模型性能?(主题:统计学、算法)
Box-cox变换指将数据按照一定次幂进行转换,例如将其平方、立方或开方(即1/2次方)。由于任何数的0次方永远是1,因此,box-cox变换中的“0次方”被认为是对数变换。
对数函数将指数函数放在线性尺度上,因而可以改善模型性能。也就是说,线性回归之类的线性模型在数据方面性能更优越。
此外,对函数进行平方和立方运算也有助于整理数据,或突出重点信息。
9.分析项目中的关键步骤有哪些?(主题:组织)
· 了解业务问题以及分析目标。
· 探索并熟悉数据。
· 清理数据(检测离群值、缺失值、转换变量等),准备好建模数据。
· 运行模型并对参数进行相应调整。
· 用新数据验证模型。
· 执行模型并得出相应结果。
10.什么是查全率和查准率?(主题:分类率)
查全率指“在所有的正样本中,有多少样本被分类为正样本”。查准率指“在所有被分类为正的样本中,有多少样本是真正的正样本”。
11.解释一下“维度诅咒”。(主题:数据)

图源:unsplash
“维度诅咒”指的是在分析具有许多特征的数据(高维数据)时出现的某些现象,而这些现象在普通的二维或三维空间中不会出现。随着维数增加,数据会变得极其稀疏,因而无法通过机器学习等模型对所有值进行有意义的计算。
值得注意的是,在极高维的空间中,两个样本间的欧氏距离非常小,因此,任何需要计算两点之间距离的统计方法或机器学习方法都不可行。(这也是为什么在高维图像识别中首选卷积神经网络的原因。)
12.在时间序列建模中,如何处理不同形式的季节性现象?(主题:时间序列)
通常在真实世界的时间序列数据中(比如,在玩具厂购买的泰迪熊),不同形式的季节性现象可能会相互干扰。
年度的季节性(如圣诞节前后的旺季和夏天的低谷期)可能会与每月、每周、甚至每天的季节性现象重叠。由于变量在不同时间段的平均值不同,导致时间序列具有非平稳性。
去除季节性的最好方法就是对时间序列进行差分,即取时间x中的一个日期与x减去季节性周期后(一年或一月等)两者间的差值。由于在前几个样本中,x减去季节性周期无法访问,因此丢失了一个季节性周期的原始数据。
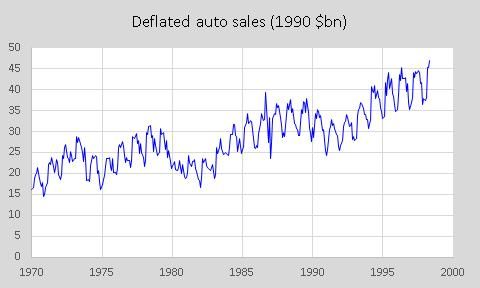
年度和月度季节性现象的一个例子
13.人们普遍认为假阴性不如假阳性。那么,假阳性不如假阴性的例子有什么?(主题:分类率、组织)
假设一家电商公司决定给可能会购买5000美元商品的顾客赠送一张1000美元的礼券。如果该公司通过模型计算出假阴性结果,那公司就(错误地)不会发送代金券,因为公司误认为该客户不会购买5000美元以上的商品。
虽然结果不妙,但公司并不亏损。如果公司将代金券发给结果呈假阳性的客户(误以为该客户会购买价值5000美元以上的商品),那些购买不足5000美元的人就会让公司亏损赔钱。
14.测试集和验证集的区别是什么?(主题:数据、组织)
测试集用于评估模型训练后的性能,而验证集用于在模型训练期间选择参数并防止训练集上出现过拟合。
图源:unsplash
15.你在什么情况下会使用随机森林算法,什么情况下会使用支持向量机算法(SVM)?(主题:算法)
SVM和随机森林是两种强大的分类算法。对于无离群的纯净数据,可以选择SVM;反之,则可以选择随机森林。
SVM(尤其是带有广泛参数搜索的SVM)需要进行更多的计算,因此如果内存有限的话,选择随机森林会更合适。此外,随机森林算法适用于多类问题,而SVM算法适应于高维问题,如文本分类。
16.你会用哪些方法来填补缺失的数据,如果填错会有什么后果?(主题:数据清理)
现实世界的数据往往会有缺失。填补这些数据的方法多种多样。彻底的处理方式就是删除具有NA 值的行。如果NA 值不是很多,并且数据充足,则这种方法可行;否则,则不可行。在现实世界的数据中,删除带有NA 值的行可能会消除部分可观察到的模式。
倘若上述方法不可行,也可以根据具体情况,选择其他方法来填充缺失数据,比如众数、中位数或平均值。
另一种方法是通过k最近邻算法(KNN)计算丢失数据的邻近数据,并选取这些邻近数据的平均值、中位数或众数来填补缺失数据。比起使用汇总值,这种方法灵活度更高,规范性更强。
如果填补数据的方法使用不当,可能会出现选择性偏差——模型的好坏与数据一致,如果数据有误,其模型也会受到影响。

图源:unsplash
17.什么是集成?集成有什么用?(主题:算法)
集成是对最终决定进行投票的算法组。集成会选出瑕不掩瑜的模型,但成功的模型必须是多样化的。也就是说,每个模型的缺点必须各不相同。研究表明,正确创建的集成,其性能往往远优于单分类器。
18.在将数据传递到线性回归模型前,需要对数据作哪些基本假设?(主题:算法)
数据应具有正态残差分布、误差的统计相关性以及线性。
19.贝叶斯估计和最大似然估计的区别是什么?(主题:算法)
在贝叶斯估计中,模型具有先前的数据知识。我们可以寻找多个参数,如5个gammas和5个lambdas来解释数据。在贝叶斯估计中,有多个模型可以做出多个预测(每对参数一个,其先验知识相同)。因此,如果想预测新的样本,只需计算预测的加权和就可以了。

图源:bjdataart
然而,最大似然估计不考虑先验概率,它与使用平坦先验的贝叶斯模型比较相似。
20. P值对数据来说意味着什么?(题目:统计学)
在统计学中,P值用于确定假设检验后结果的显著性,它可以帮助分析器得出结论。显著性水平往往在0到1之间。
· 如果p值小于0.05,说明拒绝零假设的理由充分,可以拒绝零假设。
· 如果P值大于0.05,说明拒绝零假设的理由不充分,不能拒绝零假设。
· 而0.05是临界值,表示两种情况都有可能发生。
21.何时使用均方误差(MSE)和平均绝对误差(MAE)?(主题:精确度测量)
MSE常用于“突出”较大的误差。由于x²的导数为2x,x越大,x与x-1的差值就越大。然而,MAE常用于输出可解释的结果。
因此,当结果不需要进行解释,而只是作为数字(可能用于模型之间的比较)时,可以选择MSE;但是当结果需要进行解释时(例如,模型平均下降4美元左右),选择MAE更佳。
22.什么是ROC曲线?什么是AUC?(主题:精确度测量)
ROC曲线描述的是模型的假阳性率与真阳性率之间的关系。完全随机预测的ROC曲线就是一条直对角线(图中的黑色虚线)。最靠近坐标轴的曲线就是最优模型。
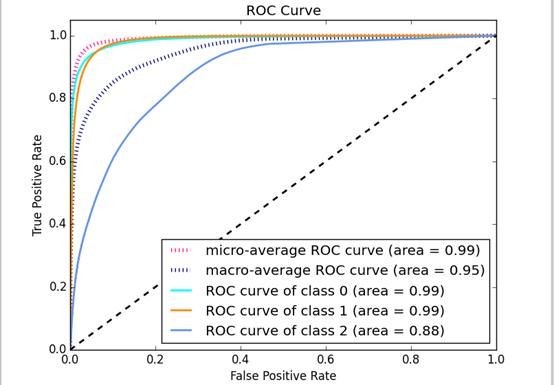
AUC是衡量ROC曲线与坐标轴之间距离的一项指标,即曲线下的面积。曲线下的面积越大,则性能越好。
23.解释一下偏差方差平衡,并列举高偏差和低偏差算法的示例。(主题:算法)
偏差指的是由于机器学习算法过度简化而在模型中引入的误差。偏差会导致欠拟合。如果在欠拟合时训练模型,模型会做出简化的假设,使目标函数更易于理解。
低偏差的机器学习算法有决策树、KNN、SVM等。高偏置的机器学习算法有线性回归和逻辑回归。
方差指的是由于机器学习算法较为复杂而在模型中引入的误差。有时模型会从训练数据集中学习噪声数据,导致在测试集中表现不佳。方差会导致高灵敏度和过拟合。
通常,当模型的复杂度增加时,模型中低偏差导致的误差就会减少。然而,当复杂度增加到某个特定点时,模型就会发生过拟合。
24.什么是PCA以及PCA有什么用?(主题:算法)
主成分分析(PCA)是一种降维方法,通过寻找n个正交向量来表示数据中的最大方差,其中n是数据降至的维度。n个向量可用作新数据的维度。PCA可以帮助加快机器学习算法的速度,或者用于高维数据的可视化。
25.为什么在复杂的神经网络中,Softmax非线性函数往往最后进行运算?(主题:神经网络)
这是因为Softmax非线性函数输入实数向量后会返回概率分布。设x是一个实数向量(正或负),那Softmax函数就会输出一个概率分布:每个元素都是非负的,且所有元素的和为1。
图源:unsplash
26.什么是TF/IDF向量化?(主题:NLP)
TF-IDF是术语“词频-逆文本频率指数”的缩写。它是一种数字统计方法,用以反映一个字词对语料库中一份文档的重要性。在信息检索和文本挖掘中,它常被用作权重因子。
TF-IDF值与字词在文档中出现的次数成正比增加,与字词在语料库中出现的频率成反比下降,这有助于在某些字词出现频繁时进行调整。
你做对了几个?这些问题覆盖主题广泛,从神经网络到数据清洗,从SVM到NLP,从分类率到统计学。不熟悉的话得好好复习啦!
留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)