MYSQL基础篇(分析语句在数据库内部的执行过程)
mysql的基础理解;
对于mysql,我自己刚开始接触的时候只是大致的理解,一些主从、双主、读写分离、群集的部署,底层的细微知识根本没了解到,前几天看了一个课程,在这分享一下,关于mysql基础的细微分析。
介绍两条语句。
- (1)查询语句在mysql数据库内部的执行过程
- (2)更新语句在mysql数据库内部的执行过程
把这两条语句拆解开来,慢慢分析,接下来进入正题。
1、mysql的查询语句。
大体来说,mysql分为两部分,一部分是server层,他的一些功能主要有,连接、查询缓存、分析器、优化器、执行器。一部分是储存引擎层,主要功能是储存和提取数据。
下面是一个mysql基本架构示意图:
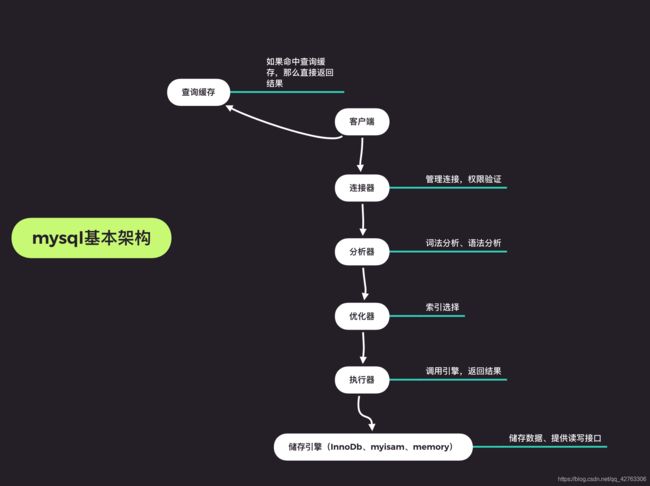
储存引擎的架构模式是插件式的,支持innodb、myisam等多个储存引擎,不过现在最常用的是innodb,他从mysql5.5.5版本之后就成了mysql的默认储存引擎,也就是说,当你创建表,输入create table 表名,没有指定储存引擎,那么默认的就是innodb,当然不同的储存引擎实现的功能不一样,储存方式也是不同,各有千秋吧。
(1)连接器
第一步 客户端数据命令连接到数据库服务,此时接待你的就是连接器,命令如下:
mysql -h(服务器IP地址) -P(数据库端口) -u(用户名) -p(密码)
当然这个密码也可以在-p后面输入,但是如果是生产服务器,不推荐这样,因为这样可能会导致你的密码泄漏。
连接命令中的mysql是客户端工具,用来和服务器建立连接,在完成了经典的tcp/ip之后,连接器就开始验证你的身份,这时候输入密码就会正常登入数据库(用户名是一开始就指定的,不过在输密码的时候是不可见的,不要以为一直没有输入,而且不能删除,一次输错,重新连接)
如果密码验证通过,那么数据库会根据权限表查询此连接的权限,后面做一些逻辑查询的时候都会依赖于这个权限。
这就意味着,如果此时数据库管理员登陆账号,修改次连接的权限,在次连接没有断开之前,他的权限是不会改变的,只有新建连接才会刷新全新的用户权限。
连接成功后,如果长时间不做操作,数据库就会认为次连接是空闲连接,如果太长时间没有任何操作的话,数据库会断开这条连接,这个时间是由参数wait_timeout控制的,默认时间是8小时。
在数据库里面,有长连接和短连接之分,长连接是指客户端连接数据库服务成功后,保持连接,做一些操作,短连接是指,发起一个连接,做几条语句,之后断开,需要查询的时候再连。
由于数据库建立连接是很复杂的,所以推荐使用长连接,长连接也有缺陷,会占用大量的服务器内存,可以通过定时断开某个长连接,释放掉长连接占用的内存来解决。
查询缓存
连接建立以后,就可以执行select语句了,执行逻辑就会到第二步:查询缓存。
mysql拿到一个查询请求后,首先会到数据库里面找有没有执行过此条语句,已经存在的语句会依key-value对的形式存在,key是语句,value是结果,如果此条key存在那么直接返回value给客户端,这样就能在很大程度上降低数据库服务器的压力,因为不用执行后面的功能模块,直接返回结果了。
但是多数情况下是不建议使用查询缓存的,因为查询缓存的失效非常频繁,只要对一个表进行更新那么此表的查询缓存将会彻底清空,所以对于更新压力较大的服务器来说,是不适合做查询缓存的,一些静态表、系统配置表,比较适合,所以要按需使用它。不使用查询缓存的时候可以把 query_cache_type参数设置成 DEMAND 这样对默认的SQL语句就不会使用查询缓存。而需要对表用查询缓存的时候,可以用SQL_CACHE显示指定,像下面的语句一样:
mysql> select SQL_CACHE * from T where ID=10;
这里提一句,在mysql8.0之后,查询缓存这整块模块全部删除了,也就是8.0之后就没有查询缓存功能了。
分析器
如果没有命中查询缓存,那么语句就会来到下个功能模块:分析器
首先会检测到select这是一个查询语句,之后对语句进行词法分析、语法分析,例如:
select * from T where ID=2
词法分析:进行词法分析的时候,数据库会把 “T“ 识别为表名T,把ID识别为列ID。经过了词法分析后,做语法分析;
语法分析:语法分析主要分析写的sql是否正确,各个参数是否符合要求等。如果语法分析报了错,那么紧跟找报错的“use near”。一般报错都会在这个位置。
优化器
经过了分析器之后,数据库就知道你要做什么了,接下来就看怎么做了,执行逻辑就来到了下一步:优化器
优化器是指如果 表里有多个索引或者一个表关联另一个表的时候,要选择使用索引或者从哪个表关联到哪个表的执行过程。例如下面这个:
mysql> select * from t1 join t2 using(ID) where a1.number=10 and a2.val=20;
- 既可以先从表a1里面取出number=10的记录的ID值,再根据ID值关联到表a2,在判断a2里面的val的值是否等于20;
- 也可以先从表a2里面取出val=20的记录的ID值,再根据ID值关联的表a1,再判断a1的number的值是否等于10;
这两种执行方法的逻辑结果是一样的,不同的只是执行过程,还有就是执行的效率。而优化器就是选择最好的一个方案。
执行器
数据库知道了要做什么,也知道了该怎么做,接下来就是开始做事情,执行逻辑就来到了最后一步:执行器
开始执行的时候,数据库会首先进行权限检测,检查你对此表有没有查询权限,没有的话直接报错,当然在查询缓存的时候,也会先进行权限查询。如果权限通过,进行下一步。开始执行;
select * from M where ID=20;
1、调用引擎提供的接口,取出第一行,判断ID是否等于20,如果匹配,将结果取出来;
2、继续调用接口,取出下一行,重复同样的判断逻辑,直到最后一行;
3、将所有匹配的结果全部储存到结果集中,返回给客户端;
致次,语句执行结束。
简单来捋一遍,就是首先
连接器;
查询缓存:查看是否有存在的key-value对;
分析器:词法分析、语法分析
优化器:执行道路
执行器:调用接口,返回结果
2、mysql的更新语句。
一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎。
那么一条更新语句的执行过程呢?
例子:
创建一个表T
mysql> create table A(ID int primary key, C int);
更新C的值
mysql> update A set C=C+1 where ID=2;
这里更新语句也会走一遍查询语句的执行链路。
不同的是他不会经过查询缓存这一步,因为前面提到过,如果一个表做了一个语句的更改,那么此表的查询缓存将会被清空,所以在update语句中,是不存在查询缓存这一模块功能。
接着会经过分析器,做词法和语法的分析,然后选择索引,最后返回结果。
只是与查询语句不同的是更新语句会涉及到两个重要的日志模块。redo log
binlog。
重要的日志模块:redo log
举个(例子)
在以前的餐馆里面都会有一个粉板,专门记录客人的赊账还账记录,如果赊账的人不多,可以直接记到粉板上,但是粉板肯定会用完,这时候就有一个专门记账的账本了。
如果有客人来还账或者赊账,此时酒店老板有两种方式解决:
- 第一,拿出账本,找到那人所在的页数,然后找到那人所在行数,最后抹去记录或者添加记录
- 第二,直接将记录写到粉板上,到空闲的时候再把粉板上的内容写到账本上。
当酒店生意很忙的时候,老板肯定会选择后者,因为效率更高,不会影响生意。第一种显然就有点麻烦啦。
同样在数据库里面,如果每次都将更改结果直接存入磁盘,然后磁盘也需要找到那条记录,最后更新,那么整个过程的IO成本,查找成本都很高,所以为了解决这个办法,mysql也用了类似于酒馆粉板的设计思路
在mysql里面粉板与账本的配合过程也就是mysql里的WAL技术(write- ahead logging),关键思路就是先写粉板,再写账本,也就是先写内存,再写磁盘。
具体来说,就是当有一条语句需要更新的时候,innodb引擎会先把记录写到redo log中,此时就算是更新完成了。同时innodb会在适当的时候将次操作更新到磁盘中。
由于粉板大小是有限制的,在粉板写满的时候,酒店老板就不得不停止手上的工作,将粉班上的内容移动到账本上,因为如果不写入账本,再新写入数据的话就不得不擦掉粉班上的记录,导致之前的数据丢失。与此类似,redo log也是有固定大小的,写入的方式也是同样的循环写入。
有了这个redo log,innodb就能保证在数据库发生异常重启之后也能恢复数据,这也就为数据库提供了crash-safe的能力。
重要的日志模块binlog
binlog的用途很多,比如主从,简单说一下主从的实现原理。
master服务器将记录写入到binlog(二进制日志)中,slave将master里的binlog保存到自己的中继日志中,slave通过重做中继日志中的事务,以此来更新自己的数据。
前面说过,mysql从整体来看,可以分为两层结构,server层和储存引擎层,redo log是innodb独有的日志,而server也有自己的日志—binlog
在早期的mysql里面是没有两份日志的,只有一个binlog,而这样数据库就没有了crash-safe的能力,而innodb是另一家公司以插件形式引入的mysql的,而redo log又是innodb特有的日志系统,所以redo log和binlog的结合就有了数据库的crash-safe能力。
redo log和binlog有几点不同,如下:
- 一、redo log是innodb特有的日志系统,而binlog是在server层实现的,同时支持所有的储存引擎。
- 二、redo log的写入方式是循环写入,如果写完一圈不将数据写到磁盘中,数据就会丢失,binlog的写入方式是追加,就是写满一个会再生成另一个,不会有内存的限制。
- 三、redo是物理日志,记录的是更新页上的内容,binlog是逻辑日志,记录的是执行的逻辑语句。
有了这两个日志的理解,下面来说说语句更新的过程。
例子:
mysql> update A set C=C+1 where ID=2;
- (1)调用引擎接口取出ID等于2这一行,如果数据在内存中,那么直接返回给执行器,如果不在,从磁盘读入内存,在返回给执行器;
- (2)执行器拿到这行数据,将数据增加一,得到一行新数据,并调用引擎接口写入新数据;
- (3)引擎将这行新数据写入内存,同时生成此操作的redo log 并将状态设置成prepare(准备)状态,已经准备好,随时可以提交事务;
- (4)执行器生成此操作的binlog,并写入磁盘;
- (5)执行器调用引擎的提交事务接口,将redo log改为提交状态,更新完成;
下面一个流程图:

可以看到,redo log首先是prepare状态,然后commit(提交)状态,这里涉及到了两阶段提交。
使用两阶段性提交主要是为了让两份日志保持逻辑上的一致。
如果写入一个日志,另一个不写入会发生什么?
先给个例子:
create table b (id int(11), C int(11));
update b set C=C+1 where id=1;
1、先写入redo log后写入binlog
在数据库写完redo log之后,还没来得及写binlog,数据库就crash,前面说过,如果写完redo之后,数据库发生异常重启之后,在灾难恢复的时候,可以恢复数据,恢复出来的是1,但是binlog还没有写完就crash了,如果需要binlog来恢复数据的话,由于binlog中缺少了一个更新语句的事务,所有恢复出来的C的值是0,和原库不同;
2、先写 binlog后写redo log
在写完binlog之后,还没来得及写redo log数据库就异常重启了,前面提到过,redo log记录的是更新页上的内容,由于redo log还没写入数据库就崩溃了,所以此次update无效,但是此时执行器已经生成了次操作的binlog,在进行数据恢复的时候,binlog中多出了一行数据,此时恢复来的C的值是1和原库不同。
可以看出,如果不使用两阶段性提交,那么在进行数据恢复的时候,恢复的数据可能就会不一致。
简单说,redo log和binlog都可以用于表示提交事务的状态,而两阶段性提交主要是为了让他们保持逻辑上的一致。
> 在看了林晓斌的mysql实战45讲之后,总结的知识点。