机器学习-无监督学习-聚类:聚类方法(一)--- k-Means算法,k-Means++算法【使用最大期望值算法(EM算法)来求解】
一、聚类算法
1、聚类算法概述
聚类算法:一种典型的无监督学习算法(没有目标值),主要用于将相似的样本自动归到一个类别中。在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
1.1 聚类的基本思想
给定一个有 N个对象的数据集,构造数据的 k k k 个簇, k ≤ n k≤n k≤n。满足条件:
- 每一个簇至少包含一个对象;
- 每一个对象属于且仅属于一个簇;
- 将满足上述条件的 k k k 个簇称作一个合理划分;
基本思想:对于给定的类别数目 k k k,首先给出初始划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好 。
1.2 认识聚类算法
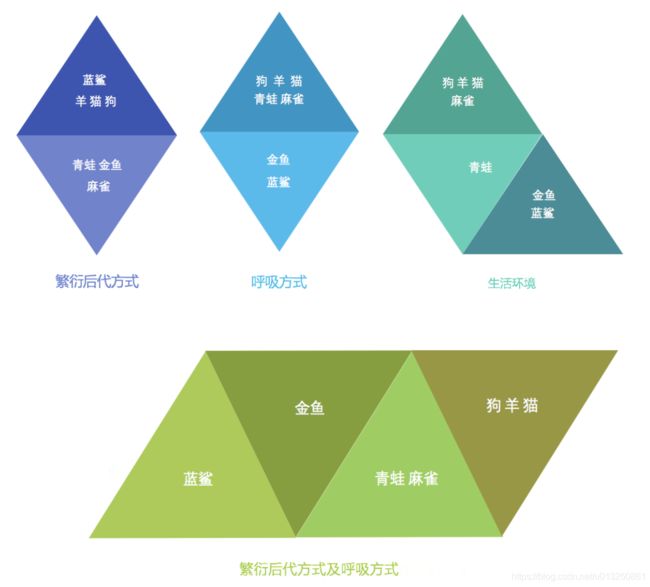
使用不同的聚类准则,产生的聚类结果不同。
1.3 聚类算法在现实中的应用
- 用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
- 基于位置信息的商业推送,新闻聚类,筛选排序
- 图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
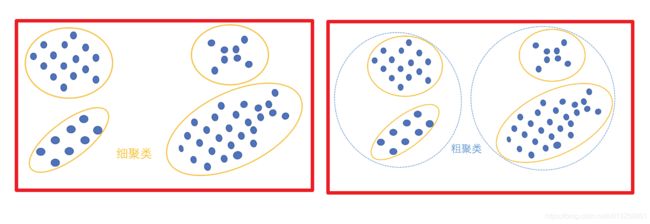
1.4 “聚类算法”与“分类算法”的区别与联系
- 聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
- 对于要用到分类算法的项目,如果初始时没有分类目标值,则先用聚类算法进行聚合,得出分类标签(目标值),然后再对待分类样本集进行分类算法。
- “聚类算法”是“分类算法”(如果无现成的目标值)的先导步骤;
1.5 相似度/距离计算方法总结

1.6 聚类算法有效性评估指标:轮廓系数(Silhouette Coefficient)
结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的有效性:
S C i = b i − a i m a x ( b i , a i ) \begin{aligned}SC_i=\frac{b_i-a_i}{max(b_i,a_i)}\end{aligned} SCi=max(bi,ai)bi−ai
- 一般 S C i SC_i SCi 处于 0.1-0.2 就算是效果很好了,很难超过0.7。
- 如果 S C i < 0 SC_i<0 SCi<0,说明 a i a_i ai 的平均距离大于最近的其他簇。聚类效果不好
- 如果 S C i SC_i SCi 越大,说明_ 的平均距离小于最近的其他簇。聚类效果好
- 轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优,聚类效果越好。
- 簇内样本的距离越近,簇间样本距离越远。
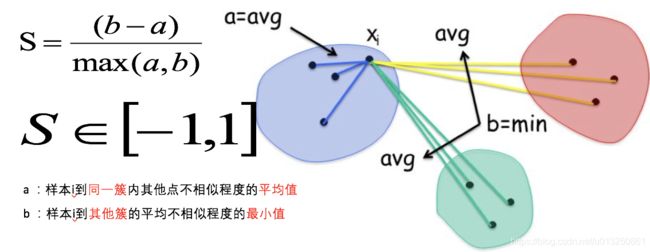
目的: 内部距离最小化,外部距离最大化
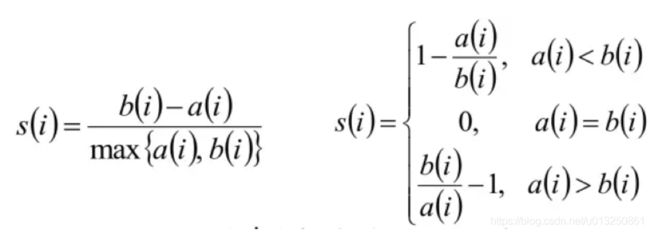
- 计算样本i到同簇其他样本的平均距离ai,ai 越小样本i的簇内不相似度越小,说明样本i越应该被聚类到该簇。
- 计算样本i到最近簇Cj 的所有样本的平均距离bij,称样本i与最近簇Cj 的不相似度,定义为样本i的簇间不相似度:bi =min{bi1, bi2, …, bik},bi越大,说明样本i越不属于其他簇。
- 求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
案例:下图是500个样本含有2个feature的数据分布情况,我们对它进行SC系数效果衡量:
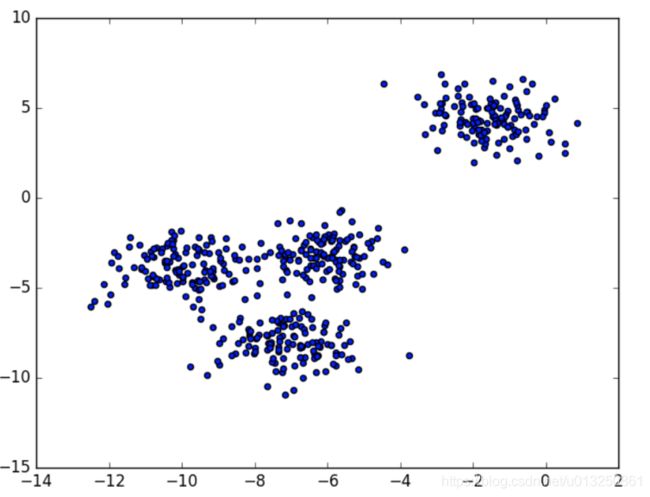
- n_clusters = 2 The average silhouette_score is : 0.7049787496083262
- n_clusters = 3 The average silhouette_score is : 0.5882004012129721
- n_clusters = 4 The average silhouette_score is : 0.6505186632729437
- n_clusters = 5 The average silhouette_score is : 0.56376469026194
- n_clusters = 6 The average silhouette_score is : 0.4504666294372765
- n_clusters 分别为 2,3,4,5,6时,SC系数如下,是介于[-1,1]之间的度量指标:
每次聚类后,每个样本都会得到一个轮廓系数,当它为1时,说明这个点与周围簇距离较远,结果非常好,当它为0,说明这个点可能处在两个簇的边界上,当值为负时,暗含该点可能被误分了。
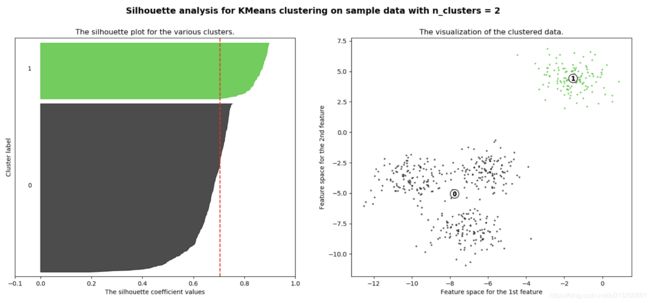
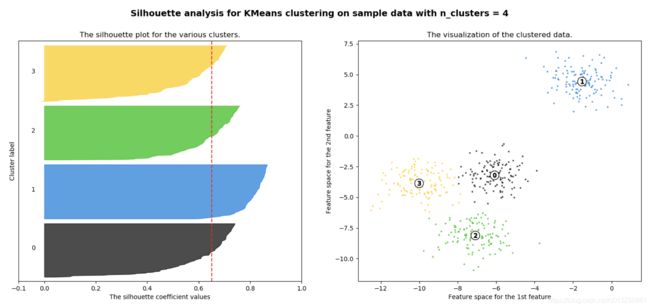
从平均SC系数结果来看,K取3,5,6是不好的,那么2和4呢?
k=2的情况:
k=4的情况:
n_clusters = 2时,第0簇的宽度远宽于第1簇;
n_clusters = 4时,所聚的簇宽度相差不大,因此选择K=4,作为最终聚类个数。
2、k-Means算法
k-Means算法,也被称为k-平均或k-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础。
k-Means其实包含两层内容:
- K : 初始中心点个数(计划聚类数)
- means:求中心点到其他数据点距离的平均值
2.1 k-Means算法步骤
假定输入样本为 S = x 1 , x 2 , . . . , x m S=x_1,x_2,...,x_m S=x1,x2,...,xm
- 随机设置 k k k 个特征空间内的点作为初始的类别中心: μ 1 , μ 2 , … , μ k μ_1,μ_2,…,μ_k μ1,μ2,…,μk;
- 对于其他每个样本点 x i x_i xi 计算到 k k k 个类别中心的距离,并选择最近的一个类别中心点作为标记类别: l a b e l i = arg min 1 ≤ j ≤ k ∣ ∣ x i − μ j ∣ ∣ label_i=\argmin \limits_{1≤j≤k}||x_i-μ_j|| labeli=1≤j≤kargmin∣∣xi−μj∣∣;
- 将每个类别中心更新为隶属该类别的所有样本的均值 μ j = 1 ∣ c j ∣ ∑ i ∈ c j x i μ_j=\cfrac{1}{|c_j|}\sum_{i∈c_j}x_i μj=∣cj∣1∑i∈cjxi,其中 c j c_j cj 表示类别 j j j 中样本的数量;
- 如果计算得出的类别中心的变化小于某阈值,那么结束,否则重新进行第二步过程。
- 结束条件:迭代次数/簇中心变化率/最小平方误差MSE(Minimum Squared Error)。
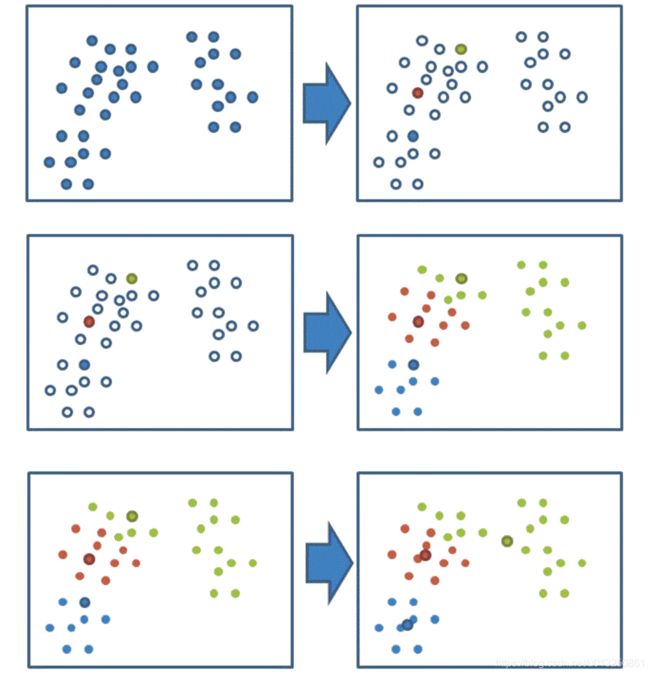
案例解释:
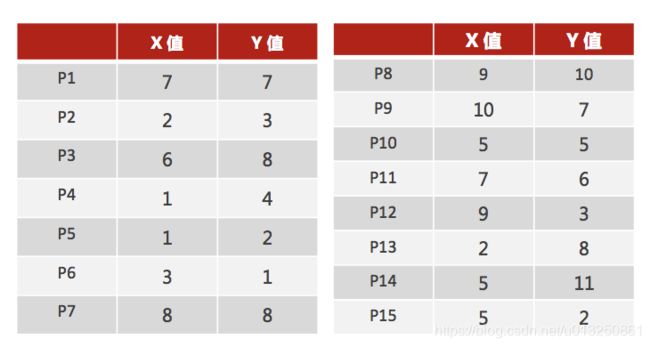
1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
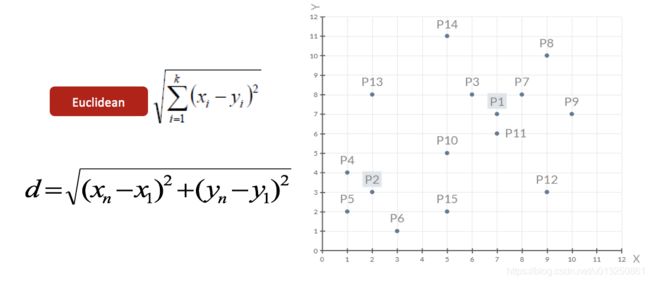
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
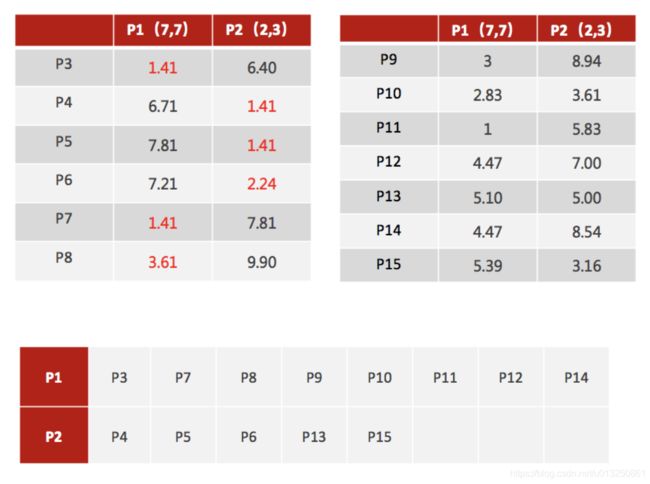
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
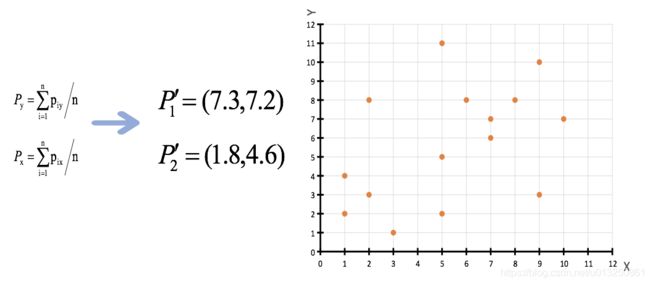
4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】
5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
2.2 k-Means算法动态效果图
The data points

2.2.1 Starting with 4 left-most points

2.2.2 Starting with 4 right-most points
2.2.3 Starting with 4 top points
2.2.4 Starting with 4 bottom points
2.2.5 Starting with 4 random points in one cluster
2.3 k-Means算法的公式化解释
- 记K个簇中心为 μ 1 , μ 2 , . . . , μ K μ_1,μ_2,...,μ_K μ1,μ2,...,μK,每个簇的样本数量为 N 1 , N 2 , . . . , N K N_1,N_2,...,N_K N1,N2,...,NK
- 使用平方误差作为目标函数:
J ( μ 1 , μ 2 , . . . , μ K ) = 1 2 ∑ j = 1 K ∑ i = 1 N j ( x i − μ j ) 2 J(μ_1,μ_2,...,μ_K)=\frac12\sum^K_{j=1}\sum^{N_j}_{i=1}(x_i-μ_j)^2 J(μ1,μ2,...,μK)=21j=1∑Ki=1∑Nj(xi−μj)2 - 求目标函数对 μ 1 , μ 2 , . . . , μ K μ_1,μ_2,...,μ_K μ1,μ2,...,μK 的偏导,令偏导为0求驻点
∂ J ( μ 1 , μ 2 , . . . , μ K ) ∂ μ j = − ∑ i = 1 N j ( x i − μ j ) = 0 ⟹ μ j = 1 N ∑ i = 1 N j x i \begin{aligned} &\cfrac{\partial J(μ_1,μ_2,...,μ_K)}{\partial μ_j}=-\sum^{N_j}_{i=1}(x_i-μ_j)=0 \\ & \implies \\ &μ_j=\frac1N\sum^{N_j}_{i=1}x_i \end{aligned} ∂μj∂J(μ1,μ2,...,μK)=−i=1∑Nj(xi−μj)=0⟹μj=N1i=1∑Njxi
2.4 k-Means算法Api
sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
参数:
- n_clusters:开始的聚类中心数量,整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
- init:初始化方法,默认为’k-means ++’
labels_:默认标记的类型,可以和真实值比较(不是值比较)
方法: - estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
2.5 k-Means算法小结
优点:
- 原理简单(靠近中心点),实现容易
- 聚类效果中上(依赖K的选择)
- 空间复杂度 O ( N ) O(N) O(N),时间复杂度 O ( I K N ) O(IKN) O(IKN),N为样本点个数,K为中心点个数,I为迭代次数
- 是解决聚类问题的一种经典算法,简单、快速
- 对处理大数据集,该算法保持可伸缩性和高效率
- 当簇近似为高斯分布时,它的效果较好
- 可作为其他聚类方法的基础算,如谱聚类
缺点:
- 对离群点,噪声敏感 (中心点易偏移)
- 很难发现大小差别很大的簇及进行增量计算
- 结果不一定是全局最优,只能保证局部最优(与K的个数及初值选取有关)
- 在簇的平均值可被定义情况下才能使用 ,不适用于某些应用
- 必须事先给出 k k k( 要生成的簇数目 ),而且对初值敏感,对于不同的初始值,可能会导致不同结果。
- 不适合于发现非凸形状的簇或者大小差别很大的簇
若簇中含有异常点,将导致均值偏离严重。以一维数据为例:
- 数组 1、2、3、4、100 的均值为 22 ,显然距离“大多数”数据 1、2、3、4比较远
- 改成求数组的中位数3,在该实例中更为稳妥。
- 这种聚类方式即 k-Mediods 聚类算法 (k-中值距离)
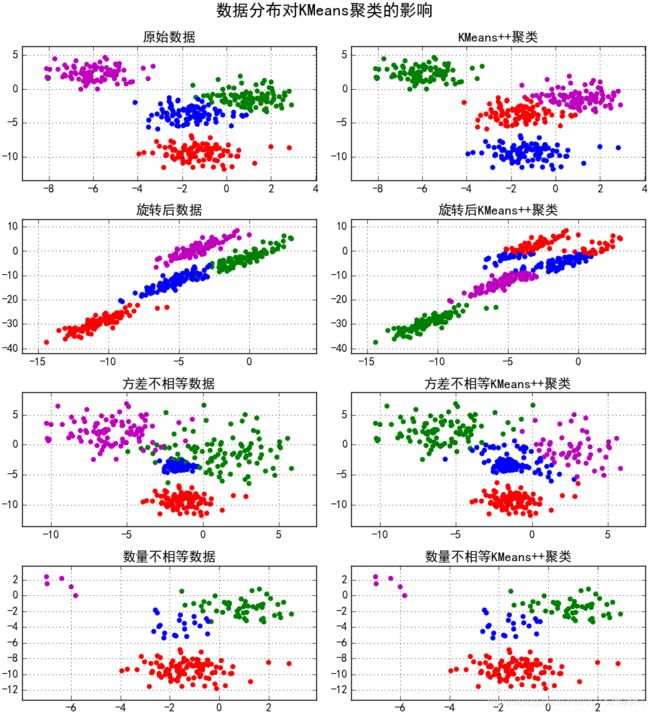
2.6 k-Means算法代码实现
import numpy as np
import matplotlib.pyplot as plt
# 引入scipy中的距离函数,默认欧式距离
from scipy.spatial.distance import cdist
# 从sklearn中直接生成聚类数据
from sklearn.datasets.samples_generator import make_blobs
# 一、数据加载
x, y = make_blobs(n_samples=100, centers=6, random_state=1234, cluster_std=0.6)
print('x.shape = {0}, y.shape = {1}'.format(x.shape, y.shape))
print('\nx[:30] = \n{0}'.format(x[:30]))
print('\ny[:30] = {0}'.format(y[:30]))
# 二、原始数据画图
plt.figure(figsize=(6, 6))
plt.scatter(x[:, 0], x[:, 1], c=y)
# 三、 K_Means算法实现
class K_Means(object):
def __init__(self, n_clusters=5, max_iter=300, centroids=[]): # 初始化,参数 n_clusters(K)、迭代次数max_iter、初始质心 centroids
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = np.array(centroids, dtype=np.float)
def fit(self, data): # 训练模型方法,k-means聚类过程,传入原始数据
if (self.centroids.shape == (0,)): # 假如没有指定初始质心,就随机选取data中的点作为初始质心
self.centroids = data[np.random.randint(0, data.shape[0], self.n_clusters), :] # 从data中随机生成0到data行数的6个整数,作为索引值
for i in range(self.max_iter): # 开始迭代
distances = cdist(data, self.centroids) # 1. 计算距离矩阵,得到的是一个100*6的矩阵
c_ind = np.argmin(distances, axis=1) # 2. 对距离按有近到远排序,选取最近的质心点的类别,作为当前点的分类
for i in range(self.n_clusters): # 3. 对每一类数据进行均值计算,更新质心点坐标
if i in c_ind: # 排除掉没有出现在c_ind里的类别
self.centroids[i] = np.mean(data[c_ind == i], axis=0) # 选出所有类别是i的点,取data里面坐标的均值,更新第i个质心
def predict(self, samples): # 预测
distances = cdist(samples, self.centroids) # 跟上面一样,先计算距离矩阵,然后选取距离最近的那个质心的类别
c_ind = np.argmin(distances, axis=1)
return c_ind
# 定义一个绘制子图函数
def plotKMeans(x, y, centroids, subplot, title):
# 分配子图,121表示1行2列的子图中的第一个
plt.subplot(subplot)
plt.scatter(x[:, 0], x[:, 1], c='r')
# 画出质心点
plt.scatter(centroids[:, 0], centroids[:, 1], c=np.array(range(5)), s=100)
plt.title(title)
# 四、测试
if __name__ == '__main__':
# 实例化K_Means算法
kmeans = K_Means(max_iter=300, centroids=np.array([[2, 1], [2, 2], [2, 3], [2, 4], [2, 5]]))
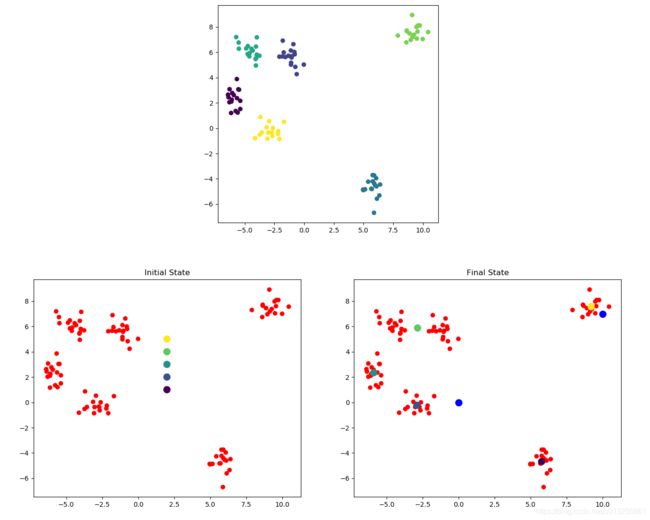
plt.figure(figsize=(16, 6))
# 画所有待聚类数据、初始时的质心位置
plotKMeans(x, y, kmeans.centroids, 121, 'Initial State')
# 开始聚类
kmeans.fit(x)
print('\n聚类结束后,得到的所有质心位置:kmeans.centroids = \n{0}'.format(kmeans.centroids))
# 画所有待聚类数据、聚类之后的质心位置
plotKMeans(x, y, kmeans.centroids, 122, 'Final State')
# 预测新数据点的类别
x_new = np.array([[0, 0], [10, 7]]) # 待预测数据 [[0, 0], [10, 7]]
print('\nx_new.shape = {0}'.format(x_new.shape))
print('x_new = \n{0}'.format(x_new))
y_pred = kmeans.predict(x_new)
print('y_pred = {0}'.format(y_pred))
plt.scatter(x_new[:, 0], x_new[:, 1], s=100, c='blue')
plt.show()
打印结果:
x.shape = (100, 2), y.shape = (100,)
x[:30] =
[[-0.02708305 5.0215929 ]
[-5.49252256 6.27366991]
[-5.37691608 1.51403209]
[-5.37872006 2.16059225]
[ 9.58333171 8.10916554]
[-3.76462743 5.72284189]
[ 9.54005257 7.6305493 ]
[-4.44247192 6.27435008]
[ 9.24659704 7.38484131]
[-5.76427854 1.35195908]
[-5.92633895 2.61563059]
[ 9.08975003 8.93811387]
[-4.04917756 5.52723579]
[-1.80119781 6.91187744]
[ 8.97066474 6.96893338]
[-4.59307462 5.9281383 ]
[-5.66460616 3.87675173]
[ 9.97746543 7.03575246]
[ 9.11922209 7.18829094]
[10.43700221 7.59201676]
[-1.11831519 6.13000405]
[-2.62551587 0.01105124]
[-6.27947612 3.07755693]
[ 9.73427408 8.11153524]
[-0.82290828 6.02127646]
[ 5.64742155 -4.78812664]
[ 6.33426078 -5.31681286]
[-3.03539144 -0.35209334]
[ 8.87837454 7.48463526]
[-1.57439069 5.62039997]]
y[:30] = [1 3 0 0 4 3 4 3 4 0 0 4 3 1 4 3 0 4 4 4 1 5 0 4 1 2 2 5 4 1]
聚类结束后,得到的所有质心位置:kmeans.centroids =
[[ 5.76444812 -4.67941789]
[-2.89174024 -0.22808556]
[-5.89115978 2.33887408]
[-2.8455246 5.87376915]
[ 9.20551979 7.56124841]]
x_new.shape = (2, 2)
x_new =
[[ 0 0]
[10 7]]
y_pred = [1 4]
2.7 k-Means算法案例01
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
# 1.获取数据
order_product = pd.read_csv("F:/AI_Data/instacart/order_products__prior.csv")
products = pd.read_csv("F:/AI_Data/instacart/products.csv")
orders = pd.read_csv("F:/AI_Data/instacart/orders.csv")
aisles = pd.read_csv("F:/AI_Data/instacart/aisles.csv")
# 2.数据基本处理
# 2.1 合并表格
table1 = pd.merge(order_product, products, on=["product_id", "product_id"])
table2 = pd.merge(table1, orders, on=["order_id", "order_id"])
table = pd.merge(table2, aisles, on=["aisle_id", "aisle_id"])
# 2.2 交叉表合并
data = pd.crosstab(table["user_id"], table["aisle"])
print('data.shape =', data.shape)
print('data.head() =', data.head())
# 2.3 数据截取(原始数据太大)
new_data = data[:500]
# 3.特征工程:数据降维-主成分分析(PCA)
pca = PCA(n_components=0.9)
data_pca = pca.fit_transform(new_data)
print('data_pca.shape =', data_pca.shape)
# 4.算法工程(聚类算法k-means)
estimator = KMeans(n_clusters=4) # 超参数,如果不知道则调参,如果知道则直接用已知数。
KMeans = estimator.fit(data_pca)
print('KMeans = \n', KMeans)
y_predict = estimator.predict(data_pca)
print('y_predict =\n', y_predict)
# 5.显示聚类的结果
plt.figure(figsize=(10, 10))
colored = ['orange', 'green', 'blue', 'purple'] # 建立4个颜色的列表
colr = [colored[i] for i in y_predict]
plt.scatter(data_pca[:, 1], data_pca[:, 10], color=colr)
plt.show()
# 6.模型评估(评判聚类效果:轮廓系数)
score = silhouette_score(data_pca, y_predict)
print('轮廓系数:score = ', score)
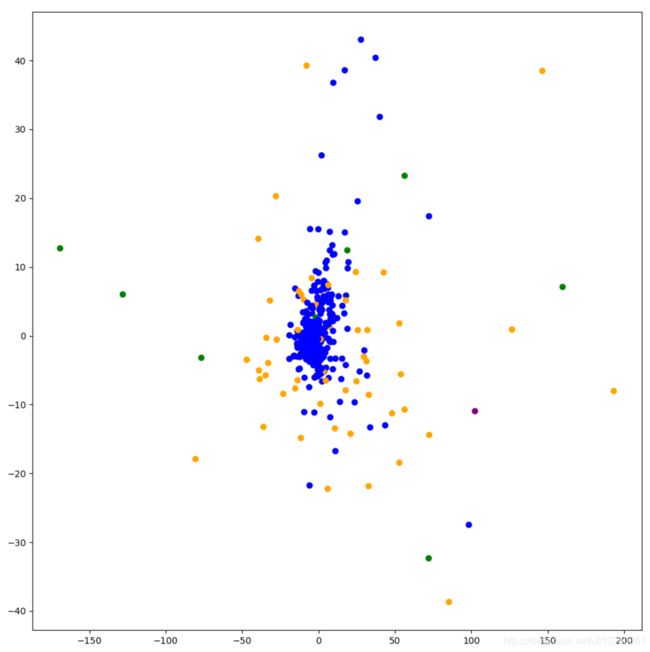
打印结果:
data.shape = (206209, 134)
data.head() = aisle air fresheners candles asian foods ... white wines yogurt
user_id ...
1 0 0 ... 0 1
2 0 3 ... 0 42
3 0 0 ... 0 0
4 0 0 ... 0 0
5 0 2 ... 0 3
[5 rows x 134 columns]
data_pca.shape = (500, 17)
KMeans =
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=4, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
y_predict =
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 1 1 1 1 1 1 1 1 0
1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 0 1 1 1
0 1 1 1 1 1 1 1 1 1 1 0 1 1 0 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 0 1 1 1 0 1 1
1 1 1 3 0 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 1 1 3 2 1 1 1 0 1 1 1 1 1 1 1 1
3 1 1 1 0 1 1 1 1 0 0 0 1 0 1 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 1 1 1 1 1 1 1 2 0 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 2 1 1 1 1 1 1 1 0 1 3 1 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 2 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1
1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 2
1 1 1 0 1 1 0 0 1 0 1 1 1 1 1 1 1 3 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
1 1 1 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1]
轮廓系数:score = 0.6377849794162626
2.8 k-Means算法案例02
k-Means算法-test.txt
# -*- coding: utf-8 -*-
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.cluster import KMeans
class KmeansClustering():
def __init__(self, stopwords_path=None):
self.stopwords = self.load_stopwords(stopwords_path)
self.count_vectorizer = CountVectorizer() # 创建词袋数据结构
self.tfidf_transformer = TfidfTransformer()
def load_stopwords(self, stopwords=None):
"""
加载停用词
:param stopwords:
:return:
"""
if stopwords:
with open(stopwords, 'r', encoding='utf-8') as f:
stopword_list = [line.strip() for line in f]
print("len(stopword_list) = {0}----stopword_list = {1}".format(len(stopword_list), stopword_list))
return stopword_list
else:
return []
def preprocess_data(self, corpus_path):
"""
文本预处理,每行一个文本
:param corpus_path:
:return:
"""
corpus = []
with open(corpus_path, 'r', encoding='utf-8') as f:
for line in f:
corpus.append(' '.join([word for word in jieba.lcut(line.strip()) if word not in self.stopwords]))
print("\nlen(corpus) = {0}----corpus[0] = {1}".format(len(corpus), corpus[0]))
return corpus
def get_text_tfidf_matrix(self, corpus):
"""
获取tfidf矩阵
:param corpus:
:return:
"""
self.count_vectorizer.fit(corpus) # CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵
# 获取词袋中所有词语
words = self.count_vectorizer.get_feature_names()
print("\n词袋中所有词语:len(words) = {0}----word = {1}".format(len(words), words))
vectorizer_result = self.count_vectorizer.transform(corpus).toarray() # .toarray() 是将结果转化为稀疏矩阵矩阵的表示方式;【25行表示25篇文档,3863列表示构建的词典库词语;元素数值表示该词汇在该篇文章中的词频】
print("\nvectorizer_result.shape = {0}----vectorizer_result = \n{1}".format(vectorizer_result.shape, vectorizer_result))
tfidf_result = self.tfidf_transformer.fit_transform(vectorizer_result).toarray() # 获取tfidf矩阵
print("\ntfidf_result.shape = {0}----tfidf_result = \n{1}".format(tfidf_result.shape, tfidf_result))
return tfidf_result
def kmeans(self, corpus_path, n_clusters=5):
"""
KMeans文本聚类
:param corpus_path: 语料路径(每行一篇),文章id从0开始
:param n_clusters: :聚类类别数目
:return: {cluster_id1:[text_id1, text_id2]}
"""
corpus = self.preprocess_data(corpus_path)
tfidf_result = self.get_text_tfidf_matrix(corpus)
clf = KMeans(n_clusters=n_clusters)
clf.fit(tfidf_result)
# 中心点
centers = clf.cluster_centers_
print("\ncenters.shape = {0}----centers = \n{1}".format(centers.shape, centers))
# 用来评估簇的个数是否合适,距离越小说明簇分得越好,选取临界点的簇的个数
score = clf.inertia_
print("\n轮廓系数:score.shape = {0}----score = {1}".format(score.shape, score))
y_predict = clf.predict(tfidf_result)
print("\ny_predict.shape = {0}----y_predict = {1}".format(y_predict.shape, y_predict))
result = {
} # 每个样本所属的簇
for text_idx, label_idx in enumerate(y_predict):
if label_idx not in result:
result[label_idx] = [text_idx]
else:
result[label_idx].append(text_idx)
return result
if __name__ == '__main__':
Kmeans = KmeansClustering(stopwords_path='../data/stop_words.txt')
result = Kmeans.kmeans('../data/test_data.txt', n_clusters=4)
print("\nKmeans聚类结果:result = {0}".format(result))
打印结果:
len(stopword_list) = 2192----stopword_list = ['′', '°', '', 'gov', 'a', 'b', ...,'{-', '|', '}', '}>', '~', '~±', '~+', '¥']
len(corpus) = 25----corpus[0] = 鲍勃 库西 奖归 属 NCAA 最强 控卫 坎巴 弗神 新浪 体育讯 本赛季 NCAA 末段 各项 奖项 评选 出炉 评选 最佳 控卫 鲍勃 库西 奖 下周 最终 四强 战时 公布 鲍勃 库西 奖是 由奈 史密斯 篮球 名人堂 提供 旨在 奖励 年度 最佳 大学 控卫 最终 获奖 球员 几名 热门 人选 NCAA 疯狂 专题 主页 上线 点击 链接 查看 精彩内容 吉梅尔 弗雷 戴特 杨百翰 大学 弗神 吉梅尔 弗雷 戴特 备受 关注 一名 射手 他会用 终结 对手 脚踝 变向 掉 面前 防守 任意 一支 手 得分 犯规 提前 两份 划入 帐 一名 命中率 高达 罚球 手 弗雷 戴特 控卫 具备 一点 特质 一位 赢家 一位 领导者 赛季 至始 至终 稳定 领导 球队 这是 无可比拟 杨百翰 大学 主教练 戴夫 罗斯 称赞 道 得分 能力 毋庸置疑 带领 球队 获胜 能力 控卫 职责 主场 之外 比赛 客场 立场 取胜 场 表现 很棒 弗雷 戴特 NBA 取得成功 专业人士 资格 做出 判断 喜爱 凯尔特人 主教练 多克 里 弗斯 说道 很棒 看过 ESPN 片段 剪辑 剪辑 超级 巨星 一名 优秀 NBA 球员 诺兰 史密斯 杜克大学 赛季 球队 控卫凯瑞 厄尔 文因 脚趾 伤病 缺席 赛季 大部分 比赛 诺兰 史密斯 接管 球权 进攻 端上 足 发条 ACC 联盟 杜克大学 分区 得分 榜上 名列前茅 分区 助攻 榜上 占据 头名 众强 林立 ACC 联盟 前无古人 全美 球员 凯瑞 厄尔 文 受伤 接管 球队 毫无准备 杜克 主教练 迈克 沙舍 夫斯基 赞扬 道 他会 比赛 带入 节奏 得分 组织 领导 球队 无所不能 攻防 俱佳 持球 防守 提高 拥有 辉煌 赛季 坎巴 沃克 康涅狄格 大学 坎巴 沃克 带领 康涅狄格 赛季 毛伊岛 邀请赛 力克 密歇根州 肯塔基 等队 夺冠 他场 分 助攻 最佳 球员 大东 赛区 锦标赛 全国 锦标赛 他场 27.1 分 6.1 篮板 5.1 次 助攻 依旧 给力 疯狂 表现 赛季 疯狂 表现 结束 赛季 全国 锦标赛 天 连赢 场 赢得 大东 赛区 锦标赛 冠军 归功于 坎巴 沃克 康涅狄格 大学 主教练 吉姆 卡洪 称赞 道 一名 纯正 控卫 能为 得分 单场 分 有过 单场 助攻 单场 篮板 一名 英尺 175 镑 球员 球员 领导者 球队 做 贡献 乔丹 泰勒 威斯康辛 大学 全美 持球者 乔丹 泰勒 失误 4.26 助攻 失误 全美 遥遥领先 大十 赛区 比赛 平均 35.8 分钟 失误 名 出色 得分手 全场 砍 分 击败 印第安纳 大学 比赛 证明 下半场 分 夜晚 证明 值得 首轮 顺位 见证者 印第安纳 大学 主教练 汤姆 克 雷恩 说道 一名 控卫 领导 球队 球队 变 更好 带领 球队 成功 乔丹 泰勒 威斯康辛 教练 博 莱恩 说道 诺里斯 科尔 克利夫兰 州 诺里斯 科尔 草根 传奇 上演 默默无闻 克利夫兰 州 招募 刻苦 训练 去年 夏天 加练 千次 跳投 提高 弱点 本赛季 杨斯顿 州 比赛 分 篮板 次 助攻 年 一位 球员 NCAA 联盟 名字 布雷克 格里芬 轻松 地防下 王牌 克利夫兰 州 主教练 加里 沃特斯 称赞 弟子 得分 球队 助攻 成功 团队 事 四名 球员 带领 球队 甜蜜 强 球员 球队 挡 强 大门 之外 表现 足够 出色 不远 将来 一所 熟悉 NBA 球馆 里 clay
词袋中所有词语:len(words) = 3863----word = ['000999', '010', '011', '02', '05', ...,'鼓励', '鼓舞', '鼓起', '鼠王', '龙珠', '龙骑士']
vectorizer_result.shape = (25, 3863)----vectorizer_result =
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 1 ... 0 0 0]
[0 0 0 ... 0 0 0]
[1 0 0 ... 0 0 0]]
tfidf_result.shape = (25, 3863)----tfidf_result =
[[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
...
[0. 0. 0.07715721 ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0.03068967 0. 0. ... 0. 0. 0. ]]
centers.shape = (4, 3863)----centers =
[[-2.16840434e-19 0.00000000e+00 0.00000000e+00 ... 3.47951649e-03
1.90016129e-02 1.73975824e-03]
[-2.16840434e-19 7.83718590e-03 0.00000000e+00 ... 0.00000000e+00
8.67361738e-19 0.00000000e+00]
[ 6.13793366e-03 0.00000000e+00 1.54314412e-02 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]]
轮廓系数:score.shape = ()----score = 19.57267663283431
y_predict.shape = (25,)----y_predict = [0 0 0 0 0 0 0 1 1 0 3 3 3 3 3 1 1 1 1 1 2 2 2 2 2]
Kmeans聚类结果:result = {
0: [0, 1, 2, 3, 4, 5, 6, 9], 1: [7, 8, 15, 16, 17, 18, 19], 3: [10, 11, 12, 13, 14], 2: [20, 21, 22, 23, 24]}
Process finished with exit code 0
3、k-Means++算法
由于 K-means 算法的分类结果会受到初始点的选取而有所区别,即K-means 算法是初始值敏感的。因此有提出这种算法的改进: K-means++ 。
k-Means++算法步骤
其实这个算法也只是对初始点的选择有改进而已,其他步骤都一样。初始质心选取的基本思路就是,初始的聚类中心之间的相互距离要尽可能的远。
3.1 k-Means++算法描述:
- 步骤一:随机选取一个样本作为第一个聚类中心 c1;
- 步骤二:
- 计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用 D(x)表示;
- 这个值越大,表示被选取作为聚类中心的概率较大;
- 最后,用轮盘法选出下一个聚类中心;
- 步骤三:重复步骤二,知道选出 k 个聚类中心。
选出初始点后,就继续使用标准的 k-means 算法了。

3.2 k-Means++算法效率
- K-means++ 能显著的改善分类结果的最终误差。
- 尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
- 网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。
3.3 K-means++算法选取初始聚类中心
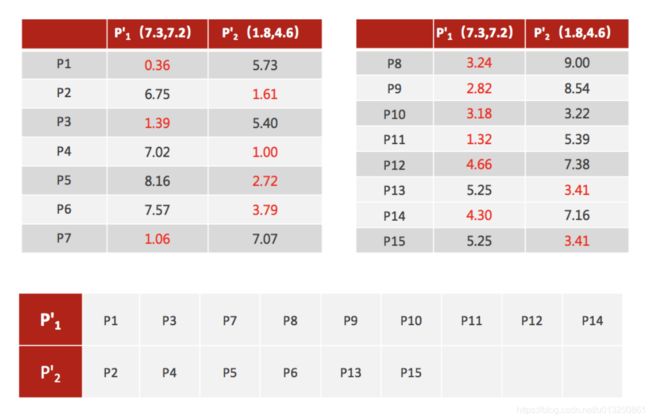
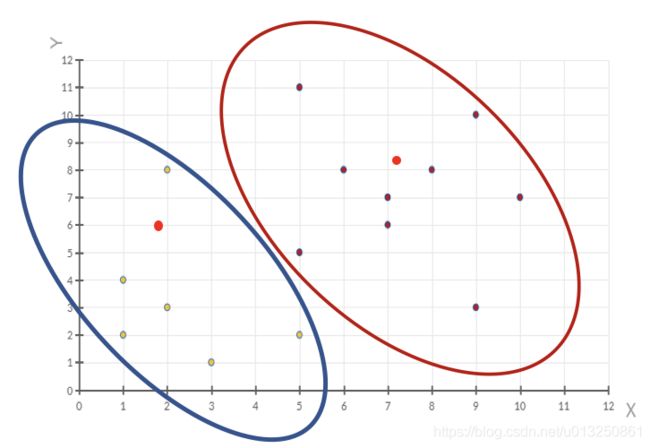
数据集中共有8个样本,分布以及对应序号如下图所示:
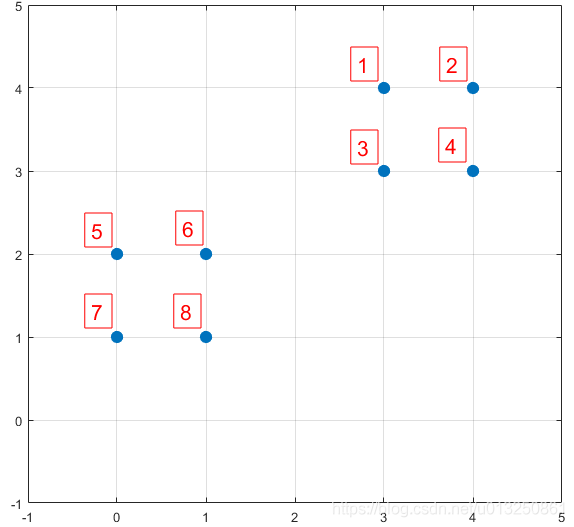
假设经过步骤一后6号点被选择为第一个初始聚类中心,
那在进行步骤二时每个样本的D(x)和被选择为第二个聚类中心的概率如下表所示:
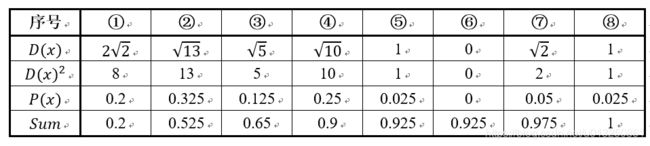
- 其中的 P ( x ) P(x) P(x) 就是每个样本被选为下一个聚类中心的概率。
- 最后一行的Sum是概率 P ( x ) P(x) P(x) 的累加和,用于轮盘法选择出第二个聚类中心。
- 方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。
- 例如1号点的区间为[0,0.2),2号点的区间为[0.2, 0.525)。
- 从上表可以直观的看到第二个初始聚类中心是1号,2号,3号,4号中的一个的概率为0.9。
- 而这4个点正好是离第一个初始聚类中心6号点较远的四个点。
- 这也验证了K-means的改进思想:即离当前已有聚类中心较远的点有更大的概率被选为下一个聚类中心。
- 可以看到,该例的K值取2是比较合适的。当K值大于2时,每个样本会有多个距离,需要取最小的那个距离作为 D(x)。
3.4 K-means++算法代码实现
import math
import random
from sklearn import datasets
def euler_distance(point1: list, point2: list) -> float:
"""计算两点之间的欧拉距离,支持多维"""
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
def get_closest_dist(point, centroids):
min_dist = math.inf # 初始设为无穷大
for i, centroid in enumerate(centroids):
dist = euler_distance(centroid, point)
if dist < min_dist:
min_dist = dist
return min_dist
def kpp_centers(data_set: list, k: int) -> list:
"""从数据集中返回 k 个对象可作为质心"""
cluster_centers = []
cluster_centers.append(random.choice(data_set))
d = [0 for _ in range(len(data_set))]
for _ in range(1, k):
total = 0.0
for i, point in enumerate(data_set):
d[i] = get_closest_dist(point, cluster_centers) # 与最近一个聚类中心的距离
total += d[i]
total *= random.random()
for i, di in enumerate(d): # 轮盘法选出下一个聚类中心;
total -= di
if total > 0:
continue
cluster_centers.append(data_set[i])
break
return cluster_centers
if __name__ == "__main__":
iris = datasets.load_iris()
print('从iris数据集中返回4个对象可作为质心:\n', kpp_centers(iris.data, 4))
打印结果:
从iris数据集中返回4个对象可作为质心:
[array([5.1, 3.4, 1.5, 0.2]), array([6.4, 3.1, 5.5, 1.8]), array([4.4, 2.9, 1.4, 0.2]), array([7.7, 3.8, 6.7, 2.2])]