Python爬取B站历史观看记录并用Bokeh做数据可视化
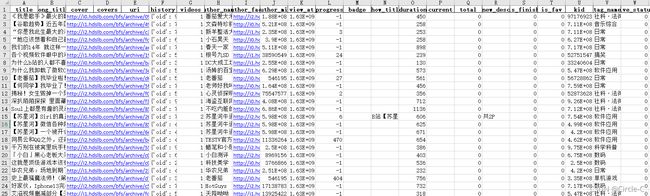
待爬取的数据

爬虫代码
import os
import time
import requests
import pandas as pd
# cookie 用浏览器登录B站,按F12打开开发人员工具,找到自己的cookie替换
cookies_dict = {'_uuid': "1C7F0395-1CDC-5BBF-E859-528F14EA305F09211infoc",
'bili_jct': "379cd5610f8d21596f2b2f29737b8369",
'blackside_state': "1",
'bp_t_offset_23436622': "590187858631120173",
'bp_video_offset_23436622': "590019044938733647",
'buvid_fp': "39749394-CBB7-407C-9BDE-FCE21FA6F68A13420infoc",
'buvid_fp_plain': "39749394-CBB7-407C-9BDE-FCE21FA6F68A13420infoc",
'buvid3': "39749394-CBB7-407C-9BDE-FCE21FA6F68A13420infoc",
'CURRENT_FNVAL': "976",
'CURRENT_QUALITY': "80",
'DedeUserID': "23436622",
'DedeUserID__ckMd5': "4dee66ab9d320fb1",
'fingerprint': "a705f93cd569878dd9441844801a58b0",
'innersign': "0",
'LIVE_BUVID': "AUTO6116247192375889",
'PVID': "1",
'rpdid': "|(RlllJ~R~R1J'uYkRllukkR",
'SESSDATA': "9ed4af92,1643348674,9e746*81",
'sid': "j08zwekk",
'video_page_version': "v_old_home_5"}
session = requests.Session()
response = session.get('https://api.bilibili.com/x/web-interface/history/cursor', cookies=cookies_dict)
history_list = []
cur_list = response.json()['data']['list']
while cur_list:
view_at = cur_list[0].get('view_at')
strftime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(view_at))
title = cur_list[0].get('title')
print(strftime, title)
history_list += cur_list
cursor = response.json()['data']['cursor']
url = 'https://api.bilibili.com/x/web-interface/history/cursor?max={}&view_at={}&business=archive'.format(cursor['max'], cursor['view_at'])
response = session.get(url, cookies=cookies_dict)
cur_list = response.json()['data']['list']
time.sleep(1)
print('git history info success')
df_history = pd.DataFrame(history_list)
strftime = time.strftime('%Y-%m-%d', time.localtime())
fpath = os.path.join(os.getcwd(), f'bili_history_{strftime}.xlsx')
df_history.to_excel(fpath, index=False)
print('save success', fpath)执行完毕后,数据保存到当前目录下的bili_history_XXX-XX-XX.xlsx文件
只有最近3个月的数据
打开jupyter notebook用Boken做可视化
# 导入模块
import os
import time
import pandas as pd
import numpy as np
from bokeh.plotting import figure, show, output_notebook
from bokeh.layouts import gridplot
output_notebook()
# 从包含bili_history的excel文件导入数据
data_dir = r'D:\Program\JupyterNotebook'
identifier = 'bili_history'
df = pd.DataFrame()
for file_name in os.listdir(data_dir):
if file_name.startswith(identifier) and file_name.endswith('.xlsx'):
fpath = os.path.join(data_dir, file_name)
print(fpath)
df_ = pd.read_excel(fpath)
df = df.append(pd.read_excel(fpath))
# 数据预处理
df.drop_duplicates(inplace=True)
df = df.astype({'tag_name': 'string', 'author_name': 'string'})
df['date'] = pd.to_datetime(df['view_at'],unit='s',origin=pd.Timestamp('1970-01-01 08:00:00'))
df['date'] = df['date'].dt.strftime("%Y-%m-%d")
df = df.fillna({"tag_name":"无"})
category = {
'生活': ['搞笑', '家居房产', '手工', '绘画', '日常', '热点', '社会', '环球'],
'游戏': ['单机游戏', '网络游戏', '手机游戏', '电子竞技', '桌游棋牌', '音游', 'GMV', 'Mugen'],
'娱乐': ['综艺', '明星', '视频聊天'],
'知识': ['科学科普', '科技科普', '社科·法律·心理', '人文历史', '财经商业', '校园学习', '职业职场', '设计·创意', '野生技能协会', '陪伴学习'],
'影视': ['短片', '影视杂谈', '影视剪辑', '预告·资讯'],
'音乐': ['音乐综合', '音乐现场', '演奏', '翻唱', 'MV', 'VOCALOID·UTAU', '电音', '原创音乐', '视频唱见'],
'动画': ['MAD·AMV', 'MMD·3D', '综合', '短片·手书·配音', '手办·模玩', '特摄'],
'时尚': ['美妆护肤', '穿搭', '时尚潮流', '风尚标', '美妆', '服饰'],
'美食': ['美食制作', '美食侦探', '美食测评', '田园美食', '美食记录'],
'汽车': ['汽车生活', '汽车文化', '汽车极客', '摩托车', '智能出行', '购车攻略'],
'运动': ['篮球·足球', '健身', '竞技体育', '运动文化', '运动综合'],
'科技': ['数码', '软件应用', '计算机技术', '工业·工程·机械', '极客DIY'],
'动物圈': ['喵星人', '汪星人', '野生动物', '爬宠', '大熊猫', '动物综合'],
'舞蹈': ['宅舞', '舞蹈综合', '舞蹈教程', '街舞', '明星舞蹈', '中国舞'],
'国创': ['国产动画', '国产原创相关', '布袋戏', '资讯', '动态漫·广播剧'],
'鬼畜': ['鬼畜调教', '音MAD', '人力VOCALOID', '鬼畜剧场', '教程演示'],
'纪录片': ['人文·历史', '科学·探索·自然', '军事', '社会·美食·旅行'],
'番剧': ['资讯', '官方延伸'],
'电视剧': ['国产剧', '海外剧'],
'电影': ['其他国家', '欧美电影', '日本电影', '国产电影'],
'无': ['无', '其他', '']
}
df['category'] = df['tag_name'].apply(
lambda x: [cate for cate, tags in category.items() if x in tags][0],
)
可视化
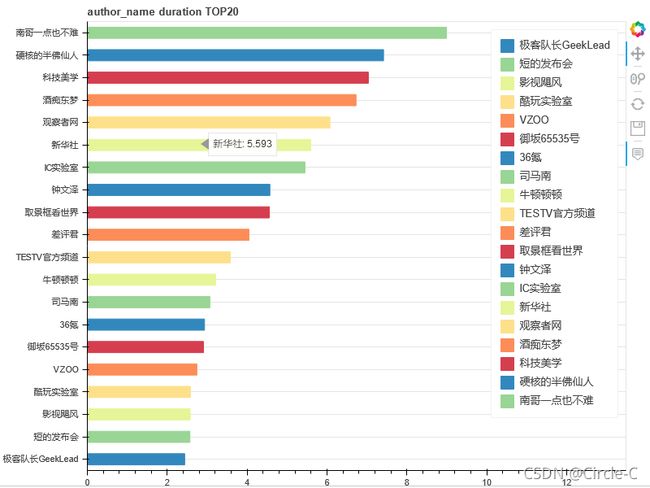
TOP20的up主(按视频数排行)
from bokeh.models import ColumnDataSource
from bokeh.palettes import Spectral6 # ['#3288bd', '#99d594', '#e6f598', '#fee08b', '#fc8d59', '#d53e4f']
key = 'author_name'
value = 'videos'
agg_fun = 'sum'
top_count = 20
df_ = df.groupby([key]).agg({value: agg_fun}).sort_values(by=[value], ascending=False)
names = df_.index.to_list()[:top_count][::-1]
values = df_[value].to_list()[:top_count][::-1]
source = ColumnDataSource(data=dict(names=names, values=values, color=Spectral6*(len(names)//6+1))) # color=Spectral6
# 工具条
TOOLS = "pan,wheel_zoom,reset,hover,save"
p = figure(x_range=[0, values[-1]*1.5], y_range=names, plot_width=800, plot_height=len(names)*30,
title=f"{key} {value} TOP{top_count}",
toolbar_location='right', tools=TOOLS,
tooltips="@names: @values"
)
p.hbar(y='names',left=0,right='values', height=0.5 ,color='color', legend="names", source=source)
p.xgrid.grid_line_color = None
# p.legend.orientation = "horizontal"
p.legend.location = "top_right"
show(p) 
TOP20的up主(按视频时长排行,单位:小时)
标签TOP20(按视频数排行)
from bokeh.models import ColumnDataSource
from bokeh.palettes import Spectral6 # ['#3288bd', '#99d594', '#e6f598', '#fee08b', '#fc8d59', '#d53e4f']
key = 'tag_name'
value = 'videos'
agg_fun = 'count'
top_count = 20
df_ = df.groupby([key]).agg({value: agg_fun}).sort_values(by=[value], ascending=False)
names = df_.index.to_list()[:top_count][::-1]
values = df_[value].to_list()[:top_count][::-1]
source = ColumnDataSource(data=dict(names=names, values=values, color=Spectral6*(len(names)//6+1))) # color=Spectral6
# 工具条
TOOLS = "pan,wheel_zoom,reset,hover,save"
p = figure(x_range=[0, values[-1]*1.5], y_range=names, plot_width=800, plot_height=len(names)*30,
title=f"{key} {value} TOP{top_count}",
toolbar_location='right', tools=TOOLS,
tooltips="@names: @values"
)
p.hbar(y='names',left=0,right='values', height=0.5 ,color='color', legend="names", source=source)
p.xgrid.grid_line_color = None
# p.legend.orientation = "horizontal"
p.legend.location = "top_right"
p.legend.click_policy="hide"
show(p)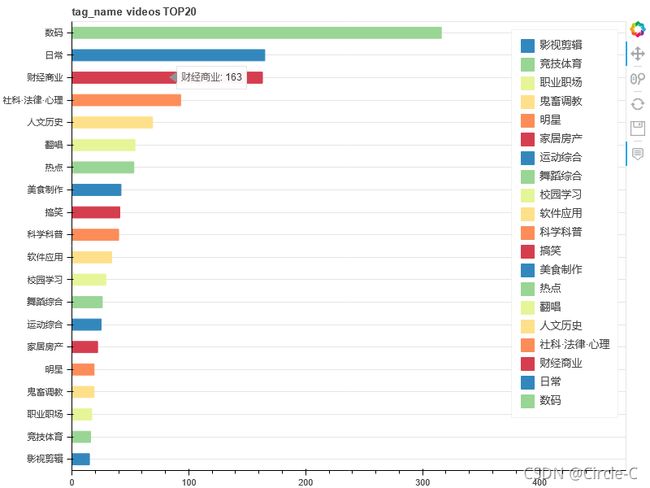
标签TOP20(按视频时长排行,单位:秒)
from bokeh.models import ColumnDataSource, LabelSet
from bokeh.palettes import Spectral6 # ['#3288bd', '#99d594', '#e6f598', '#fee08b', '#fc8d59', '#d53e4f']
key = 'tag_name'
value = 'duration'
agg_fun = 'count'
top_count = 20
df_ = df.groupby([key]).agg({value: agg_fun}).sort_values(by=[value], ascending=False)
names = df_.index.to_list()[:top_count][::-1]
values = df_[value].to_list()[:top_count][::-1]
text = [str(val) for val in values]
source = ColumnDataSource(data=dict(names=names, values=values, color=Spectral6*(len(names)//6+1), text=text)) # color=Spectral6
# 工具条
TOOLS = "pan,wheel_zoom,reset,hover,save"
p = figure(x_range=[0, values[-1]*1.5], y_range=names, plot_width=800, plot_height=len(names)*30,
title=f"{key} {value} TOP{top_count}",
toolbar_location='right', tools=TOOLS,
tooltips="@names: @values"
)
p.hbar(y='names',left=0,right='values', height=0.5 ,color='color', legend="names", source=source)
# p.xgrid.grid_line_color = None
p.ygrid.grid_line_color = None
# p.legend.orientation = "horizontal"
# 标签
labels = LabelSet(x="values",y="names",text="text",source=source)
# 添加图层
p.add_layout(labels)
p.legend.location = "top_right"
p.legend.click_policy="hide"
show(p) 
旭日图 按类别
import base64
from math import pi, sin, cos
from bokeh.util.browser import view
from bokeh.colors.named import (aquamarine, bisque, crimson, darkolivegreen, firebrick, gainsboro, hotpink, indigo, khaki,
mediumvioletred, olivedrab, orchid, paleturquoise, skyblue, seagreen, tomato, orchid, firebrick, lightgray)
from bokeh.document import Document
from bokeh.models.glyphs import Wedge, AnnularWedge, ImageURL, Text
from bokeh.models import ColumnDataSource, Plot, Range1d
from bokeh.resources import INLINE
from bokeh.sampledata.browsers import browsers_nov_2013, icons
# 数据
df_ = df.groupby(by=['category', 'author_name']).agg(
count=('author_name', 'count'),
duration_avg=('duration', 'mean'),
duration_sum=('duration', 'sum'),
author_face=('author_face', 'first')
)
df_ = df_.reset_index()
df_['duration_avg'] = df_['duration_avg'] / 60
df_['duration_sum'] = df_['duration_sum'] / 60
df_['duration_percentage'] = df_['duration_sum'] / df_['duration_sum'].sum() * 100
xdr = Range1d(start=-2, end=2)
ydr = Range1d(start=-2, end=2)
# 画布
plot = Plot(x_range=xdr, y_range=ydr, plot_width=800, plot_height=800)
# 自定义属性
plot.title.text = "Web browser market share (November 2013)"
# plot.toolbar_location = None
# 调色
colors = {"动物圈": aquamarine, "动画": bisque, "国创": crimson, "娱乐": darkolivegreen, "影视": firebrick, "时尚": gainsboro,
"汽车": hotpink, "游戏": indigo, "生活": khaki, "知识": skyblue, "科技": seagreen, "纪录片": tomato, "美食": orchid,
"舞蹈": paleturquoise, "运动": firebrick, "音乐": olivedrab, "鬼畜": mediumvioletred, "无": lightgray, "Other": lightgray}
# 数据预处理
aggregated = df_.groupby("category").agg(sum)
selected = aggregated[aggregated.duration_percentage >= 1].copy()
selected.loc["Other"] = aggregated[aggregated.duration_percentage < 1].sum()
categorys = selected.index.tolist()
radians = lambda x: 2*pi*(x/100)
angles = selected.duration_percentage.map(radians).cumsum()
end_angles = angles.tolist()
start_angles = [0] + end_angles[:-1]
name_first = selected.index.tolist()
percentages = [('{:.2f}%'.format((y - x) / 6.2831852 * 100)) for x, y in zip(start_angles, end_angles)]
categorys_source = ColumnDataSource(dict(
start = start_angles,
end = end_angles,
colors = [colors[category] for category in categorys ],
name_first = name_first,
percentages = percentages,
))
# 绘图
glyph = Wedge(x=0, y=0, radius=1, line_color="white",
line_width=2, start_angle="start", end_angle="end", fill_color="colors")
glyph_renderer = plot.add_glyph(categorys_source, glyph)
# 添加hover工具
tooltips = f"@name_first: @percentages"
plot.add_tools(HoverTool(tooltips=tooltips, renderers=[glyph_renderer]))
def polar_to_cartesian(r, start_angles, end_angles):
cartesian = lambda r, alpha: (r*cos(alpha), r*sin(alpha))
points = []
for start, end in zip(start_angles, end_angles):
points.append(cartesian(r, (end + start)/2))
return zip(*points)
first = True
for category, start_angle, end_angle in zip(categorys, start_angles, end_angles):
versions = df_[(df_.category == category) & (df_.duration_percentage >= 0.1)]
angles = versions.duration_percentage.map(radians).cumsum() + start_angle
end = angles.tolist() + [end_angle]
start = [start_angle] + end[:-1]
angle = end[-1] - start[0]
angle = angle if angle else 1
name_second = versions['author_name'].tolist() if not versions.empty else ['orthers']
if len(start) > len(name_second):
name_second += ['orthers']
percentages = [(y - x) / angle for x, y in zip(start, end)]
max_percentage = max(percentages) if max(percentages) else 1
base_color = colors[category]
fill = [ base_color.lighten((1 - i / max_percentage)*0.2).to_hex() for i in percentages ]
percentages = [('{:.2f}%'.format((y - x) / 6.2831852 * 100)) for x, y in zip(start, end)]
# extra empty string accounts for all versions with share < 0.5 together
text = [ number if share >= 1 else "" for number, share in zip(versions.author_name, versions.duration_percentage) ] + [""]
x, y = polar_to_cartesian(1.25, start, end)
source = ColumnDataSource(dict(start=start, end=end, fill=fill,
name_second=name_second, percentages=percentages))
glyph = AnnularWedge(x=0, y=0,
inner_radius=1, outer_radius=1.5, start_angle="start", end_angle="end",
line_color="white", line_width=2, fill_color="fill")
glyph_renderer = plot.add_glyph(source, glyph)
# 添加hover工具
tooltips = f"@name_second: @percentages"
plot.add_tools(HoverTool(tooltips=tooltips, renderers=[glyph_renderer]))
text_angle = [(start[i]+end[i])/2 for i in range(len(start))]
text_angle = [angle + pi if pi/2 < angle < 3*pi/2 else angle for angle in text_angle]
text_source = ColumnDataSource(dict(text=text, x=x, y=y, angle=text_angle))
glyph = Text(x="x", y="y", text="text", angle="angle",
text_align="center", text_baseline="middle", text_font_size="8pt")
plot.add_glyph(text_source, glyph)
text = [ "%.02f%%" % value for value in selected.duration_percentage ]
x, y = polar_to_cartesian(0.7, start_angles, end_angles)
text_source = ColumnDataSource(dict(text=text, x=x, y=y))
glyph = Text(x="start", y="end", text="text", text_align="center", text_baseline="middle")
plot.add_glyph(text_source, glyph)
# 显示
show(plot)
