Python数据可视化神器Plotly:小白指南篇
先插一个我觉得特别好的教程
或者说是范例?
简单易懂的plotly范例
超详细的教程
这边还是安利一下百度echart这个应用,数据可视化很强大,很炫酷,想了解的话可以去官网了解以下
Plotly简介
- Plotly是一个基于Javascript的绘图库。相比matplotlib使用更为便捷,效果也非常美观
- Plotly的保存与分享很方便,可以与Web应用集成,分享后的效果与本机现实一致
- Plotly的默认绘图结果是Html网页文件
Plotly基础
Plotly基本使用
(使用jupyter notebook进行编写)
plotly绘制二维图像
折线图
首先安装plotly。使用国内源pip install plotly -i https://pypi.mirrors.ustc.edu.cn/simple会快一点。
然后就可以进行导入了。
- 首先导入plotly库
import plotly- 然后用pandas导入已经准备好的数据集
import pandas as pd
data = pd.read_csv('path/database.csv')导入数据集后,假设要绘制以名为dataA的列数据为自变量(x),以名为dataB的列数据为应变量(y)。
首先需要提取两列的内容(以列表的形式),并预览。
(写的时候小心传入字符串时不要忘记写 ’ ')
data['dataA'], data['dataB']截取一段数据的话可以对数据进行逻辑运算,如:
data1 = data[(data['dataA'] >= '_data01') & (data['dataA'] <= 'data02')]绘图工具一般是plotly中的graph_objects工具,因此对该工具进行导入。
因此对该工具进行导入。
import plotly.graph_objects as go进行绘图。
plotly中画线和画点都使用Scatter方法。
#首先画一条线
line = go.Scatter(x=data['dataA'],y=['dataB'])
#其次创建一个图表fig用来显示这条线
fig = go.Figure(line)
#显示
fig.show()此时我遇到的问题是图像无法显示…就是一片空白orz,各种方法都不好使,所以转战pycharm。所有的代码还是原样输入pycharm运行,世界都清净了。
跑出图以后点右上角小摄像机图标可以下载图片。
如果需要同时画多条曲线,则需要将代码更改为:
#首先画一条线
line1 = go.Scatter(x=data['dataA'],y=['dataB'])
line2 = go.Scatter(x=data['dataC'],y=['dataD'])
#其次创建一个图表fig用来显示这条线
fig = go.Figure([line1,line2])
#显示
fig.show()条形图
基本同上,把绘图命令直接修改为:
bar = go.Bar(x='dataA', y='dataB')在使用条形图时,有时需要在条形图上方显示数字等操作。实现代码如下:
(textposition可更改为’auto’, ‘inside’, ‘outside’)
bar = go.Bar(x='dataA', y='dataB', text='dataB', textposition='auto')如果需要两组数据对比,则在fig=go.figure中添加一组数据,效果如下

直方图
基本同上。但是这边只需要传入一个参数,如下:
hist = go.Histogram(x=data['DataB'])
fig = go.Figure(hist)
fig.show()
hist中有一个常用参数:bargap,至每一段图的间距,修改如下:
fig.update_layout(
bargap=0.1
)修改后与修改前对比如下:
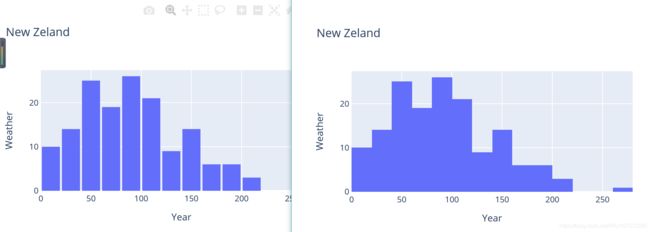
另一个常用参数,用于更改每条bar的间距,也就是组距:用xbins修改。
hist = go.Histogram(x=data['DataB'], xbins={
size:10})散点图
与折线图同样使用Scatter,但需要在命令中加入新的参数:mode='markers’:
points = go.Scatter(x=data['Data1'], y=data['Data2'], mode='markers')散点图一般负责表达趋势、规律。所以需要更多的参数来更改图表中的点的表现。
- 改变部分点的颜色
代码加入marker参数。marker传入一列数据如data3,表示按照data3来将颜色分为不同的类。注意,color中传入的参数必须是数字或颜色,因此需要把用来区分的data转换为数字。
这种转换实现的传统方法思路如下:
#按照data3这列数据分类
#找出所有的类的名字及类的数量
#返回一个列表,例如:
#Index(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='object', name='Name')
data.groupby('Name').count().index
#知道所有类后,编写一个字典
#使每个类都对应一种颜色
name_to_color = {
'name1':0,
'name2':1,
'name3':2
}
#最后给数据集加入新的一列:color
#把name映射到新的一列
data['color'] = data['Name'].map(name_to_color)
#给点上色
points = go.Scatter(x=data['Data1'],
y=data['Data2'],
mode='markers',
marker={
'color': data['data3']}
)但是potly给出了自己的方法:express,用法如下
from plotly import express as px
fig = px.scatter(data, x=data['data1'], y=data['data2'],color=data['data3'])
fig.show()而且还会自动更改图例!效果如图:
(标签是我自己加的)
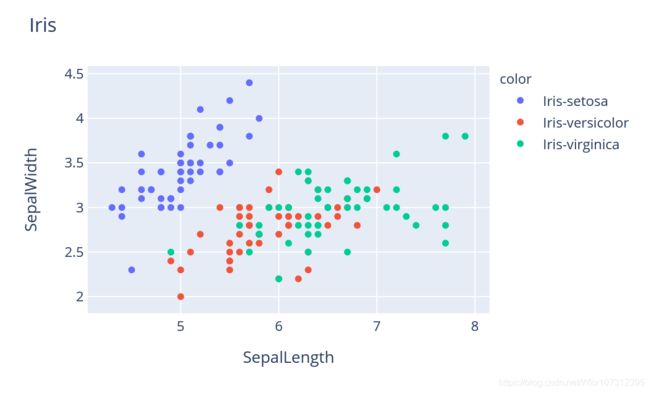
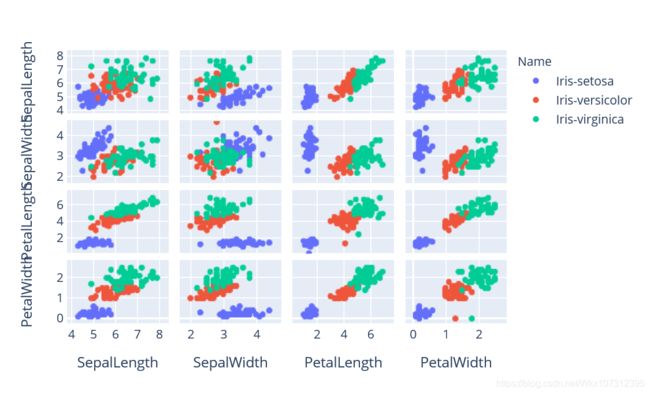
而且express在多维度绘图中也表现极佳
以众所周知的鸢尾花数据集为例
import plotly
from plotly import graph_objects as go
import pandas as pd
from plotly import express as px
data = pd.read_csv('C:/Users/MI/Documents/学习/data/iris.csv')
fig = px.scatter_matrix(data, color='Name', dimensions=['SepalLength','SepalWidth','PetalLength','PetalWidth'])
fig.show()
#dimension即维度,不写的话会有多余的图像
Plotly绘制三维图像
同样使用plotly.graph_objects进行绘图,导入plotly.graph_objects和pandas同二维图。
折线图
绘制方法和二位相似,只不过需要使用Scatter3d方法绘制。代码如下:
line = go.Scatter3d(x=data['x'], y=data['y'], z=data['z'])
fig = go.Figure(line)
fig.show()这种方法会把所有的数据点和折线都画出来。如果不需要画点/线的话,绘图时加入参数mode:
只画点:mode=‘markers’
只画线:mode=‘lines’
line = go.Scatter3d(x=data['x'], y=data['y'], z=data['z'], mode='lines')如果要更改点的大小和颜色:在如上的代码行加入参数markers,假设设置大小为5、颜色为红色,即marker={‘size’ : 5, ‘color’ : ‘red’}
from plotly import graph_objects as go
import pandas as pd
line = go.Scatter3d(x=data['x'], y=data['y'], z=data['z'], mode='markers'
, marker={
'size' : 5, 'color' : 'red'})
fig = go.Figure(line)
fig.show()如果使用express方法绘图,代码如下:
from plotly import graph_objects as go
import pandas as pd
from plotly import express as px
data = pd.read_csv('C:/Users/MI/Documents/学习/data/3d-line1.csv')
fig = px.scatter_3d(x=data['x'], y=data['y'], z=data['z'], color=data['color'])
fig.show()Plotly图表优化
在go.Scatter中,可以加入其他各种参数。一般常用参数如下:
- name:
表示图线名称。显示在图例中。
line = go.Scatter(x=data['data1'], y=data['data2'], name='data_name')- title:图表名
- xaxis_title/yaxis_title:相当于matplotlib中的xlable/ylable,坐标轴标签
- tickmode: 刻度类型。可自行更改为:‘str‘即字符串型,’auto’表示自动根据输入的数据来决定,’linear’表示线性的数值型,’array’表示由自定义的数组来表示(用数组来自定义刻度标签时必须选择此项)
- tickvals:坐标轴刻度标签的替代(tickmode此时必须被设置为’array’)
- ticktext: 标签值
(以上参数修改方法如下)
fig.update_layout(
title='title',
xaxis_title='xlable',
yaxis_title='ylable',
)- 改变点的大小
此处data[‘size’]是我根据数据集中的某一类名称映射的列表
fig = px.scatter(data, x=data['SepalLength'], y=data['PetalLength'],
color=data['Name'], size=data['size'],size_max=5)