淘宝爬虫:看看房地产拍卖行情怎么样?附可视化分析
文章目录
- 前言
- 一、爬虫篇
-
- 1、查询页
-
- 1.1、分析网页结构
- 1.2、请求与解析
- 2、详情页
-
- 2.1、关于反爬
- 2.2、直观数据解析
- 2.3、待加载数据获取与解析
- 2.4、jsonp 跨域数据获取与解析
- 2.5、附件下载
- 二、分析篇
-
- 1、杭州哪里有法拍房,有多少?
- 2、拍的都是什么样的房子?
- 3、拍卖热度如何?
- 4、有多少人关注,有多少人参与?
- 5、法拍房真的有市场吗,值钱吗?
- 6、我还有机会吗?
- 7、用动态可视化回顾一下吧!
- 三、后话:定时邮件提醒
前言
本文为数据采集和分析的综合练习,仅供学习参考,勿作他用!首先来看一下数据需求:
1、进入到住宅用房拍卖页面,以杭州市数据为例;
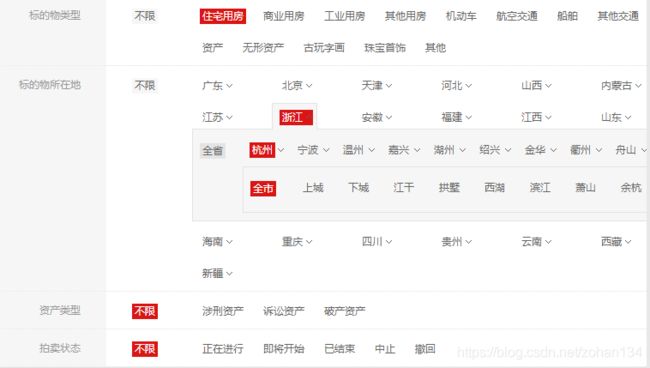
2、需要将发布的所有杭州市法拍房的信息整理至 EXCEL 表格中;
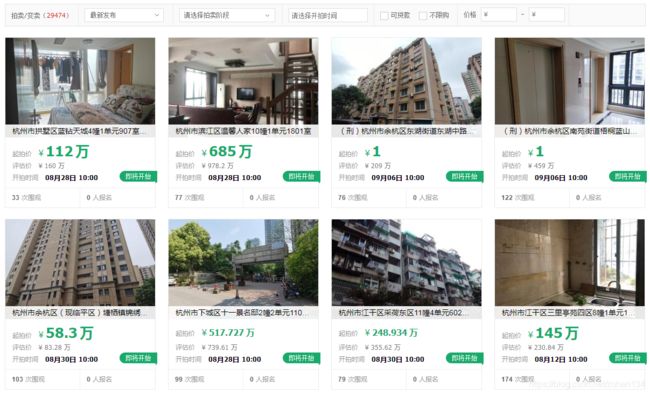
3、部分需求字段在页面中的位置:
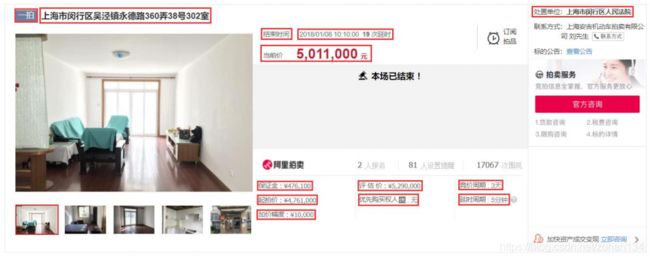
事不宜迟,开工!
一、爬虫篇
1、查询页
1.1、分析网页结构
通过观察可以发现,每页 40 条记录,最大 150 页,也就是说从基本页最多只能获取到 6000 条记录,而杭州市记录总量有 2 万余条。

但杭州市各区的数据都不超过 6000 条,因此我们可以分区爬取数据。
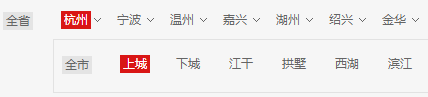
接着,在开发者模式下不难找到所需数据的出处。
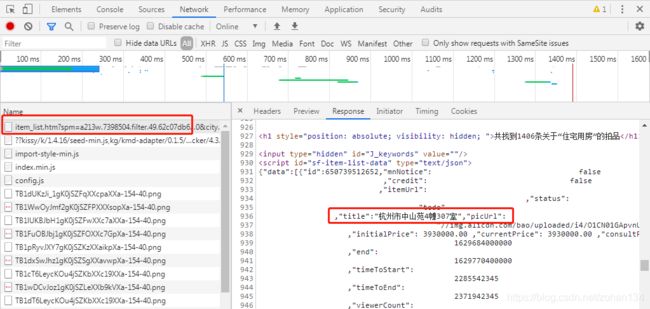
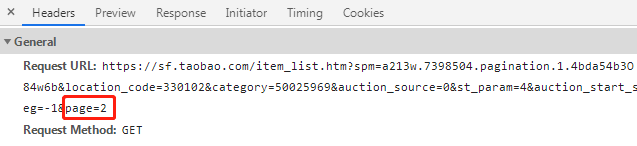
我们只需要修改请求连接中的 page 值就可以实现翻页爬取。
1.2、请求与解析
下面开始编写请求代码,很轻松就能获取到查询页的响应内容。
def search_response(p): # 爬取查询到的一页数据
url = f'https://sf.taobao.com/item_list.htm?spm=a213w.7398504.filter.50.70c67db6iX3uXM&location_code=330103&category=50025969&auction_source=0&city=&province=&st_param=-1&auction_start_seg=-1&page={
p}'
headers = {
'cookie': cookie,
'user-agent': "Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
}
res = requests.get(url, headers=headers)
return res.text
根据网页源码分析,已知查询页的数据是嵌套的 json 列表,储存在 id="sf-item-list-data" 的 script 标签中,笔者采用美丽汤(beautifulsoup)进行解析,该解析器对 HTML 页面相性优异,如果不熟悉万能的正则表达式,推荐尝试。
def analyze(response): # 解析查询页
soup = BeautifulSoup(response, "html.parser")
script_data = soup.find('script', {
'id': 'sf-item-list-data'}).get_text()
json_data = json.loads(script_data)
json_dic_lst = json_data['data']
total = pd.DataFrame()
for dic in json_dic_lst:
df = pd.DataFrame({
'id': [dic['id']],
'itemUrl': [dic['itemUrl']],
'title': [dic['title']],
})
total = total.append(df)
return total
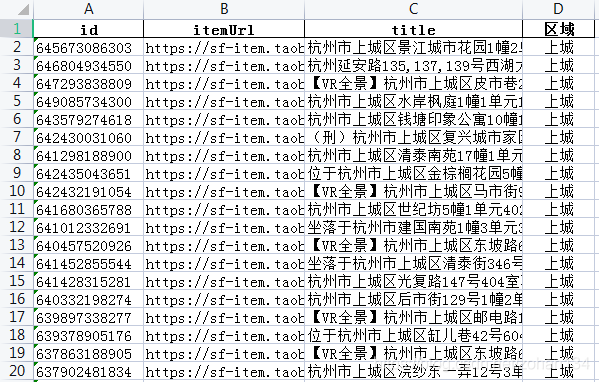
最终将各区查询页汇总整理如下,id 为每条房产记录的识别号,用于在最后连接查询页与详情页。
2、详情页
2.1、关于反爬
详情页(初步的)请求头参数也比较简单,请求地址即是查询页中的 itemUrl,从中可以截取出 track_id 参数。但详情页的反爬比较强烈,笔者采用多 user-agent 与 cookie 的方式来尝试规避,效果仍不够理想,且 cookie 池需要多个账号,之后又增加了代理 IP 池。
ua_lst = ["Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
]
cookie_lst = [cookie_1, cookie_2, cookie_3, ...]
headers = {
'cookie': random.choice(cookie_lst ),
'user-agent': random.choice(ua_lst ),
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'referer': 'https://sf.taobao.com/item_list.htm?spm=a213w.7398504.filter.49.62a854b3DbBPQy&location_code=330102&category=50025969&auction_source=0&city=&province=&st_param=-1&auction_start_seg=-1',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'authority': 'sf-item.taobao.com',
'upgrade-insecure-requests': '1',
'Connection': 'keep-alive'
}
params = {
'spm': 'a213w.7398504.filter.49.62a854b3DbBPQy',
'track_id': f'{
track_id}'
}
proxies = {
'http': random.choice(http_lst)
}
此外,在每次请求后随机睡眠也有助于减少被制裁的频率。
res = requests.get(url, headers=headers, params=params, proxies=proxies).text
df = detail_analyze(res, headers) # 相应内容解析函数
sleep(random.choice([0.6, 0.8, 1, 1.2, 1.4, 1.6, 1.8, 2, 2.2, 2.4, 2.6, 2.8, 3]))
2.2、直观数据解析
下面根据需求字段来解析详情页的响应内容,大部分数据可在同一个响应内容中直接获取。
soup = BeautifulSoup(response, "html.parser") # 创建解析器
item_id = soup.find('input', {
'id': 'J_ItemId'})['value'] # 与查询页对应的id
item_status = soup.find('span', {
'class': 'item-status'}).text # 拍卖次数
price = soup.find('span', {
'class': 'pm-current-price J_Price'}).text # 当前价格
first_person = soup.find('span', {
'class': 'pay-mark i-b pay-first'}).find_next_sibling().text # 优先人
delayed = soup.find('span', {
'class': 'pay-mark J_Delay i-b'}).find_next_sibling().text # 延时周期
timeTitle = soup.find('span', {
'class': 'title J_TimeTitle'}) # 拍卖状态
timeLeft = soup.find('span', {
'class': 'countdown J_TimeLeft'}).text # 拍卖时间
baoming = soup.find('em', {
'class': 'J_Applyer'}).text # 报名人数
weiguan = soup.find('em', {
'id': 'J_Looker'}).text # 围观次数
announcement = soup.find('span', {
'class': 'unit-txt unit-name item-announcement'}).find('a').next.strip() # 处置单位
保证金、评估价、起拍价、加价幅度、竞价周期这 5 个数据比较奇葩,它们无法靠唯一的 class 或 id 属性来定位。
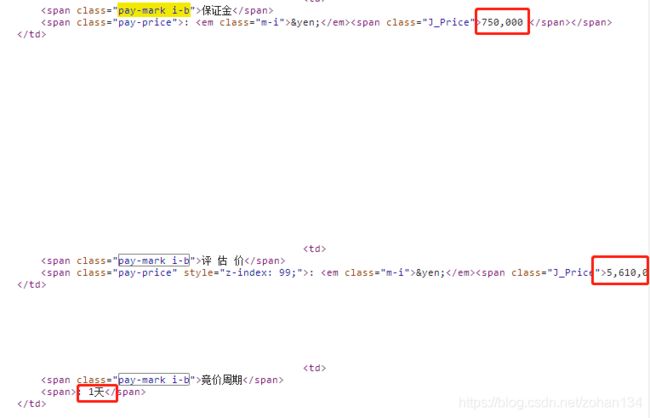
直接根据 class="pay-mark i-b" 把相关内容全都拿出来,发现不同类型/状态的房产详情页中,(至少)有 5 种情形(数据项不一致,且显示位置发生改变),如果要用索引从 Info_lst 中获取出对应的数据,还要需要写多个条件判断,比较繁琐。也可以根据价格之间的大小逻辑关系进行处理。
for el in soup.findAll('span', {
'class': 'pay-mark i-b'}):
info_lst.append(el.find_next_sibling().text)
''' 案例 id
523179234073 [': ¥200,000 ', ': ¥1,339,200', ': 1天', ': ¥1,180,000 ', ': ¥10,000']
549054948095 [': ¥1,500,000 ', ': ¥50,000', ': 1天', ': ¥8,445,314 ']
641874486020 [': ¥500,000 ', ': ¥10,000,000 ', ': 1天', ': 清算', ': ¥10,000']
618911620314 [': ¥110,000 ', ': ¥868,000', ': ¥555,520 ', ': 清算', ': ¥10,000', ': 1天']
559641084121 [': ¥5,548,800 ', ': ¥30,000', ': 60天', ': ¥960,000 ', ': ¥9,600,000', ': ¥5,548,800 ']
'''
2.3、待加载数据获取与解析
标的物介绍和竞买公告是动态加载的,其加载的数据源地址直接就写在了源码中,再度爬取一波即可,这也是详情页的整体解析函数 detail_analyze(res, headers) 中还需传入 headers 的原因。
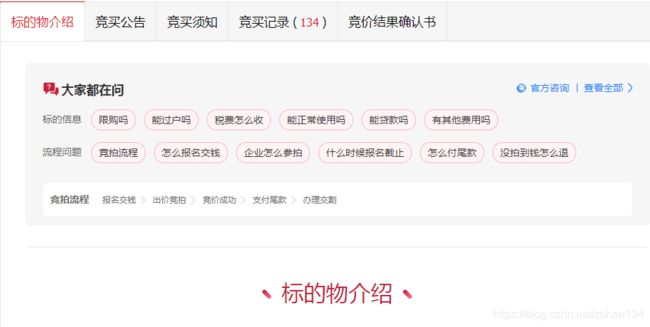
![]()
# 标的物介绍部分
introduce_url = soup.find('div', {
'id': 'J_desc'})['data-from']
introduce_res = requests.get(introduce_url if 'https:' in introduce_url else 'https:' + introduce_url, headers=headers)
introduce = BeautifulSoup(introduce_res.text, "html.parser").get_text() # 标的物介绍整体内容
# 竞买公告部分
noticeDetail_url = soup.find('div', {
'id': 'J_NoticeDetail'})['data-from']
noticeDetail_res = requests.get('https:' + noticeDetail_url, headers=headers)
noticeDetail_content = notice_analyze(noticeDetail_res.text) #公告整体内容
2.4、jsonp 跨域数据获取与解析
继续解决还未获取到的信息吧!首先是提醒人数,发现它在源码中显示为 0,但显示在页面同一区域的报名人数和围观次数却是直接加载的,推测 tb 这样设计是因为用户设置提醒的操作较为频繁,也就是这个数据会经常变化,所以将它存放在其他地方,便于实时读取最新数值。可是,它却没有像标的物介绍那样摆明资源地址,那它究竟藏在哪呢?

在请求文件列表中探索后发现,有多个 get 开头的文件,可想而知这些文件与动态数据有所关联。最后定位到如下文件,找到了我们需要的信息,看上去像是 json 格式,但 jsonp 是什么?
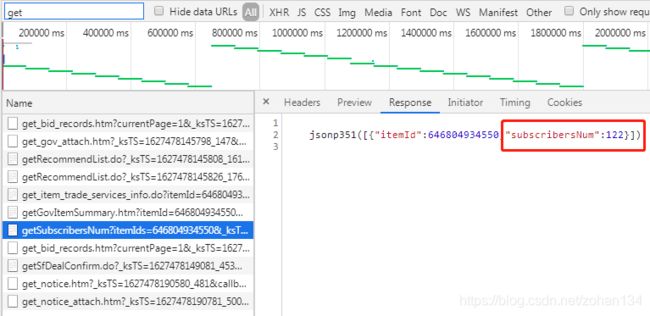
以下摘自百度百科,简而言之 jsonp 就是一种跨域获取 json 数据的方法,感兴趣的童鞋可以深入研究,自己实现一个 jsonp 案例。
JSONP(JSON with Padding)是JSON的一种“使用模式”,可用于解决主流浏览器的跨域数据访问的问题。由于同源策略,一般来说位于 server1.example.com 的网页无法与不是 server1.example.com的服务器沟通,而 HTML 的 script 元素是一个例外。利用 script 元素的这个开放策略,网页可以得到从其他来源动态产生的 JSON 资料,而这种使用模式就是所谓的 JSONP。
那么回到爬虫,该爬的数据还是一样的道理,找到要请求的地址,冲就完事儿了。乍一看,参数构造有点复杂,但里面还是有我们熟悉的部分,itemIds 就是前文所述的记录 id,ksTs 这一串数字想必和时间戳有关,callback 是 ksTs 尾部值 +1。
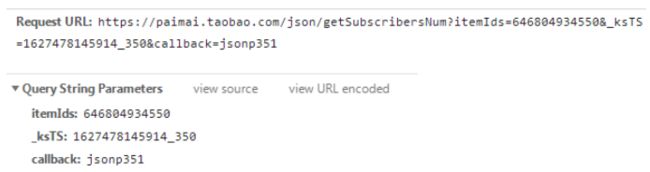
进一步分析发现规律后,编写构造代码,如此即可获取到 jsonp 回调的内容。
t_list = str(time()).split(".")
ksts = t_list[0] + t_list[1][:3] + "_" + t_list[1][3:]
call = str(int(t_list[1][3:]) + 1)
jsonp_url = f'https://paimai.taobao.com/json/getSubscribersNum?itemIds={
itemId}&_ksTS={
ksts}&callback=jsonp{
call}'
jsonp_headers = {
'cookie': random.choice(cookie_lst),
'user-agent': random.choice(ua_lst),
'referer': 'https://sf-item.taobao.com/',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
}
jsonp_params = {
'_ksTS': ksts,
'callback': call,
'itemId': itemId
}
jsonp_res = requests.get(jsonp_url, headers=jsonp_headers, params=jsonp_params).text
还有竞价记录等与设置提醒人数类似,不做赘述。
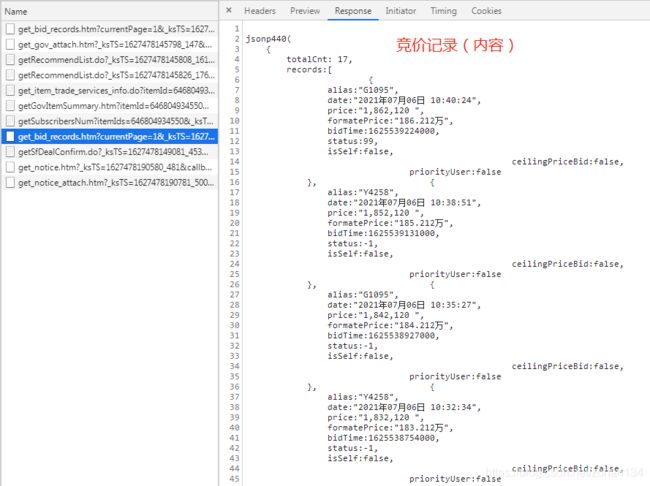
2.5、附件下载
最后我们要实现的是附件下载。
英雄不问出处,数据要问,我们可以在 data-from 属性中发现一个地址,是否就是附件链接呢?
请求后返回的是附件文件名和附件 id,不要着急,再找找真正的下载链接。
null([{“title”:“H0578-杭州市上城区郡亭公寓3幢207室-结果.doc”,“id”:“7LI2A72GS4WEW”,“fileType”:0}]);
常识往往容易被忽视,其实直接右键即可得知下载链接。

再观察一下附件 id 与其下载链接的关系,构造得到下载链接的列表,通过 get 请求就可得到文件流,按照对应的附件文件名,以二进制写入文件即可实现下载。
soup = BeautifulSoup(res, "html.parser")
download_url = soup.find('p', {
'id': 'J_DownLoadFirst'})['data-from']
_res = requests.get('https:' + download_url ).text
file_lst = re.findall(r'"title":"(.*?)",', _res)
file_ids = re.findall(r'"id":"(.*?)"', _res)
spm = soup.find('body')['data-spm']
links = [f'https://sf.taobao.com/download_attach.do?spm=a213w.{
spm}.tabs.8.6ea0294bWdhxUM&attach_id={
id}' for id in file_ids]
for filename, link in list(zip(file_lst, links)):
file = requests.get(link, headers=headers)
with open(filename, 'wb') as f:
f.write(file.content)
二、分析篇
笔者将通过回答以下问题,对所爬数据进行一次简单的数据分析,限于篇幅,直接呈现分析结果。
1、杭州哪里有法拍房,有多少?
截至2021年6月30日,在阿里拍卖平台中,杭州市共有24064套法拍房,分布在全市13个区域(其它为郊区、景区及行政规划调整的区域等),余杭、萧山、淳安等3个区域的法拍房合计占比约 4 成。
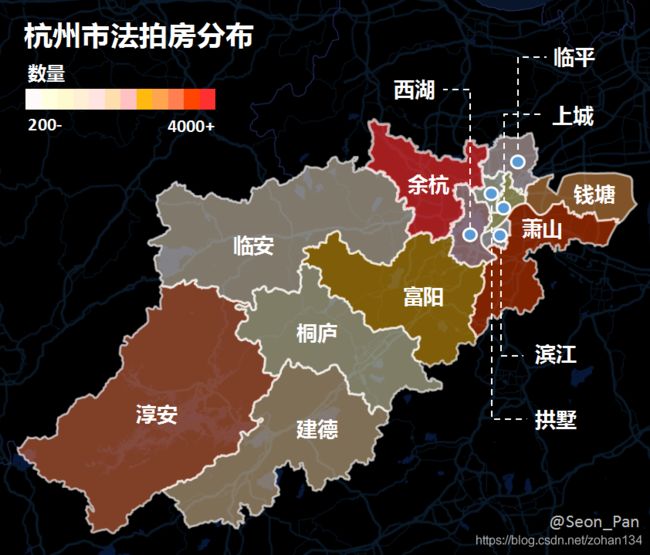
此外,各区法拍房数量排名与其GDP、常住人口数排名均无明显相关性,法拍房在上述三区相对集中或许有其他原因,可尝试从来源角度进一步对各区分析,找到影响法拍房分布的因素。
法拍房,即是法院依法拍卖的房产,其来源主要为:①借贷抵债、②司法没收、③无主(如凶宅)。
2、拍的都是什么样的房子?
根据竞买公告中的描述,杭州市绝大部分的法拍房为公寓,部分附带车位、家具、家电等。但似乎也存在一些非住宅,如厂房,说明 tb 的住宅用房拍卖品类中,不全是住宅(搞事情吗)。

从房产的面积区间,也可以一窥究竟。分析杭州市的法拍房面积发现,超过 7 成小于 200 平方米,可以认为是住宅;约 2 成在 200~1000 平方米之间,推测为豪宅或店面、厂房等;而还有 4% 竟然超过 1000 平方米,其中更是有数万坪的级别,推测为商业用地,如企业住所。由此看来,法拍房的选择还是多样的。

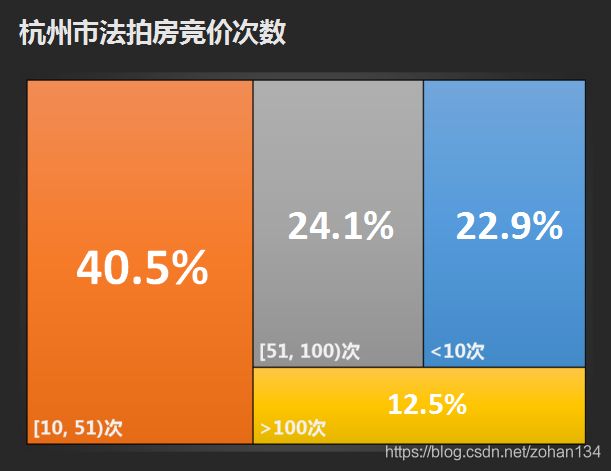
3、拍卖热度如何?
99%以上的拍卖竞价周期为1天,而在有竞价记录的拍卖中,近五成是未经过延时或延时一个小时以内的,说明大部分拍卖都是速战速决。
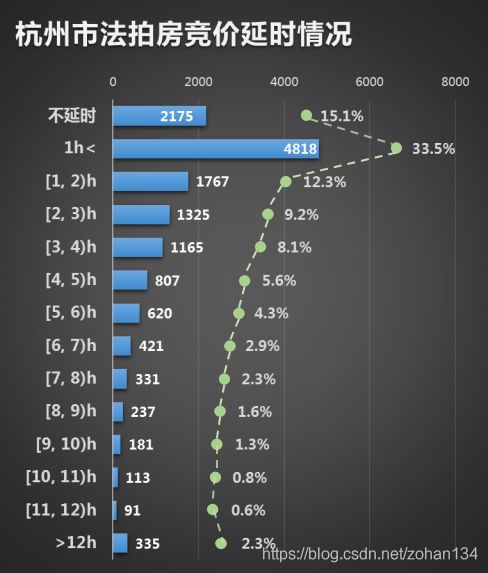
约四成拍卖的互相竞价超过10次,约两成互相竞价超过50次,约一成互相竞价超过100次,可见竞争还是比较激烈的。
4、有多少人关注,有多少人参与?
面对超过 2.4 万套房产的拍卖,报名总人数(次)高达 11.2 万,设置提醒总人数(次)高达 332.2万,围观总次数更是接近 2.5 亿!仅仅一座城市就如此,法拍房的流量可见一斑。绝大多数房产的拍卖报名人数都不超过 50 人,但设置提醒人数在 100 人以上的房产还是有超过 9000 套的,且围观次数在 10000 次以上的房产也有超过 9000 套,看来除了有直接报名参与竞拍的土豪外,还有不少蠢蠢欲动的资本家 吃瓜群众。

我们可以看到有一套房产的报名人数高达 121 人,是什么样的房子这么抢手?进一步探究发现,竟然是一套新中国成立之前就建成的老屋,只有不到 40 坪的大小,评估价 29 万元,最终拍出了 130.8 万的高价。通过全景地图在该位置附近观察,却已找不到符合描述的房子,真是一个谜呀(难道是名人故居?)。

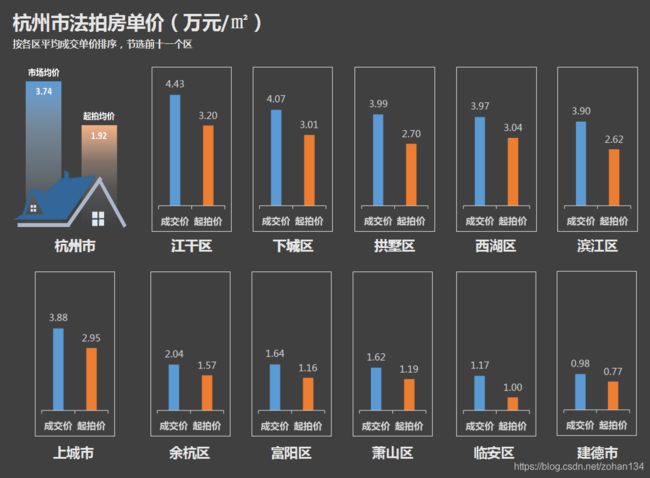
5、法拍房真的有市场吗,值钱吗?
虽然各区最终的拍卖成交价各不相同,但全市平均起拍价只有市场价的大约二分之一!这在一定程度上意味着,如果没有人和你抢,你就相当于是能以五折买一套房,也难怪有这么多人有大胆的想法了。但从拍卖成交情况来看,购房者可能还是以投资为目的居多,不贪便宜,而追求好地段。
6、我还有机会吗?
有,但不完全有。战局瞬息万变,截至本文发布,杭州法拍房数量已达 2.9 万,其中的拍卖状态想必也已经与爬取数据时大有不同,机会与风险,始终都在( 购房需谨慎,本分析不构成任何投资意见!)。
7、用动态可视化回顾一下吧!
三、后话:定时邮件提醒
为了尽可能稳定获取数据,在随机睡眠的情况下每小时可获取 300~400 条记录,爬完所有数据就需要连续作业超过 80 个小时!由于笔者上班时没有外网,就只能把爬虫挂在家里运行,但在办公室又会分心想着程序的运行情况,那么要如何远程关注爬取过程呢?笔者采取的是定时发送邮件的方式,来通知自己爬虫的进度。以下为发送纯文本邮件的方法:
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
def send(body_content):
# SMTP服务器,使用qq邮箱
mail_host = "smtp.qq.com"
# 发件人邮箱
mail_sender = "[email protected]"
# 邮箱授权码, 获取方式见所选邮箱的设置页面
mail_license = "***********"
# 收件人邮箱,可以为多个收件人
mail_receivers = ["[email protected]"]
# 构造邮件对象
mm = MIMEMultipart('related')
# 邮件主题
subject_content = """爬虫进度反馈"""
# 设置发送者,注意严格遵守格式,里面邮箱为发件人邮箱
mm["From"] = "sender_name"
# 设置接受者,注意严格遵守格式,里面邮箱为接受者邮箱
mm["To"] = "receiver_1_name"
# 设置邮件主题
mm["Subject"] = Header(subject_content, 'utf-8')
# 邮件正文内容
# 构造文本,参数1:正文内容,参数2:文本格式,参数3:编码方式
message_text = MIMEText(body_content, "plain", "utf-8")
# 向MIMEMultipart对象中添加文本对象
mm.attach(message_text)
# 创建SMTP对象
stp = smtplib.SMTP()
# 设置发件人邮箱的域名和端口,端口地址为25
stp.connect(mail_host, 25)
# 登录邮箱,传递参数1:邮箱地址,参数2:邮箱授权码
stp.login(mail_sender, mail_license)
# 发送邮件,传递参数1:发件人邮箱地址,参数2:收件人邮箱地址,参数3:把邮件内容格式改为str
stp.sendmail(mail_sender, mail_receivers, mm.as_string())
# 关闭SMTP对象
stp.quit()
持续运行爬虫与定时邮件提醒进度的核心方法如下,省略了异常处理和保存的逻辑:
flag_time = datetime(2021, 6, 30, 9, 00, 00) # 定时邮件起始时间
while True:
origin = pd.read_excel("剩余url.xlsx")
url_lst = origin['itemUrl'].to_list()
finish_count = 0
for url in url_lst:
run(url) # 爬虫与解析逻辑,略
finish_count += 1
url_lst.remove(url) # 删除成功爬取的详情页链接
origin = origin.iloc[finish_count: ]
origin.to_excel("剩余url.xlsx", index=False)
now = datetime.now().hour
if now==flag_time.hour:
send(f"剩余{
len(url_lst)}个未爬") # 发送邮件
flag_time = flag_time + timedelta(hours=1) # 更新下一次发送的时间
if len(url_lst) == 0:
break
效果如下所示,嗯,这下可以专心打工了。这里是鸽子放生爱好者,Seon塞翁,我们下一篇再见(咕咕)!~
