Python简单爬虫(以爬取豆瓣高分图书为例)
前言
浏览器或程序的一次请求,网站服务器的一次响应,就构成一次网络爬虫行为。
一个爬虫通常通过爬虫包完成请求HTML,通过解析包完成HTML解析和存储。
爬虫分类:
| 全网爬虫 | 爬取整个互联网,需要定制开发 |
|---|---|
| 网站爬虫 | 爬取一个指定网站的所有内容,使用scrapy |
| 网页爬虫 | 只爬取网页中需要的数据,使用requeset |
以下笔记为爬取“豆瓣小说top100”的部分信息的过程记录,属于简单的html格式网页的爬取
第一步,导入依赖包(爬虫库和解析库)
这里使用到requesets库作为爬虫库,BeautifulSoup4库作为解析库,保存到文件需要使用os库。其中requesets、BeautifulSoup4、lxml为第三方库,需要单独安装
1. BeautifulSoup4简介
BeautifulSoup4是一个能够解析xml和html的第三方库,能够根据xml和html的语法建立解析树,进而高效解析其中的内容。它采用了面向对象的思想,把每个页面当成一个对象,可以通过a.b的方式调用对象的属性。它创建的对象是一个树形结构,包含了页面里面的所有tag元素,如head、body等。
引入方法是:from bs4 import BeautifulSoup
1.1 解析器
BeautifulSoup的使用,首先需要选择解析器
| 解析器 | 使用方法 | 优势 |
|---|---|---|
| Python标准库 | BeautifulSoup(markup,“html.parser” ) | Python的内置标准库,执行速度适中,文档容错能力强 |
| lxml HTML解释器(本次使用) | BeautifulSoup(markup,“lxml”) | 速度快,文档容错能力强 |
| lxml XML解释器 | BeautifulSoup(markup,“xml”) | 速度快,唯一支持XML的解释器 |
1.2 选择器
lxml HTML解释器下的选择器
-
标签选择器
选择元素、获取名称、获取属性、获取内容、嵌套选择、子节点和子孙节点、父节点和祖先节点、兄弟节点
soup.prettify()、soup.title.name、soup.head、soup.p.string、soup.p[‘name’] -
标准选择器
soup.find_all(‘ul’)、find_parents()、find_next_siblings()、find_previous_siblings()
soup.find(‘ul’)、find_parent()、find_next_sibling()、find_previous_sibling() -
CSS选择器(推荐使用)
通过select()、select_one()直接传入CSS选择器即可完成选择
1.3 select() 选择器的用法
CSS的select()用法
| 类访问 | soup.select(’.panel .panel-heading’)) .代表class |
|---|---|
| 标签访问 | soup.select(‘ul li’) |
| id访问 | soup.select(’#list-2 .element’) #代表id |
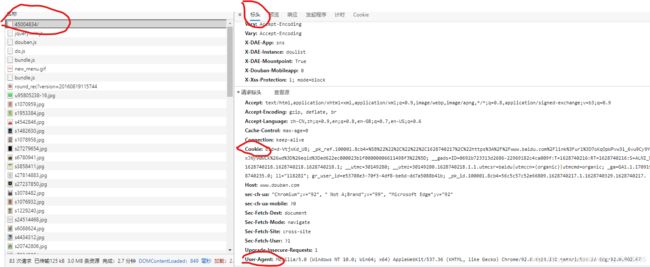
第二步,编写头部headers
编写headers的目的是为了伪装成浏览器,主要包括user-agent(伪装成不同的浏览器),cookie(识别用户身份),Referer(用来表示从哪链接到当前的网页,防盗链措施)
这里只使用到user-agent
1.headers的获取方法

打开【网络】,点击【刷新】


第三步,爬取并保存需要的内容
1. 填写url


2.使用requests库的get方法获取页面源代码
3.使用BeautifulSoup解析源代码
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml') # lxml需要安装,否则会报错
这里选择了lxml解释器,需要先安装lxml库,否则会报错
4.爬取需要的数据
titles = soup.select('#content .article .title') # 爬取的书名
writers = soup.select('#content .article .abstract') # 爬取的作者
rates = soup.select('#content .article .rating_nums') # 爬取的评分
imgs = soup.select('#content .article .post img') # 爬取的图片链接
爬取出来的内容构成一个个单独的列表,需要把原有的信息匹配起来,这里使用了zip方法
Titles = []
Writers = []
Rates = []
for title in titles:
Titles.append(title.text.strip()) # 去除多余的空格
for writer in writers:
Writers.append(writer.text.strip().replace('\n', ',').replace(' ', ''))
for rate in rates:
Rates.append(rate.text.strip())
Articles = zip(Titles, Writers, Rates)
5. 保存到csv文件
创建一个单独的文件夹【douban】,把书名、出版信息、评分写入csv文件,保存到【douban】文件夹中
filepath = 'douban'
if not os.path.exists(filepath):
os.mkdir(filepath)
with open(filepath + '/' + 'novelTop100.csv', 'a', encoding='utf-8') as f: # 以追加模式打开文件
writer = csv.writer(f)
writer.writerows(list(Articles))
【注意】:创建csv文件时,需要设置编码格式为‘utf-8’,否则默认是‘gbk’格式,保存中文时会出现乱码的情况。zip方法创建的是元组,而csv.writerrows()方法参数是列表,所以需要将元组先转换为列表
6. 下载图片
当前网页爬取到的仅为图片的链接,所以图片需要再次访问链接,获取图片的源代码。然后保存为二进制文件
for img in imgs:
download(img['src'])
def download(url):
filepath = 'douban/image'
if not os.path.exists(filepath):
os.mkdir(filepath)
html = requests.get(url, headers=headers)
filename = url.split('/')[-1]
with open(filepath+'/'+filename,'wb') as f: # 打开模式选择‘二进制写入’
f.write(html.content)
爬取多个页面
因为top100分成了4个页面,所以需要爬取4个页面的信息。首先观察url的规律
'https://www.douban.com/doulist/45004834/'
'https://www.douban.com/doulist/45004834/?start=25&sort=time&playable=0&sub_type='
'https://www.douban.com/doulist/45004834/?start=50&sort=time&playable=0&sub_type='
'https://www.douban.com/doulist/45004834/?start=75&sort=time&playable=0&sub_type='
发现每页之间的不同之处在于’start='这一处,第二、三、四页分别是25、50、75,由此推测第一页为0,所以用一个for循环来改变url
for i in range(0, 4):
url = 'https://www.douban.com/doulist/45004834/?start={}' \
'&sort=time&playable=0&sub_type='.format(25*i)
get_data(url)
写在后面
肆意的爬取网络数据并不是文明现象。Robots 排除协议,也被称为爬虫协议,是网站管理者表达是否希望爬虫自动获取网络信息意愿的方法。管理者在网站根目录放置一个robots.txt 文件,并在文件中列出哪些链接不允许爬虫爬取。如果没有该文件则表示网站内容可以被爬虫获得。绝大部分成熟的搜索引擎爬虫都会遵循这个协议,建议个人也能按照互联网规范要求合理使用爬虫技术。
源码
import requests
from bs4 import BeautifulSoup
import os
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67'
}
def get_data(url):
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml') # lxml需要安装,否则会报错
titles = soup.select('#content .article .title') # 爬取的书名
writers = soup.select('#content .article .abstract') # 爬取的作者
rates = soup.select('#content .article .rating_nums') # 爬取的评分
imgs = soup.select('#content .article .post img') # 爬取的图片链接
Titles = []
Writers = []
Rates = []
for title in titles:
Titles.append(title.text.strip()) # 去除多余的空格
for writer in writers:
Writers.append(writer.text.strip().replace('\n', ',').replace(' ', ''))
for rate in rates:
Rates.append(rate.text.strip())
Articles = zip(Titles, Writers, Rates)
filepath = 'douban'
if not os.path.exists(filepath):
os.mkdir(filepath)
with open(filepath + '/' + 'novelTop100.csv', 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerows(list(Articles))
# for article in Articles:
# writer.writerow(list(article))
for img in imgs:
download(img['src'])
def download(url):
filepath = 'douban/image'
if not os.path.exists(filepath):
os.mkdir(filepath)
html = requests.get(url, headers=headers)
filename = url.split('/')[-1]
with open(filepath+'/'+filename,'wb') as f:
f.write(html.content)
if __name__ == '__main__':
for i in range(0, 4):
url = 'https://www.douban.com/doulist/45004834/?start={}' \
'&sort=time&playable=0&sub_type='.format(25*i)
get_data(url)