手把手带你入门Python爬虫(二、爬虫预备知识)
爬虫预备知识
- 一、计算机网络协议基础
- 二、Html、Css、Javascript
-
- Ajax 异步加载
- GET请求 与 POST请求
- 3种content-type
- 三、爬虫基本方法
-
- 1. 采集方案分类
- 2. requests库
- 3. 正则表达式
- 4. beautifulsoup用法
- 5. xpath基本语法
- 6. css选择器提取元素
一、计算机网络协议基础
一个完整的网络请求过程如下:
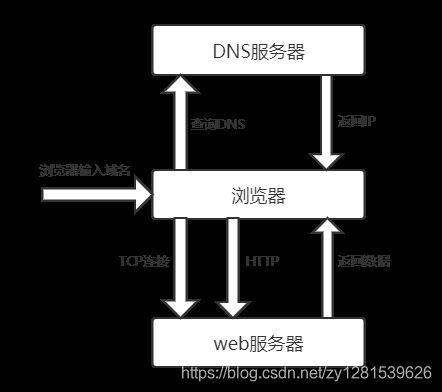
在浏览器输入域名后,浏览器先访问DNS服务器,DNS返回ip给浏览器,然后浏览器与web服务器建立TCP连接,浏览器就可以发送http请求,web服务器返回数据到浏览器,接下来就是浏览器解析内容的步骤。
七层网络协议:
- 应用层
Http、ftp、pop3、DNS - 表示层
- 会话层
- 传输层
TCP、UDP - 网络层
ICMP、IP、IDMP - 数据链路层
ARP、RARP - 物理层 物理传输介质
二、Html、Css、Javascript
网页三要素:Html、Css、Javascript
Html是承载网页内容的骨骼;
Css是网页的样式;
Javascript是网页运行的脚本;
我们需要爬虫的内容一般为网页的部分HTML的内容,所以说可见即可得,只要在页面上看得到的我们就可以爬到。
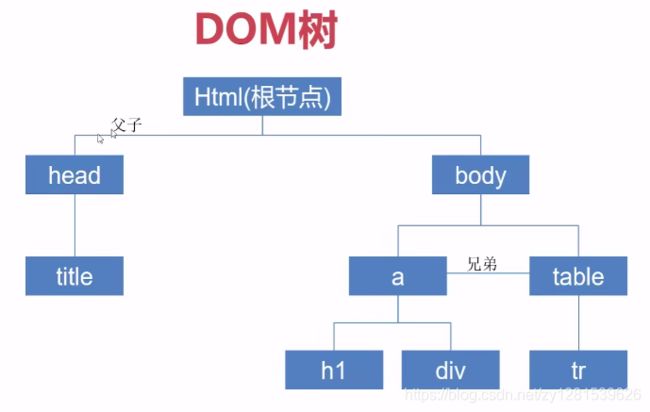
浏览器的加载过程:
构建DOM树—子资源加载(加载外部的css、js、图片等外部资源)—样式渲染(css执行)
查找页面元素一般通过DOM树来查找:
Ajax 异步加载
有的数据是通过js向服务器发送请求,返回数据将数据通过js动态插入到页面的,这种方式不会刷新页面,用户体验效果好。
ajax返回的数据又可能是json格式,也可以是html页面部分。
动态网页和静态网页:
动态:数据是与后台有交互的,可以变的(ajax)
静态:数据不可变的(如果要变需要修改源代码)
动态网页体验好,局部加载,对服务器好,扩展性好
静态网页有利于SEO
GET请求 与 POST请求
GET参数包含在URL中,POST通过request body 传递参数。
- GET在浏览器回退时是无害的,而POST会再次提交请求
- GET请求只能进行url编码,而POST支持多种编码方式
- GET请求在URL中传送的参数是有长度限制的,而POST没有
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能传递敏感信息
3种content-type
-
application/x-www-form-urlencoded
POST提交数据,浏览器原生form表单,如果不设置enctype属性,那么最终就会以application/x-www-form-urlencoded方式提交数据。提交的数据按照key1=val1&key2=val2的方式进行编码,key和val都进行了URL转码。 -
multipart/form-data
表单上传文件。 -
application/json
告诉服务器消息主体是序列化后的JSON字符串。
三、爬虫基本方法
1. 采集方案分类
一般我们采集网站只采集需要的指定的数据,采集方案分类:
- 利用http协议采集 - 页面分析
- 利用api接口采集 - app数据采集
- 利用目标网站的api采集 - 微博、github
2. requests库
官方文档地址:https://requests.readthedocs.io/zh_CN/latest/
安装:
pip install requests
如果使用了虚拟环境,请确保在虚拟环境再安装一遍,保证使用了虚拟环境的项目正常运行
初探,爬一下百度页面:
import requests
res = requests.get("http://www.baidu.com")
print(res.text)
百度页面的html代码就打印出来了:

后面具体项目再详细介绍具体用法。
3. 正则表达式
正则表达式是为了更好的处理获取的字符串,更方便的获取我们需要的字符。
常用的正则语法:
| 语法 | 作用 |
|---|---|
| . | 匹配任意字符(不包括换行符) |
| ^ | 匹配开始位置,多行模式下匹配每一行的开始 |
| $ | 匹配结束位置,多行模式下匹配每一行的结束 |
| * | 匹配前一个元字符0到多次 |
| + | 匹配前一个元字符1到多次 |
| ? | 匹配前一个元字符0到1次 |
| {m,n} | 匹配前一个元字符m到n次 |
| \\ | 转义字符 |
| [ ] | 字符集 |
| | | 逻辑或 |
| \b | 匹配位于单词开始或结束位置的空字符串 |
| \B | 匹配不位于单词开始或结束位置的空字符串 |
| \d | 匹配一个数字 |
| \D | 匹配非数字 |
| \s | 匹配任意空白 |
| \S | 匹配非任意空白 |
| \w | 匹配数字、字母、下划线中任意一个字符 |
| \W | 匹配非数字、字母、下划线中的任意字符 |
python使用正则,简单提取生日:
import re
info = "姓名:zhangsan 生日:1995年12月12日 入职日期:2020年12月12日"
# print(re.findall("\d{4}", info))
match_result = re.match(".*生日.*?(\d{4})", info)
print(match_result.group(1)) # 1995
4. beautifulsoup用法
- 安装
(如果使用的是虚拟环境,需要先切换到虚拟环境进行安装)
pip install beautifulsoup4
- 官方文档
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/ - 简单使用
from bs4 import BeautifulSoup
import requests
baidu = requests.get("http://www.baidu.com")
baidu.encoding = "utf-8"
bs = BeautifulSoup(baidu.text, "html.parser")
title = bs.find("title")
print(title.string)
navs = bs.find_all("img")
for i in navs:
print(i)
结果:

5. xpath基本语法
这里主要介绍Selector.
安装:
python包下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/
如果直接安装lxml或scrapy安装不成功可以去上面网站依次下载安装包,然后通过pip安装:
pip install lxml
pip install Twisted-20.3.0-cp38-cp38-win32.whl
pip install Scrapy-1.8.0-py2.py3-none-any.whl
xpath使用路径表达式在xml和html中进行导航。
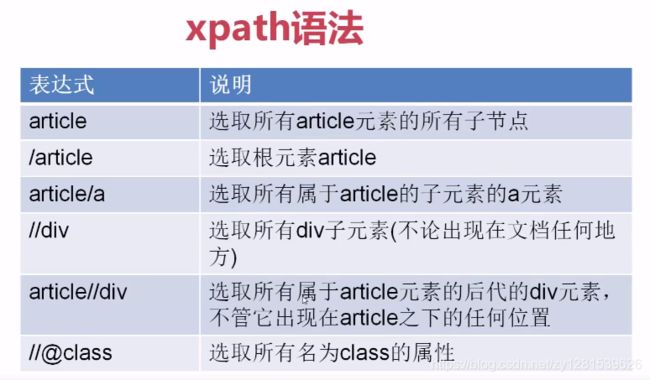

简单用法:
import requests
from scrapy import Selector
baidu = requests.get("http://www.baidu.com")
baidu.encoding = "utf-8"
html = baidu.text
sel = Selector(text=html)
tag = sel.xpath("//*[@id='lg']/img").extract()[0]
print(tag)
# 
6. css选择器提取元素
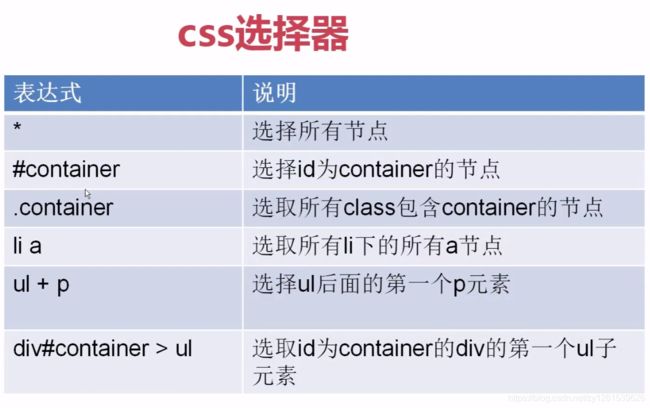
import requests
from scrapy import Selector
baidu = requests.get("http://www.baidu.com")
baidu.encoding = "utf-8"
html = baidu.text
sel = Selector(text=html)
imgs = sel.css("img").extract()
for i in imgs:
print(i)
#
# 
