GPU架构演进十年,从费米到安培

撰文 | Will Zhang
随着软件从1.0进化到2.0,即从图灵机演进到类深度学习算法。计算用的硬件也在加速从CPU到GPU等迁移。本文试图整理从2010年到2020年这十年间的英伟达GPU架构演进史。
1
CPU and GPU
我们先对GPU有一个直观的认识,如下图:

众所周知,由于存储器的发展慢于处理器,在CPU上发展出了多级高速缓存的结构,如上面左图所示。而在GPU中,也存在类似的多级高速缓存结构。只是相比CPU,GPU将更多的晶体管用于数值计算,而不是缓存和流控(Flow Control)。这源于两者不同的设计目标,CPU的设计目标是并行执行几十个线程,而GPU的目标是要并行执行几千个线程。
可以在上面右图看到,GPU的Core数量要远远多于CPU,但是有得必有失,可以看到GPU的Cache和Control要远远少于CPU,这使得GPU的单Core的自由度要远远低于CPU,会受到诸多限制,而这个限制最终会由程序员承担。这些限制也使得GPU编程与CPU多线程编程有着根本区别。
这其中最根本的一个区别可以在上右图中看出,每一行有多个Core,却只有一个Control,这代表着多个Core同一时刻只能执行同样的指令,这种模式也称为 SIMT (Single Instruction Multiple Threads). 这与现代CPU的SIMD倒是有些相似,但却有根本差别,本文在后面会继续深入细究。
从GPU的架构出发,我们会发现,因为Cache和Control的缺失,只有 计算密集 与 数据并行 的程序适合使用GPU。
-
计算密集:数值计算的比例要远大于内存操作,因此内存访问的延时可以被计算掩盖,从而对Cache的需求相对CPU没那么大。
-
数据并行:大任务可以拆解为执行相同指令的小任务,因此对复杂流程控制的需求较低。
而深度学习恰好满足以上两点,本人认为,即使存在比深度学习计算量更低且表达能力更强的模型,但如果不满足以上两点,都势必打不过GPU加持下的深度学习。
2
Fermi
Fermi是Nvidia在2010年发布的架构,引入了很多今天也仍然不过时的概念,而比Fermi更早之前的架构,也已经找不到太多资料了,所以本文从Fermi开始,先来一张总览。

GPU通过Host Interface读取CPU指令,GigaThread Engine将特定的数据从Host Memory中拷贝到内部的Framebuffer中。随后GigaThread Engine创建并分发多个Thread Blocks到多个SM上。多个SM彼此独立,并独立调度各自的多个Thread Wraps到SM内的CUDA Cores和其他执行单元上执行。
上面这句话有几个概念解释一下:
-
SM: 对应于上图中的SM硬件实体,内部有很多的CUDA Cores
-
Thread Block: 一个Thread Block包含多个线程(比如几百个),多个Blocks之间的执行完全独立,硬件可以任意调度多个Block间的执行顺序,而Block内部的多个线程执行规则由程序员决定,程同时程序员可以决定一共有多少个Blocks
-
Thread Warp: 32个线程为一个Thread Warp,Warp的调度有特殊规则,本文后面会继续深入
由于本文不是讲怎么写CUDA,所以如果对SM/Block的解释仍然不明白,可以参考这一小节:https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#scalable-programming-model
上图存在16个SMs,每个SM带32个Cuda Cores,一共512个Cuda Cores. 这些数量不是固定的,和具体的架构和型号相关。
接下来我们深入看SM,来一张SM总览。
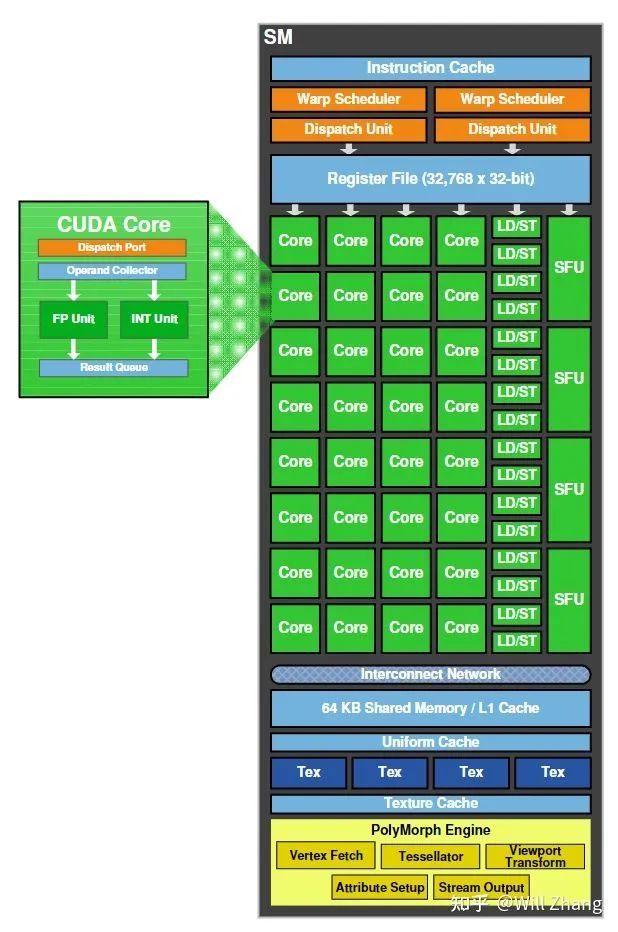
从上图可知,SM内有32个CUDA Cores,每个CUDA Core含有一个Integer arithmetic logic unit (ALU)和一个Floating point unit(FPU). 并且提供了对于单精度和双精度浮点数的FMA指令。
SM内还有16个LD/ST单元,也就是Load/Store单元,支持16个线程一起从Cache/DRAM存取数据。
4个SFU,是指Special Function Unit,用于计算sin/cos这类特殊指令。每个SFU每个时钟周期只能一个线程执行一条指令。而一个Warp(32线程)就需要执行8个时钟周期。SFU的流水线是从Dispatch Unit解耦的,所以当SFU被占用时,Dispatch Unit会去使用其他的执行单元。
之前一直提到Warp,但之前只说明了是32个线程,我们在这里终于开始详细说明,首先来看Dual Warp Scheduler的概览。

在之前的SM概览图以及上图里,可以注意到SM内有两个Warp Scheduler和两个Dispatch Unit. 这意味着,同一时刻,会并发运行两个warp,每个warp会被分发到一个Cuda Core Group(16个CUDA Core), 或者16个load/store单元,或者4个SFU上去真正执行,且每次分发只执行 一条 指令,而Warp Scheduler维护了多个(比如几十个)的Warp状态。
这里引入了一个核心的约束,任意时刻,一个Warp里的Thread都在执行同样的指令,对于程序员来说,观测不到一个warp里不同thread的不同执行情况。
但是众所周知,不同线程可能会进入不同的分支,这时如何执行一样的指令?

可以看上图,当发生分支时,只会执行进入该分支的线程,如果进入该分支的线程少,则会发生资源浪费。
在SM概览图里,我们可以看到SM内64KB的On-Chip Memory,其中48KB作为shared memory, 16KB作为L1 Cache. 对于L1 Cache 以及非On-Chip的L2 Cache,其作用与CPU多级缓存结构中的L1/L2 Cache非常接近,而Shared Memory,则是相比CPU的一个大区别。无论是CPU还是GPU中的L1/L2 Cache,一般意义上都是无法被程序员调度的,而Shared Memory设计出来就是让渡给程序员进行调度的片上高速缓存。
3
Kepler
2012年NVIDIA发布了Kepler架构,我们直接看使用Kepler架构的GTX680概览图。

可以看到,首先SM改名成了SMX,但是所代表的概念没有大变化,我们先看看SMX的内部。
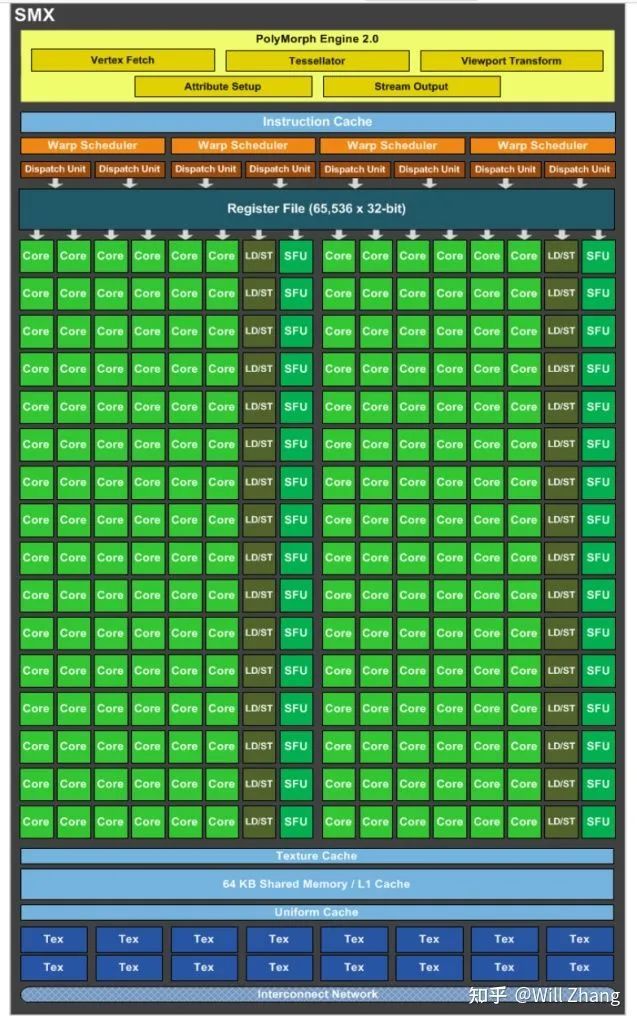
还是Fermi中熟悉的名词,就是数量变多了很多。
本人认为这个Kepler架构中最值得一提的是GPUDirect技术,可以绕过CPU/System Memory,完成与本机其他GPU或者其他机器GPU的直接数据交换。毕竟在2021年的当今,Bypass CPU/OS已经是最重要加速手段之一。
4
Maxwell
2014年NVIDIA发布了Maxwell架构,我们直接看架构图。
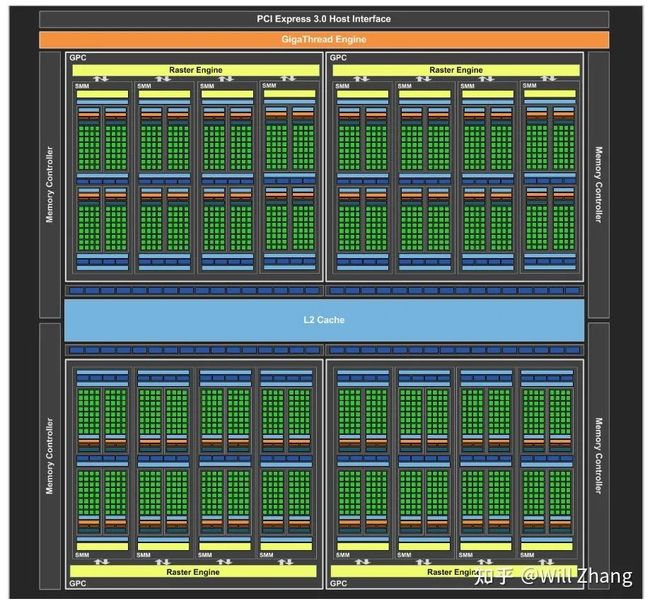
可以看到,这次的SM改叫SMM了,Core更多了,也更强大了,这里就不过多介绍了。
5
Pascal
2016年NVIDIA发布了Pascal架构,这是第一个考虑Deep Learning的架构,也是一个值得大书笔墨的架构,首先看如下图P100。

可以看到,还是一如既往地增加了很多Cores, 我们细看SM内部。
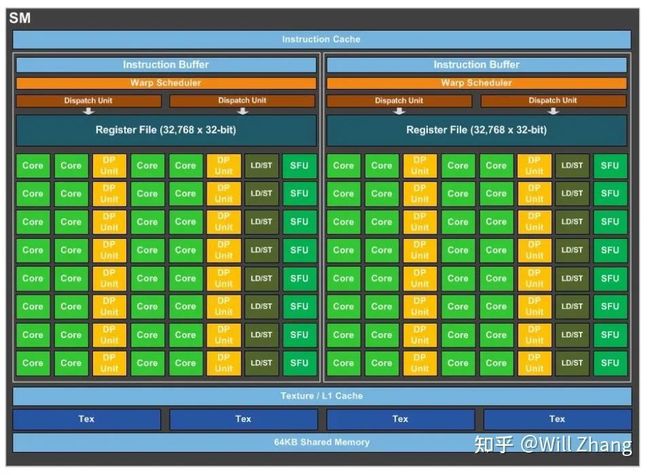
单个SM只有64个FP32 Cuda Cores,相比Maxwell的128和Kepler的192,这个数量要少很多,并且64个Cuda Cores分为了两个区块。需要注意的是,Register File的大小并未减少,这意味着每个线程可以使用的寄存器更多了,而且单个SM也可以并发更多的thread/warp/block. 由于Shared Memory并未减少,同样意味着每个线程可以使用的Shared Memory及其带宽都会变大。
增加了32个FP64 Cuda Cores, 也就是上图的DP Unit. 此外FP32 Cuda Core同时具备处理FP16的能力,且吞吐率是FP32的两倍,这却是为了Deep Learning准备的了。
这个版本引入了一个很重要的东西,NVLink.
随着单GPU的计算能力越来越难以应对深度学习对算力的需求,人们自然而然开始用多个GPU去解决问题。从单机多GPU到多机多GPU,这当中对GPU互连的带宽的需求也越来越多。多机之间,采用InfiniBand和100Gb Ethernet去通信,在单机内,特别是从单机单GPU到达单机8GPU以后,PCIe的带宽往往就成为了瓶颈。为了解决这个问题,NVIDIA提供了NVLink用以单机内多GPU内的点到点通信,带宽达到了160GB/s, 大约5倍于PCIe 3 x 16. 下图是一个典型的单机8 P100拓扑。

一些特殊的CPU也可以通过NVLink与GPU连接,比如IBM的POWER8。
6
Volta
2017年NVIDIA发布了Volta架构,这个架构可以说是完全以Deep Learning为核心了,相比Pascal也是一个大版本。
首先还是一如既往地增加了SM/Core, 我们就直接看单个SM内部吧。

和Pascal的改变类似,到了Volta,直接拆了4个区块,每个区块多配了一个L0指令缓存,而Shared Memory/Register File这都没有变少,也就和Pascal的改变一样,单个线程可使用的资源更多了。单个区块还多个两个名为Tensor Core的单元,这就是这个版本的核心了。可以吐槽一下,这个版本又把L1和Shared Memory合并了。
我们首先看CUDA Core, 可以看到,原本的CUDA Core被拆成了FP32 Cuda Core和INT32 Cuda Core,这意味着可以同时执行FP32和INT32的操作。
众所周知,DeepLearning的计算瓶颈在矩阵乘法,在BLAS中称为GEMM,TensorCore就是只做GEMM计算的单元,可以看到,从这里开始,NVIDIA从SIMT走到了SIMT+DSA的混合。
每个TensorCore只做如下操作
D=A*B+C即
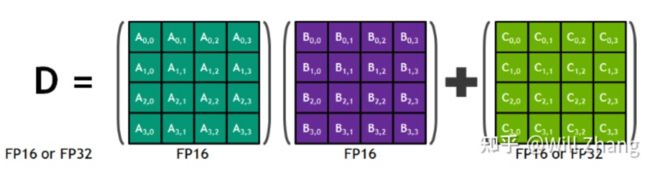
其中A, B, C, D都是4x4的矩阵,且A和B是FP16矩阵,C和D可以是FP16或者FP32. 通常,更大的矩阵计算会被拆解为这样的4x4矩阵乘法。
这样的矩阵乘法是作为Thread Warp级别的操作在CUDA 9开始暴露给程序员,除此以外,使用cublas和cudnn当然同样也会在合适的情况下启用TensorCore.
在这个版本中,另一个重要更新是NVLink, 简单来说就是更多更快。每个连接提供双向各自25GB/s的带宽,并且一个GPU可以接6个NVLink,而不是Pascal时代的4个。一个典型的拓扑如下图。

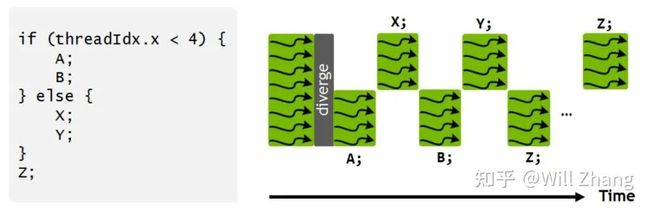
从Volta开始,线程调度发生了变化,在Pascal以及之前的GPU上,每个Warp里的32个线程共享一个Program Counter (简称PC) ,并且使用一个Active Mask表示任意时刻哪些线程是可运行的,一个经典的运行如下。

直到第一个分支完整结束,才会执行另一个分支。这意味着同一个warp内不同分支失去了并发性,不同分支的线程互相无法发送信号或者交换数据,但同时,不同warp之间的线程又保留了并发性,这当中的线程并发存在着不一致,事实上如果程序员不注意这点,很可能导致死锁。
在Volta中解决了这个问题,同warp内的线程有独立的PC和栈,如下。

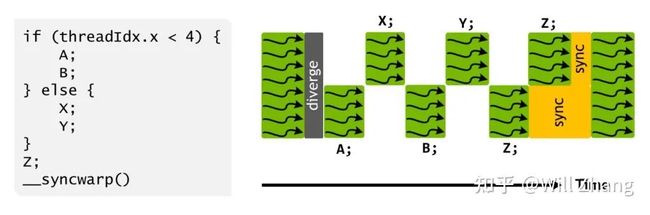
由于运行时仍然要符合SIMT,所以存在一个调度优化器负责将可运行的线程分组,使用SIMT模式执行。经典运行如下。
上图可以注意到,Z的执行并没有被合并,这是因为Z可能会产生一些被其他分支需要的数据,所以调度优化器只有在确定安全的情况下才会合并Z,所以上图Z未合并只是一种情况,一般来说,调度优化器足够聪明可以发现安全的合并。程序员也可以通过一个API来强制合并,如下。
从Volta开始,提高了对多进程并发使用GPU的支持。在Pascal及之前,多个进程对单一GPU的使用是经典的时间片方式。从Volta开始,多个用不满GPU的进程可以在GPU上并行,如下图。

7
Turing
2018年NVIDIA发布了Turing架构,个人认为是Volta的延伸版本,当然首先各种参数加强,不过我们这里就不提参数加强了。
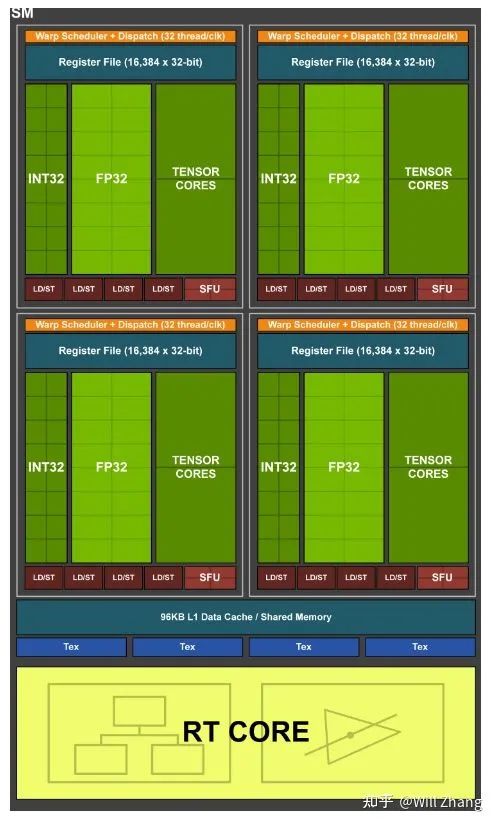
比较重要是的增加了一个RT Core,全名是Ray Tracing Core, 顾名思义,这个是给游戏或者仿真用的,因为本人没有从事过这类工作,就不介绍了。
此外Turing里的Tensor Core增加了对INT8/INT4/Binary的支持,为了加速deep learning的inference, 这个时候深度学习模型的量化部署也渐渐成熟。
8
Ampere
2020年NVIDIA发布了Ampere架构,这就是一个大版本了,里面又细分了GA100, GA102, GA104, 我们这里就只关注GA100
我们先看GA100的SM
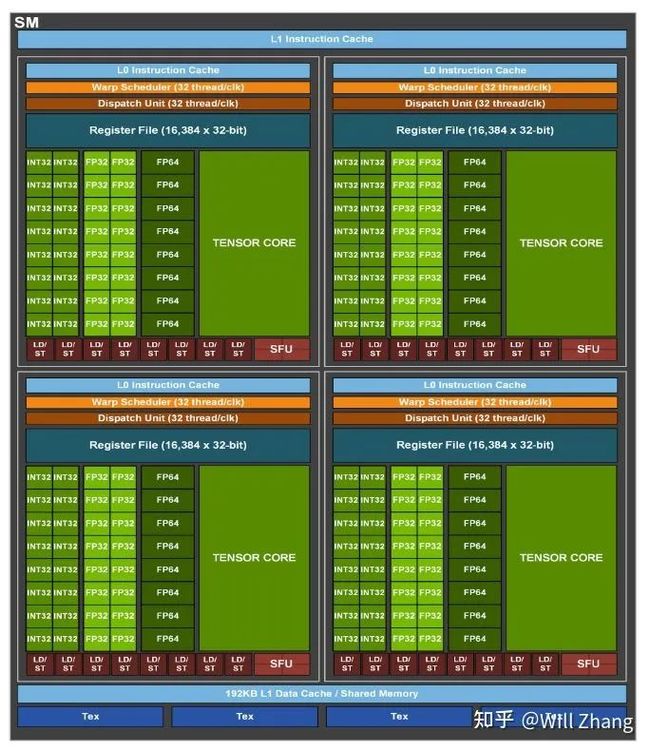
这里面最核心的升级就是Tensor Core了
除了在Volta中的FP16以及在Turing中的INT8/INT4/Binary,这个版本新加入了TF32, BF16, FP64的支持。着重说说TF32和BF16, 如下图。
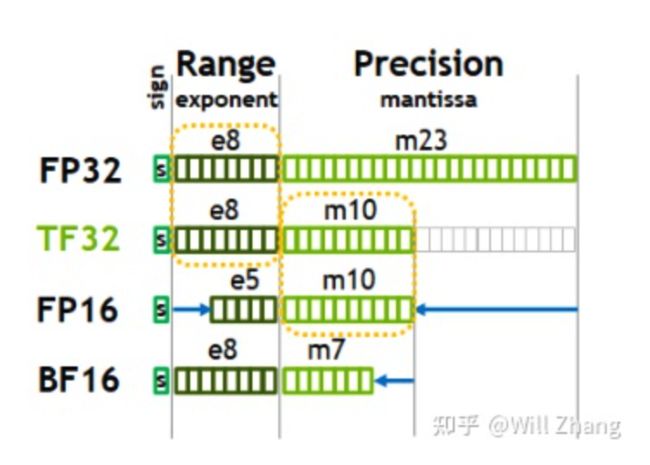
FP16的问题在于表示范围不够大,在梯度计算时容易出现underflow, 而且前后向计算也相对容易出现overflow, 相对来说,在深度学习计算里,范围比精度要重要得多,于是有了BF16,牺牲了精度,保持和FP32差不多的范围,在此前比较知名支持BF16的就是TPU. 而TF32的设计,在于即汲取了BF16的好处,又保持了一定程度对主流FP32的兼容,FP32只要截断就是TF32了。先截断成TF32计算,再转成FP32, 对历史的工作几乎无影响,如下图

另一个变化则是细粒度的结构化稀疏,深度学习模型压缩这个领域除了量化,稀疏也是一个大方向,只是稀疏化模型难以利用硬件加速,这个版本的GPU则为稀疏提供了一些支持,当前的主要目的则是应用于Inference场景。
首先说NVIDIA定义的稀疏矩阵,这里称为2:4的结构化稀疏,2:4的意思是每4个元素当中有2个值非0,如下图

首先使用正常的稠密weight训练,训练到收敛后裁剪到2:4的结构化稀疏Tensor,然后走fine tune继续训练非0的weight, 之后得到的2:4结构化稀疏weight理想情况下具有和稠密weight一样的精确度,然后使用此稀疏化后的weight进行Inference. 而这个版本的TensorCore支持一个2:4的结构化稀疏矩阵与另一个稠密矩阵直接相乘。
最后一个比较重要的特性就是MIG(Multi-Instance GPU)了,虽然业界的计算规模确实越来越大,但也存在不少的任务因为其特性导致无法用满GPU导致资源浪费,所以存在需求在一个GPU上跑多个任务,在这之前有些云计算厂商会提供虚拟化方案。而在安培中,会为此需求提供支持,称为MIG.
可能会有人有疑问,在Volta中引入的多进程支持不是解决了问题吗?举个例子,在Volta中,虽然多个进程可以并行,但是由于所有进程都可以访问所有的内存资源,可能存在一个进程把所有的DRAM带宽占满影响到其他进程的运行,而这些被影响的进程很可能有Throughput/Latency要求。所以我们需要更严格的隔离。
而在安培MIG中,每个A100可以被分为7个GPU实例被不同的任务使用。每个实例的SMs有独立的内存资源,可以保证每个任务有符合预期的稳定的Throughput/Latency. 用户可以将这些虚拟的GPU实例当成真实的GPU使用。
9
结语
事实上关于各个架构的细节还有很多,限于篇幅这里只能简单概述。随后将分享一些更具体的关于CUDA编程的内容。
Reference
https://images.nvidia.com/aem-dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf
https://images.nvidia.com/aem-dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf
https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf
https://www.microway.com/download/whitepaper/NVIDIA_Maxwell_GM204_Architecture_Whitepaper.pdf
https://www.nvidia.com/content/PDF/product-specifications/GeForce_GTX_680_Whitepaper_FINAL.pdf
https://www.hardwarebg.com/b4k/files/nvidia_gf100_whitepaper.pdf
https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
https://blog.nowcoder.net/n/4dcb2f6a55a34de9ae6c9067ba3d3bfb
https://jcf94.com/2020/05/24/2020-05-24-nvidia-arch/
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
https://en.wikipedia.org/wiki/Bfloat16_floating-point_format本文获得授权后发布。原文链接:https://zhuanlan.zhihu.com/p/413145211
题图源自Pixabay
其他人都在看
-
OneFlow v0.5.0 正式上线
-
玩转大模型,是时候展示你真正的技术了
-
动态调度的“诅咒”| 原有深度学习框架的缺陷③
-
计算机架构史上的一次伟大失败,多数人都不知道
-
深度学习框架量化感知训练的思考及OneFlow的解决方案
点击“阅读原文”,欢迎下载体验OneFlow新一代开源深度学习框架

![]()