python线性回归分析练手:用大众点评500家的评分数据拟合线性回归
python线性回归分析
大家好!我是未来村村长!就是那个“请你跟我这样做,我就跟你那样做!”的村长!
一、简单说明
1、数据源

2、探究目的
我们通过线性回归方法,探究’评论人数’,‘人均价格’,‘口味’,‘环境’,'服务’与’评论分数’的相关关系,得出对应的线性回归方程,并探究回归模型的拟合程度
3、所使用的库
#coding=gbk
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from scipy import stats
二、数据预处理
由于数据无缺失值和重复值,我们不需要进行对异常值的处理,我们只需要清洗以下,将字符数据转换为数值型数据即可。
df_allinfo = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息.csv', header=0, names=['店铺名称', '评论分数', '评论人数', '人均价格', '口味', '环境', '服务'],encoding='gbk')
#数据预处理
for i in range(len(df_allinfo['店铺名称'])):
df_allinfo.loc[i, '口味'] = df_allinfo['口味'][i].replace('口味:', '')
df_allinfo.loc[i, '评论人数'] = df_allinfo['评论人数'][i].replace('条评价', '')
df_allinfo.loc[i, '人均价格'] = df_allinfo['人均价格'][i].replace('人均:', '')
df_allinfo.loc[i, '人均价格'] = df_allinfo['人均价格'][i].replace('元', '')
df_allinfo.loc[i, '环境'] = df_allinfo['环境'][i].replace('环境:', '')
df_allinfo.loc[i, '服务'] = df_allinfo['服务'][i].replace('服务:', '')
df_allinfo[['评论分数', '评论人数', '人均价格', '口味', '环境', '服务']]=df_allinfo[['评论分数', '评论人数', '人均价格', '口味', '环境', '服务']].astype('float64')
#数据字段总体描述
df_describe = df_allinfo.describe().T
print(df_describe)
三、绘制散点图和关系热力图
我们为了初步查看其相关数据的相关关系,可以画出散点图和关系热力图
#绘制散点图
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#定义绘制函数
def drawing(x,y,xlabel):
plt.scatter(x,y)
plt.title('%s与评论分数的散点图' %xlabel)
plt.xlabel(xlabel)
plt.ylabel('评论分数')
plt.grid()
plt.show()
#绘制
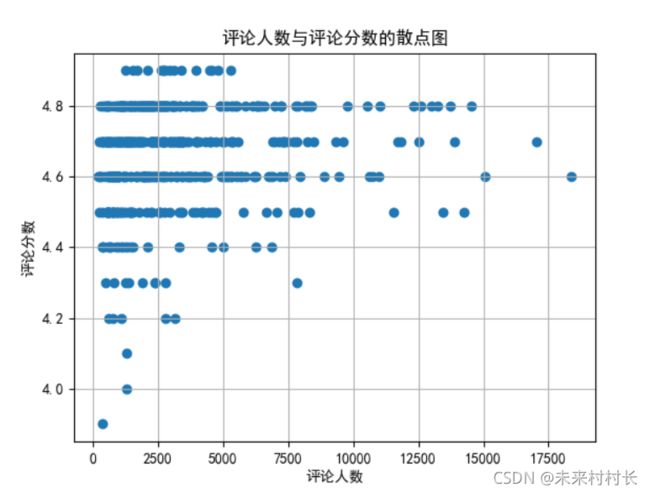
drawing(df_allinfo['评论人数'],df_allinfo['评论分数'],'评论人数')
drawing(df_allinfo['口味'],df_allinfo['评论分数'],'口味')
drawing(df_allinfo['环境'],df_allinfo['评论分数'],'环境')
drawing(df_allinfo['服务'],df_allinfo['评论分数'],'服务')
drawing(df_allinfo['人均价格'],df_allinfo['评论分数'],'人均价格')
#关系热力图
corr = df_allinfo.loc[:,['评论分数','评论人数','人均价格','口味','环境','服务']].corr()
print(corr)
sns.heatmap(corr,linewidths=0.1,vmax=1.0, square=True,linecolor='white', annot=True)
plt.show()
散点图示例:
关系热力图示例:
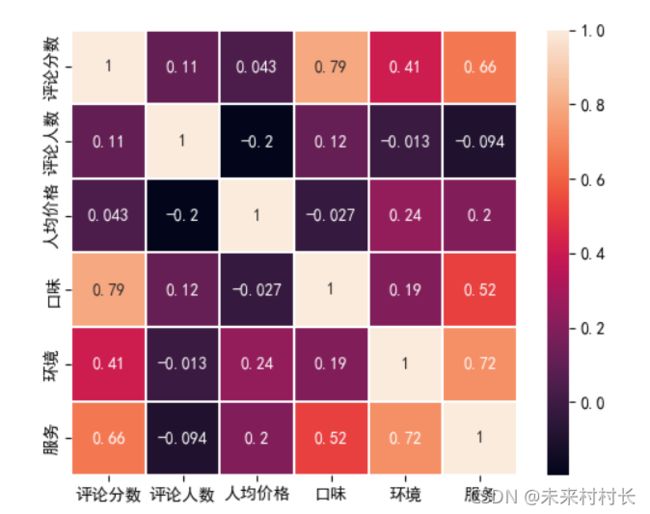
矩形块内的数值为对应的相关系数corr
四、模型建立
我们先将数据随机二八分配,其中80%作为训练数据,20%作为测试数据
#定义变量
X = pd.DataFrame(np.c_[df_allinfo['人均价格'],df_allinfo['评论人数'],
df_allinfo['口味'],df_allinfo['环境'],df_allinfo['服务']],
columns = ['人均价格','评论人数','口味','环境','服务'])
Y = df_allinfo['评论分数']
#数据集分割:80%训练,20%测试
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=5)
print(X_train.shape,X_test.shape,Y_train.shape,Y_test.shape)
然后调用相应的函数进行模型的拟合
#模型拟合
model = LinearRegression()
model.fit(X_train,Y_train)
通过训练函数拟合后,我们查看得到的结果
#模型参数输出
#截距
print(model.intercept_)
#估计系数
coeffcients = pd.DataFrame([X_train.columns,model.coef_]).T
coeffcients = coeffcients.rename(columns={
0:'Attribute',1:'Coefficients'})
print(coeffcients)
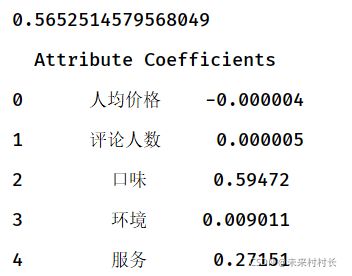
得到结果后,我们用测试数据去验证拟合的效果,测试拟合效果的方法为两种,一是画测试数据的散点图,查看有无离群点。二是算出R方,R方越接近1,说明方程拟合度越高。
#绘制预测值与实际值的散点图
price_pred = model.predict(X_test)
plt.scatter(Y_test,price_pred)
plt.xlabel("Actual Prices")
plt.ylabel("Predicted prices")
plt.title("Actual price vs Predicted prices")
plt.show()
#R的二次方越接近1说明模型拟合得越合适
print('R-Squared: %.4f' % model.score(X_test,Y_test))

![]()
综上拟合度已经很高了,说明得到的方程可信。如果R方过低,则可能是数据集不够或者出现了离群值,做出调整后进行重新拟合。
五、结论
我们可以得出方程:评论分数 = 0.60x口味 + 0.01x环境 + 0.27x服务(评论人数和价格影响过小而省略)
所以餐饮行业要想店铺评论高,顾客口碑好。还是得好好搞好味道,其次是服务态度。哪怕你是苍蝇馆还是米其林,味道不好服务差,迟早都得倒闭。
(以上只是练手,所有结论皆不严谨)