Prometheus监控(kube-prometheus)
Prometheus监控实战(kube-prometheus)
- 部署kube-prometheus监控套件
- 调试
- manifests下用户可以自定义CRD等资源配置
- 增加prometheus监控K8S集群权限
- 监控springboot 2.x项目
- 监控java程序jmx_exporter
-
- 将jmx_exporter放到程序可以找到的目录
- 程序启动添加参数
- 使用PodMonitor自动发现pod
- 使用ServiceMonitor自动发现service
- 为Prometheus serviceAccount 添加对应namespace的权限
- 添加告警规则rules
- 配置告警接收者们
- 修改或删除默认告警规则
- 集成钉钉告警插件
- 新增/添加prometheus server配置(静态配置job_name)
- 配置blackbox_exporter
-
- models配置
- prometheus静态配置job
- 使用curl接口测试
- grafana参考
- 告警配置
- prometheus-adapter实现自定义指标HPA
-
- 部署app
- 配置app ServiceMonitor 自动采集数据
- helm安装prometheus-adapter并做配置
- 创建hpa策略
- 验证规则
- 压力测试查看pod数量变化
- redis
-
- redis-exporter
- Redis Data Source 插件
- rocketmq-exporter
- mysql-exporter
- elasticsearch_exporter
- 腾讯云对接Grafana
- 卸载监控套件
部署kube-prometheus监控套件
中文文档
This repository collects Kubernetes manifests, Grafana dashboards, and Prometheus rules combined with documentation and scripts to provide easy to operate end-to-end Kubernetes cluster monitoring with Prometheus using the Prometheus Operator.
git clone https://github.com/prometheus-operator/kube-prometheus.git
kubectl create -f manifests/setup
kubectl create -f manifests/
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
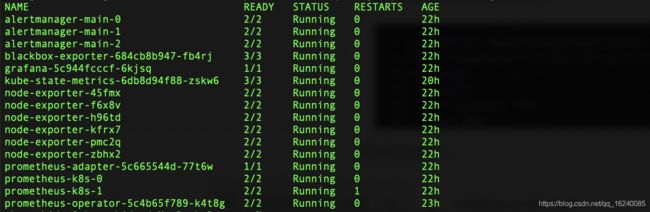
调试
Prometheus
$ kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090
Then access via http://localhost:9090
Grafana
$ kubectl --namespace monitoring port-forward svc/grafana 3000
Then access via http://localhost:3000 and use the default grafana user:password of admin:admin.
Alert Manager
$ kubectl --namespace monitoring port-forward svc/alertmanager-main 9093
Then access via http://localhost:9093
manifests下用户可以自定义CRD等资源配置
https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md
增加prometheus监控K8S集群权限
Failed to watch *v1.Pod: failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" in the namespace \"loki\""
cat prometheus-clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
- pods
- services
- endpoints
verbs:
- list
- get
- watch
- nonResourceURLs:
- /metrics
verbs:
- get
监控springboot 2.x项目
grafana官方手册
监控java程序jmx_exporter
https://github.com/prometheus/jmx_exporter
将jmx_exporter放到程序可以找到的目录
ls /usr/monitor/jmx_export/
jmx_exporter_config.yaml
jmx_prometheus_javaagent-0.14.0.jar
下面配置在grafana对应的模版里面可以找到:https://grafana.com/grafana/dashboards/8563
cat jmx_exporter_config.yaml
---
lowercaseOutputLabelNames: true
lowercaseOutputName: true
whitelistObjectNames: ["java.lang:type=OperatingSystem"]
blacklistObjectNames: []
rules:
- pattern: 'java.lang<>(committed_virtual_memory|free_physical_memory|free_swap_space|total_physical_memory|total_swap_space)_size:'
name: os_$1_bytes
type: GAUGE
attrNameSnakeCase: true
- pattern: 'java.lang<>((?!process_cpu_time)\w+):'
name: os_$1
type: GAUGE
attrNameSnakeCase: true
程序启动添加参数
-javaagent:/usr/monitor/jmx_export/jmx_prometheus_javaagent-0.14.0.jar=12345:/usr/monitor/jmx_export/jmx_exporter_config.yaml
java -javaagent:/usr/monitor/jmx_export/jmx_prometheus_javaagent-0.14.0.jar=12345:/usr/monitor/jmx_export/jmx_exporter_config.yaml -jar app.jar
这时程序会额外启动12345这个http端口
使用PodMonitor自动发现pod
使用场景:对于没有使用service的应用可以使用PodMonitor
deployment 配置
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: mq-test # 关键配置,PodMonitor 关联
......
......
imagePullPolicy: IfNotPresent
name: mq-test
ports:
- containerPort: 12345
name: prometheus # 关键配置,PodMonitor 关联找到该名字
protocol: TCP
resources:
PodMonitor 配置关联deployment,apply下列文件
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: default-mqtest # 最终显示在promtheus中的job名称
namespace: default
spec:
namespaceSelector:
matchNames:
- default
podMetricsEndpoints:
- interval: 15s
path: /metrics
targetPort: 12345
# port: prometheus # 也可以使用与pod中的port 12345对应的名字,个人习惯使用targetPort
selector:
matchLabels:
k8s-app: mq-test # 关键配置,pod的labels
使用ServiceMonitor自动发现service
使用场景:使用service的应用(常用)
通过使用ServiceMonitor会自动将service相关联的pod自动加入到监控之中,并从apiserver获取最新的pod列表实时更新
service配置
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: mq-test
name: mq-test
namespace: default
spec:
ports:
- name: 8080-8080-tcp
port: 8080
protocol: TCP
targetPort: 8080
- name: 12345-12345-tcp
port: 12345
protocol: TCP
targetPort: 12345
selector:
k8s-app: mq-test
ServiceMonitor 配置关联service,并apply
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: mq-test
namespace: default
labels:
k8s-app: mq-test # 关键配置
spec:
#jobLabel: metrics
endpoints:
- interval: 15s
port: 12345-12345-tcp # 关键配置
namespaceSelector: # 支持监听多个namespace
matchNames:
- default
selector:
matchLabels:
k8s-app: mq-test
导入grafana模版:https://grafana.com/grafana/dashboards/8563
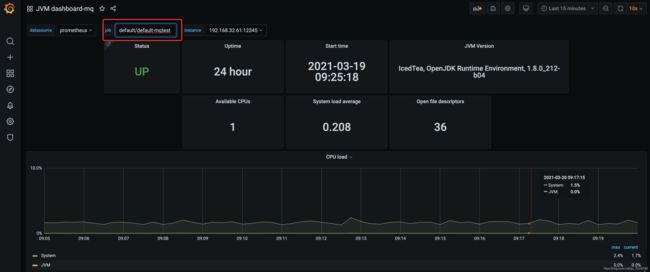
为Prometheus serviceAccount 添加对应namespace的权限
--- # 在对应的ns中创建角色
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: prometheus-k8s
namespace: my-namespace
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
--- # 绑定角色 prometheus-k8s 角色到 Role
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-k8s
namespace: my-namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s # Prometheus 容器使用的 serviceAccount,kube-prometheus默认使用prometheus-k8s这个用户
namespace: monitoring
添加告警规则rules
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s # 必须有
role: alert-rules # 必须有
name: jvm-metrics-rules
namespace: monitoring
spec:
groups:
- name: jvm-metrics-rules
rules:
# 在5分钟里,GC花费时间超过10%
- alert: GcTimeTooMuch
expr: increase(jvm_gc_collection_seconds_sum[5m]) > 10
for: 5m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} GC时间占比超过10%"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} GC时间占比超过10%,当前值({
{ $value }}%)"
# GC次数太多
- alert: GcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count[1m]) > 30
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} 1分钟GC次数>30次"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} 1分钟GC次数>30次,当前值({
{ $value }})"
# FGC次数太多
- alert: FgcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count{
gc="ConcurrentMarkSweep"}[1h]) > 3
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} 1小时的FGC次数>3次"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} 1小时的FGC次数>3次,当前值({
{ $value }})"
# 非堆内存使用超过80%
- alert: NonheapUsageTooMuch
expr: jvm_memory_bytes_used{
job="mq-test", area="nonheap"} / jvm_memory_bytes_max * 100 > 80
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} 非堆内存使用>80%"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} 非堆内存使用率>80%,当前值({
{ $value }}%)"
# 内存使用预警
- alert: HeighMemUsage
expr: process_resident_memory_bytes{
job="mq-test"} / os_total_physical_memory_bytes * 100 > 85
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} rss内存使用率大于85%"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} rss内存使用率大于85%,当前值({
{ $value }}%)"
配置告警接收者们
参考:https://zhuanlan.zhihu.com/p/74932366
cat test-alert.yaml
global:
resolve_timeout: 5m
route:
group_by: ['job', 'alertname', 'pod']
group_interval: 2m
receiver: my-alert-receiver
routes:
- match:
job: jmx-metrics
receiver: my-alert-receiver
repeat_interval: 3h
receivers:
- name: my-alert-receiver
webhook_configs:
- url: http://6e2db971bfba.ngrok.io/dingtalk/webhook1/send
max_alerts: 1
send_resolved: true
cat test-alert.yaml |base64
将经过base64转换的secret贴到这里,稍后刷新alertmanager页面即可看到配置变更了
kubectl edit -n monitoring Secret alertmanager-main
修改或删除默认告警规则
manifests/prometheus-prometheusRule.yaml
集成钉钉告警插件
https://github.com/timonwong/prometheus-webhook-dingtalk/releases/
新增/添加prometheus server配置(静态配置job_name)
官网文档:https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#prometheusspec
prometheus的配置默认是不能修改的,目前可以通过新增prometheus-additional.yaml来添加新增配置,如下:
cat prometheus-additional.yaml
- job_name: rocketmq-exporter
honor_timestamps: true
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- 10.250.62.4:5557
创建secret对象
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
更新的话删除,再创建
kubectl delete secret additional-configs -n monitoring
在manifests/prometheus-prometheus.yaml 配置文件追加 additionalScrapeConfigs 字段和对应name和key,并apply该文件配置,会在target中看到该配置啦
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {
}
serviceMonitorSelector: {
}
version: 2.25.0
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml

若有问题查看日志
kubectl logs -f prometheus-k8s-0 prometheus -n monitoring
配置blackbox_exporter
使用kube-prometheus部署套件会自动部署blackbox_exporter服务,特别注意:开启的端口是19115而不是9115,可以到pod内ps查看
官网支持的模块models示例ping、http、dns等
官网blackbox_exporter配置参考
models配置
configmap:blackbox-exporter-configuration
confix.yml
"modules":
"http_2xx": # 配置get请求检测
"http":
"preferred_ip_protocol": "ip4"
"prober": "http"
"http_post_2xx": # 配置post请求检测
"http":
"method": "POST"
"preferred_ip_protocol": "ip4"
"prober": "http"
"irc_banner":
"prober": "tcp"
"tcp":
"preferred_ip_protocol": "ip4"
"query_response":
- "send": "NICK prober"
- "send": "USER prober prober prober :prober"
- "expect": "PING :([^ ]+)"
"send": "PONG ${1}"
- "expect": "^:[^ ]+ 001"
"pop3s_banner":
"prober": "tcp"
"tcp":
"preferred_ip_protocol": "ip4"
"query_response":
- "expect": "^+OK"
"tls": true
"tls_config":
"insecure_skip_verify": false
"ssh_banner":
"prober": "tcp"
"tcp":
"preferred_ip_protocol": "ip4"
"query_response":
- "expect": "^SSH-2.0-"
"tcp_connect": # 配置tcp端口检测
"prober": "tcp"
"tcp":
"preferred_ip_protocol": "ip4"
"icmp": # 配置ping检测
"prober": "icmp"
"icmp":
"preferred_ip_protocol": "ip4"
prometheus静态配置job
secret:additional-configs # 该配置是prometheus静态配置,请参考上文如何创建
prometheus-additional.yaml
- job_name: 'blackbox_http_2xx'
scrape_interval: 5s
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response. 与models关联
static_configs:
- targets:
- https://www.baidu.com/ # 监控的url
labels:
instance: web_status
group: 'web'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.63.76:19115 # blackbox-exporter 地址和端口
- job_name: 'blackbox_ping'
scrape_interval: 5s
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets:
- 127.0.0.1
labels:
instance: icmp_status
group: 'icmp'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: 192.168.63.76:19115
- job_name: 'blackbox_tcp_connect'
scrape_interval: 5s
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets:
- 127.0.0.1:9090
labels:
instance: tcp_status
group: 'tcp'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.63.76:19115
使用curl接口测试
大同小异,更换module和对应的target字段即可
curl http://192.168.32.44:19115/probe?target=127.0.0.1:9090&module=blackbox_
tcp_connect
curl http://192.168.32.44:19115/probe?target=www.baidu.com&module=http_2xx&d
ebug=true
出现如下数据说明数据正常
/ # # HELP probe_dns_lookup_time_seconds Returns the time taken for probe dns lookup in seconds
# TYPE probe_dns_lookup_time_seconds gauge
probe_dns_lookup_time_seconds 0.105269463
# HELP probe_duration_seconds Returns how long the probe took to complete in seconds
# TYPE probe_duration_seconds gauge
probe_duration_seconds 0.200167873
# HELP probe_failed_due_to_regex Indicates if probe failed due to regex
# TYPE probe_failed_due_to_regex gauge
probe_failed_due_to_regex 0
# HELP probe_http_content_length Length of http content response
# TYPE probe_http_content_length gauge
probe_http_content_length -1
# HELP probe_http_duration_seconds Duration of http request by phase, summed over all redirects
# TYPE probe_http_duration_seconds gauge
probe_http_duration_seconds{
phase="connect"} 0.006833871 #连接时间
probe_http_duration_seconds{
phase="processing"} 0.008490896 #处理请求的时间
probe_http_duration_seconds{
phase="resolve"} 0.105269463 #响应时间
probe_http_duration_seconds{
phase="tls"} 0 #校验证书的时间
probe_http_duration_seconds{
phase="transfer"} 0.079338462
# HELP probe_http_redirects The number of redirects
# TYPE probe_http_redirects gauge
probe_http_redirects 0 #重定向的次数
# HELP probe_http_ssl Indicates if SSL was used for the final redirect
# TYPE probe_http_ssl gauge
probe_http_ssl 0
# HELP probe_http_status_code Response HTTP status code
# TYPE probe_http_status_code gauge
probe_http_status_code 200 #返回的状态码
# HELP probe_http_uncompressed_body_length Length of uncompressed response body
# TYPE probe_http_uncompressed_body_length gauge
probe_http_uncompressed_body_length 298537
# HELP probe_http_version Returns the version of HTTP of the probe response
# TYPE probe_http_version gauge
probe_http_version 1.1
# HELP probe_ip_addr_hash Specifies the hash of IP address. It's useful to detect if the IP address changes.
# TYPE probe_ip_addr_hash gauge
probe_ip_addr_hash 2.768965475e+09
# HELP probe_ip_protocol Specifies whether probe ip protocol is IP4 or IP6
# TYPE probe_ip_protocol gauge
probe_ip_protocol 4
# HELP probe_success Displays whether or not the probe was a success
# TYPE probe_success gauge
probe_success 1 # 1代表成功
grafana参考
12275、9965
http状态:13230
告警配置
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30 # 域名过期30天检测
expr: probe_http_status_code{
job="blackbox_http_2xx"} >=400 and probe_success{
job="blackbox_http_2xx"}==0 # 实现状态码>400且状态为0(失败)的告警。
expr: sum(probe_http_duration_seconds) by (instance) > 3 # 接口总耗时大于 3 秒的告警。
新建个PrometheusRule文件,apply之后在UI查看
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: blackbox-metrics-alert
namespace: monitoring
spec:
groups:
- name: blackbox-metrics-alert
rules:
- alert: curlHttpStatus
expr: probe_http_status_code{
job="blackbox_http_2xx"} >=400 and probe_success{
job="blackbox_http_2xx"}==0
for: 1m
labels:
severity: red
annotations:
summary: 'web接口访问异常状态码 > 400'
description: '{
{$labels.instance}} 不可访问,请及时查看,当前状态码为{
{$value}}'
- name: blackbox-ssl_expiry
rules:
- alert: Ssl Cert Will Expire in 30 days
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "域名证书即将过期 (instance {
{ $labels.instance }})"
description: "域名证书 30 天后过期 \n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
prometheus-adapter实现自定义指标HPA
在腾讯云上测试失败,腾讯云有一套自己的custom.metrics.k8s.io/v1beta1,需要删除才能创建,会导致腾讯云控制台hpa无法使用,参考在 TKE 上使用自定义指标进行弹性伸缩
K8S HPA
prometheus-adapter插件官网
kube-prometheus监控套件默认已经安装该插件
prometheus-adapter可以通过应用程序暴露metrics来实现HPA,扩展了K8S默认提供的HPA不足之处,常用的指标有QPS 大小等
部署app
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: metrics-app
name: metrics-app
spec:
replicas: 1
selector:
matchLabels:
app: metrics-app
template:
metadata:
labels:
app: metrics-app
annotations:
prometheus.io/scrape: "true" # 设置允许被prometheus采集
prometheus.io/port: "80" # prometheus 采集的端口
prometheus.io/path: "/metrics" # prometheus 采集的路径
spec:
containers:
- image: ikubernetes/metrics-app
name: metrics-app
ports:
- name: web
containerPort: 80
resources:
requests:
cpu: 200m
memory: 256Mi
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: metrics-app
labels:
app: metrics-app
spec:
ports:
- name: web
port: 80
targetPort: 80
selector:
app: metrics-app
curl一下发现该app暴露了如下metrics
# HELP http_requests_total The amount of requests in total
# TYPE http_requests_total counter
http_requests_total 1
# HELP http_requests_per_second The amount of requests per second the latest ten seconds
# TYPE http_requests_per_second gauge
http_requests_per_second 1
配置app ServiceMonitor 自动采集数据
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: metrics-app
namespace: default
spec:
endpoints:
- bearerTokenSecret:
key: ""
interval: 15s
port: web
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: metrics-app

helm安装prometheus-adapter并做配置
通过如下的 PromQL 计算出每个业务 Pod 的 QPS 监控。示例如下:
sum(rate(http_requests_total[2m])) by (pod)
将其转换为 prometheus-adapter 的配置,创建 values.yaml,内容如下:
rules:
- seriesQuery: 'http_requests_total{namespace!="",pod!=""}'
resources:
overrides:
namespace: {
resource: "namespace"}
pod: {
resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second" # PromQL 计算出来的 QPS 指标, 也可写成 http_requests_qps
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'
prometheus:
url: http://prometheus.monitoring.svc.cluster.local # 替换 Prometheus API 的地址 (不写端口)
port: 9090
helm安装
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# Helm 3
helm install prometheus-adapter prometheus-community/prometheus-adapter -f values.yaml
# Helm 2
# helm install --name prometheus-adapter prometheus-community/prometheus-adapter -f values.yaml
创建hpa策略
下述示例 QPS 为800m,表示 QPS 值为0.8。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: metrics-app
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: metrics-app
minReplicas: 1
maxReplicas: 6
metrics:
- type: Pods
pods:
metric:
name: http_requests_per_second # http_requests_qps
target:
type: AverageValue
averageValue: 800m # 800m 即0.8个/秒,如果是阀值设置为每秒10个,这里的值就应该填写10000m, 不写单位m就是个数
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
metrics-app Deployment/metrics-app <unknown>/800m 1 6 1 30h
验证规则
Custom Metrics API 返回配置的 QPS 相关指标
规则不生效则删除pod重新加载下配置
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/metrics-app/pods/*/http_requests_per_second
# kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/metrics-app/pods/*/http_requests_qps
压力测试查看pod数量变化
while sleep 0.01; do wget -q -O- http://metrics-app/metrics; done
redis
redis-exporter
https://github.com/oliver006/redis_exporter
grafana: 11835
apiVersion: v1
kind: Secret
metadata:
name: redis-secret-test
namespace: exporter
type: Opaque
stringData:
password: your password #对应 Redis 密码
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: redis-exporter # 根据业务需要调整成对应的名称,建议加上 Redis 实例的信息
name: redis-exporter # 根据业务需要调整成对应的名称,建议加上 Redis 实例的信息
namespace: exporter
spec:
replicas: 1
selector:
matchLabels:
k8s-app: redis-exporter # 根据业务需要调整成对应的名称,建议加上 Redis 实例的信息
template:
metadata:
labels:
k8s-app: redis-exporter # 根据业务需要调整成对应的名称,建议加上 Redis 实例的信息
spec:
containers:
- env:
- name: REDIS_ADDR
value: ip:port # 对应 Redis 的 ip:port
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redis-secret-test
key: password
image: oliver006/redis_exporter
imagePullPolicy: IfNotPresent
name: redis-exporter
ports:
- containerPort: 9121
name: metric-port # 这个名称在配置抓取任务的时候需要
securityContext:
privileged: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: 你的imagePullSecrets
prometheus PodMonitor配置
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: redis-exporter
namespace: exporter
spec:
namespaceSelector:
matchNames:
- exporter
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metric-port
selector:
matchLabels:
k8s-app: redis-exporter
Redis Data Source 插件
使用最近推出的grafana redis插件也是个不错的选择,包含stream式的实时监控和集群监控dashboard,stream式的dashborad支持在grafana面板中输入命令行。缺点就是缺乏审计功能。折中而言可以通过只读账号限制,不过还是不够完美。
https://grafana.com/grafana/plugins/redis-app/
插件列表中才能看到,配置下redis信息就可以
grafana-cli plugins install redis-app
命令行dashboard
集群dashboard
rocketmq-exporter
grafana: 10477
https://github.com/apache/rocketmq-exporter
docker版: docker container run -it --rm -p 5557:5557 -e rocketmq.config.namesrvAddr=IP:9876 huiwq1990/rocketmq-exporter
k8s版:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: rocketmq-exporter
name: rocketmq-exporter
namespace: exporter
spec:
replicas: 1
selector:
matchLabels:
k8s-app: rocketmq-exporter
template:
metadata:
labels:
k8s-app: rocketmq-exporter
spec:
containers:
- env:
- name: rocketmq.config.namesrvAddr
value: "IP:9876"
- name: rocketmq.config.webTelemetryPath
value: "/metrics"
- name: server.port
value: "5557"
image: huiwq1990/rocketmq-exporter
imagePullPolicy: IfNotPresent
name: rocketmq-exporter
ports:
- containerPort: 5557
name: metric-port # 这个名称在配置抓取任务的时候需要
securityContext:
privileged: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: rocketmq-exporter
namespace: exporter
spec:
namespaceSelector:
matchNames:
- exporter
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metric-port
selector:
matchLabels:
k8s-app: rocketmq-exporter
mysql-exporter
https://github.com/prometheus/mysqld_exporter
elasticsearch_exporter
https://github.com/justwatchcom/elasticsearch_exporter
grafana:6483
apiVersion: v1
kind: Secret
metadata:
name: es-secret-test
namespace: es-demo
type: Opaque
stringData:
esURI: http://admin:pass@localhost:9200 #对应 ElasticSearch 的 URI
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: es-exporter
name: es-exporter
namespace: exporter
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: es-exporter
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
k8s-app: es-exporter
spec:
containers:
- env:
- name: ES_ALL
value: "true"
- name: ES_URI
valueFrom:
secretKeyRef:
key: esURI
name: es-secret-test
optional: false
image: bitnami/elasticsearch-exporter:latest
imagePullPolicy: IfNotPresent
name: es-exporter
ports:
- containerPort: 9114
name: metric-port
protocol: TCP
resources: {
}
securityContext:
privileged: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: 你的imagePullSecrets
prometheus PodMonitor
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: es-exporter
namespace: exporter
spec:
namespaceSelector:
matchNames:
- exporter
podMetricsEndpoints:
- interval: 15s
path: /metrics
port: metric-port
selector:
matchLabels:
k8s-app: es-exporter
腾讯云对接Grafana
腾讯云监控插件及大盘
日志服务对接Grafana

卸载监控套件
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
参考文献:
https://github.com/prometheus-operator/kube-prometheus
https://github.com/prometheus/jmx_exporter
https://grafana.com/grafana/dashboards/8563
https://www.jianshu.com/p/7fb9e68a5a6c
https://www.it610.com/article/1288617417697730560.htm
转载请注明出处。