前言
”数据可视化“这个话题,相信大家并不陌生,在一些平台,经常可以看到一些动态条形图的视频,大多都是某国家 GDP 的变化或者不同国家疫情中感染人数的变化等等。
这篇文章,我们将使用 Python 绘制动态词频条形图,顾名思义,就是以词频作为数量指标的动态条形图。
前期准备
输入以下命令,安装必须的库:
pip install JiashuResearchTools pip install jieba pip install pandas pip install bar_chart_race
数据的选择与获取
我们这次使用的数据是简书文章收益排行榜,日期范围为 2020 年 6 月 20 日至 2021 年 9 月 18 日。
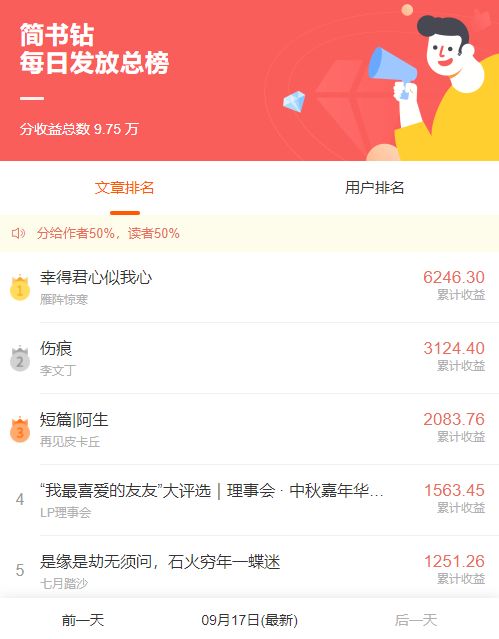
从网页中解析数据的过程较为复杂,我们使用简书数据科学库 JianshuResearchTools 完成。
为方便调试,我们使用 Jupyter Notebook 进行交互式开发。
导入 JianshuResearchTools,并为其设置别名:
import JianshuResearchTools as jrt
调用接口,获取 2021 年 9 月 17 日的数据:
jrt.rank.GetArticleFPRankData("20210917")
返回的数据如下:
[{'ranking': 0,
'aslug': 'a03adf9d5dd5',
'title': '幸得君心似我心',
'author_name': '雁阵惊寒',
'author_avatar_url': 'https://upload.jianshu.io/users/upload_avatars/26225608/682b892e-6661-4f98-9aab-20b4038a433b.jpg',
'fp_to_author': 3123.148,
'fp_to_voter': 3123.148,
'total_fp': 6246.297},
{'ranking': 1,
'aslug': '56f7fe236842',
'title': '伤痕',
'author_name': '李文丁',
'author_avatar_url': 'https://upload.jianshu.io/users/upload_avatars/26726969/058e18c4-908f-4710-8df7-1d34d05d61e3.jpg',
'fp_to_author': 1562.198,
'fp_to_voter': 1562.198,
'total_fp': 3124.397},
(以下省略)
可以看出,返回的数据中包含文章的排名、标题、作者名、作者头像链接和关于简书资产的一些信息。
我们只需要文章的标题进行统计,所以我们将上面获取到的数据赋值给变量 raw_data,然后:
[item["title"] for item in raw_data]
使用列表推导式,我们得到了文章标题组成的列表。
为方便处理,我们将这些数据连接起来,中间用空格分隔:
" ".join([item["title"] for item in raw_data])
但是我们遇到了报错:
TypeError: sequence item 56: expected str instance, NoneType found
从报错信息中可以看出,我们获取到的文章标题列表中有空值,导致字符串的连接失败了。
(空值是因为作者删除了文章)
所以我们还需要加入去除空值的逻辑,代码编程这样:
" ".join(filter(None, [item["title"] for item in raw_data]))
filter 函数在第一个参数为 None 时,默认过滤掉列表中的空值。
现在我们获取到的数据如下:
'幸得君心似我心 伤痕 短篇|阿生 “我最喜爱的友友”大评选|理事会 · 中秋嘉年华,等你来! 是缘是劫无须问,石火穷年一蝶迷 职业日记|从蜜月到陌路:我和美国外教的一点事 红楼||浅谈《红楼梦》开篇一顽石 城市印象|走笔八卦城 花豹与狗的爱情终结在人与动物的战争里(以下省略)
接下来,我们需要获取时间范围内的所有数据。
查询 JRT 的函数文档可知,我们需要一个字符串类型,格式为”YYYYMMDD“的参数表示目标数据的日期。
所以我们需要写一段程序,用于实现这些日期字符串的生成,代码如下:
from datetime import date, timedelta
def DateStrGenerator():
start_date = date(2020, 6, 20)
after = 0
result = None
while result != "20210917":
current_date = start_date + timedelta(days=after)
result = current_date.strftime(r"%Y%m%d")
yield result
after += 1
接下来,我们编写一段代码,实现对这些数据的获取:
result = []
for current_date in tqdm(DateStrGenerator(), total=455):
raw_data = jrt.rank.GetArticleFPRankData(current_date)
processed_data = " ".join(filter(None, [item["title"] for item in raw_data]))
result.append({"date": current_date,
"data": processed_data})
这里使用 tqdm 库显示了一个进度条,非必须。
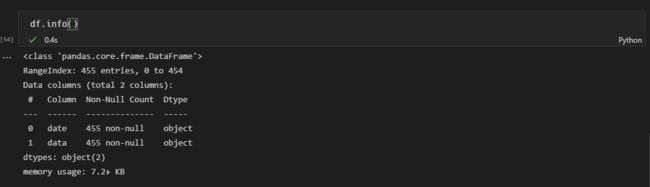
使用 Pandas 库,将我们采集到的数据转换成 DataFrame:
df = pandas.DataFrame(result)

分词
我们使用 jieba 库实现分词,先尝试对第一条数据进行处理:
jieba.lcut(df["data"][0])
使用 Python 标准库 collections 中的 Counter 进行词频统计:
Counter(jieba.lcut(df["data"][0]))
简单画个条形图:
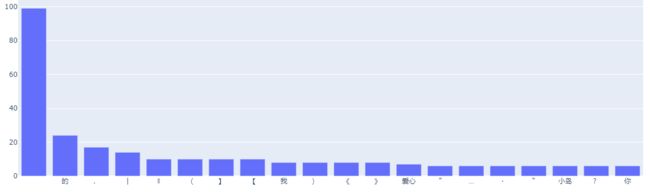
可以看到,空格和一些标点符号,包括”的“、”我“之类无意义词汇出现频率很高,我们需要将它们剔除出去。
我们构建一个存放停用词的 txt 文档,之后使用如下代码将其读取,并转换成一个列表:
stopwords_list = [item.replace("\n", "") for item in open("stopwords.txt", "r", encoding="utf-8").readlines()]
接下来,编写一个函数,实现停用词的剔除,为了方便后续的数据处理,我们也一并剔除单字和只出现一次的词语:
def process_words_count(count_dict):
result = {}
for key, value in count_dict.items():
if value < 2:
continue
if len(key) >= 2 and key not in stopwords_list:
result[key] = value
return result
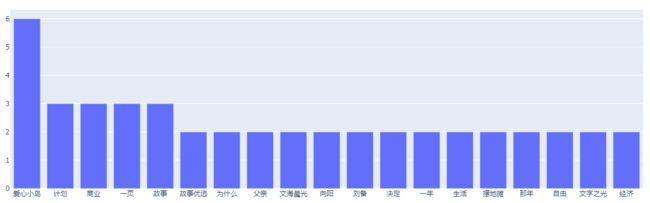
另外,我们使用 jieba 库的 add_word 函数将一些简书中的组织名和专有名词添加到词库中,从而提高分词的准确性,代码如下:
keywords_list = [item.replace("\n", "") for item in open("keywords.txt", "r", encoding="utf-8").readlines()]
for item in keywords_list:
jieba.add_word(item)
经过一番处理,现在分词效果有了明显的改善:
最后,用这段代码对所有数据进行分词,并将结果保存到另一个 DataFrame 中:
data_list = []
date_list = []
for _, item in df.iterrows():
date_list.append(datetime(int(item["date"][0:4]), int(item["date"][4:6]), int(item["date"][6:8])))
data_list.append(process_words_count(Counter(jieba.lcut(item["data"]))))
processed_df = pandas.DataFrame(data_list, index=date_list)
我最终得到的结果是一个 455 行,2087 列的 DataFrame。
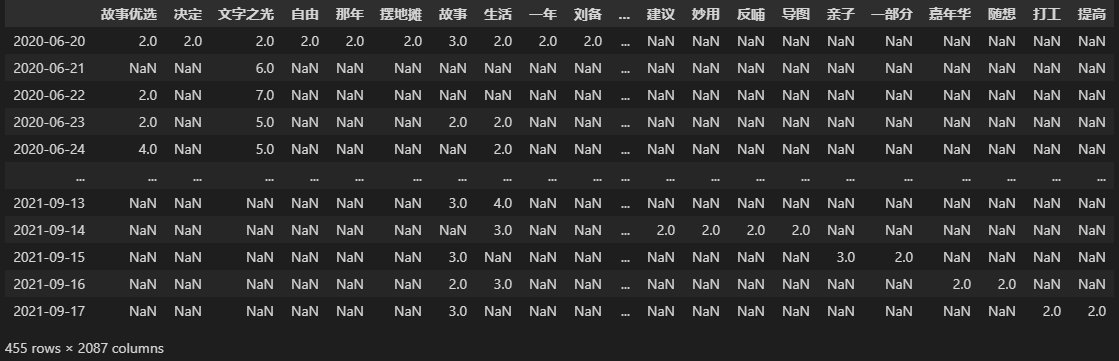
筛选与可视化
这样多的数据,其中很大一部分都不能代表整体情况,所以我们需要进行数据筛选。
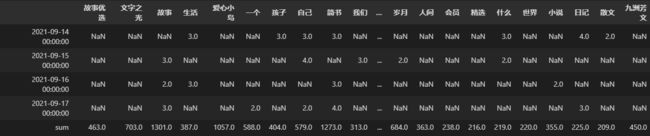
使用以下代码,统计所有列数值的总和,即每个关键词在全部数据中出现的次数,存储到名为 sum 的行中:
try:
result = []
for i in range(3000):
result.append(processed_df.iloc[:, i].sum())
except IndexError:
processed_df.loc["sum"] = result
运行以下代码,只保留在数据集中出现 300 次以上的关键词:
maller_df = processed_df.T[processed_df.T["sum"] >= 300].T smaller_df = smaller_df.drop(labels="sum") smaller_df.columns
现在,数据集中的列数减少到了 24 个,可以进行可视化了。
不要忘记先导入模块:
import bar_chart_race as bcr
使用此模块需要先安装 ffmpeg,这方面教程可以自行查找。
另外,为了支持中文显示,我们需要打开这个模块下的 _make_chart.py 文件,在 import 之后增加以下两行代码:
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False
这两行代码将会把 matplotlib 的默认字体替换成支持中文显示的字体。
最后,使用一行代码完成可视化:
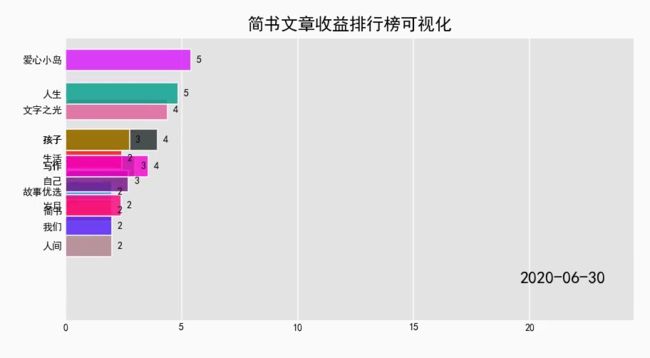
bcr.bar_chart_race(smaller_df, steps_per_period=30, period_length=1500, title="简书文章收益排行榜可视化", bar_size=0.8, fixed_max=10, n_bars=10)
在这行代码中,我们使用 smaller_df 作为数据集,输出文件为 output.mp4,帧率设置为 30,每行数据显示 2 秒。
由于数据较多,这一步时间较长,而且会占用较多内存。运行结束后,即可在目录中找到输出的文件。
总结
到此这篇关于Python制作动态词频条形图的文章就介绍到这了,更多相关Python制作动态词频条形图内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!