刷穿剑指offer-Day14-哈希表I 基础知识整理
引子
哈希表作为算法解题中的top数据结构,因为其查找、插入、删除的平均复杂度都是O(1),可以大幅度缩减时间复杂度,所以成为一种空间换时间的解题方式。
有人相爱,有人夜里开车看海,有人leetcode第一题都做不出来。
很多第一次刷力扣算法的朋友,都在 twoSum 这道题中看到了这句评论,也相信有90%的朋友在第一次在做这道题的时候也和我一样,使用了双层for循环的O(n ^ 2)时间复杂度去提交。

直到后来,学习了哈希表才了解了更高效的解题方法。那么今天,我们就要开始哈希表的学习了,它真的是所有数据结构中扛把子级别的选手,需要我们认真去对待。
哈希函数与寻址表
哈希函数是一个可以将任意长度的数据块映射到固定长度的值,这个步骤称为hash,也就是散列。
而哈希表又称为散列表,是一种线性表的存储结构,它由一个哈希函数和一个直接寻址表组成。
哈希表经常作为面试考点,力扣上就有对应的两道题目 设计哈希集合 和 设计哈希映射。只有我们理解了哈希表的实现原理才谈得上设计,让我们一步步的去理解哈希表吧。
上面我们提到了哈希表是由一个哈希函数和一个直接寻址表组成,这两者缺一不可。根据哈希函数的定义,我们可以变相的理解为不管系统告诉我们的是一个数字、字符串还是其他的什么,我都可以将其转化成一个具体的标识符与和寻址表做对应。
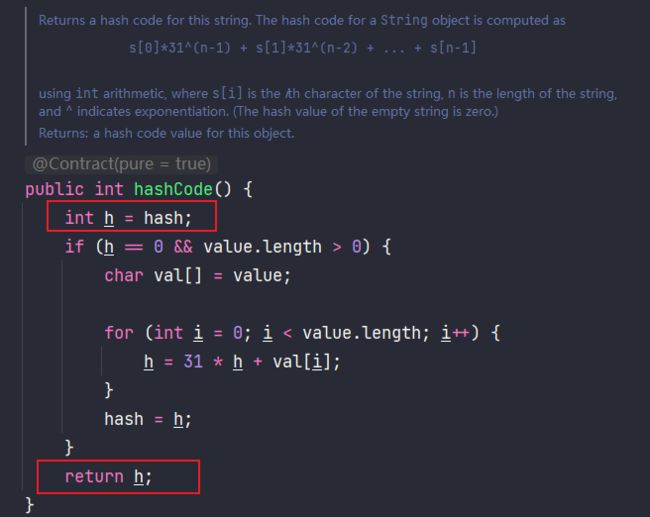
Python有hash函数,而Java中存在hashCode,他们都可以将任意的内容转化为一个固定的整数。那么,我们将转化后的整数与寻址表的下标做对应,就完成了一个理论上的hash表。
然而,整数的范围太大了,我们初始化一个如此大的寻址表,然后只存寥寥几个数组,会造成多大的空间浪费啊,这显然是不切实际的想法。那么如何节约内存开销?我们在刷穿剑指offer系列Day3中讲解了整数的取模与快速幂操作。当时还专门引出了一段前戏,问题是:
对
10 ^ 9 + 7取余,到底有什么含义?
没错,既然我们想缩小寻址表的空间,我们就可以通过取模的操作来实现,然而使用什么数字进行取模才能分布均匀呢,当然是尽可能大的质数。比如最小的7、13 、17 等等...
我们每输入一个内容,通过哈希函数转换后取模,就可以定位到有限的寻址表了。但这样操作,又会引出一个问题。即便我们使用足够大的质数,难免会出现哈希后取模结果一样的场景,那该怎么办?
这种场景叫做 哈希冲突!
哈希冲突
上面提到,由于我们为了节约空间所以缩小了寻址表的大小,导致可能会出现哈希冲突的情况。
比如,我们创建了一个长度为7的寻址表,此时我们需要保存{x:100}和{y:200},x和y两个key在执行哈希后的结果分别为1和8。那么两者对7取模的结果都为1。
那么,当遇到这种情况应该如何解决呢?一般常见的有两种解决办法:
- 开放寻址法(开放地址法),又细分为线性探查、二次探查、二度哈希
- 链式地址法(拉链发)
对于第一种解决办法,当x存入寻址表index1位置后,y发现x把index1这个下标占了,它就依次往后找2有没有占,没有占我就用index2,如果依然被占了就继续往后找,直到找到结果。
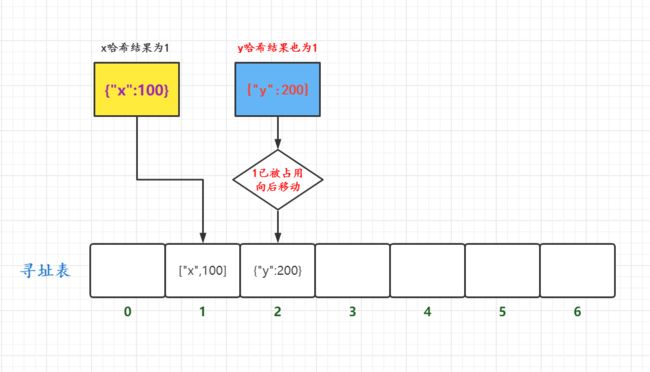
很多人会说,这样错乱的保存,我们在取数的时候该怎么拿呢?我们来思考下
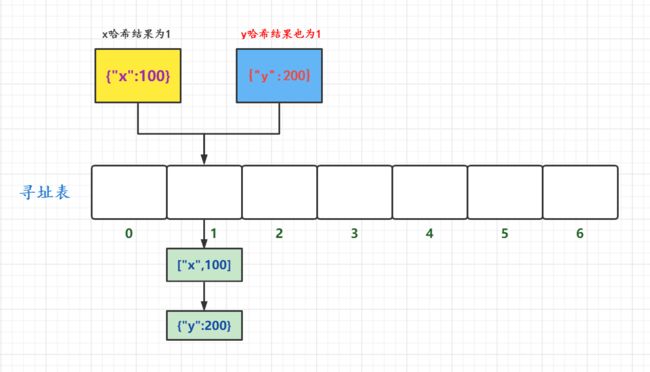
- 如果是找x,我们hash后取模找到寻址表的1节点,此时节点数据为["x", 100],找到了key,直接返回100。
- 如果是找y,我们hash后取模找到寻址表的1节点,发现不是y,那就往后找,找到下一个节点["y",200]是结果,返回200
这样的操作方式就是开放寻址法中的线性探查。至于二次探查和二度哈希,原理也是如此。
对于第二种解决办法,当x存入寻址表index1位置后,y发现x把index1这个下标占了,此时我们就需要在index1的位置创建一个链表,然后将x、y分别添加至链表。这样下次在查找x和y时,遍历链表节点并返回即可。
不管是第一种办法,还是第二种办法,出现了这种哈希冲突后,都会造成哈希表的时间复杂度提升,所以说到哈希表的时间复杂度都是指的平均时间复杂度。
介绍了这么多内容,不做一道题目,怎么验证知识的掌握程度,让我们先来做一道简单的设计哈希集合题目。
705.设计哈希集合
https://leetcode-cn.com/problems/design-hashset/solution/705-she-ji-ha-xi-ji-he-xiang-na-yao-duo-2jo2w/
难度:简单
题目
不使用任何内建的哈希表库设计一个哈希集合(HashSet)。实现 MyHashSet 类:
- void add(key) 向哈希集合中插入值 key 。
- bool contains(key) 返回哈希集合中是否存在这个值 key 。
- void remove(key) 将给定值 key 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
提示:
- 0 <= key <= 10 ^ 6
- 最多调用 10 ^ 4 次 add、remove 和 contains 。
示例
输入:
["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]
解释:
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = [1]
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(1); // 返回 True
myHashSet.contains(3); // 返回 False ,(未找到)
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(2); // 返回 True
myHashSet.remove(2); // set = [1]
myHashSet.contains(2); // 返回 False ,(已移除)分析
通过我们介绍的哈希表知识,再来做这道题就不会显得无从下手了。
首先,我们可以考虑一种极限场景,即构造一个 0 <= key <= 10 ^ 6 长度的寻址表。
这样,无需任何操作,就可以在O(1)的时间内返回答案了。
验证是可行的。但这样的解题很明显面试的时候要被吊打。
所以,我们还是来考虑链式地址法,即通过数组与链表的方式设计一个哈希集合。
两种解题如下:
与key等长的寻址表
Python:
class MyHashSet:
def __init__(self):
self.my_set = [False] * 1000001
def add(self, key: int) -> None:
self.my_set[key] = True
def remove(self, key: int) -> None:
self.my_set[key] = False
def contains(self, key: int) -> bool:
return self.my_set[key]Java:
class MyHashSet {
boolean[] mySet = new boolean[1000001];
public void add(int key) {
mySet[key] = true;
}
public void remove(int key) {
mySet[key] = false;
}
public boolean contains(int key) {
return mySet[key];
}
}链式地址法解题
Python:
class MyHashSet:
def __init__(self):
self.mod = 1007
self.table = [[] for _ in range(self.mod)]
def hash(self, key):
return key % self.mod
def div(self, key):
return key // self.mod
def add(self, key):
hash_key = self.hash(key)
if not self.table[hash_key]:
self.table[hash_key] = [0] * self.mod
self.table[hash_key][self.div(key)] = 1
def remove(self, key):
hash_key = self.hash(key)
if self.table[hash_key]:
self.table[hash_key][self.div(key)] = 0
def contains(self, key):
hash_key = self.hash(key)
return self.table[hash_key] != [] and self.table[hash_key][self.div(key)] == 1Java:
class MyHashSet {
private static final int BASE = 1007;
private LinkedList[] mySet;
private static int hash(int key) {
return key % BASE;
}
public MyHashSet() {
mySet = new LinkedList[BASE];
for (int i = 0; i < BASE; i++) {
mySet[i] = new LinkedList();
}
}
public void add(int key) {
int h = hash(key);
Iterator iterator = mySet[h].iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
if (value == key) {
return;
}
}
mySet[h].offerLast(key);
}
public void remove(int key) {
int h = hash(key);
Iterator iterator = mySet[h].iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
if (value == key) {
mySet[h].remove(value);
return;
}
}
}
public boolean contains(int key) {
int h = hash(key);
Iterator iterator = mySet[h].iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
if (value == key) {
return true;
}
}
return false;
}
} 今天关于哈希表的知识就学习到这里,明天我们需要通过学习HashSet和HashMap来完成相关类型题目。
欢迎关注我的公众号: 清风Python,带你每日学习Python算法刷题的同时,了解更多python小知识。
我的个人博客:https://qingfengpython.cn
力扣解题合集:https://github.com/BreezePython/AlgorithmMarkdown