Flink流处理API——window(窗口) API详解
原文链接:https://www.toutiao.com/i6859649771255104012/
本文主要从以下几个方面介绍Flink流处理API——window(窗口) API
一、window概念
二、window类型
三、windowAPI 的Demo
四、时间语义
五、设置事件创建时间(Event Time)
六、水位线(Watermark)
七、watermark的API
版本:
scala:2.11.12
Kafka:0.8.2.2
Flink:1.7.2
pom.xml依赖部分(log日志的依赖一定要加上,否则当Flink链接Kafka0.8时会报Failed to instantiate SLF4J LoggerFactory Reported exception错误)
org.apache.flink
flink-scala_2.11
1.7.2
org.apache.flink
flink-streaming-scala_2.11
1.7.2
provided
org.apache.flink
flink-clients_2.11
1.7.2
org.apache.flink
flink-connector-kafka-0.8_2.11
1.7.2
org.slf4j
slf4j-api
1.7.22
org.slf4j
slf4j-log4j12
1.7.22
org.apache.bahir
flink-connector-redis_2.11
1.0
一、window概念

streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 window 是一种切割无限数据为有限块进行处理的手段。Window 是无限数据流处理的核心, Window 将一个无限的 stream 拆分成有限大小的集合,我们可以在这些集合上做计算操作。(类似于Spark的批处理,每次处理一小部分)。
二、window类型
- 时间窗口(Time Window):按照时间生成Window
1、滚动时间窗口
将数据依据固定的窗口长度对数据进行切片 。时间对齐,窗口长度固定,没有重叠。

2、滑动时间窗口
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定, 可以有重叠。

3、会话窗口
由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。

- 计数窗口(CountWindow):按照数据的条数生成Window
1、滚动计数窗口
2、滑动计数窗口
计数窗口类似于上面的时间窗口。
三、windowAPI 的Demo
数据源:从kafka中进行读取
package xxx
import java.util.Properties
import com.njupt.ymh.APITest.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08
// 样例类,传感器ID,时间戳,温度 (后面都使用这个样例类作为数据的类型)
case class SensorReading(id: String, timestamo: Long, temperature: Double){
override def toString: String = {
id+":"+ timestamo.toString + "," + temperature
}
}
/**
*窗口测试
*/
object SlidingWindowTest {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置读取的kafka参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "slave1:9092,slave2:9092,slave3:9092")
properties.setProperty("group.id", "flink_group1")
properties.setProperty("zookeeper.connect", "slave2:2181,slave3:2181,slave4:2181")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") // key的反序列化
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") // value的反序列化
properties.setProperty("auto.offset.reset", "latest") // 偏移量
// 链接kafka读取数据
val kafkaStream: DataStream[String] = environment.addSource(new FlinkKafkaConsumer08[String]("window",
new SimpleStringSchema(), properties))
// transform操作
val maped: DataStream[SensorReading] = kafkaStream.map(line => {
val fildes: Array[String] = line.split(",") // 这里的split是scala的split方法
SensorReading(fildes(0).trim, fildes(1).trim.toLong, fildes(2).trim.toDouble)
})
// 开窗操作需要在KeyBy之后能用
val keyByed: KeyedStream[(String, Double), Tuple] = maped.map(data => {
(data.id, data.temperature)
}).keyBy(0)
// 开窗操作写在这里
environment.execute()
}
}- 创建滚动时间窗口
// 创建滚动时间窗口
val window: WindowedStream[(String, Double), Tuple, TimeWindow] = keyByed.timeWindow(
Time.seconds(5)) // 开窗时间
val windowReduced: DataStream[(String, Double)] = window.reduce((data1, data2) => {
(data1._1, data1._2.min(data2._2)) // 对每个窗口内的数据进行聚合,求最小温度
})- 创建滑动时间窗口
// 创建滑动时间窗口
val window: WindowedStream[(String, Double), Tuple, TimeWindow] = keyByed.timeWindow(
Time.seconds(5), Time.seconds(2)) // 开窗时间,滑动步长
val windowReduced: DataStream[(String, Double)] = window.reduce((data1, data2) => {
(data1._1, data1._2.min(data2._2)) // 对每个窗口内的数据进行聚合,求最小温度
})- 创建会话窗口
// 创建会话窗口
val sessionWindow: WindowedStream[(String, Double), Tuple, TimeWindow] = keyByed.window(
EventTimeSessionWindows.withGap(Time.minutes(2))) // 会话间隔多长时间
val sessionWindowReduced: DataStream[(String, Double)] = sessionWindow.reduce((data1, data2) => {
(data1._1, data1._2.min(data2._2)) // 对每个窗口内的数据进行聚合,求最小温度
})- 创建滚动计数窗口
// 创建滚动计数窗口
val tumblingCountWindow: WindowedStream[(String, Double), Tuple, GlobalWindow] = keyByed.countWindow(5)- 创建滑动计数窗口
// 创建滑动计数窗口
val slidingCountWindow: WindowedStream[(String, Double), Tuple, GlobalWindow] = keyByed.countWindow(5, 2)- 另外还有其他可选API
.trigger() —— 触发器 定义 window 什么时候关闭,触发计算并输出结果
.evitor() —— 移除器 定义移除某些数据的逻辑
.allowedLateness() —— 允许处理迟到的数据
.sideOutputLateData() —— 将迟到的数据放入侧输出流
.getSideOutput() —— 获取侧输出流 四、时间语义
在Flink的流数据进行时间窗口处理时,是根据时间来进行划分窗口的。这里就会涉及时间的不同概念,如下图:

- Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间, Flink 通过时间戳分配器访问事件时间戳。
- Ingestion Time:是数据进入 Flink 的时间。
- Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
但是这里有个问题,在某些场景下往往更关心事件时间(Event Time)。
例如,在我们玩CF等游戏时,A和B两个人对战,A于1分19秒开枪爆头B,B于1分19.2秒开枪爆头A。但是由于网络等原因,A开枪的数据需要1秒传输到服务器,B的数据只需要0.2秒传输到服务器。那么服务器就会先收到B的数据,服务器如果判定B赢,似乎对A不公平。这里就需要等A和B的数据都到达服务器的时候,看看谁的开枪时间更早,也就是事件时间(Event Time)
五、设置事件创建时间(Event Time)
在 Flink 的流式处理中,绝大部分的业务都会使用 eventTime,一般只在eventTime 无法使用时,才会被迫使用 ProcessingTime 或者 IngestionTime。
如果要使用 EventTime,那么需要引入 EventTime 的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给 env 创建的每一个 stream 追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)六、水位线(Watermark)
但是,这里比较EventTime就会有另一个问题,例如上面的游戏例子,服务器等待A、B的数据都到达服务器的时间要等多久,加入A压根就没有开枪,服务器会一直等下去吗?
这里就需要引入水位线的概念。
我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了,这个特别的机制,就是 Watermark。
- Watermark 是一种衡量 Event Time 进展的机制。平衡结果正确性以及时间延迟的机制
- Watermark是只能增长,不能减少。例如,我们收到时间戳为18秒的数据,认为Watermark为17秒(延时设为1秒),不能在下次收到时间戳为16秒的数据的时候认为Watermark为15秒,而应保持不变。当收到19秒的数据时,Watermark上涨为18秒。
- Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark 机制结合 window 来实现。
- 数据流中的 Watermark 用于表示 timestamp(时间戳)小于 Watermark 的数据,都已经到达了,因此, window 的执行也是由 Watermark 触发的。
- Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 eventTime比 maxEventTime 小t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
加入我们设置Wateramrk的等待时间是0.5秒,那么当B的数据来得时候我们认为19.2-0.5=18.7秒之前的数据都已经到达服务器。假设服务器收到一个20.3秒的数据,那么服务器此时的Watermark就是20.3-0.5=19.8秒,并且有个窗口函数的闭窗时间为19.5秒,那么服务器此时就不会继续等待A的数据,而进行关窗。
另外,还有一个问题是,假如有多个分区的数据来,以哪个时间戳作为产生watermark的基础呢?
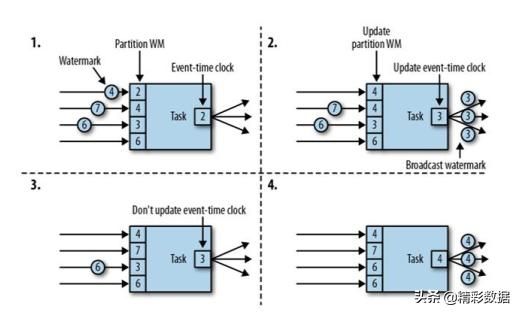
我们应以所有分区中各个分区的Watermark最小的值作为watermark。
而每个分区计算Warkmark时,应以当前该分区中最大时间戳减去延时时间为Watermark。
七、watermark的API
我们以开滑动窗口并且设置EventTime为例来设置watermark
package xxx
import java.util.Properties
import com.njupt.ymh.APITest.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08
// 样例类,传感器ID,时间戳,温度 (后面都使用这个样例类作为数据的类型)
case class SensorReading(id: String, timestamo: Long, temperature: Double){
override def toString: String = {
id+":"+ timestamo.toString + "," + temperature
}
}
/**
*watermark测试
*/
object SlidingWindowTest {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 需要通过setStreamTimeCharacteristic显示的指出以EventTime作为时间戳时
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置读取的kafka参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "slave1:9092,slave2:9092,slave3:9092")
properties.setProperty("group.id", "flink_group1")
properties.setProperty("zookeeper.connect", "slave2:2181,slave3:2181,slave4:2181")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") // key的反序列化
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") // value的反序列化
properties.setProperty("auto.offset.reset", "latest") // 偏移量
// 链接kafka读取数据
val kafkaStream: DataStream[String] = environment.addSource(new FlinkKafkaConsumer08[String]("window",
new SimpleStringSchema(), properties))
// transform操作
val maped: DataStream[SensorReading] = kafkaStream.map(line => {
val fildes: Array[String] = line.split(",") // 这里的split是scala的split方法
SensorReading(fildes(0).trim, fildes(1).trim.toLong, fildes(2).trim.toDouble)
})
//这里写设置watermark的操作
// 将maped设置watermark后变为watermarked
// 开窗操作需要在KeyBy之后能用
val keyByed: KeyedStream[(String, Double), Tuple] = watermarked.map(data => {
(data.id, data.temperature)
}).keyBy(0)
// 创建滑动时间窗口
val window: WindowedStream[(String, Double), Tuple, TimeWindow] = keyByed.timeWindow(
Time.seconds(15), Time.seconds(5)) // 开窗时间,滑动步长
val windowReduced: DataStream[(String, Double)] = window.reduce((data1, data2) => {
(data1._1, data1._2.min(data2._2)) // 对每个窗口内的数据进行聚合,求最小温度
})
windowReduced.print().setParallelism(1)
environment.execute()
}
}watermark的引入,以及采用哪个字段作为eventTime
// 引入watermark
val watermarked: DataStream[SensorReading] = maped.assignTimestampsAndWatermarks(
// 括号的参数是eventTime减x秒为watermark
new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
// 生成eventTime的方式(以哪个字段作为EventTime)
override def extractTimestamp(t: SensorReading): Long = (t.timestamo * 1000).toLong
})Event Time 的使用一定要指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话,就只能使用 Processing Time 了)。
另外也可以这样指定:
// 通过自定义类引入watermark和指定哪个字段作为EventTime
val watermarked: DataStream[SensorReading] = maped.
assignTimestampsAndWatermarks(new MyAssigner())而MyAssigner可以继承的有两种类型:
- AssignerWithPeriodicWatermarks(周期性计算Watermark)
- AssignerWithPunctuatedWatermarks(打断式的计算Watermark)
以上两个接口都继承自 TimestampAssigner。
1、AssignerWithPeriodicWatermarks:(周期性计算Watermark)
/**
* 自定义抽取时间戳,以及生成watermark方法,表示周期性的抽取时间戳
*/
class MyAssigner() extends AssignerWithPeriodicWatermarks[SensorReading]{
val bound: Long = 1000 // 延时1秒
var maxTimestamp: Long = Long.MinValue // 记录观察到的最大时间
// 计算当前watermark的值,以Flink接收到的数据中最大的时间戳减1秒作为watermark
// 例如,已经接收到 1,3,4,6 四个时间的数据, 则当前Watermark为5,
// Flink会认为5这个时间戳之前的数据都已经收集好了(其实可能并没有)。
override def getCurrentWatermark: Watermark = {
new Watermark(maxTimestamp - bound)
}
// 抽取时间戳方法
override def extractTimestamp(t: SensorReading, l: Long): Long = {
maxTimestamp = maxTimestamp.max((t.temperature*1000).toLong)
t.timestamo*1000
}
}既然是周期性的产生Watermark,就需要设置周期时间:
// 默认200毫秒,这里设置为为1秒
environment.getConfig.setAutoWatermarkInterval(1000L)产生 watermark 的逻辑:每隔 1 秒钟, Flink 会调用AssignerWithPeriodicWatermarks 的 getCurrentWatermark()方法。如果方法计算出的水位大于之前水位的时间戳,新的 watermark 会被插入到流中。这个检查保证了水位线是单调递增的。如果方法返回的时间戳小于等于之前水位的时间戳,则不会产生新的 watermark。
2、AssignerWithPunctuatedWatermarks:(打断式的计算Watermark)
例如,我们知道1号传感器的延迟最大,我们以1号传感器发送来的数据作为当前最大EventTime计算来源,并且只当1号传感器传来数据的时间戳计算Watermark。
/**
* 打断式生成watermark
*/
class MyAssignerPunctuated extends AssignerWithPunctuatedWatermarks[SensorReading]{
val bound: Long = 1000 // 延时1秒
var maxTimestamp: Long = Long.MinValue // 记录观察到的最大时间
// t: 当前数据,可用于最为判断条件, l:提取出的时间戳
override def checkAndGetNextWatermark(t: SensorReading, l: Long): Watermark = {
if(t.id == "sensor_1"){ // 每当遇到1号传感器的数据设置一次watermark
new Watermark(l - bound)
}else{
null
}
}
// 抽取时间戳方法(仅抽取1号传感器)
override def extractTimestamp(t: SensorReading, l: Long): Long = {
if(t.id == "sensor_1"){
maxTimestamp = maxTimestamp.max((t.temperature*1000).toLong)
t.timestamo*1000
}
else {
maxTimestamp
}
}
}