RabbitMQ的Federation和Shovel的使用
一、跨越集群的界限
RabbitMQ可以通过3种方式实现分布式部署:集群、Federation、Shovel。Federation和Shovel可以为RabbitMQ的分布式部署提供更高的灵活性,但也提高了部署的复杂性
二、Federation介绍与使用
2-1、Federation的目标
Federation插件的设计目标是使RbbitMQ 在不同的 Broker 节点之间进行消息传递而无须建立集群,该功能在很多场景下都非常有用:
- Federation插件使RabbitMQ在不同Broker节点间进行消息传递而无须建立集群,在不同管理域(不同的用户和vhost、不同版本的RabbitMQ Erlang上)中的Broker或集群间传递消息。
- Federation插件基于AMQP 0-9-1协议在不同的Broker之间通信,能容忍不稳定的网络连接情况
- 一个Broker节点中可以同时存在联邦交换器(或队列)或者本地交换器(或队列),只需对特定交换器(或队列)创建Federation连接(Federation link)
- Federation插件可以让多个交换器或者多个队列进行联邦
- 一个联邦交换器federated exchange或者一个联邦队列federated queue接收上游upstream的消息,这里的上游指的是其他Broker上的交换器或者队列
- 联邦交换器能够将原本发送给上游交换器的消息路由到本地的某个队列中;联邦队列则允许本地消费者接收来自上游队列的消息
2-2、联邦交换器
在广域网中,如果因为网路的延迟导致消息发送消息接收确认的时候导致阻塞,降低性能,消费也是同样道理,解决异地的问题,生产者和消费者可以异地部署而感受不到过多的差异
一条Federation link是单向的
broker1->broker3的单向Federation link建立过程:
1、在broker1上创建同名(可配置,默认同名)交换器exchangeA
2、在broker1上建立内部交换器exchangeA->broker3 B,通过路由键rkA与第一步的exchangeA绑定;#broker3是集群名称
3、在broker1上建立队列federation:exchangeA->broker3 B,并与上步的交换器绑定
4、通过AMQP将broker1上的队列中的消息消费到borcker3中的exchangeA中
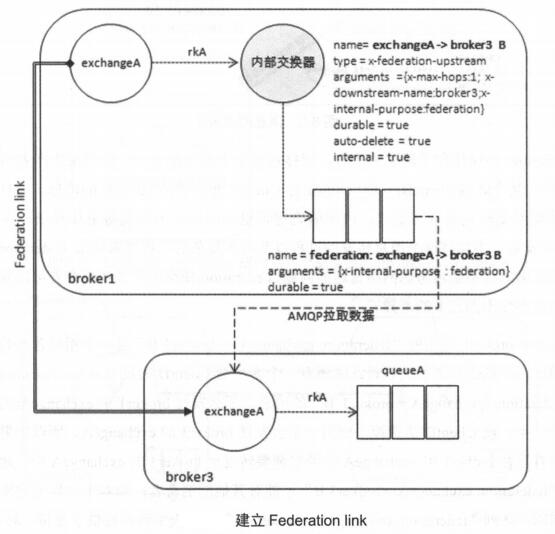
经过Federation link转发的消息会带有特殊的headers属性标记

默认交换器(没有名称的交换器)和内部交换器不能对其使用Federation功能。
联邦交换器可以部署成多叉树、三角形、环形等拓扑
2-3、联邦队列
联邦队列可以在多个Broker节点(或集群)之间为单个队列提供均衡负载的功能。一个联邦队列可以连接一个或多个上游队列upstream queue

brocker2的消费者先消费broker2中的消息,直到消费完,才会到brocker1上去拉消息。消费者既可以消费broker2中的队列,又可以消费broker1中的队列,从而可以提升单个队列的容量,并可在一定程度上做到负载均衡
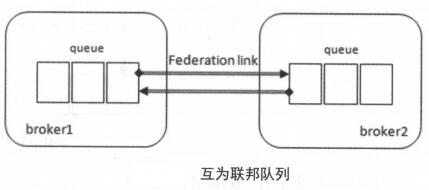
一条消息可以在联邦队列间转发无限次。互为联邦队列可以让有多余消费能力的消费者在brocker1和brocker2中切换
对于联邦队列只能使用Basic.Consume进行消费,而不能用Basic.Get,因为Basic.Get是异步的方法
联邦队列不具备传递性,不能级联
理论上可以将federated queue与federated exchange绑定使用,但这会导致不可预测的结果,若对结果评估不足,慎用这种搭配方式
2-4、Federation的使用
前提是你的RabbitMQ已经安装成功了。没有安装参考:Centos7、Erlang-21.3、RabbitMQ-3.8.0 单机版安装
(1)配置一个或多个upstream,可通过运行时参数或federation management插件来完成
(2)定义匹配交换器或队列的一种/多种策略policy
启用federation插件
rabbitmq-server -detached
rabbitmq-plugins enable rabbitmq_federation
启用federation管理插件
rabbitmq-plugins enable rabbitmq_federation_management
需要在集群中使用Federation功能时,集群中所有节点都应该开启Federation插件
Federation中存在3种级别的配置
1)upstreams,定义与其他broker建立连接的信息
2)upstream sets,对一系列使用Federation功能的upstream进行分组
3)policies,每个policy会选定一组交换器,或队列,或两者进行限定,进而作用于一个单独的upsteam或upsteam set上
默认有一种名为all的upstream set,为隐式定义。upstreams和upstream sets属于运行时参数。Federation相关的运行时参数和策略都可以通过这3种方式进行设置:
通过rabbitmqctl;通过HTTPAPI接口;通过rabbitmq_federation_management的Web管理界面。基于Web管理界面的方式不能提供全部功能,如无法对upstream set进行管理
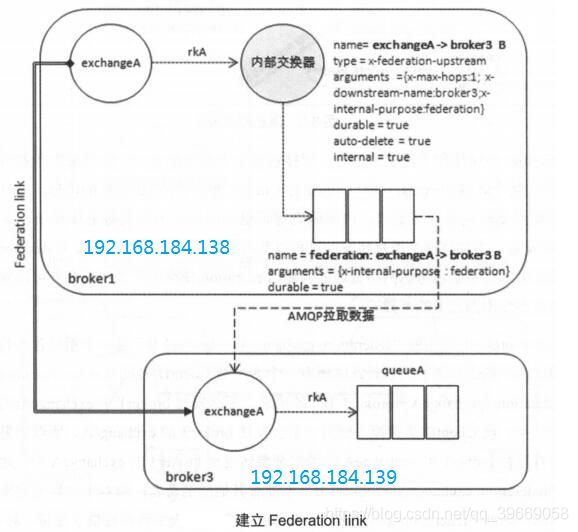
部署步骤:
1、启用插件
在broker1和broker3中开启rabbitmq_federation插件,最好同时开启rabbitmq_federation_management插件
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management
2、定义upstream
在broker3中定义一个upstream
#ack-mode可以是no-ack,on-publish,on-confirm
方法1:rabbitmqctl set_parameter federation-upstream f1 '{"uri":"amqp://admin:123456@192.168.184.138:5672","ack-mode":"on-confirm","expires":3600000}'
方法2:curl -i -u admin:123456 -XPUT -d'{"value":{"uri":"amqp://admin:123456@192.168.184.138:5672","ack-mode":"on-confirm"}}' http://192.168.184.139:15672/api/parameters/federation-upstream/%2F/f1
方法3:在Web上操作
参数说明:
Name,名称
URI,uri,定义AMQP连接
Prefetch count,prefetch_count,Federation内部缓存消息条数,收到上游消息之后且发到下游之前缓存的消息条数
Reconnect delay,reconnect-delay,若连接断开后,需等待多少秒开始重新建立连接
Acknowledgement Mode,ack-mode,消息确认方式,on-confirm(默认),on-publish,no-ack。on-confirm接收到下游确认消息后再向上游发送消息确认,可以确保网络失败或Broker宕机时不丢失消息,但处理速度最慢;on-publish消息发送到下游后,再向上游发送消息确认,可以确保网络失败时不丢失消息,不能确保Broker宕机时的消息丢失;no-ack无须进行消息确认,速度最快,最容易丢失消息
Trust User-ID,trust-user-id,为false时,忽略消息中user_id属性;为true时,只转发user_id为上游任意有效用户的消息
只适合联邦交换器的参数:
Exchange,exchange,指定upstream exchange名称,默认和federated exchange同名
Max hops,max-hops,消息被丢弃前最大跳转次数,默认为1
Expires,expires,连接断开后,上游队列的超时时间,默认为none,表示不删除,单位为ms。相当于设置队列的x-expires参数,设置该值可以避免连接断开后,生产者一直向上游队列发送消息,造成上游大量消息堆积
Message TTL,message-ttl,上游队列的x-message-ttl参数,默认为none,表示没有超时时间
HA Policy,ha-policy,上游队列的x-ha-policy参数,默认为none,表示队列中没有任何HA
只适合联邦队列的参数
Queue,queue,执行upstream queue的名称,默认和federated queue同名
3、定义policy
定义Policy用于匹配交换器exchangeA,并使用第二步所创建的upstream
方法1:rabbitmqctl set_policy --apply-to exchanges p1 "^exchange" '{"federation-upstream":"f1"}'
方法2:curl -i -u admin:admin -XPUT -d'{"pattern":"^exchange","definition":{"federati},"apply-to":"exchanges"}' http://192.168.158.139:15672/api/policies/%2F/p1
方法3:在Web上操作
4、查看状态
rabbitmqctl eval 'rabbit_federation_status:status().'
2-5、定义联邦队列
先定义一个upstream,之后在定义policy时,将apply to指定为queues即可,如
rabbitmqctl set_policy --apply-to queues p2 "^queue" '{"federation-upstream":"f1"}'
三、Shovel介绍与使用
3-1、Shovel介绍
和Federation的数据转发功能类似,Shovel能可靠、持续地从一个Broker的队列(源,source)拉取数据至另一个Broker中的交换器(目的,destination)。源和目的可以是同一个Broker
Shovel优势:
松耦合,解决不同Broker、集群、用户、vhost、MQ和Erlang版本移动消息
支持广域网,可以容忍糟糕的网络,能保证消息的可靠性
高度定制,当Shovel成功连接后,可以配置
3-2、Shovel的原理
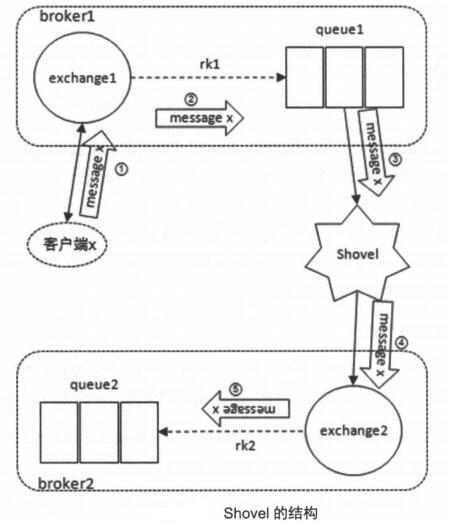
若在配置Shovel link时设置了add_forward_headers参数为true,则最后消息会有特殊headers属性标记

通常源为队列,目的为交换器,但是,也可以源为队列,目的为队列。实际也是由交换器转发,只不过这个交换器是默认交换器

配置交换器做为源也是可行的。实际上会在源端自动新建一个队列,消息先存在这个队列,再被Shovel移走
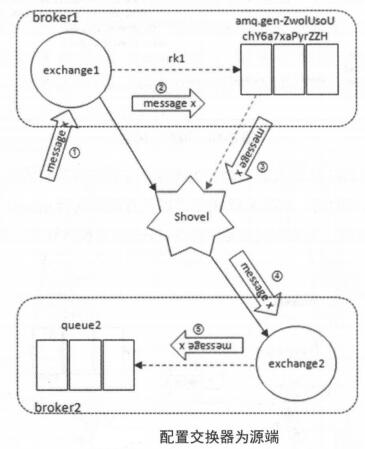
源和目的端的交换器和队列都可以在建立Shovel之后再创建。Shovel可以为源端或目的端配置多个Broker地址,这样可以在一个连接失败后随机挑选其他地址建立连接
3-3、Shovel的使用
#启用插件
rabbitmq-plugins enable rabbitmq_shovel
#启用管理插件
rabbitmq-plugins enable rabbitmq_shovel_management
Shovel既可以部署在源端,也可以部署在目的端。部署方式有静态方式static和动态方式dynamic,静态方式指在rabbitmq.config配置文件中设置,动态方式指运行时Parameter
3-3-1、静态方式
单条Shovel条目构成(shovels部分的下一层)
{rabbitmq_shovel,[{shovels,[{shovel_name,[...]},...]} ]}
其中shovel_name名称需要唯一,每条shovel定义如下:
sources、destination和queue必需,其余都可以默认
配置示例:
其中,broker配置URI。若源或目标是集群,可以使用brokers,内容为列表,如
{brokers,["amqp://root:root@192.168.0.2:5672","amqp://root:root@192.168.0.3:5672"]}
当一个节点故障时,可以转移到另一个节点上
声明declarations是可选的
queue表示源端的队列名称,可以设置为<<>>表示匿名队列,队列名称由MQ自动生成
prefetch_count表示Shovel内部缓存的消息条数
ack_mode表示在完成转发时的确认模式,有no_ack、on_publish、on_confirm。官方推荐on_confirm,即使用publisher confirm机制,收到目的端的消息确认后,再向源发送消息确认
publish_properties消息发往目的端时需要特别设置的属性列表。默认被转发的消息的各属性是被保留的,此处设置的值会覆盖原来的值。属性列表有:content_type、content_encoding、headers、delivery_mode、priority、correlation_id、reply_to、expiration、message_id、timestamp、type、user_id、app_id、cluster_id
add_forward_headers若设置为true,会在转发的消息内添加x-shovelled的header属性
publish_fields定义消息发往目的端交换器的路由键。若交换器和路由键没有定义,则Shovel会从原始消息上复制
reconnect_delay在连接失效后,重建连接前的等待时间,单位为秒,若设置为0,则不重连,默认为5秒


3-3-2、动态方式
动态配置的信息会存入Mnesia数据库中
Shovel仅在一端启用即可
#源192.168.158.100,目的192.168.158.139,源queue:queue1,目的交换器:
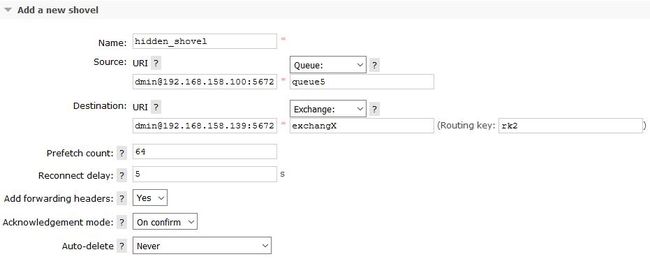
方式一:rabbitmqctl set_parameter shovel hidden_shovel '{"src-uri":"amqp://admin:admin@192.168.158.100:5672","src-queue":"queue1","dest-uri":"amqp://admin:admin@192.168.158.139:5672","src-exchange-key":"rk2","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}'
方式二:curl -i -u admin:admin -XPUT -d'{"value":{"src-uri":"amqp://admin:admin@192.168.158.100:5672","src-queue":"queue1","dest-uri":"amqp://admin:admin@192.168.158.139:5672","src-exchange-key":"rk2","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}}' http://192.168.158.139:15672/api/parameters/shovel/%2F/hidden_shovel
方式三:Web界面
查看状态
rabbitmqctl eval 'rabbit_shovel_status:status().'
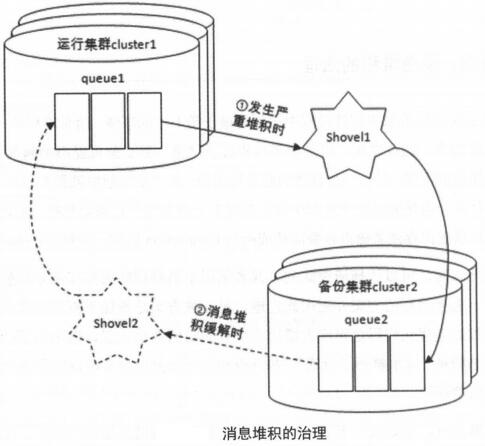
3-3-3、案例:消息堆积的治理
单个队列中堆积10万条消息不会有丝毫影响,但超过1千万时,将引起严重问题,如内存、磁盘告警、connection阻塞等
可以使用Shovel,当某个队列消息堆积严重时,可以使用Shovel将队列中消息移交给另一个集群
1、当检测到集群cluster1中队列queue1中有严重消息堆积,如通过/api/queues/vhost/name获取消息个数messages超过2千万或者消息占用大小messages_bytes超过10GB时,启用shovel1将queue1中消息转发至备份集群cluster2中队列queue2
2、当检测到queue1中消息个数低于1百万或者消息大小低于1GB时,停止shovel1,让原本队列消化剩余堆积
3、当检测到queue1消息个数低于10万个或占用大小低于100MB时,开启shovel2将queue2队列中暂存的消息返还队列queue1
4、当检测到queue1消息个数超过1百万,或消息占用高于1GB时,将shovel2停掉
记录于:朱忠华的《RabbitMQ实战指南》