企业级内部日志分析系统ELK+kafka+filebeat介绍
一、ELK介绍
ELK由ElasticSearch、Logstash和Kibana三个开源工具组成:

1、ElasticSearch:
ElasticSearch是一个基于Lucene的开源分布式搜索服务。只搜索和分析日志
特点:分布式,零配置,自动发现,索引自动分片,索引副本机制等。它提供了一个分布式多用户能力的全文搜索引擎。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
在elasticsearch中,所有节点的数据是均等的。
索引:
索引(库)–>类型(表)–>文档(记录)
ES特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
Elasticsearch核心概念
1)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置来决定的,对于中小型企业刚开始集群就一个节点很正常
2)Node:节点,集群中的一个节点,节点也要一个名称(默认是随机分配的),节点的名称很重要(在执行运维管理的时候),默认的节点会加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个“elasticsearch”的集群,当然一个节点也可以组成一个集群。
3)Document:文档,ES中最小的数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中都可以存储多个document
4)Index:索引,包含一堆相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。
5)Type:类型,每个索引里面都可以有一个或多个type,type是index的一个逻辑数据分类,一个type下的document有相同的filed。比如博客系统,有一个索引,一个用户数据type,博客数据type,评论数据type。
7)shard:单机服务器无法存储大量数据,ES可以将一个索引中的数据分割为多个shard,分布在多台机器上存储,有了shard就可以横向扩展,存储更多的数据,让搜索和分析操作分布到多台机器上执行,提高吞吐量和性能。
8)replica:任何一个服务器都会出现故障,此时shard可能会丢失,因此为每个shard建立多个replica副本,replica可以在shard故障时候提供备用服务。
2、logstash
日志加工、搬运工
(1) Logstash是一个完全开源工具,可以对你的日志进行收集、过滤、分析,并将其存储供以后使用(如,搜索),logstash带有一个web界面,搜索和展示所有日志。 **只收集和过滤日志,和改格式
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
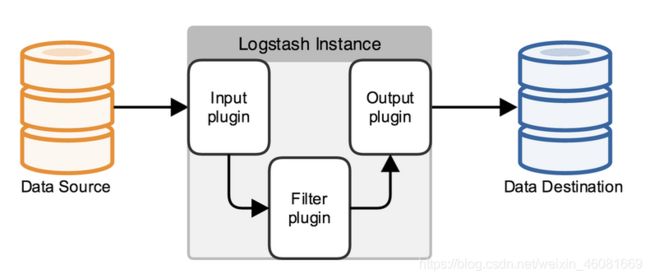
(2)Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
logstash整个工作流分为三个阶段:输入、过滤、输出。每个阶段都有强大的插件提供支持:
Input (必须),设置数据来源
Filter(可选),负责数据处理与转换
output(必须),负责数据输出
3、kibana
Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮你汇总、分析和搜索重要数据日志。
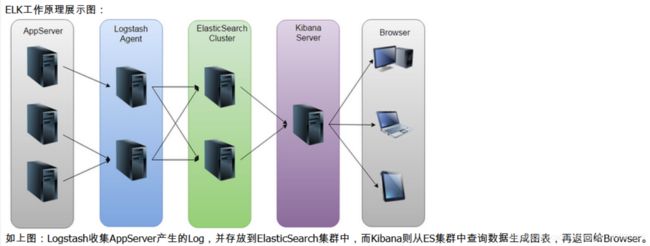
二、Kafka
数据缓冲队列。同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka的特性:
-
高吞吐量:kafka每秒可以处理几十万条消息。
-
可扩展性:kafka集群支持热扩展- 持久性、
-
可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
-
高并发:支持数千个客户端同时读写
它主要包括以下组件
话题(Topic):是特定类型的消息流。(每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的) 生产者(Producer):是能够发布消息到话题的任何对象(发布消息到 kafka 集群的终端或服务). 消费者(Consumer):可以订阅一个或多个话题,从而消费这些已发布的消息。 服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。 partition(区):每个 topic 包含一个或多个 partition。 replication:partition 的副本,保障 partition 的高可用。 leader:replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 follower:replica 中的一个角色,从 leader 中复制数据。 zookeeper:kafka 通过 zookeeper 来存储集群的 信息。
zookeeper:
ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括:配置维护、分布式同步等。Kafka的运行依赖ZooKeeper。
ZooKeeper用于分布式系统的协调,Kafka使用ZooKeeper也是基于相同的原因。ZooKeeper主要用来协调Kafka的各个broker,不仅可以实现broker的负载均衡,而且当增加了broker或者某个broker故障了,ZooKeeper将会通知生产者和消费者,这样可以保证整个系统正常运转。
在Kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况与消费者当前消费的状态信息都会保存在ZooKeeper中。
架构
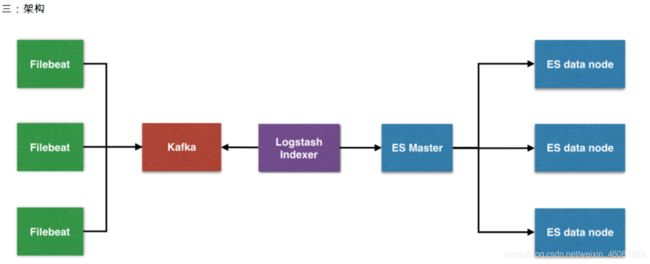
三、filebeat
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具:
- 1.Packetbeat(搜集网络流量数据)
- 2.Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。)
- 3.Filebeat(搜集文件数据)
- 4.Winlogbeat(搜集 Windows 日志数据)f
filebeat 需要部署在每台应用服务器上