Win10基于python,spleeter 人声提取工具安装和使用(全网最全,超详细)
Win10基于python,spleeter 音频分轨工具安装和使用(全网最全,超详细)
- 小声BB(不想看可直接跳到正片)
- 碎碎念(写给小白)
- 正片开始
-
- 说明
- 总体的框架
- 详细步骤
-
- 1.安装python,配置环境变量,安装pip
- 2.安装spleeter库
- 3.安装ffmpeg库
- 4.下载预测模型
- 5.开始尝试使用spleeter
小声BB(不想看可直接跳到正片)
Hello,这里是努力写出让大多数人都能很容易懂的而且有用的文章的小筱。
事情是这样的,制作某个视频的时候需要用到人声提取技术,然后在B站发现了一个python的库spleeter可以实现上述需求,内心:这也太香了吧。于是上手开始搞,途中遇到一些问题,找了很多教程,多次尝试,一直出现问题,最后综合多篇文章,意外摸索到解决办法,感觉网上没有哪一篇文是整理得比较完整而且详细的,因此打算写这一篇文。第一次写,写得不好,请多担待。
(一开始没打算写文章,所以记录的错误的截图较少,而且不能一一对应问题的解决,以后我处理问题的时候可能会多记录一下,方便写文)
遇到过的错误,比如这样的:
![]()
还有比如这样的:
could not chdir to ‘2stems’
碎碎念(写给小白)
遇到困难不要怕,微笑着面对它!!!新手配置软件的时候,总会怂的一批,而且会遇到各种问题,各种报错各种惊悚红字,这是很正常的,不要恐惧。遇到问题就解决问题呗,善用百度、谷歌查报错的错误,指不定就会看到相关的问题的解决,即使没有完整的文章,也会找到很多相关的,多参考几篇,多尝试,问题就解决了。
正片开始
说明
1.本人的系统是win10 64位,不确定其他的版本的系统是否会有差异
2.各位按需求食用,因为每个人目前所处的安装步骤位置不一样
3.尽可能记住自己下载和安装的路径,保证自己需要什么都能找到就行
4.如果其中某个步骤失败,请重复操作三次(重新手动输入,别复制粘贴),查看自己命令有无输错字符,还是有问题的话,可以在评论区找我
总体的框架
1.安装python,配置环境变量,安装pip
2.安装库:spleeter
3.安装库:ffmpeg,添加环境变量
4.下载预测模型
5.开始尝试使用spleeter
详细步骤
1.安装python,配置环境变量,安装pip
(如果看不懂以下我说的东西,直接去看那个视频教程,就知道我在说什么了)
见B站同济子豪兄的视频:一劳永逸安装和配置python3.7(这是我见过的最好、最小白的安装python教程)。
视频链接:一劳永逸安装和配置python3.7
视频分为两部分,一部分是python安装,一部分是pip的使用,按自己需求拉进度条观看,其中关于镜像,建议设置一个永久的镜像,比如清华镜像之类的,以后需要安装任何库就只需要pip install 库名,这样以后每次安装库,就不需要每次都写镜像地址了,非常方便(不要太香好嘛!!!)
2.安装spleeter库
保证上述安装完成后,现在就可以安装库啦
提醒,一定要把pip更新到最新版本,否则后续安装可能会报错
如过看过步骤1的话,就知道老规矩,在桌面左下角的输入框输入,cmd,然后回车,打开命令提示符(比较熟悉这个的,麻烦忽略我的傻瓜式教学截图)
进入后就会出现这个小黑框啦

保证这个时候你是有联网的,然后输入:
python -m pip install --upgrade pip
然后回车,这个命令的功能是更新pip到最新版本,等待成功了以后回车,再输入:
pip install spleeter
然后同样回车,这个命令的功能是下载spleeter库,
回车以后,就会开始下载spleeter库了,需要一定时间,不会很久,等它下载完成
3.安装ffmpeg库
这个步骤呢,其实我找的很多教程里都没有这个步骤,但是因为我在安完spleeter的时候,就直接按照教程,直接使用spleeter了,但是报错了,我找了很多篇文章都没有安装ffmpeg这个过程,最后我在知乎上,看到一篇文章有这个步骤,然后我亲测了,确实需要这一步,否则会报错。这个不需要加速器,国内可以直接下载,很快。
下载地址是这个:下载ffmpeg的官网链接
【注意!!!】 评论区有人反馈我这个链接进去以后看到的不是我这个样子了,我后面查了一下,在贴吧看到有人说那个网站的老哥2020年9月18日跑路了,我这篇博客发的时间是2020年9月17日,真的就巧了。现在官网上面那个我也不知道怎么下,但是我重新测试了一下,我之前安好的环境,依旧可以用,所以我把我之前在那个网站下好资源分享在这了,自己取:
百度网盘链接:ffmpeg win10 x64 版 百度网盘资源
提取码:2s88
进去以后如图操作:
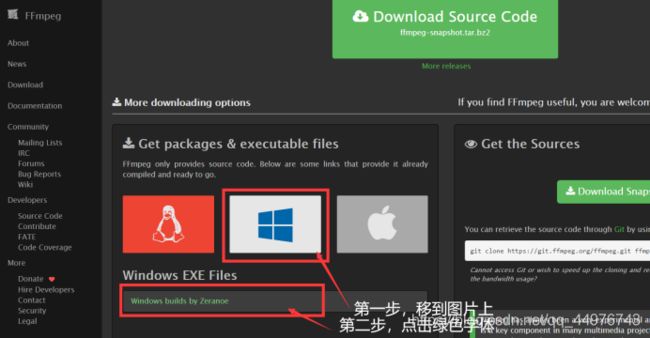
之后会跳转到另一个界面:
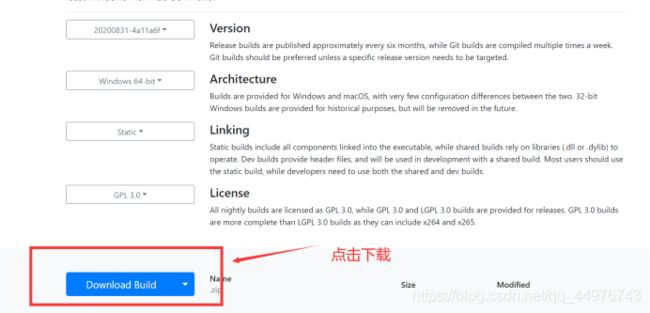
下载成功后,浏览器下方会有显示
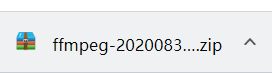
此时,右击,点击在文件夹中显示,就能找到它在文件夹中的位置,这是一个压缩包,此时需要将它解压,解压成一个文件夹。 !!!千万别点上面那个解压到当前文件夹!!!
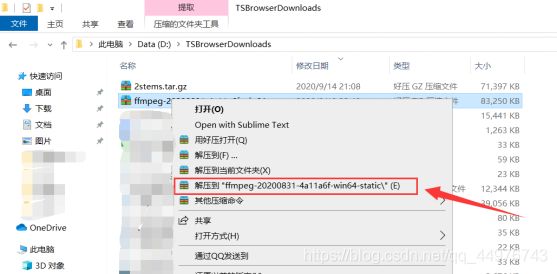
解压完成:
![]()
然后就是添加环境变量了,进入上图文件夹的bin
如图操作
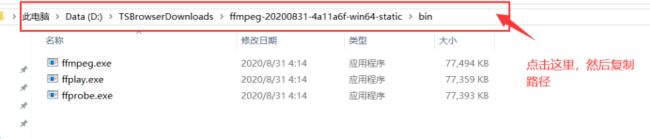
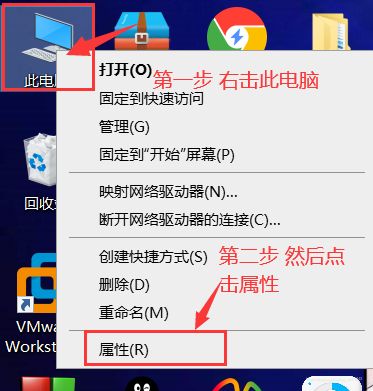
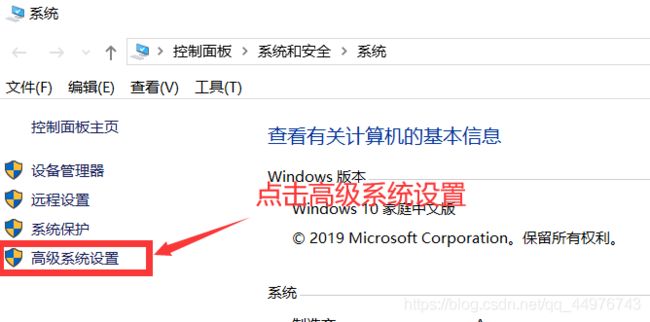
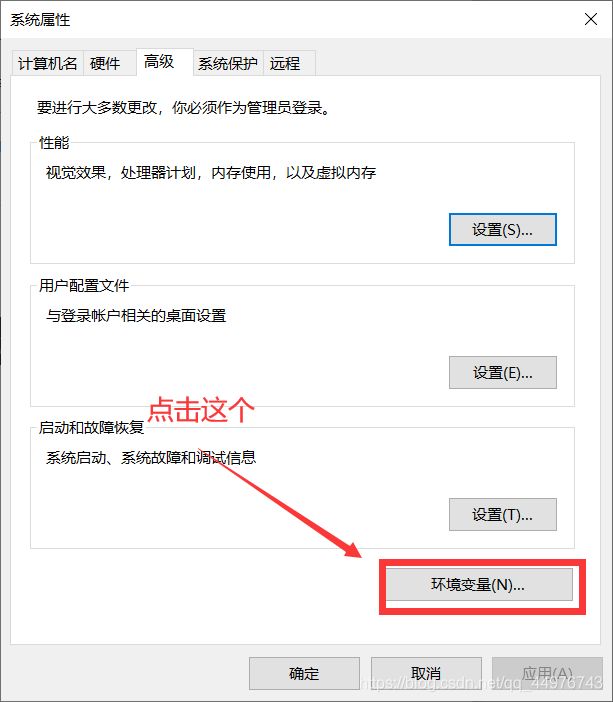
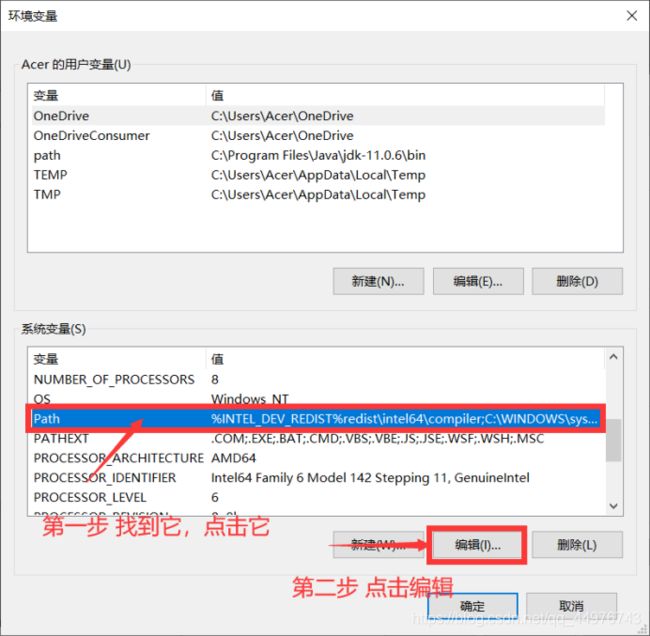
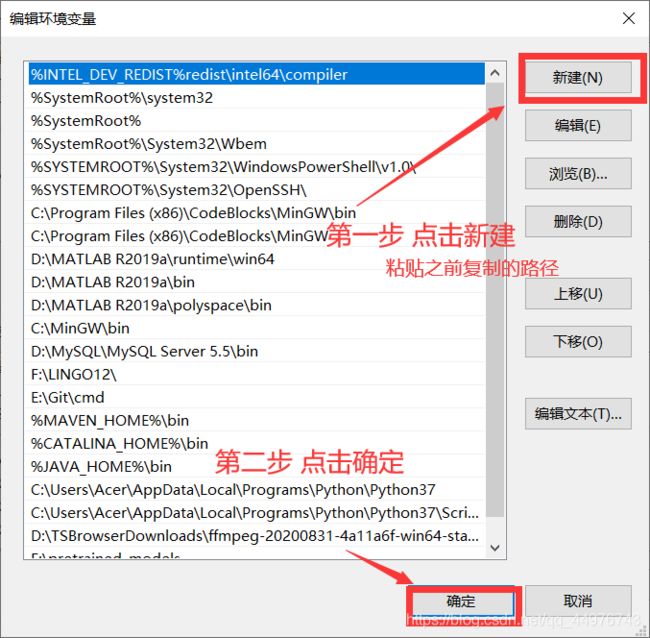
这样就成功添加环境变量了。
然后回到我们的命令行(小黑框)
老规矩输入:pip install ffmpeg
然后回车,等待安装成功(我印象中是有pip install ffmpeg这步的,但是看很多教程都没有说到这个,所以我不是很确定到底有没有,反正试一试嘛,除了这一步,其他步骤我印象中都是有的)
检验安装ffmpeg是否成功的方式:
在命令行输入:ffmpeg
如果有类似下图的内容,即为安装成功
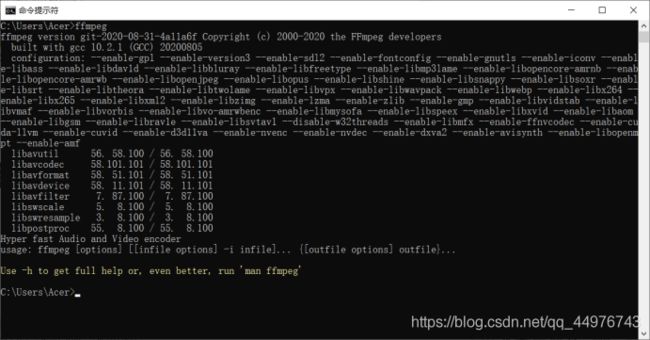
4.下载预测模型
然后就是下载预测模型了,在GitHub上,国内网下载超级慢,想直接在网站上下载的话,需要开加速器(fan qiang)。不想自己从那个网站上下载的话,看我放的网盘链接,放的我之前已经下好的东西,不过只有2stems,不全,其他的还有4stems,5tems(其实就是一个拆分出来声道的问题,2stems拆出来就只有背景音和人声,其他的我没用过,个人估计就是能拆分更细的分层次的不同的背景音吧。比如有一些电影的声道就是5.1声道的,5.1声道是指中央声道,前置左、右声道,后置左、右环绕声道,及所谓的0.1声道重低音声道,这种你在pr中使用的时候会发现它所有的音效是单独分开的,可以单独使用,而且很纯净,原始无损,不需要人为用软件去处理音频就可以拿到最纯净的人声)
下载的链接1:github上,下载预测模型
网盘链接:百度网盘下载预测模型stem2
网盘提取码:uot4
(!!!禁止在线解压,文件会损坏,别人就提取不了了,麻烦把压缩包下载到自己电脑以后再解压!!!)
如果是在Github下载的就是这样:
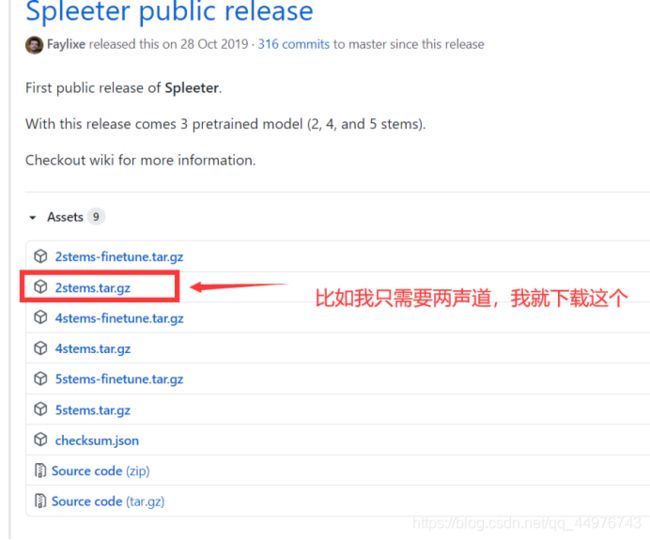
下载完成后,就是这样一个压缩包:
![]()
然后在C盘acer的文件夹里

找到这个文件夹
新建文件夹,命名为pretrained_models
将之前下载的2stems.tar.gz压缩包复制一份到这个文件夹下,
解压成文件夹,与之前类似
![]()
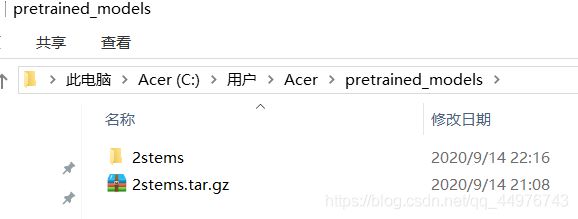
现在的目录情况就是这样的
–pretrained_models
-----2stems
-----2stems.tar.gz
5.开始尝试使用spleeter
然后就可以开始尝试使用了
这里建议在某个盘的根目录里新建一个全英文的文件夹(尽量不要出现中文或者特殊符号,因为这样它有可能会找不到路径,会报错)用于存放你将要处理的MP3或者wav文件,其次你本身要处理的文件的名字也应该是全英文,理由同上
最后就是开始使用了,在命令行中输入:
Python -m spleeter separate - i 你要处理的文件的绝对路径 -p spleeter:2stems -o 你要获得的结果文件的路径
然后回车
!!!
注意:
1.尽可能不要出现中文,否则很可能报错,我写的“你要处理的文件的绝对路径”这里要换成你自己的文件的路径,后面的“你要获得的结果文件的路径”同理,
2.尽可能用绝对路径
3.注意空格
4.示例图片里我写的longkuisovle.mp3其实是错的,输出来的是一个文件夹,所以直接写路径文件夹名字就好了,不需要加任何后缀。
然后很快看到successfully就说明提取人声成功了,可以去之前写的那个路径下看成果了
![]()
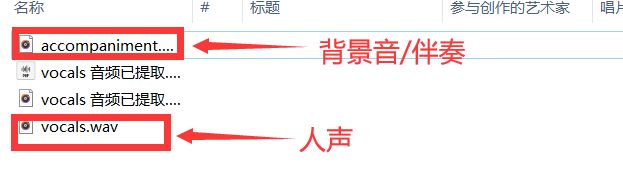
补充:
输入文件名、输出文件名不可以带空格,否则会导致找不到文件,就像这样
![]()
![]()
完结!感谢观看!如果有帮助,麻烦点个赞,如果看到哪里陈述有错误,欢迎在评论区指出,可以相互讨论(๑•̀ㅂ•́)و✧