基于图片分割的Canny边缘检测算法优化方案(可重构计算大作业)
源代码下载地址
摘要
对于Canny边缘检测算法,本文利用了Vivado HLS对其中耗时较多的循环进行了优化,并且运用了图片分割的思想,将源图片分割成4/8份同时并行运算,以达到利用更多资源换取耗时更短的优化效果,最终实现了Latency的极大提升并且充分利用了HLS所给的资源。很好的解决了算法复杂度过高的问题,基于上述优化思想,小组对源代码进行了较大程度的改写,得到了基于图片规格为512*512的如下优化成果和资源利用率成果。
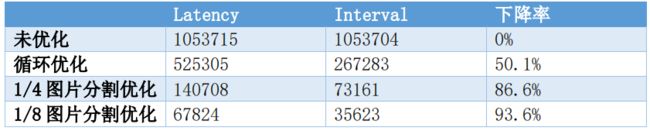

对于上述结果,小组生成了硬件IP,完成了基于ZYNQ开发板的电路搭建,以及对Python测试代码的修改,最终在PYNQ云平台测试成功。
文章目录
- 摘要
- 一、算法描述
-
- 1.1 Sobel滤波
- 1.2 梯度分解
- 1.3 非最大值抑制
- 1.4 hysteresis 滞后
- 二、优化方案
-
- 2.1优化前
- 2.2循环优化
-
- 2.2.1 hysteresis 滞后
- 2.2.2 nonmax_suppression 非最大值抑制
- 2.2.3 gradient_decomposition(梯度分解)
- 2.2.4 canny_edge数据读写部
- 2.2.5 循环优化成果
- 2.3 1/4图片分割优化
-
- 2.3.1 瓶颈
- 2.3.2 并行计算思想
- 2.3.3 代码层面的并行修改方案
- 2.3.4 图片分割(1/4)优化成果
- 2.4 1/8图片分割优化
-
- 2.4.1 图片分割(1/8)优化成果
- 2.5 优化结果对比分析
- 三、PYNQ云平台测试
-
- 3.1 各部件连线图
- 3.2 Python代码修改
- 3.3 平台测试结果
- 四、心得体会
-
- 4.1组员一心得:
- 4.2组员二心得:
- 4.3组员三心得:
- 五、参考文献
一、算法描述
1.1 Sobel滤波
Sobel算子用了一个3*3的滤波器来对图像进行滤波从而得到梯度图像纵向算子,提取图像水平边缘:
横向算子,提取图像竖直边缘:

用滤波器与图像进行卷积即可。例如,对于原图的灰度图如下

纵向特征提取:

横向梯度提取:

1.2 梯度分解
将梯度方向量化成四个方向。1.3 非最大值抑制
给出一张图片和上面许多物体检测的候选框(即每个框可能都代表某种物体),但是这些框很可能有互相重叠的部分,我们要做的就是只保留最优的框。 例如,在人脸识别算法中:
已经识别出了 5 个候选框,但是我们只需要最后保留两个人脸。

1.4 hysteresis 滞后
通过非极大值抑制后,仍然有很多的可能边缘点,进一步的设置一个双阈值,即低阈值(low)、高阈值(high),有如下判断条件:
1、某一像素的灰度值超过high 阈值, 该像素被保留为边缘像素。
2、某一像素的灰度值小于low 阈值, 该像素被排除。
3、如果某一像素的灰度值在两个阈值之间,该像素仅仅在连接到一个高于high阈值的像素时被保留。
二、优化方案
2.1优化前
为了得到可视化的Latency和资源利用信息,我们将图片规格定为512*512(即lena图片大小)用如下代码进行限定:
assert(rows=512);assert(cols=512);
优化前的Latency信息:

查看详细Latency信息:

由于Sobel滤波和Duplicate均调用了hls的库函数,我们无法对其进一步优化,但是其余部分(上图红色框出部分)可以进行优化。
优化前的资源利用信息:

我们发现资源利用率极低,可以进行较大程度的优化以利用资源提升速度。
2.2循环优化
2.2.1 hysteresis 滞后
有如下二重循环:
![]()
对其进行禁止展开,然后进行流水处理的优化,其中流水线添加enable_flush它实现了一个管道,如果在管道输入时有效的数据不活动,该管道将刷新并清空。rewind它支持倒绕或连续循环流水线,在一个循环迭代结束和下一个迭代开始之间没有停顿。
最终优化指令如下:
#pragma HLS LOOP_FLATTEN OFF
#pragma HLS DEPENDENCE array inter false
#pragma HLS PIPELINE enable_flush rewind
优化后该函数Latency:

该函数的Latency相比于优化前的![]() 性能提升了74.8%
性能提升了74.8%
2.2.2 nonmax_suppression 非最大值抑制
有如下二重循环:
![]()
与上面一样,对其中的二重循环进行禁止展开,然后进行流水处理的优化,其中流水线添加enable_flush它实现了一个管道,如果在管道输入时有效的数据不活动,该管道将刷新并清空。rewind它支持倒绕或连续循环流水线,在一个循环迭代结束和下一个迭代开始之间没有停顿。
最终优化指令如下:
#pragma HLS LOOP_FLATTEN OFF
#pragma HLS DEPENDENCE array inter false
#pragma HLS PIPELINE enable_flush rewind
优化后该函数的Latency:
![]()
该函数的Latency相比于优化前的![]() 性能提升了66.5%
性能提升了66.5%
2.2.3 gradient_decomposition(梯度分解)
有如下二重循环:
![]()
与前面两个也一样,对其中的二重循环进行禁止展开,然后进行流水处理的优化,其中流水线添加enable_flush它实现了一个管道,如果在管道输入时有效的数据不活动,该管道将刷新并清空。rewind它支持倒绕或连续循环流水线,在一个循环迭代结束和下一个迭代开始之间没有停顿。
最终优化指令如下:
#pragma HLS PIPELINE enable_flush rewind
#pragma HLS LOOP_FLATTEN OFF
#pragma HLS DEPENDENCE array inter false
优化后该函数的Latency:
![]()
该函数的Latency相比于优化前的![]() 性能提升了66.4%
性能提升了66.4%
2.2.4 canny_edge数据读写部
发现top-function中的数据读写部分有两个循环,我们对其进行优化:
![]()
![]()
我们对其做流水线优化:
添加流水线指令:
#pragma HLS PIPELINE enable_flush rewind
优化结果:

![]()
此处Latency对于优化前![]() 性能提升了20.0%
性能提升了20.0%
2.2.5 循环优化成果
在经过上述对循环优化后,我们得到了如下Latency结果:
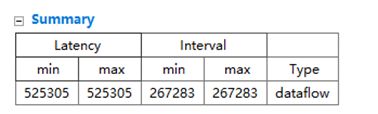
得到了如下资源利用成果:

小组对此结果并不满意,我们可以发现,上述资源利用率是非常低的,可以把剩下的资源尽可能地都利用起来,以达到进一步的优化效果。于是小组在此基础上探索新的优化方式。
2.3 1/4图片分割优化
2.3.1 瓶颈
结束了循环优化,我们尝试了很多种优化方案,包括在所有函数中进行inline优化,但是时钟无法使得Latency有再有较大的提升,因为循环优化结束后的各项Latency如下:
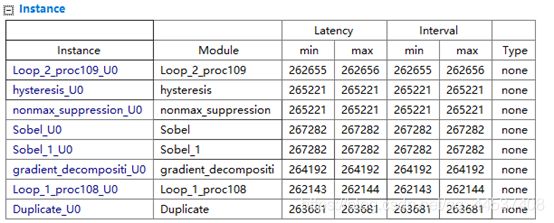
我们发现基本上所有函数的Latency都趋近与26万了,由于Sobel滤波和Duplicate都是调用了内部函数,而其Latency一开始就固定到26万了,再进行其他优化也无法减少总的Latency。
那么还有什么方案可以进一步产生巨大优化呢?
2.3.2 并行计算思想
观察我们的资源利用:

资源利用是很少的,还有很大的优化空间。
那么什么方案能充分利用资源呢?
此时我们想到了并行计算的思想,我们计划将图片分割成四部分同时跑这个算法。
分割详情如下:

2.3.3 代码层面的并行修改方案
修改原有的代码:(完整代码请看源文件)
额外增加3个输入端口:
void canny_edge(wide_stream* in_stream1, wide_stream* out_stream1,
wide_stream* in_stream2, wide_stream* out_stream2,
wide_stream* in_stream3, wide_stream* out_stream3,
wide_stream* in_stream4, wide_stream* out_stream4,
ap_uint<32> rows, ap_uint<32> cols, int threshold1, int threshold2)
#pragma HLS INTERFACE axis port=in_stream1 bundle=INPUT
#pragma HLS INTERFACE axis port=out_stream1 bundle=OUTPUT
#pragma HLS INTERFACE axis port=in_stream2 bundle=INPUT
#pragma HLS INTERFACE axis port=out_stream2 bundle=OUTPUT
#pragma HLS INTERFACE axis port=in_stream3 bundle=INPUT
#pragma HLS INTERFACE axis port=out_stream3 bundle=OUTPUT
#pragma HLS INTERFACE axis port=in_stream4 bundle=INPUT
#pragma HLS INTERFACE axis port=out_stream4 bundle=OUTPUT
各类资源也增加三倍:
如:
GRAY_IMAGE src_bw1(rows, cols);
GRAY_IMAGE src_bw2(rows, cols);
GRAY_IMAGE src_bw3(rows, cols);
GRAY_IMAGE src_bw4(rows, cols);
写入和读出的代码也应增加三倍:
如:
for(int r = 0; r < packets; r++){
#pragma HLS PIPELINE enable_flush rewind
ap_uint<32> dat1 = in_stream1->data;
src_bw1.write(GRAY_PIXEL(dat1.range(7,0)));
src_bw1.write(GRAY_PIXEL(dat1.range(15,8)));
src_bw1.write(GRAY_PIXEL(dat1.range(23,16)));
src_bw1.write(GRAY_PIXEL(dat1.range(31,24)));
++in_stream1;
ap_uint<32> dat2 = in_stream2->data;
src_bw2.write(GRAY_PIXEL(dat2.range(7,0)));
src_bw2.write(GRAY_PIXEL(dat2.range(15,8)));
src_bw2.write(GRAY_PIXEL(dat2.range(23,16)));
src_bw2.write(GRAY_PIXEL(dat2.range(31,24)));
++in_stream2;
ap_uint<32> dat3 = in_stream3->data;
src_bw3.write(GRAY_PIXEL(dat3.range(7,0)));
src_bw3.write(GRAY_PIXEL(dat3.range(15,8)));
src_bw3.write(GRAY_PIXEL(dat3.range(23,16)));
src_bw3.write(GRAY_PIXEL(dat3.range(31,24)));
++in_stream3;
ap_uint<32> dat4 = in_stream4->data;
src_bw4.write(GRAY_PIXEL(dat4.range(7,0)));
src_bw4.write(GRAY_PIXEL(dat4.range(15,8)));
src_bw4.write(GRAY_PIXEL(dat4.range(23,16)));
src_bw4.write(GRAY_PIXEL(dat4.range(31,24)));
++in_stream4;
}
部分操作的调用也增加三倍:
如:
hls::Duplicate( src_bw1, src11, src12 );
hls::Duplicate( src_bw2, src21, src22 );
hls::Duplicate( src_bw3, src31, src32 );
hls::Duplicate( src_bw4, src41, src42 );
2.3.4 图片分割(1/4)优化成果
在经过一系列调试和代码修改后,按照一张图片分割成4部分,我们得到了如下Latency结果:

得到了如下资源利用成果:

可以发现,Latency相比于前面的循环优化后的53万有极大的缩减,变成了现在的14万,此结果得力于四部分并行优化。当然,我们也消耗了更多的资源,
其中LUT我们的使用率达到了55%
但是,当我们看到了这样的资源利用,我们发现仍存在一定的优化空间,还可以进一步利用资源,那么能不能将图片进一步分割呢?
2.4 1/8图片分割优化
2.4.1 图片分割(1/8)优化成果
按照上面代码修改方案,进一步改进,我们把一张图片分成了八份并行运算
分割方式如下:

得到如下Latency结果:

得到了如下资源利用成果:

2.5 优化结果对比分析
经过上述优化我们得到了如下Latency结果对比:

得到了如下资源利用率对比:

结果分析:
在循环优化的基础上进行越精细的图片分割的代码级并行优化可以实现Latency的极大提升,同时又充分利用了给的资源。同时,可以发现,当进行1/8分割后,资源LUT的利用率已经达到93%,所以无法再进行进一步分割了。
三、PYNQ云平台测试
声明:由于电路复杂性,这里以1/4图片分割优化结果为例。
3.1 各部件连线图
由于增加了3个输入输出端口,连线比较复杂:

3.2 Python代码修改
由于多了3个输入端口,我们对Python测试代码也要进行修改:
(只粘贴部分,完整代码请参考源文件)
增加声明的dma数量:
dma1 = CannyEdge_design.axi_dma_0
dma2 = CannyEdge_design.axi_dma_1
dma3 = CannyEdge_design.axi_dma_2
dma4 = CannyEdge_design.axi_dma_3
增加输入输出流:
in_buffer1 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
out_buffer1 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
in_buffer2 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
out_buffer2 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
in_buffer3 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
out_buffer3 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
in_buffer4 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
out_buffer4 = xlnk.cma_array(shape=(256, 256), dtype=np.uint8)
拷贝修改:
np.copyto(in_buffer1,input_array[0:256,0:256])
np.copyto(in_buffer2,input_array[256:512,256:512])
np.copyto(in_buffer3,input_array[0:256,256:512])
np.copyto(in_buffer4,input_array[256:512,0:256])
#in_buffer.nbytes = input_array.nbytes
buf_image1 = Image.fromarray(in_buffer1)
buf_image2 = Image.fromarray(in_buffer2)
buf_image3 = Image.fromarray(in_buffer3)
buf_image4 = Image.fromarray(in_buffer4)
数据传输:
dma1.sendchannel.transfer(in_buffer1)
dma1.recvchannel.transfer(out_buffer1)
dma2.sendchannel.transfer(in_buffer2)
dma2.recvchannel.transfer(out_buffer2)
dma3.sendchannel.transfer(in_buffer3)
dma3.recvchannel.transfer(out_buffer3)
dma4.sendchannel.transfer(in_buffer4)
dma4.recvchannel.transfer(out_buffer4)
3.3 平台测试结果
由于我们用的是512*512的图片格式进行优化的,所以测试我们就用lena
我们分四份输入输出:
输入:


输出:


最后我们用Python把四部分图片拼接到一起:

测试结果分析:
利用python将图片分为四份分别输入主函数的四个端口,成功的得到了边缘分割后的各部分图像,用python将四部分拼接在一起,得到完整的图像。此次优化成功。
但是,可能是python图像拼接函数的问题,无法将四张图像严丝合缝地拼接在一起,这一点尚有遗憾。
四、心得体会
4.1组员一心得:
实验方面:
这次的优化实验可以说是非常考验我的自主学习和思维拓展能力的,其实一开始做这个优化是很迷茫的,发现优化上限是二重循环数据量512*512≈26万,发现对所有循环加上pipeline基本就可以达到这个极限了,加上可能是数据写入和计算不能并行处理的缘故,那么Latency极限就是52万左右。
后来听了老师上课讲的可以通过分割图片的方法,思路一下子就拓展了,然后进行了代码的修改和器件连接的修改,最终把一开始的105万Latency优化到了6万,也充分利用了给的资源。
所以,在这次实验中,我学到了在遇到瓶颈的时候要懂得寻找新方法。
课程方面:
对于可重构计算这门课程的理解,我个人觉得这是我们目前为止,或者说是本科阶段,学得最靠近计算机科学前言的东西了,是非常贴近实际的,而正是因为它贴近实际这一特点,往往一些问题没有特定的答案,这就要利用我们自身的思考去解决实际问题了。当然,在本学期的可重构计算这门课程中,我也学到了很多关于FPGA的知识,还有基础的神经网络知识,通过一次次的实验,让我学到了如何制作,或者说是进行一次FPGA的算法优化。
4.2组员二心得:
对图像处理的边缘检测算法、Sobel滤波、梯度分解、非最大值抑制有了一定的了解。
循环优化是以往实验做过的,但结合了图片分割思想后优化效果有了显著提升。提醒我们不要囿于固有的思路,在想法上能够大胆创新。
4.3组员三心得:
通过查阅资料和阅读代码学习了canny图像边缘检测算法,了解到这是一种非常优秀的边缘检测算法,拓宽了对于算法学习的视野;经过添加各类优化指令来尝试对程序的加速,提高了自己对各种优化指令的理解,也清楚了各种类型优化指令对于性能的提升效果;遇到优化瓶颈后也思考了很多,也一度很茫然,不过在听了老师课上的讲的图片分割方法后,一位队友就根据这个方法尝试了图片分割,最后在我们已有优化的基础上又提升了好几倍,我们对于优化也有了更进一步的认识,不能困在一种思维方式下,解决问题的角度可以有很多种。
对于可重构的理解:
因为计算机的架构对于其处理能力有着至关重要的影响,不会存在一种对所有运算任务都是最优解的计算机架构。可重构就是一种灵活的架构来解决不同任务有其最合适架构的问题,可重构计算有硬件设计可基于软件设计的灵活性,并且运算能力和功耗也都有很大的改进。就像比较简单的pipeline循环优化,按照原来的硬件结构,在for循环中,只有在完成一个循环后才能开始下一个循环,但是加入了pipeline循环优化指令后,这两个循环就可以并行计算,提高运行速度。
五、参考文献
[1]rrr2.HLS for 循环优化其他方法[EB/OL].https://blog.csdn.net/qq_35608277/article/details/104650513,2020-03-04.
[2]许进进.边缘检测算法 之 Canny边缘检测算法的实现[EB/OL].https://blog.csdn.net/LucasXu01/article/details/90764559,2019-06-04.
[3]豆沙粽子好吃嘛!.xilinx 暑期学校学习笔记(Day 6) Vitis及PYNQ-Z2上的Canny边缘提取[EB/OL].https://blog.csdn.net/kzz6991/article/details/107580643,2020-07-25.
[4]jzj1993.Xilinx Vivado的使用详细介绍(1):创建工程、编写代码、行为仿真、Testbench[EB/OL].https://blog.csdn.net/jzj1993/article/details/45533729,2015-05-06.
[5]谭检成,吴定 祥,李明鑫 ,等.基于 Vivado HLS 的 Canny 算法实时加速设计[J].嵌入式技术,2018,44(9):59-62.
源代码下载地址