计算机网络(五)应用层(DNS、文件传送协议、HTTP)
域名系统DNS
互联网的域名系统DNS被设计成 一个联机分布式数据库,采用客户服务器方式。DNS使大多数名字都在本地进行解析,仅少量解析需要在互联网上通信(由于分布式设计,单个计算机故障并不影响整个DNS系统的运作)
域名到IP地址的解析由分布在互联网上的域名服务器程晓旭共同完成。
解析步骤如下:1.应用进程调用解析程序,成为DNS的一个客户,把待解析的域名放在DNS请求报文中,以UDP数据报的方式发送给本地域名服务器。
2.得到请求后的服务器将IP地址放在报文中返回,应用进程在获取IP地址后继续通讯。
3.若本地服务器不能应答,此域名服务器会暂时成为另一个DNS的客户,向其发送查询请求直至查到为止。
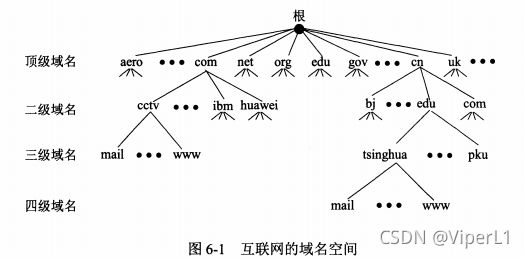
互联网的域名结构

DNS规定,每个标号不超过63个字符,不区分大小写,多个标号组成的完整域名至多不超过255个字符。(域名只是逻辑概念,并不代表计算机所在的物理)
顶级域名分三大类:
1.国家顶级域名nTLD:cn-中国,us-美国,uk-英国...
2.通用顶级域名gTLD:com-公司企业,net-网络服务机构,org-非盈利组织,int-国际组织,edu-教育机构,gov-政府部门,mil-军事部门...
3.基础结构域名:arpa(用于反向域名解析,又称为反向域名)
二级域名(中国)
1.类别域名:ac-科研机构,com-企业,edu-教育机构,gov-政府,mil-国防机构,net-网络提供机构,org-非盈利机构
2.行政区域名:bj-北京市,js-江苏省
所有我国互联网发展的现状和规定都可以在中国互联网信息中心CNNIC找到
域名服务器
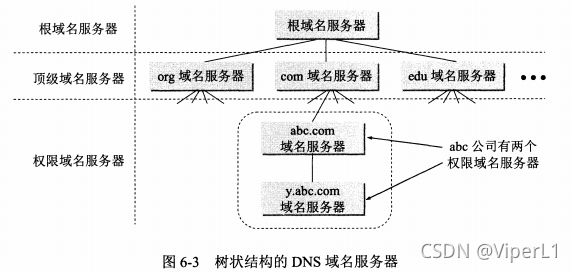
根域名服务器:知道所有顶级域名服务器的域名和IP地址,任何无法解析的域名都可以请求根域名服务器,域名为:a.rootservers.net--m.rootservers.net(全世界域名服务器仅有13个域名,但并不是只有13台根域名服务器)
顶级域名服务器(TLD):负责管理顶级域名服务器注册的所有二级域名
权限域名服务器:负责一个区的域名解析(区中的结点必须相互连通)
本地域名服务器:此级别不属于图6-3的结构,这种域名服务器也被成为默认域名服务器。
为提高可靠性,域名服务器一般会把数据复制到几个域名来保存,其中一个是主域名服务器,其他的是辅助域名服务器。
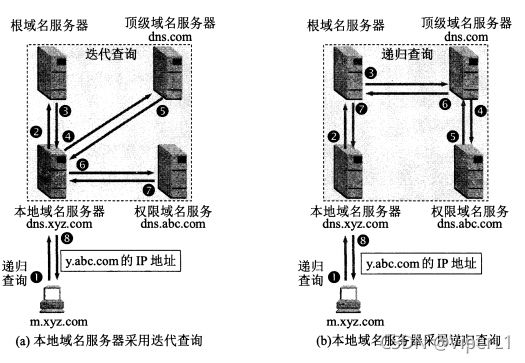
主机向本地域名服务器的域名查询一般采用递归查询
本地域名服务器向根域名服务器查询通常采用迭代查询
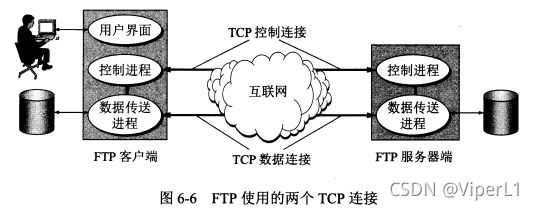
文件传送协议
FTP协议(基于TCP)
FTP之提供文件传送的一些基础功能,它使用TCP可靠的运输服务。FT[的主要功能是减少或消除在不同操作系统下处理文件的不兼容性。
FTP的服务器进程分为两种:主进程(负责接受新的请求),从属进程(若干,负责单个请求)
主进程的工作步骤如下:
1.打开熟知端口(21),使客户进程能够连接
2.等待客户进程的连接请求
3.启动从属进程处理客户进程发送的请求,从属进程对客户进程的请求处理完毕后即终止,但从属进程在运行期间根据需求可能创建一些子进程
4.回到等待状态,继续接受其他客户进程发送的请求,主进程和从属进程是并发的
FTP工作时需要建立两个TCP连接:
1.控制链接
2.数据连接(传输文件)
简单文件传送协议TFTP
优点: 1.可用于UDP环境
2.TFTP代码占用的内存较小
特点: 1.每次传送的数据报文中只有512字节数据(最后一次可以不足512字节)
2.数据报文按序编号,从1开始
3.支持ASCII码或二进制传送
4.可对文件进行读或写
5.使用很简单的首部
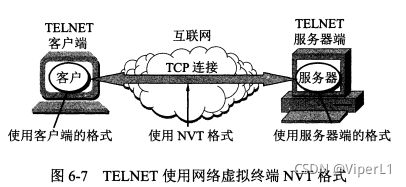
远程终端协议TELNET(远程控制协议)
基于TCP,又称终端仿真协议
万维网WWW
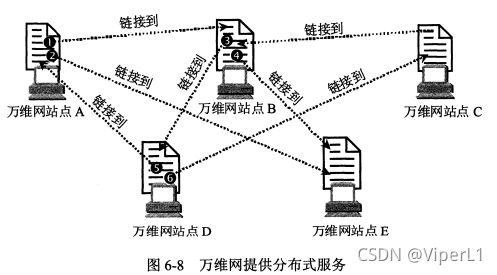
万维网是一个大规模的、联机式的信息储藏所(分布式)
统一资源定位符URL
URL用来表示从互联网上获得的资源位置和访问这些资源的方法,URL给资源位置提供一种抽象的标识方法。
URL相当于一个文件名在网络范围的扩展
![]()
协议:使用何种协议获取该万维网文档,一般是http,其次是ftp
主机:指出此文档在那台主机上
端口和路径有时可以省略
使用HTTP的URL
![]()
HTTP的默认端口号为80,可以省略,若再省略<路径>选项,URL就指向互联网上某个主页。
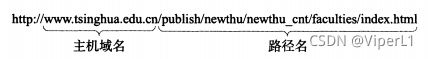
超文本传送协议HTTP
HTTP的操作过程
HTTP是面向事务的应用层协议,它是万维网上能可靠的交换文件的重要基础。
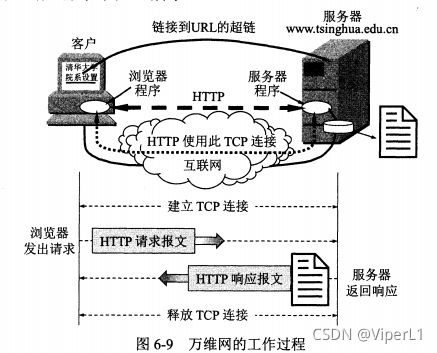
HTTP基于TCP协议,网点会有一个服务器进程监听80端口,客户端和服务器建立联系后HTTP页面的交互都通过此TCP进行传输,直至TCP连接被释放
HTTP使用了TCP来保证数据的可靠传输。HTTP不必考虑数据在传输过程中丢失,但是HTTP协议本身是无连接的(在双方交换HTTP报文之间,并不需要建立HTTP连接)
HTTP是无状态的,服务器并不会记录客户端的访问数据

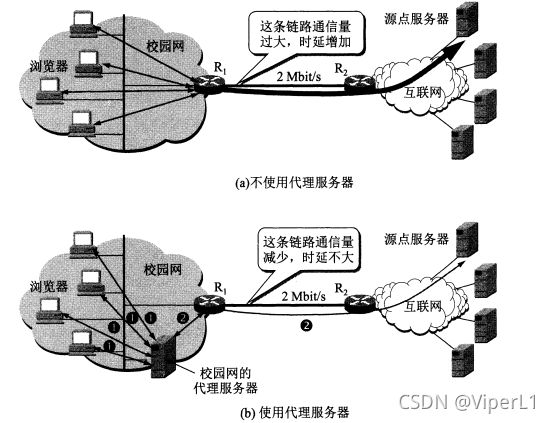
代理服务器
代理服务器将最近的一些请求和响应暂存在本地服务器,又称万维网高速缓存。
HTTP的报文格式

HTTP的报文分两类:请求报文、响应报文
HTTP是面向文本的,报文中每个字段都是一些ASCII码串,每段的长度都是不确定的
开始行:用于区分报文类型(请求还是响应)
首部行:说明给浏览器、服务器或一些报文主体的信息
实体主体:请求报文一般不实用这个字段,而响应报文中也可能没有这个字段
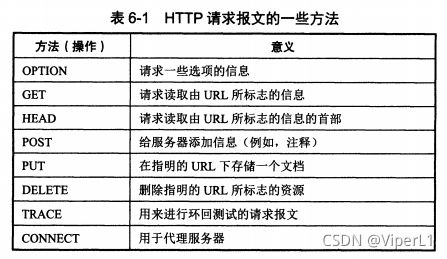
请求报文的“请求行”(第一行)仅有三个内容:方法,请求资源的URL,以及HTTP版本

在服务器上存放用户信息(Cookie)
在用户A浏览网页时,网站服务器为A生成一个唯一识别码,当收到A的响应时,浏览器会在它管理的特定Cookie文件中添加一行(包括服务器主机名和Set-Cookie的识别码),每次提交申请的时候,浏览器会从Cookie文件中取出这个网站的识别码添加刀HTTP报文的Cookie首部中。
于是网站就可以追踪用户A在该网站的活动了,服务器并不需要知道这个用户的真实信息