Tensorboard可视化神经网络详细教程
Tensorboard可视化神经网络详细教程
前言: tensorboard是一个非常强大的工具、不仅仅可以帮助我们可视化神经网络训练过程中的各种参数,而且可以帮助我们更好的调整网络模型、网络参数,这一块类容后面会讲到,不管是tensorflow、keras、还是pytorch,tensorboard都提供了非常好的支持,本文是系列文章的第一篇,详细介绍基于keras+tensorboard如何来进行网络的可视化。写这篇文章的初衷很简单,网上很多方面类似的文章,但是我还没有找到一篇真正满意的,很多都是互相转载,很多要么是太过简单,不具备什么参考价值,本文会由浅入深的来说明。
一、keras是如何使用tensorboard的
keras使用tensorboard是通过回调函数来实现的,关于什么是keras的“回调函数”,这里就不再赘述了,所以Tensorboard也是定义在keras.callbacks模块中的,通过构造一个Tensorboard类的对象,然后在训练的时候在fit里面指定callbacks参数即可,keras使用的一般格式为:
# 构造一个Tensorboard类的对象
tbCallBack = TensorBoard(log_dir="./model")
# 在fit 里面指定callbacks参数
history=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2, validation_split=0.2,callbacks=[tbCallBack])
但是Tensorboard远远不止这么简单,它的参数众多,每一个参数都代表不同的含义。下面将分别来介绍。
在介绍之前,先来说一下本文的案例,本文以手写字识别为案例,搭建的模型如下所示:
model = Sequential()
model.add(Conv2D(32, (5,5), activation='relu', input_shape=[28, 28, 1])) #第一卷积层
model.add(Conv2D(64, (5,5), activation='relu')) #第二卷积层
model.add(MaxPool2D(pool_size=(2,2))) #池化层
model.add(Flatten()) #平铺层
model.add(Dropout(0.5)) #dropout层
model.add(Dense(128, activation='relu')) #Dense层
model.add(Dropout(0.5)) #dropout层
model.add(Dense(10, activation='softmax')) #Dense层
二、Tensorboard类详解
该类在keras.callbacks模块中。它的参数列表如下:
log_dir: 用来保存被 TensorBoard 分析的日志文件的文件名。
histogram_freq: 对于模型中各个层计算激活值和模型权重直方图的频率(训练轮数中)。 如果设置成 0 ,直方图不会被计算。对于直方图可视化的验证数据(或分离数据)一定要明确的指出。
write_graph: 是否在 TensorBoard 中可视化图像。 如果 write_graph 被设置为 True。
write_grads: 是否在 TensorBoard 中可视化梯度值直方图。 histogram_freq 必须要大于 0 。
batch_size: 用以直方图计算的传入神经元网络输入批的大小。
write_images: 是否在 TensorBoard 中将模型权重以图片可视化,如果设置为True,日志文件会变得非常大。
embeddings_freq: 被选中的嵌入层会被保存的频率(在训练轮中)。
embeddings_layer_names: 一个列表,会被监测层的名字。 如果是 None 或空列表,那么所有的嵌入层都会被监测。
embeddings_metadata: 一个字典,对应层的名字到保存有这个嵌入层元数据文件的名字。 查看 详情 关于元数据的数据格式。 以防同样的元数据被用于所用的嵌入层,字符串可以被传入。
embeddings_data: 要嵌入在 embeddings_layer_names 指定的层的数据。 Numpy 数组(如果模型有单个输入)或 Numpy 数组列表(如果模型有多个输入)。 Learn ore about embeddings。
update_freq: 'batch' 或 'epoch' 或 整数。当使用 'batch' 时,在每个 batch 之后将损失和评估值写入到 TensorBoard 中。同样的情况应用到 'epoch' 中。如果使用整数,例如 10000,这个回调会在每 10000 个样本之后将损失和评估值写入到 TensorBoard 中。注意,频繁地写入到 TensorBoard 会减缓你的训练。
注意的是:该部分来自官方文档,有几个地方说得不是很清楚,所以后面我会逐一介绍。红色的是本文会详细讲到的,黑色的是涉及到嵌入层相关的,本文暂且略过。
这些参数的默认值如下所示:
log_dir='./logs', # 默认保存在当前文件夹下的logs文件夹之下
histogram_freq=0,
batch_size=32,
write_graph=True, #默认是True,默认是显示graph的。
write_grads=False,
write_images=False,
embeddings_freq=0,
embeddings_layer_names=None,
embeddings_metadata=None,
embeddings_data=None,
update_freq='epoch' #默认是“epoch”,这个是很好理解的,这与训练集与验证集的loss、acc曲线相关
2.1 最简单的Tensorboard类的构造对象(log_dir,write_graph,update_freq三个参数)
本文以手写字识别为例,因为网络的搭建过程很简单,这里就不给出全部代码了,占地方,只讨论与tensorboard相关的。
最简单的tensorboard对象是不传递任何参数,只是用默认的设定值:如下:
tbCallBack = TensorBoard()
history=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2, validation_split=0.2,callbacks=[tbCallBack])
这样通过谷歌浏览器启动tensorboard程序,得到如下的结果:
(1)tensorboard面板中只有scalers和graph两个面板。graph面板是通过默认的write_graph=True来设置的;
(2)scalers面板中默认给出的是训练数据的loss和accuracy、以及验证集上的loss和accuracy(如果有验证集的话,没有则没有)。本例子训练了10个epochs,而且update_freq=“epoch”,是默认值,得到如下所示:
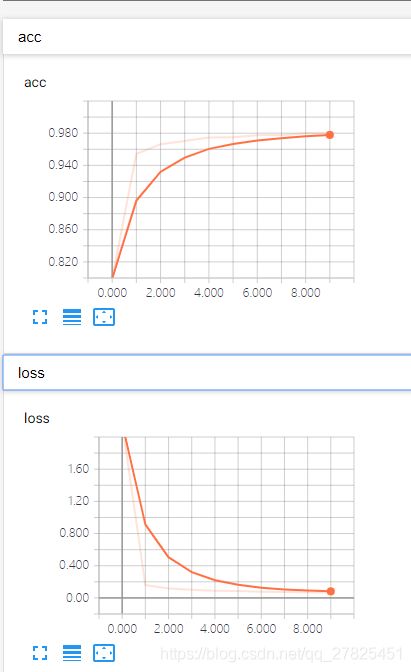
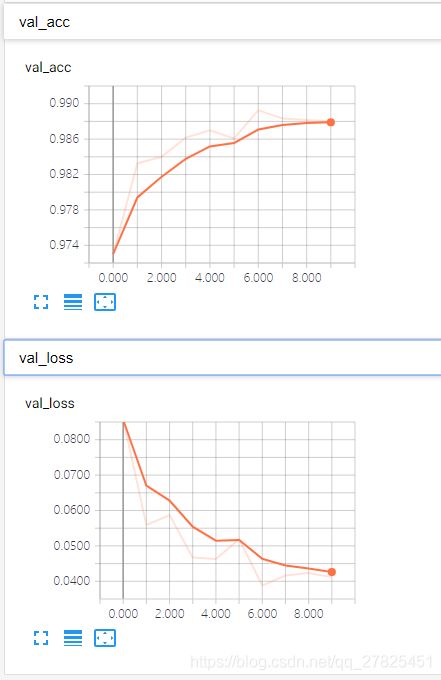
总结:默认的Tensorboard类回调只会显示graph图像和几个训练的scalers,而且日志文件并不是很大,本文中例子只有301K。
2.2 histogram_freq参数
tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1)
'''
该参数用于设置tensorboard面板中的histograms和distributions面板,默认是0,即不显示,设置为大于01的数,本例设置为1,则显示这两个面板。
'''
设置了histogram_freq参数之后,则会显示histograms和distributions面板这两个面板,需要注意的是:
keras中没一个卷积层、全连接层都会默认有权值矩阵,称之为kernel,默认有偏置项bias,所以在这两个面板中会有kernel和bias这两个图形。
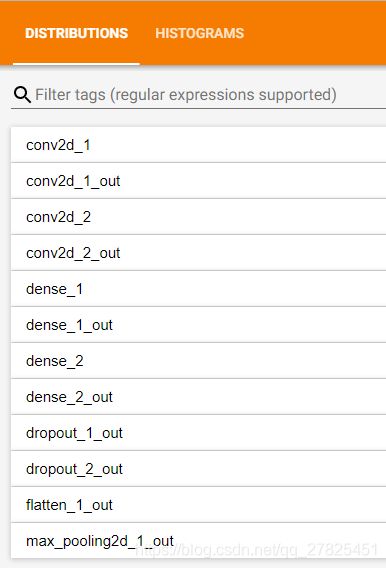
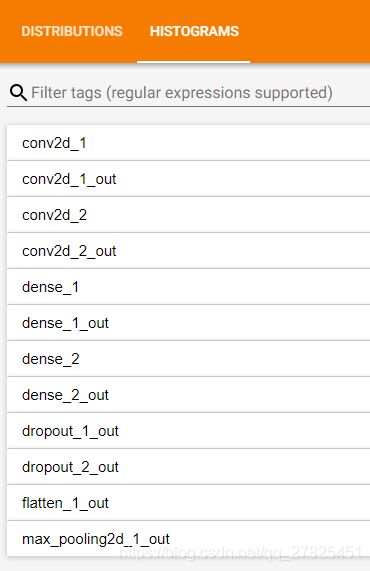
上面是收缩了的面板,我们发现所有的层都会显示出来的,本例中的两个卷积层、两个全连接层、两个dropout层、一个flatten层、一个maxpooling层都显示出来了,但是顺序不是模型中的顺序,会发生变化,是按照英文字母的顺序显示。不仅如此,对于每一个层的输出数据也会被统计出来,对应于上面那些以“out”结尾的名称,表示的是输出。对于像conv卷积层和dense这样的全连接层,除了本身的权阵kernel、偏置项bias外,还有他们的输出,但是像dropout、maxpooling、flatten这样的层本身没有kernel和bias,只有输出,所以只显示输出的统计数据,同样是以“out”结尾。
注意:本例中每一个层使用的是默认名称,在实际项目里面为了更加清晰的查看,我们最好是自己给每一个层自定义一个名字。
那么如何查看histograms和distributions面板这两个面板的图标呢?这其实是一个很基础的问题,这里通过一个例子来说明吧。、
为什么histograms和distributions面板是相伴而生的,主要是因为它们其实是同一批数据统计分布的“不同视角”呈现的结果,怎么理解?看下图,以第一个卷积层为例conv2d_1.
先看histograms:
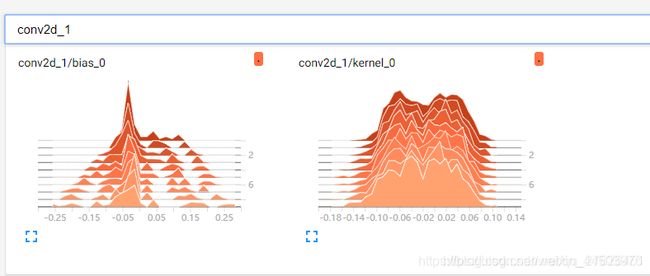
histogram本质上就是在没一个epoch上,权重数据kernel和偏执数据bias的统计分布图,看起来很清楚,可以非常方便的看到在每一个epoch,数据的分布变化状况。
再看一下distributions:
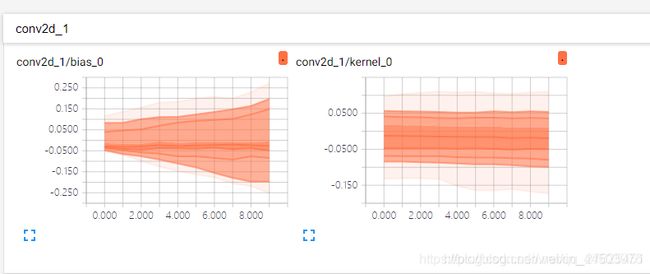
仔细分析其实可以发现,distributions其实就是histograms的一个“俯视图”,因为histograms中图像是三维的,所以可以更直观的看起来哪一个范围内的分布更多(即峰值更高),那distributions中变为了一个平面图是不是就不能看了呢?当然不是,依然可以,它可以通过颜色的深浅来看峰值,比如上面两图中,在histograms中的bias图中,峰值集中在-0.05附近,我们看下面的distributions中的bias,发现-0.05附近的颜色更深,其实这就是对应的峰值。其实右边的图也是一样的分析。
总结:histogram_freq参数会在面板中添加histograms面板和distributions面板,会将每一个层的权值、偏置、输出值的统计分布以不同的视觉角度显示出来,因为权重等信息的存在,现在日志文件变为了111M,增大了很多。
2.3 write_grads参数(默认为False)
将梯度信息也在distributions面板和histograms面板中显示出来,因此它需要依赖 histogram_freq参数,只有当histogram_freq参数大于0(即设置的前提下),然后设置write_grads=True参数才有意义,如下:
tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1,write_grads=True)
'''
将梯度信息也在distributions面板和histograms面板中显示出来,因此它需要依赖 histogram_freq参数,只有当histogram_freq参数大于0(即设置的前提下),然后设置write_grads=True参数才有意义
'''
现在那些可以求梯度的层将会增加梯度的统计过分布信息,包括卷积层conv、全连接层dense等,但是像dropout、flatten、maxpooling层本身没有求梯度,所以相比与之前没什么变化。
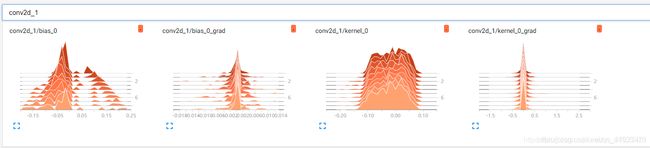
上图是第一个卷积层,增加了对权值kernel和偏置bias的梯度统计分布信息。
总结:将梯度信息也在distributions面板和histograms面板中显示出来,因此它需要依赖 histogram_freq参数,只有当histogram_freq参数大于0(即设置的前提下),然后设置write_grads=True参数才有意义,由于添加了梯度数据,现在的日志文件更大了,达到了221M。
2.4 write_images参数(默认为False)
这个参数将那些具有权值kernel和偏置bias的层(如卷积层conv和全连接层dense)的kernel和bias用图片的形式展示出来,所以由于flatten、maxpooling、dropout是没有kernel和bias的,就没有,设定如下:
tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1,write_images=True)
打开结果如下:
只有两个卷积层,两个全连接层有,因为只有它们有kernel和bias,我们展开一个卷积层查看如下:
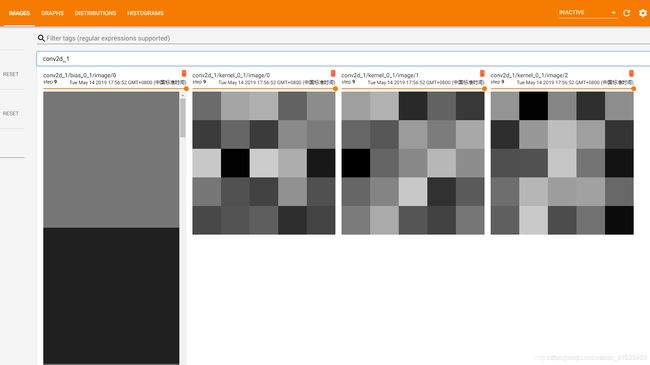
因为我的第一个卷积核是5x5的,所以这里的kernel是5x5的,
总结:write_images参数可以将带有权重kernel和bias的网络层的参数用图片的形式显示出来,但是这样做有一个致命的问题,那就是会导致日志文件增加的很庞大,训练过程也会因为这个操作变得更加缓慢,所以非常的不推荐使用。使用该参数之后,之日文件增加到了2.4G,相较于之前增加了10倍之多,这还仅仅是一个很浅层的网络。所以慎用。
从上面可以看出,直接使用keras的回调函数Tensorboard,可以很方便的实现网络的可视化训练,对于一些参数的调优是有帮助的,而且这样的操作更加简单直观,使用起来很方便,当然我完全可以自己定制更加功能强大的实现,这是后面的文章会说到的。
三、该案例的全部代码如下
import numpy as np
from keras.models import Sequential # 采用贯序模型
from keras.layers import Input, Dense, Dropout, Activation,Conv2D,MaxPool2D,Flatten
from keras.optimizers import SGD
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.callbacks import TensorBoard
def create_model():
model = Sequential()
model.add(Conv2D(32, (5,5), activation='relu', input_shape=[28, 28, 1])) #第一卷积层
model.add(Conv2D(64, (5,5), activation='relu')) #第二卷积层
model.add(MaxPool2D(pool_size=(2,2))) #池化层
model.add(Flatten()) #平铺层
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def compile_model(model):
#sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
model.compile(loss='categorical_crossentropy', optimizer="adam",metrics=['acc'])
return model
def train_model(model,x_train,y_train,batch_size=128,epochs=10):
#构造一个tensorboard类的对象
#tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1, write_graph=True, write_images=True,update_freq="epoch")
tbCallBack = TensorBoard(log_dir="./model", histogram_freq=1,write_grads=True)
history=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2, validation_split=0.2,callbacks=[tbCallBack])
return history,model
if __name__=="__main__":
(x_train,y_train),(x_test,y_test) = mnist.load_data() #mnist的数据我自己已经下载好了的
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test))
x_train=np.expand_dims(x_train,axis=3)
x_test=np.expand_dims(x_test,axis=3)
y_train=to_categorical(y_train,num_classes=10)
y_test=to_categorical(y_test,num_classes=10)
print(np.shape(x_train),np.shape(y_train),np.shape(x_test),np.shape(y_test))
model=create_model()
model=compile_model(model)
history,model=train_model(model,x_train,y_train)