PS:要转载请注明出处,本人版权所有。
PS: 这个只是基于《我自己》的理解,
如果和你的原则及想法相冲突,请谅解,勿喷。
前置说明
本文作为本人csdn blog的主站的备份。(BlogID=112)
环境说明
- Ubuntu 18.04
- MLU270 加速卡一张
前言
阅读本文前,请务必须知以下前置文章概念:
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(一)--- 基本概念及相关介绍》 ( https://blog.csdn.net/u011728480/article/details/121194076 )
前文我们已经介绍一些基本的概念。在本文,将会从安装加速卡,到模型环境移植搭建完成,都会做一个简单的介绍。
若文中引用部分存在侵权,请及时联系我删除。
安装MLU270加速卡到主机
首先MLU270加速卡你可以直接把他看为一张普通的独立显卡就行。只需要安装在主机的PCIE x16 口即可,并连接好供电线,其供电线是特制的接口,需要官方提供的线缆进行转换一下接口。其官网渲染图如图:

开机后通过查看pcie设备即可发现刚刚安装的设备(lspci命令):

安装驱动
根据其官网资料( https://www.cambricon.com/docs/driver/index.html ),我简要说明部分内容。
首先根据其资料,我们可以看到大概支持两个系列的os,一个是ubuntu/debian,一个是centos。这里,我建议使用ubuntu,具体原因,有兴趣的可以去查看此文档的注意部分。
在Ubuntu18.04上安装驱动
首先从你的供应商拿到驱动包,名字如:neuware-mlu270-driver-dkms_xxx_all.deb。然后不用客气,直接执行:sudo dpkg -i neuware-mlu270-driver-dkms_xxx_all.deb。
我们其实可以看到,其用DKMS来管理驱动,和安装N卡驱动非常类似。具体显示信息,请查看如上官网资料。这里只有一个问题要注意,就是内核版本一定要在其文档说明支持的范围内。
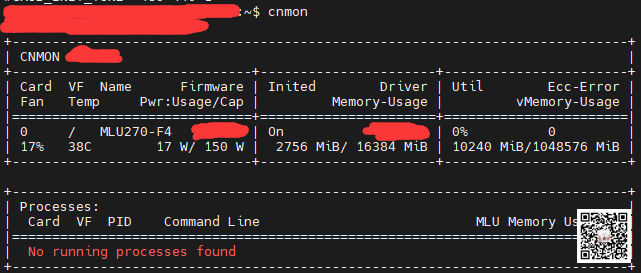
当安装成功后,执行:cnmon,可以看到一个类似nvidia-smi的信息,包含了加速卡的一些基本信息。
安装CNToolKit
其实和我们前置文章里面讲的软件框架部分,当我们准备好驱动之后,其实下一步就是安装运行时层。运行时层就是CNToolKit,里面包含了好几个模块。其具体介绍请查看其官网: https://www.cambricon.com/docs/cntoolkit/index.html 。
在CNToolKit模块里面,我接触的最多的就是CNRT,因为这是离线模型推理部分的底层支持部分。也就是说前文我提到的EasyDK就是大部分基于CNRT进行设计的。
在Ubuntu18.04上安装CNToolKit
官方路子:
- sudo dpkg -i cntoolkit_xxx.deb
- sudo apt update
- sudo apt-get install cnas cncc cncodec cndev cndrv cnlicense cnpapi cnperf cnrt cnrtc cnstudio
野路子:
- 解压cntoolkit_xxx.deb。
- 找到里面的所有deb文件,选择自己需要的,直接解压安装。
注意,野路子在边缘端环境配置的时候、边缘端程序生成的时候有奇效。
配置相关环境变量:
- export NEUWARE_HOME="/usr/local/neuware"
- export PATH="${NEUWARE_HOME}/bin:${PATH}"
注意,此变量NEUWARE_HOME将会伴随着你移植模型,生成边缘端程序等阶段,需要注意。
安装好进行测试,执行命令:/usr/local/neuware/bin/cncc --version 得到如图输出:

配置模型移植开发环境
寒武纪官方支持3种常见框架的模型移植,他们分别是caffe/tensorflow/pytorch,他们的官方资料如下:
- caffe: https://www.cambricon.com/docs/caffe/index.html
- tensorflow: https://www.cambricon.com/docs/tensorflow/user_guide/index.html
- pytorch: https://www.cambricon.com/docs/pytorch/index.html
寒武纪官方支持的环境配置方式有两种,一种是全程手动搭建环境。第二种是docker。
对于手动搭建环境,这里仁者见仁智者见智,我个人认为新手可以尝试着搭建一次就行,后续还是使用docker。因为手动搭建可以让你更加的了解整个移植工作的流程。以pytorch为例,因为手动搭建,大概包含了安装virtualenv,解压源码,设定NEUWARE_HOME环境,打patch,安装依赖,编译编译生成对应的库,运行单元测试,最终检测即可。
对于业务开发来说,我建议还是docker来的快点。
搭建模型移植docker环境
docker的安装我就不说了,自己百度把docker基本环境搭好,能够跑hello-world就行。
首先我们在寒武纪那里可以拿到对应环境的docker镜像,下载到我们的安装了MLU270的主机电脑。然后执行命令: sudo docker load -i pytorch-xxxx-ubuntu18.04.tar,然后执行sudo docker images 查看你已经导入的image文件。如图:

然后执行寒武纪提供的run脚本即可。根据脚本中的配置,默认会将当期目录映射到docker的/home/share目录。
当我们第一次进入一个docker环境时,需要执行寒武纪提供的patch脚本(联系供应商),在docker根目录生成一个env_pytorch.sh文件,配设定相关的环境。
此外,每当我们执行run脚本进入docker后(docker run),每一次都需要执行:cd / && source env_pytorch.sh 进入pytorch虚拟环境。这个时候执行如下命令,并反馈如图:

使用docker还有一个好处是更新升级方便,更重要的是方便建立多个不同算法移植环境。
后记
对于寒武纪加速平台来说,我们不要将它视为一个新的事物,可以将它类比为Nvidia的显卡加速平台。加速卡驱动对应n卡驱动。cncc类比nvcc。bang c类比为cuda。更高级的算法推理和训练框架其实底层加速部分就是使用cuda/bang c/cpu-simd来构建的。对于我们用户来说,一般情况下,我们只需要普通的了解pytorch/tensorflow/caffe的api即可。只有当对某些特殊算子需要加速的时候,这个时候你有可能去涉及这些cuda/bang c/cpu-simd。这里寒武纪加速平台根据其提供的一些资料来看,直接在算子里面集成了例如ssd/yolov3/yolov5等目标检测的最后一个解码层,详情见相关文档。
这里介绍了寒武纪算法移植环境搭建的方法,同时也对整个流程做了一个简要的说明。其实如果你能够和供应商联系上,应该还可以得到一些其他的相关支持和资料。我这里由于一些原因,只引用了其官方公开的内容。
参考文献
- 《寒武纪加速平台(MLU200系列) 摸鱼指南(一)--- 基本概念及相关介绍》 ( https://blog.csdn.net/u011728480/article/details/121194076 )
- https://www.cambricon.com/
- 其他相关保密资料。

PS: 请尊重原创,不喜勿喷。
PS: 要转载请注明出处,本人版权所有。
PS: 有问题请留言,看到后我会第一时间回复。