数据挖掘建模过程全公开

![]()
导读:本文以餐饮行业的数据挖掘应用为例,详细介绍数据挖掘的建模过程。
![]()
数据挖掘的基本任务包括利用分类与预测、聚类分析、关联规则、时序模式、偏差检测、智能推荐等方法,帮助企业提取数据中蕴含的商业价值,提高企业的竞争力。
对餐饮企业而言,数据挖掘的基本任务是从餐饮企业采集各类菜品销量、成本单价、会员消费、促销活动等内部数据,以及天气、节假日、竞争对手及周边商业氛围等外部数据,之后利用数据分析手段,实现菜品智能推荐、促销效果分析、客户价值分析、新店选点优化、热销/滞销菜品分析和销量趋势预测,最后将这些分析结果推送给餐饮企业管理者及有关服务人员,为餐饮企业降低运营成本、提升盈利能力、实现精准营销、策划促销活动等提供智能服务支持。
接下来将以餐饮行业的数据挖掘应用为例,详细介绍数据挖掘的建模过程,如图1所示。
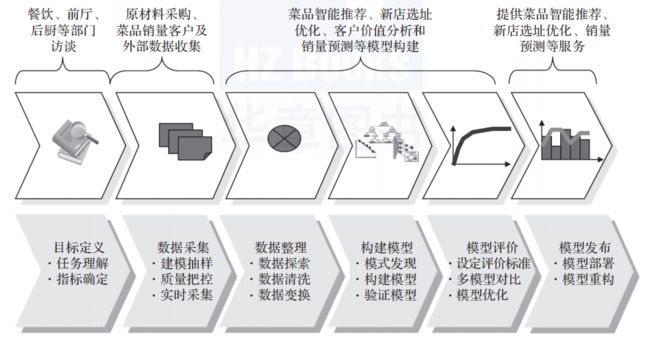
图1 餐饮行业数据挖掘建模过程
01
定义挖掘目标
针对具体的数据挖掘应用需求,首先要明确本次的挖掘目标是什么,系统完成后能达到什么样的效果。因此,我们必须分析应用领域(包括应用中的各种知识和应用目标),了解相关领域的有关情况,熟悉背景知识,弄清用户需求。要想充分发挥数据挖掘的价值,必须要对数据挖掘目标有清晰明确的认识,即决定到底想干什么。
针对餐饮行业的数据挖掘应用,可定义如下挖掘目标:
1)实现动态菜品智能推荐,帮助顾客快速发现自己感兴趣的菜品,同时确保推荐给顾客的菜品也是餐饮企业期望顾客消费的菜品,实现餐饮消费者和餐饮企业的双赢。
2)对餐饮客户进行细分,了解不同客户的贡献度和消费特征,分析哪些客户是最有价值的、哪些是最需要关注的,对不同价值的客户采取不同的营销策略,将有限的资源投放到最有价值的客户身上,实现精准化营销。
3)基于菜品历史销售情况,综合考虑节假日、气候和竞争对手等影响因素,对菜品销量进行趋势预测,方便餐饮企业准备原材料。
4)基于餐饮大数据,优化新店选址,并对新店潜在顾客的口味偏好进行分析,以便及时进行菜式调整。
02
数据取样
在明确了数据挖掘的目标后,接下来就需要从业务系统中抽取一个与挖掘目标相关的样本数据子集。抽取数据的标准:一是相关性,二是可靠性,三是有效性,而不是动用全部企业数据。通过数据样本的精选,不仅能减少数据处理量,节省系统资源,而且使我们想要寻找的规律能更好地突显出来。
进行数据取样,一定要严把质量关。在任何时候都不能忽视数据的质量,即使是从一个数据仓库中进行数据取样,也不要忘记检查数据质量如何。因为数据挖掘是要探索企业运作的内在规律性,原始数据有误,就很难从中探索其规律。若真的从中探索出什么“规律性”,再依此去指导工作,则很可能会对相关决策造成误导。若从正在运行的系统中进行数据取样,更要注意数据的完整性和有效性。
衡量取样数据质量的标准包括:资料完整无缺,各类指标项齐全;数据准确无误,反映的都是正常(而不是异常)状态下的水平。
对获取的数据可再从中作抽样操作。抽样的方式多种多样,常见的方式如下:
1)随机抽样:在采用随机抽样方式时,数据集中的每一组观测值都有相同的被抽取的概率。如按10%的比例对一个数据集进行随机抽样,则每一组观测值都有10%的机会被取到。
2)等距抽样:如果按5%的比例对一个有100组观测值的数据集进行等距抽样,则有个数据被取到,那么等距抽样方式是取第20、40、60、80组这和第100组这5组观测值。
3)分层抽样:在这种抽样操作中,首先将样本总体分成若干层次(或者说分成若干个子集)。每个层次中的观测值都具有相同的被选用的概率,但对不同的层次可设定不同的概率。这样的抽样结果通常具有更好的代表性,进而使模型具有更好的拟合精度。
4)按起始顺序抽样:这种抽样方式是从输入数据集的起始处开始抽样。抽样的数量可以给定一个百分比,或者直接给定选取观测值的组数。
5)分类抽样:在前述几种抽样方式中,并不考虑抽取样本的具体取值。分类抽样则依据某种属性的取值来选择数据子集,如按客户名称分类、按地址区域分类等。分类抽样的选取方式就是前面所述的几种方式,只是抽样以类为单位。
基于前面提到的针对餐饮行业的数据挖掘目标,需从客户关系管理系统、前厅管理系统、后厨管理系统、财务管理系统和物资管理系统中抽取用于建模和分析的餐饮数据,主要包括的内容如下:
餐饮企业信息:名称、位置、规模、联系方式、部门、人员以及角色等。
餐饮客户信息:姓名、联系方式、消费时间、消费金额等。
餐饮企业菜品信息:菜品名称、菜品单价、菜品成本、所属部门等。
菜品销量数据:菜品名称、销售日期、销售金额、销售份数。
原材料供应商资料及商品数据:供应商姓名、联系方式、商品名称、客户评价信息。
促销活动数据:促销日期、促销内容以及促销描述等。
外部数据:如天气、节假日、竞争对手以及周边商业氛围等数据。
03
数据探索
前面所叙述的数据取样,多少带有人们对如何实现数据挖掘目的的先验认识而进行操作的。当我们拿到一个样本数据集后,它是否达到我们原来设想的要求、其中有没有什么明显的规律和趋势、有没有出现从未设想过的数据状态、属性之间有什么相关性、它们可分成怎样的类别……这都是要首先探索的内容。
对所抽取的样本数据进行探索、审核和必要的加工处理,能保证最终的挖掘模型的质量。可以说,挖掘模型的质量不会超过抽取样本的质量。数据探索和预处理的目的是保证样本数据的质量,从而为保证模型质量打下基础。
针对采集的餐饮数据,数据探索主要包括异常值分析、缺失值分析、相关分析、周期性分析等。
04
数据预处理
当采样数据维度过大时,如何进行降维处理、缺失值处理等都是数据预处理要解决的问题。
由于采样数据中常常包含许多含有噪声、不完整甚至不一致的数据,对数据挖掘所涉及的数据对象必须进行预处理。那么如何对数据进行预处理以改善数据质量,并最终达到完善数据挖掘结果的目的呢?
针对采集的餐饮数据,数据预处理主要包括数据筛选、数据变量转换、缺失值处理、坏数据处理、数据标准化、主成分分析、属性选择、数据规约等。
05
挖掘建模
样本抽取完成并经预处理后,接下来要考虑的问题是:本次建模属于数据挖掘应用中的哪类问题(分类、聚类、关联规则、时序模式或智能推荐)?选用哪种算法进行模型构建?
这一步是数据挖掘工作的核心环节。针对餐饮行业的数据挖掘应用,挖掘建模主要包括基于关联规则算法的动态菜品智能推荐、基于聚类算法的餐饮客户价值分析、基于分类与预测算法的菜品销量预测、基于整体优化的新店选址。
以菜品销量预测为例,模型构建是对菜品历史销量,综合考虑节假日、气候和竞争对手等采样数据轨迹的概括,它反映的是采样数据内部结构的一般特征,并与该采样数据的具体结构基本吻合。模型的具体化就是菜品销量预测公式,公式可以产生与观察值有相似结构的输出,这就是预测值。
06
模型评价
从建模过程会得出一系列的分析结果,模型评价的目的之一就是从这些模型中自动找出一个最好的模型,另外就是要根据业务对模型进行解释和应用。
07
常用的数据挖掘建模工具
数据挖掘是一个反复探索的过程,只有将数据挖掘工具提供的技术和实施经验与企业的业务逻辑和需求紧密结合,并在实施过程中不断磨合,才能取得好的效果。下面简单介绍几种常用的数据挖掘建模工具。
(1)SAS Enterprise Miner
Enterprise Miner(EM)是SAS推出的一个集成数据挖掘系统,允许使用和比较不同的技术,同时还集成了复杂的数据库管理软件。它通过在一个工作空间(Workspace)中按照一定的顺序添加各种可以实现不同功能的节点,然后对不同节点进行相应的设置,最后运行整个工作流程(Workflow),便可以得到相应的结果。
(2)IBM SPSS Modeler
IBM SPSS Modeler原名Clementine,2009年被IBM收购后对产品的性能和功能进行了大幅度改进和提升。它封装了最先进的统计学和数据挖掘技术来获得预测知识,并将相应的决策方案部署到现有的业务系统和业务过程中,从而提高企业的效益。IBM SPSS Modeler拥有直观的操作界面、自动化的数据准备和成熟的预测分析模型,结合商业技术可以快速建立预测性模型。
(3)SQL Server
Microsoft的SQL Server集成了数据挖掘组件—Analysis Servers,借助SQL Server的数据库管理功能,可以无缝集成在SQL Server数据库中。SQL Server 2008提供了决策树算法、聚类分析算法、Naive Bayes算法、关联规则算法、时序算法、神经网络算法、线性回归算法等9种常用的数据挖掘算法。但是其预测建模的实现是基于SQL Server平台的,平台移植性相对较差。
(4)Python
Python是一种面向对象的解释型计算机程序设计语言,它拥有高效的高级数据结构,并且能够用简单而又高效的方式进行面向对象编程。但是Python并不提供专门的数据挖掘环境,它提供众多的扩展库,例如,以下3个十分经典的科学计算扩展库:NumPy、SciPy和Matplotlib,它们分别为Python提供了快速数组处理、数值运算以及绘图功能,Scikit-learn库中包含很多分类器的实现以及聚类相关算法。正因为有了这些扩展库,Python才能成为数据挖掘常用的语言,也是比较适合数据挖掘的语言。
(5)WEKA
WEKA(Waikato Environment for Knowledge Analysis)是一款知名度较高的开源机器学习和数据挖掘软件。高级用户可以通过Java编程和命令行来调用其分析组件。同时,WEKA也为普通用户提供了图形化界面,称为WEKA Knowledge Flow Environ-ment和WEKA Explorer,可以实现预处理、分类、聚类、关联规则、文本挖掘、可视化等功能。
(6)KNIME
KNIME(Konstanz Information Miner)是基于Java开发的,可以扩展使用WEKA中的挖掘算法。KNIME采用类似数据流(Data Flow)的方式来建立分析挖掘流程。挖掘流程由一系列功能节点组成,每个节点有输入/输出端口,用于接收数据或模型、导出结果。
(7)RapidMiner
RapidMiner也叫YALE(Yet Another Learning Environment),提供图形化界面,采用类似Windows资源管理器中的树状结构来组织分析组件,树上每个节点表示不同的运算符(Operator)。YALE提供了大量的运算符,包括数据处理、变换、探索、建模、评估等各个环节。YALE是用Java开发的,基于WEKA来构建,可以调用WEKA中的各种分析组件。RapidMiner有拓展的套件Radoop,可以和Hadoop集成起来,在hadoop集群上运行任务。
(8)TipDM开源数据挖掘建模平台
TipDM数据挖掘建模平台是基于Python引擎、用于数据挖掘建模的开源平台。它采用B/S结构,用户不需要下载客户端,可通过浏览器进行访问。平台支持数据挖掘流程所需的主要过程:数据探索(相关性分析、主成分分析、周期性分析等),数据预处理(特征构造、记录选择、缺失值处理等),构建模型(聚类模型、分类模型、回归模型等),模型评价(R-Squared、混淆矩阵、ROC曲线等)。用户可在没有Python编程基础的情况下,通过拖曳的方式进行操作,将数据输入输出、数据预处理、挖掘建模、模型评估等环节通过流程化的方式进行连接,以达到数据分析挖掘的目的。
本文摘编于《Python数据分析与挖掘实战(第2版)》。
推荐语:畅销书全新升级,第1版销售超过10万册,被国内100余所高等院校采用为教材,同时被广大数据科学工作者奉为经典,是该领域公认的事实标准。


扫码关注【华章计算机】视频号
每天来听华章哥讲书

更多精彩回顾
书讯 | 8月书讯(上)| 这些新书不可错过
书讯 | 8月书讯(下)| 这些新书不可错过
资讯 | Rust跨界前端全攻略
书单 | 2021半年盘点,不想你错过的重磅新书
干货 | Rust跨界前端全攻略
收藏 | 快收藏!!整理了100个Python小技巧!!
上新 | 【新书速递】深入浅出Pandas,用好Python必备

点击阅读全文购买