YOLOV3训练环境的搭建
YOLOV3推理环境搭建参考文章:
Yolov3网络的物体检测_tugouxp的专栏-CSDN博客1.Get darknet 代码$ git clone https://github.com/pjreddie/darknet$ cd darknet$ makecaozilong@caozilong-Vostro-3268:~/yolo$ git clone https://github.com/pjreddie/darknet正克隆到 'darknet'...remote: Enumerating objects: 5937, done.remote: Total 5937 (dehttps://blog.csdn.net/tugouxp/article/details/119297898PC跑跑YOLOV的推理还行,如果要是试图跑模型训练,要求就高了很多,河里没水撑不起大船,训练场景需要较强的算例支持,需要显卡和CUDA环境,关于CUDA环境的安装,可以参考这两篇文章:
FairMOT Cuda环境搭建并进行推理_tugouxp的专栏-CSDN博客环境准备1.PC Host Ubuntu 18.04.6,Linux Kernel 5.4,内核版本关系不大,记录下来备查。2.安装基础工具,比如GCC,CMAKE,VIM,GIT等等,工具尽量完备, 如果做不到,遇到问题临时下载也可。3.安装python3发行版,我用的是anaconda发行版,具体版本是 Anaconda3-2020.11-Linux-x86_64.sh下载地址在如下链接,选择对应的版本即可。https://repo.anaco...https://blog.csdn.net/tugouxp/article/details/121248457Ubuntu18.04安装CUDA深度学习环境_tugouxp的专栏-CSDN博客N卡在深度学习领域具备无可替代的地位,这里记录以下在我这台配备GF MX350 N卡笔记本 上安装cuda以及cuNN的具体步骤。MX350属于低端显卡了,一开始我还担心它会不会不支持CUDA,后面确认了一下,发现可以支持。关于确认N卡是否支持CUDA以及支持版本的具体步骤,可以参考我的这篇博客:如何确定PC Nvidia显卡是否支持CUDA以及cudaNN?过程不难,细节很多,下面记录具体步骤:1.安装显卡驱动:...https://blog.csdn.net/tugouxp/article/details/119829792我的主机环境是Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz和MX250显卡,支持安装CUDA11.5
建立darknet的环境
参考上面的文章,搭建darknet环境,这里需要注意的是darknet使用如下的源
https://github.com/AlexeyAB/darknet本文使用的就是如上的源,便以前记得把CUDA和OPENCV的支持打开,按照上面博客的方法安装OPENCV依赖包:

之后编译darknet项目,并验证YOLOV3推理是否可以成功进行。
下载COCO数据集:
首先将darkent/scripts/get_cocodataset.sh拷贝到darknet/data目录:
![]()
之后,在darknet/data目录执行bash get_coco_dataset.sh,开始下载COCO数据集。
![]()
COCO数据集非常的大,有18G左右,所以不但要求你的磁盘有足够的空间,也要求你有足够的耐心。
下载完成后,脚本会对数据进行解压,最终脚本执行结束之后,在darknet/data目录中,新增加了一个COCO目录,所下载的数据集以及数据及解压后的目录都在这里:

至于数据集的化,则在darknet/data/coco/images目录:

修改darknet/cfg/coco.data,将训练数据集的路径和权重文件的目录设置为正确的路径。

下载预训练权重文件:
wget -c https://pjreddie.com/media/files/darknet53.conv.74
开始训练:
在darknet目录下,执行训练命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
开始训练,遇到如下的错误:

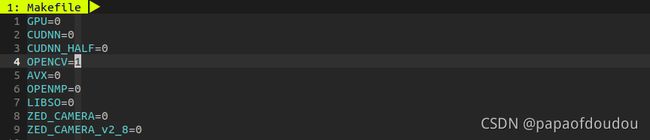
错误原因是我们需要把batch 和subdivisions设置为64,我们按照要求设置,之后再次执行,遇到新的错误:

这条错误怀疑是由于我PC的资源不足以训练yolov3.cfg这个相对复杂的模型,天无绝人之路,看到darknet/cfg目录下还有不少基于YOLOV3改进的模型,我们改用小模型yolov3-tiny.cfg来训练,训练前同样修改yolov3-tiny.cfg的batch 和subdivisions设置为64,此时,darknet目录的状态为:
(base) caozilong@caozilong-RedmiBook-14:~/darknet$ git status
位于分支 master
您的分支与上游分支 'origin/master' 一致。
尚未暂存以备提交的变更:
(使用 "git add <文件>..." 更新要提交的内容)
(使用 "git checkout -- <文件>..." 丢弃工作区的改动)
修改: Makefile
修改: cfg/coco.data
修改: cfg/yolov3-tiny.cfg
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
darknet53.conv.74
predictions.jpg
修改尚未加入提交(使用 "git add" 和/或 "git commit -a")
(base) caozilong@caozilong-RedmiBook-14:~/darknet$ git diff
diff --git a/Makefile b/Makefile
index 431933c..ba48185 100644
--- a/Makefile
+++ b/Makefile
@@ -1,7 +1,7 @@
-GPU=0
+GPU=1
CUDNN=0
CUDNN_HALF=0
-OPENCV=0
+OPENCV=1
AVX=0
OPENMP=0
LIBSO=0
@@ -119,7 +119,7 @@ CFLAGS+= -DGPU
ifeq ($(OS),Darwin) #MAC
LDFLAGS+= -L/usr/local/cuda/lib -lcuda -lcudart -lcublas -lcurand
else
-LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
+LDFLAGS+= -L/usr/local/cuda/lib64 -L/usr/local/cuda-11.5/targets/x86_64-linux/lib/stubs -lcuda -lcudart -lcublas -lcurand
endif
endif
diff --git a/cfg/coco.data b/cfg/coco.data
index 3003841..8cadd38 100644
--- a/cfg/coco.data
+++ b/cfg/coco.data
@@ -1,8 +1,8 @@
classes= 80
-train = /home/pjreddie/data/coco/trainvalno5k.txt
+train = /home/caozilong/darknet/data/coco/trainvalno5k.txt
valid = coco_testdev
#valid = data/coco_val_5k.list
names = data/coco.names
-backup = /home/pjreddie/backup/
+backup = /home/caozilong/backup/
eval=coco
diff --git a/cfg/yolov3-tiny.cfg b/cfg/yolov3-tiny.cfg
index cfca3cf..ad9c505 100644
--- a/cfg/yolov3-tiny.cfg
+++ b/cfg/yolov3-tiny.cfg
@@ -1,7 +1,7 @@
[net]
# Testing
-batch=1
-subdivisions=1
+batch=64
+subdivisions=64
# Training
# batch=64
# subdivisions=2
(base) caozilong@caozilong-RedmiBook-14:~/darknet$
执行训练命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
这次成功执行,训练过程会启动一张坐标图来记录LOSS随着训练迭代次数增加的变化情况,左边的窗口是检测显卡状态用的,这张图是在训练开始后4个小时后截的,可以看到剩余训练时间仍有974个小时,非常的恐怖,我们已经选择的小模型进行训练了,如果训练的是大模型,训练时常可想而知,这也是为什么老黄的N卡能够垄断机器学习的训练领域的原因,他考虑到了高性能计算,并提供了CUDA,CUDANN等工具用于开发高性能计算的产品。
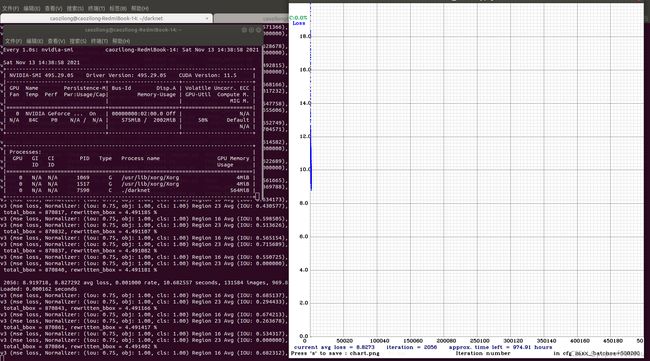
训练过程的动态情况,可以看到训练曲线进行的非常慢,用蜗牛乌龟形容它已经构成对蜗牛和乌龟的诽谤了,非要拿它们哥俩儿作比喻的花,也只能说它们可能是蜗牛世界里的蜗牛里的世界。。。里的蜗牛了,隔着好基层世界呢。
跑15个小时后:

注意:
训练曲线图只有在OPENCV打开的情况下才会出来,如果OPENCV关闭,默认只有训练时控制台的打印输出,不会呼出训练进度曲线图。
backup目录中保存的是不同阶段训练出来的权重文件,训练从一个预训练权重开始初始化网络,之后随着训练进度不断前进,不断产生新的更好的权重数据替换backup目录中的之前的权重文件,通过下图对比可以看到权重文件更新情况:

训练5个小时候,NPU温度已经飙升到90度,笔记本键盘上方5CM内都感觉得到股股热浪袭来,冬天放在房间里活脱脱就是一台取暖器。
看来有必要买台游戏本嫖机器学习了。
训练跑完估计是不可能的了,电脑过了周末就要有它用,当前尽量跑完这个周末,让图像曲线多记录一些,分阶段更新训练曲线~, 就先写到这里。