K8S集群部署kube-Prometheus监控tomcat jvm
K8S集群部署kube-Prometheus监控tomcat jvm
一、背景描述
kube-Prometheus部署在K8S集群中!
kube-prometheus部署参考:K8S集群二进制部署之Prometheus监控告警
现在需要实现kube-prometheus 监控 tomcat jvm
tomcat 部署在 172.16.1.15 服务器上
jdk版本:java version "1.8.0_121
tomcat 版本:Apache Tomcat/8.5.59
二、tomcat环境配置
注:tomcat 安装目录 /usr/local/tomcat
所以以下的操作都是在 /usr/local/tomcat/bin 目录进行
①、下载jmx_exporter
[root@jumpserver01 bin]# pwd
/usr/local/tomcat/bin
[root@jumpserver01 bin]# wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.16.0/jmx_prometheus_javaagent-0.16.0.jar
②、配置jmx_exporter
其实配置的时候,可以很简单的写成下面的格式如下,
#vim /usr/local/prometheus/jmx-exporter.yaml
---
rules:
- pattern: '.*'
不过,个人觉得上面这种配置,可以快速的上手,正式使用的时候,不推荐这样,因为这样会导致prometheus收集的指标太多了,对于存储和网络都会有些许的影响,特别是手机的主机特别多的时候。比较推荐官方给的配置,如下:
#官方推荐配置实例:https://github.com/prometheus/jmx_exporter/blob/master/example_configs/tomcat.yml
#将文件下载下来放到下面文件中/usr/local/tomcat/bin/jmx-exporter.yaml
#cat /usr/local/tomcat/bin/jmx-exporter.yaml
---
lowercaseOutputLabelNames: true
lowercaseOutputName: true
rules:
- pattern: 'Catalina<>(\w+):'
name: tomcat_$3_total
labels:
port: "$2"
protocol: "$1"
help: Tomcat global $3
type: COUNTER
- pattern: 'Catalina<>(requestCount|maxTime|processingTime|errorCount):'
name: tomcat_servlet_$3_total
labels:
module: "$1"
servlet: "$2"
help: Tomcat servlet $3 total
type: COUNTER
- pattern: 'Catalina<>(currentThreadCount|currentThreadsBusy|keepAliveCount|pollerThreadCount|connectionCount):'
name: tomcat_threadpool_$3
labels:
port: "$2"
protocol: "$1"
help: Tomcat threadpool $3
type: GAUGE
- pattern: 'Catalina<>(processingTime|sessionCounter|rejectedSessions|expiredSessions):'
name: tomcat_session_$3_total
labels:
context: "$2"
host: "$1"
help: Tomcat session $3 total
type: COUNTER
③、配置tomcat
添加这一行配置
[root@jumpserver01 bin]# cat setenv.sh
JAVA_OPTS=" -javaagent:/usr/local/tomcat/bin/jmx_prometheus_javaagent-0.16.0.jar=9901:/usr/local/tomcat/bin/jmx-exporter.yaml"
如果是jar包的话添加
java -javaagent:/opt/apps/prometheus/jmx_prometheus_javaagent-0.16.0.jar=9901:/opt/apps/prometheus/jmx-exporter.yaml -jar yourJar.jar
9901为jvm暴露监控数据的接口
启动tomcat 访问接口查看
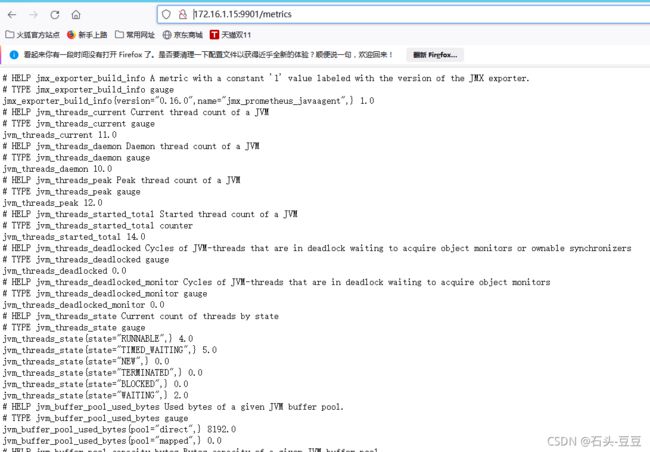
三、prometheus新增targets配置
注:因为监控的tomcat 是K8S集群外部署的,所以配置方式参考:K8S集群部署kube-Prometheus监控Ceph(版本octopus)集群、并实现告警。
①、添加tomcat的 prometheus-servicemonitor
[root@k8s01 prometheus-tomcat]# cat prometheus-serviceMonitortomcat.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: tomcat-k8s
namespace: monitoring
labels:
app: tomcat
spec:
jobLabel: k8s-app
endpoints:
- port: port
interval: 15s
selector:
matchLabels:
app: tomcat
namespaceSelector:
matchNames:
- kube-system
②、kube-prometheus 添加 tomcat service和 endpoint ,把tomcat外部服务映射到k8s集群
[root@k8s01 prometheus-tomcat]# cat prometheus-tomcatService.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: tomcat-k8s
namespace: kube-system
labels:
app: tomcat
subsets:
- addresses:
- ip: 172.16.1.15
ports:
- name: port
port: 9901
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: tomcat-k8s
namespace: kube-system
labels:
app: tomcat
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 9901
protocol: TCP
应用yaml 文件
[root@k8s01 prometheus-tomcat]# kubectl apply -f prometheus-serviceMonitortomcat.yaml
servicemonitor.monitoring.coreos.com/tomcat-k8s configured
[root@k8s01 prometheus-tomcat]# kubectl apply -f prometheus-tomcatService.yaml
endpoints/tomcat-k8s created
service/tomcat-k8s created
③、查看prometheus

四、granfa展示
grafana的dashboards编号是8563,添加到grafana中即可。之后,就完成了tomcat的监控,如下图。
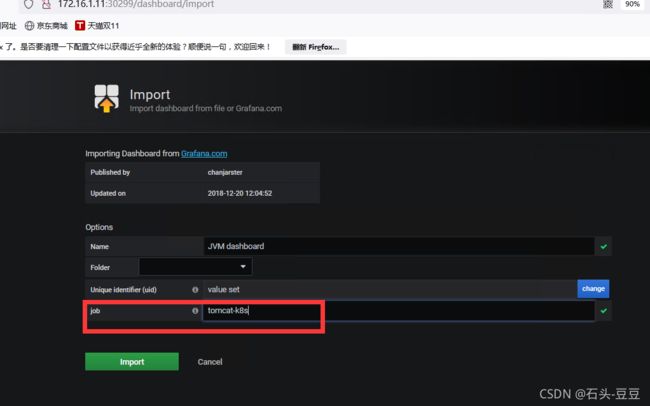
图

参考:https://bbs.huaweicloud.com/blogs/166271
五、jvm告警
vim /kube-prometheus/manifests/prometheus-rules.yaml
- name: tomcat-jvm监控
rules:
# GC次数太多
- alert: GcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count[1m]) > 30
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} 1分钟GC次数>30次"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} 1分钟GC次数>30次,当前值({
{ $value }})"
- alert: GcTimeTooMuch
expr: increase(jvm_gc_collection_seconds_sum[5m]) > 30
for: 5m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} GC时间占比超过10%"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} GC时间占比超过10%,当前值({
{ $value }}%)"
# FGC次数太多
- alert: FgcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count{
gc="ConcurrentMarkSweep"}[1h]) > 3
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} 1小时的FGC次数>3次"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} 1小时的FGC次数>3次,当前值({
{ $value }})"
# 非堆内存使用超过80%
- alert: NonheapUsageTooMuch
expr: jvm_memory_bytes_used{
job="jmx-metrics", area="nonheap"} / jvm_memory_bytes_max * 100 > 80
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} 非堆内存使用>80%"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} 非堆内存使用率>80%,当前值({
{ $value }}%)"
# 内存使用预警
- alert: HeighMemUsage
expr: process_resident_memory_bytes{
job="jmx-metrics"} / os_total_physical_memory_bytes * 100 > 85
for: 1m
labels:
severity: red
annotations:
summary: "{
{ $labels.app }} rss内存使用率大于85%"
message: "ns:{
{ $labels.namespace }} pod:{
{ $labels.pod }} rss内存使用率大于85%,当前值({
{ $value }}%)"