Deep learning多分类和多任务分类的区别及损失函数的选择
多分类模型和多任务模型(Multi-task Model)的区别在于:
多分类模型:样本集包含多个类别,但是一个样本只属于一类。
多任务模型:样本集包含多个类别,一个样本可以属于多个类别。
一、多分类模型
1、多分类模型使用交叉熵损失函数。

在计算时其实就是-log(pt),
对一个样本来说,pt就是该样本真实的类别,模型预测样本属于该类别的概率。例如某样本的label是[0,1,0],模型预测softmax输出的各类别概率值为[0.1,0.6,0.3]。该样本属于第二类别,模型预测该样本属于第二类别的概率是0.6。这就是pt。pt实际上就是个阶段函数。

存在一种特殊情况,二分类。既一个事件只存在两种可能性。称之为0-1分布问题(二项分布的特例),对于这类问题,熵的计算方法可以简化为如下算式:
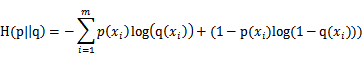
numpy实现如下:
(ps:其实在tensorflow实现这些函数更加复杂,考虑了很多种避免梯度爆炸的情况。例如避免出现y_prd=0或者1的情况(log(0)为-inf,导致loss无穷大),以下的代码实现只是为了更简洁的阐述,是不严谨的实现代码)
y_true = np.array([0,1,0])
y_pred = np.array([0.1,0.7,0.2])
print(-y_true*np.log(y_pred))
print(np.sum(-y_true*np.log(y_pred)))
#输出:
[-0. 0.35667494 -0. ]
0.356674943938732452、二分类模型
二分类的模型有两种情况:输出节点只有一个,输出节点包含两个。这两种情况的损失函数都使用二分类的交叉熵损失函数。以下分别说明
1)只有一个输出节点
模型只有一个输出节点时。该节点的激活函数使用sigmoid函数而不是softmax函数。如果该节点的值大于0.5则属于一类。小于0.5属于另外一类。
举例说明该情况的loss计算
如果某一样本的类别label=1,模型预测的pred=0.8,则此时的
![]()
用numpy实现的代码如下:
y_true = np.array([0])
y_pred = np.array([0.2])
print(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred))
print(np.mean(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred),axis=-1))
#输出:
[0.22314355]
0.2231435513142097
y_true = np.array([1])
y_pred = np.array([0.8])
print(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred))
print(np.mean(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred),axis=-1))
#输出:
[0.22314355]
0.22314355131420972)有两个输出节点。
将label进行one-hot编码,输出层使用softmax激活函数。
例如label=[1,0],pred=[0.7,0.3]
此时的loss fn仍然使用 binary_crossentropy,loss fn会计算每个节点的loss然后求平均。由于两个节点概率互斥,所以其loss总是相等,再求平均所以其loss等同于只使用一个节点的loss。
y_true = np.array([0,1])
y_pred = np.array([0.2,0.8])
print(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred))
print(np.mean(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred),axis=-1))
#输出:
[0.22314355 0.22314355]
0.2231435513142097二、多任务模型(Multi-task model)
用于二分类的binary_crossentropy损失函数也可用与多任务模型。
其实在tensorflow 实现sigmoid_cross_entropy_with_logits的源码注释中提到。该loss fn用于类别独立不互斥的情况。也就是一张图像可以包含多个类别。
def sigmoid_cross_entropy_with_logits( # pylint: disable=invalid-name
_sentinel=None,
labels=None,
logits=None,
name=None):
"""Computes sigmoid cross entropy given `logits`.
Measures the probability error in discrete classification tasks in which each
class is independent and not mutually exclusive. For instance, one could
perform multilabel classification where a picture can contain both an elephant
and a dog at the same time.binary_crossentropy为什么可以用于多任务模型的训练。
这是由于binary_crossentropy会计算输出层中每一个节点的损失,一个节点对应于一个类别,其实也就是计算每一个类别的损失。然后求平均作为最终该图像的loss。用numpy实现如下:
import numpy as np
y_true = np.array([0,1,1])
y_pred = np.array([0.1,0.7,0.8])
print(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred))
print(np.mean(-y_true*(np.log(y_pred))-(1-y_true)*np.log(1-y_pred),axis=-1))
#输出:
[0.10536052 0.35667494 0.22314355]
0.22839300363692283