4小时学完Python数据分析入门笔记(一) Data Analysis with Python(Numpy, Pandas, Matplotlib, Seaborn)
4小时学完Python数据分析入门笔记(一)
-
- 写在前面
- 数据分析是什么
- 数据分析流程
- 数据分析实例
- 小结
写在前面
作为一个数据科学专业的学生,最近总在做深度学习和前端,想想暑假还是要再看看数据科学的东西。找到freecodecamp.org + RMOTR的Python数据分析课,全视频4小时22分钟,复习一下做个笔记。以下内容斜体和(括号)部分仅为我个人的想法或补充,图片和其他文字为视频截图和中文翻译。估计要分几次发完,转载标明出处。
原视频链接:https://www.youtube.com/watch?v=r-uOLxNrNk8
Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn)
数据分析是什么
对数据进行检查、清理、转换和建模的过程,目的是发现有用的信息,告知结论并支持决策制定。The process of inspecting, cleansing, transforming and modeling data with the goal of discovering useful information, informing conclusion and supporting decision making.
——维基百科的定义和有道词典的翻译
像tableau,looker一类的付费包,学起来会比较简单(类比美图秀秀);Python,R之类的编程语言会难一些但发挥自由一些,功能也更强大(类比photoshop)。
Python语言近年也非常火,是很好的入门语言(比如我的“母语”就是python),而且对口数据分析,有很强大的包/库支持。
常用数据分析Python工具/库:
- Jupyter Notebook
- Numpy
- Pandas
- Matplotlib
- Seaborn
- scipy
- scikit-learn
其中打勾的几项之后会介绍
数据分析流程
流程图共五个部分:
- 数据提取
获取数据的方式有多种,比如本来就有数据库,那可以用SQL等语言读取;爬虫获取数据(注意要合法爬虫);API获取等等。 - 数据清洗
清除无效数据,空数据,错数据等。 - 数据处理
将数据结构化,便于读取。 - 数据分析
初步探索,可视化,关联性分析,统计分析。 - 后续行动
机器学习建模等一系列高级分析。
这五部分往往不是直线过程,而是一个循环。
我的理解是,这几部分往往是由不同的岗位合作完成的,数据工程师可能负责更多的是1,2甚至3部分;数据分析师负责3,4部分;数据科学家主要负责5部分。
然后就看到这个数据分析师和数据科学家的对比图:

可以看到,数据分析师在探索分析方面能力要求更高,数据科学家在后续建模方面更胜。
数据分析实例
我们可以先看一个数据分析实例来直观感受一下数据分析做什么,但我们会跳过细节,细节会在之后的视频(博客)里详细介绍。由于没有提供这个数据集,我就只能看看截图,先不能跟着操作了(虽然这个例子的本意也不需要跟着操作)。
数据的格式是csv文件(excel或者pages可以打开),长这样:
我们不会仔细观察每一行数据,而是大概对数据有点感觉就行了。这里我们用jupyter notebook这个工具进行数据分析。第一次接触jupyter notebook的话,可以通过下载anaconda然后使用jupyter(之后详细介绍)。Jupyter notebook里框输入Python代码然后每个框下面的是print出来的结果,可以分段运行代码,不像是用VS code或者PyCharm会在console里全部输出。
首先导入数据,看看前五行就大概知道这个数据是什么样了。然后我们再看看总共有几行几列,比如这里我们有113036行18列,可想而知我们也不可能每一行都看一遍。
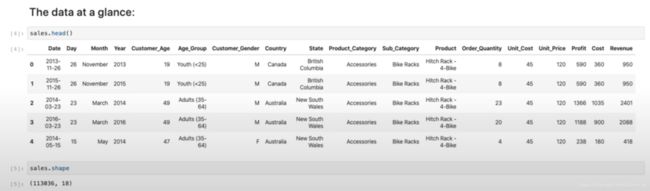
然后看看这18列都代表什么含义。Column一栏是每列的名字,比如第0列是日期,第11列是产品。Non-Null Count一栏是每列的空数据的个数,很幸运的是我们没有空数据,那这样数据清洗的任务就小多了。Dtype一栏是每列的数据类型,编程语言中也有这个概念,比如string,list,float都是数据类型。这里的类型和常见python数据类型似乎不同,比如datetime64[ns]是一种时间的数据类型,int64是一种数字的类型,还有object类型。
sales.describe()从统计角度来看我们的数据,返回给我们平均,最大最小,标准偏差,25%, 50%, 75%百分位等。

现在如果我们单看Unit_Cost这一列。我们同样可以看它的统计学信息,比如平均数,中位数等(就是把上面表格抽取一行)。

但更直观的是通过可视化的方法看一下图像大概的样子。我们这里用matplotlib画4个图:box,density,平均&中位线和直方图。

图里靠左带尾巴的框是大多数数据集中的区域,黑色的小圈都是脱离大部队的数据。

同样的,我们可以在密度图里看到类似的结论:大部分数据集中在0周围。

在密度图的基础上,我们画上平均线(红)和中位线(绿)。

同理,直方图一样。
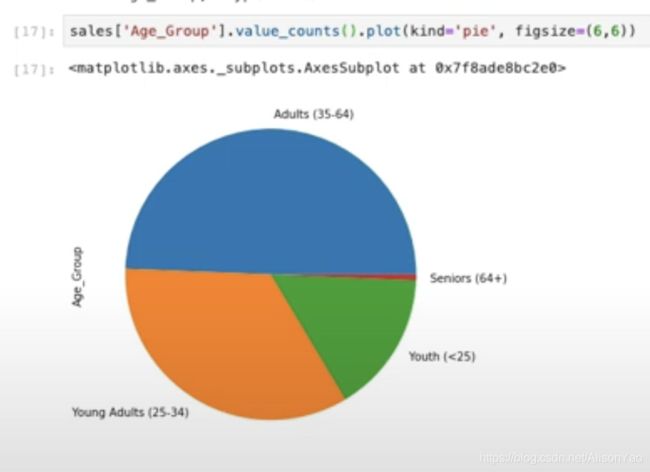
注意这里的Unit_Cost是int64的数据类型,也就是说这一列所有的数据都是数字,本来就可以量化,那非数字的数据类型怎么办?我们再来看Age_Group这一列。Age_Group分为四种:Adults, Young Adults, Youth和Seniors, 他们不再用数字而是用文字表示了。

我们可以画个饼图来看一看。
画个柱状图。

看完一堆漂亮的图表,我们来研究一下每一列之间的关系/相关性,并看更多的图表。这是一个统计上的概念。简单来说就是比如年龄和身高在年龄在一定范围的时候有一定的相关性,但你的年龄和这篇博客码多少字没有什么相关性。记得Tom Mitchell教授在机器学习课里解释correlation的时候讲过一个很极端的例子:如果你的两列数据碰巧一列是这个人是否生日在7/1及以前,另一列数据是这个人是否生日在7/1之后,那这两列数据就有很高的相关性,生日这个feature会对模型产生双重影响。我们这里的数据中,肉眼观察我们会猜测Unit_Cost和Profit相关,因为单位成本越高,利润大概率越少。
接下来我们用数字验证一下我们的猜测。可以观察到的是:左上到右下对角线全是1,那是因为同一列的相关性肯定高的爆表,最高就是1了。这里Unit_Cost和Profit相关性是0.74,还比较高,验证了我们的猜测。还有一个观察就是整个矩阵是一个转置矩阵(对角线对称),那是因为计算相关性的公式对A和B两列的位置没有要求,A和B的相关性和B和A的相关性相等。
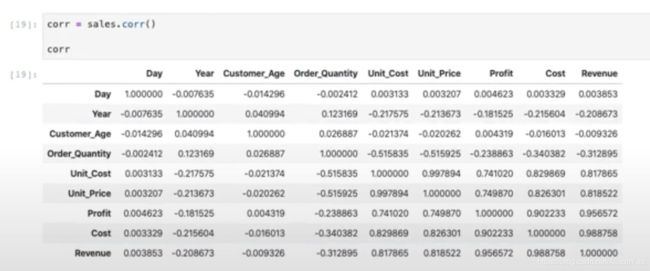
看数字不太直观,我们用颜色来反应数字大小。红色代表低相关性,蓝色代表高相关性。同样的,对角线都是蓝色。

如果我们想单独看看某两列的关系,比如Customer_Age和Revenue,我们可以用散点图来看看。我们并没有看到很明显的相关性。

相比之下,Revenue和Profit则有很高的相关性。有一种想拟合一条y=kx直线的冲动,也就是说Revenue越高,Profit越高,这也非常合情合理符合常识。

再来看看Profit和Age_Group的关系。box图不是我最享受的图表,但为了示例,还是多
看看。这里可以把每个Age_Group都分别表示出来,还是挺棒的。
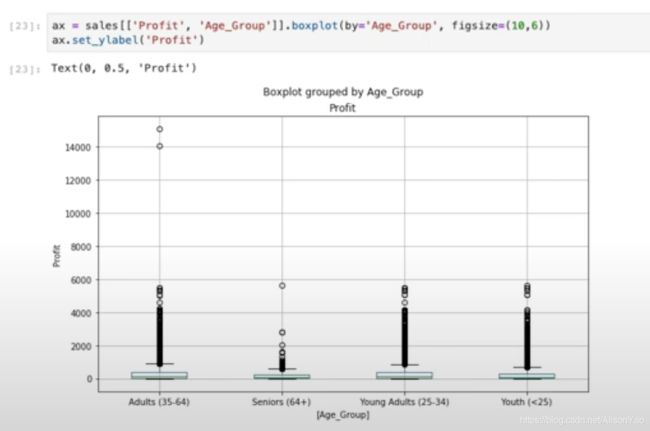
再来一个。

在数据处理部分,我们可以用已有数据创造新的数据列(有时我们可能觉得这样更有意义)。比如之前我们一次Kaggle课内比赛用路程除以时间得到新的一列数据:平均速度(顺便提一句Kaggle是个非常棒的数据科学网站,包含很多数据库和比赛,可以自己组队尝试一下积累经验)。这里我们计算Revenue_per_Age = Revenue / Age,虽然这没有什么特别的意义。这就是为什么数据分析/数据科学很需要商业或者专业领域的知识,说不定Revenue_per_Age有自己的意义,只是视频主讲人(和我)认为没有什么意义,那就不会看这样的数据,就会错过有用信息。相反,对一个领域了解越深,就越知道什么样的数据有用,就可以在前期数据处理的时候自由发挥。

这样我们就成功添加了新的一列数据,同样可以可视化。
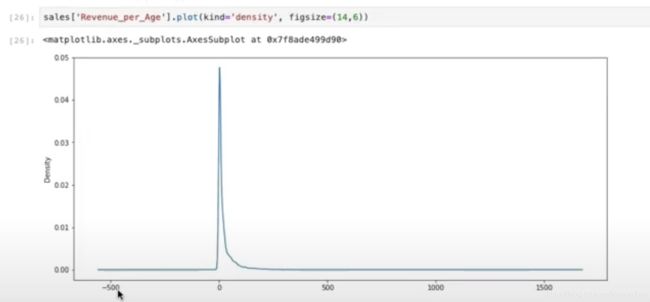

当然,我们也可以两列相乘,相加,一列整个乘以2之类的生成新的一列,只要我们自己认为这样做有意义即可。
接下来,我们看看怎么从这么多数据里筛选出我们想要的数据。loc函数可以解决很多筛选的需求。
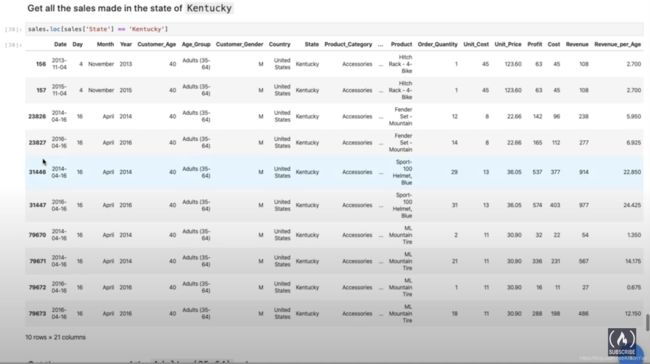
筛选条件有的时候会比较复杂。

再次说明,以上细节都会在之后的视频(博客)里详细介绍,这个例子只是让大家看看先有点感觉就行。
小结
刚开始不涉及代码,就简单介绍数据分析是什么,数据分析的流程,看一个实例。
这里只是挑重点的笔记,分几次发完,转载标明出处。第一次码字,翻译又不到位之处表示抱歉,轻喷谢谢。欢迎留言交流,互相学习。
原视频链接:https://www.youtube.com/watch?v=r-uOLxNrNk8
Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn)
接下来写Jupyter Notebook & Numpy,动手开始实际操作。
未完待续To be continued…
下一篇:4小时学完Python数据分析入门笔记(二)