【王道笔记-计算机组成原理】第三章 存储系统
文章目录
- 一、半导体随机存取存储器
-
- 1.基本结构
- 2.随机存储器RAM
- 3.只读存储器ROM
- 4.RAM和ROM区别
- 二、主存储器与CPU的连接
-
- 1.主存容量的扩展
- 2.存储器与CPU的连接
- 3.片选
- 三、并行技术
-
- 1.双端口RAM(空间并行)
- 2.多模块存储器(时间并行)
- 四、高速缓存Cache(采用SRAM)
-
- 1.工作原理
- 2.Cache命中率与平均访问时间
- 3.Cache和主存的映射方式
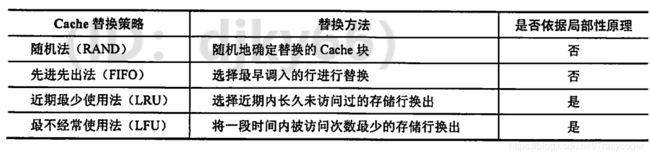
- 4.Cache中主存块的替换算法
- 五、虚拟存储器
-
- 1.Cache写策略
- 2.页式虚拟存储器(基本单位页,定长)
- 3.快表(减少页虚拟存储器访存次数)
- 4.段式虚拟存储器(基本单位段,不定长)
- 5.段页式虚拟存储器(基本单位页)
- 附:王道课后题笔记
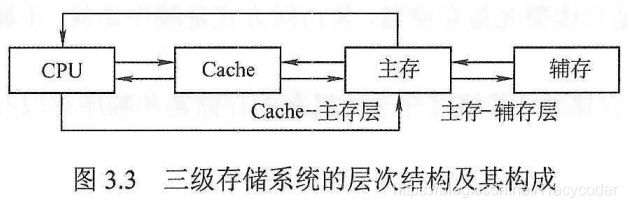
主存和Cache之间的数据调动是由硬件自动完成的,对所有程序员均是透明的;而主存和辅存之间的数据调动则是由硬件和操作系统共同完成的,对应用程序员是透明的。
MDR和MAR逻辑上在主存中,实际上在CPU中;地址译码器在主存中。
一、半导体随机存取存储器
1.基本结构

2.随机存储器RAM
Cache由静态随机存取SRAM实现,主存由动态随机存储器DRAM实现,它们都是易失的。
(1) 工作原理
- 静态随机存取存储器SRAM
SRAM基于双稳态触发器,存取速度快,但集成度低,功耗较大。
- 动态随机存取存储器DRAM
DRAM基于电荷,采用地址复用技术(地址线是原来的一半),存取速度比SRAM慢,集成度高,价位低,容量大,功耗低。
即时电源不断电,信息也会自动消失,因此每个一个刷新周期(2ms)就要刷新一次,每次占用一个存储周期。
刷新方式:
①集中刷新:在死时间/死区对所有行一次刷新,访存速度快,但在死时间内不能访问存储器。
②分散刷新:把对每行的刷新分散到各个工作周期中去,访存速度慢,但没有死时间。若将刷新安排在不需要访问存储器的译码阶段,则既不会加长存取周期,又不会产生"死时间",这是分散刷新方式的发展,也称为"透明刷新"。
③异步刷新:具体做法是将刷新周期除以行数,得到两次刷新操作之间的时间间隔t,利用逻辑电路每隔时间t产生一次刷新请求。这样可以避免使CPU连续等待过长的时间,而且减少了刷新次数,从根本上提高了整机的工作效率。
刷新需注意以下问题∶
①刷新对CPU透明,即刷新不依赖于外部的访问;
②刷新单位是行,因此刷新操作时仅需要行地址;
③刷新操作类似于读操作,但又有所不同;
④刷新操作仅给栅极电容补充电荷,不需要信息输出;
⑤刷新时不需要选片,即整个存储器中的所有芯片同时被刷新。
(2)SRAM和DRAM的比较

3.只读存储器ROM
结构简单,所以位密度比RAM的高;具有非易失性,所以可靠性高。ROM的升级版有以下几种:
- MROM(Mask Read-Only Memory)∶在生产过程中直接写入,以后任何人都无法改变其内容
- PROM(Programmable ROM)∶允许用户用专门设备写入程序,写入后内容就无法改变
- EPROM(Erasable Programmable ROM)∶允许用户写入程序,程序员可以对其内容进行多次改写
- Flash∶在不加电时仍可长期保存信息且能进行快速擦除重写
- SSD(Solid State Disk):什么都好,但价格高。一般由Flash芯片组成。
以前我总是分不清这几个,后来发现结合英文全称好记多了。
4.RAM和ROM区别

二、主存储器与CPU的连接
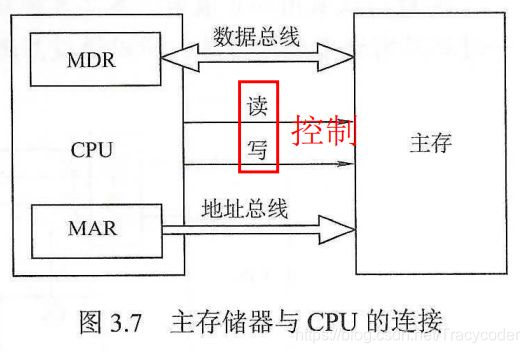
1.主存容量的扩展

芯片数=容量/单片芯片容量
2.存储器与CPU的连接
(1)合理选择存储芯片
通常选用 ROM存放系统程序,选用 RAM组成用户区。
(2)地址线的连接
低位用于地址空间,高位用于片选。片选原理会在下面单独介绍。
(3)数据线的连接
对应数据位数。
(4)读写控制线
两根,一根读,一根写。
3.片选
片选信号的产生分为线选法和译码片选法。
- 线选法
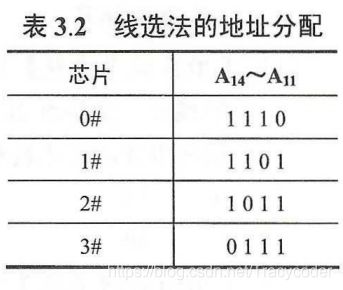
优点∶不需要地址译码器,线路简单。缺点∶地址空间不连续,选片的地址线必须分时为低电平(否则不能工作),不能充分利用系统的存储器空间,造成地址资源的浪费。
- 译码片选法
即用一片74LS138作为地址译码器,则A15A14A13=000时选中第一片,A15A14A13=001 时选中第二片,以此类推(即3位二进制编码)。
三、并行技术
1.双端口RAM(空间并行)
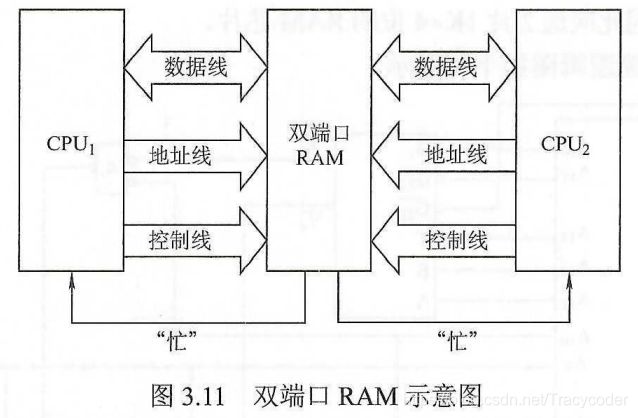
当两个端口的地址不相同时,在两个端口上进行读写操作一定不会发生冲突。当对同一个主存操作时,写操作只能互斥进行(不能写写、写读),读操作可以同时进行。
2.多模块存储器(时间并行)
(1)单体多字存储器
存储器中只有一个存储体,每个存储单元存储m个字,总线宽度也为m个字。一次并行读出m个字,地址必须顺序排列并处于同一存储单元。即每隔1/m存取周期,CPU向主存取一条指令。显然,这增大了存储器的带宽,提高了单体存储器的工作速度。
(2)多体并行存储器
多体并行存储器由多体模块组成。每个模块都有相同的容量和存取速度,各模块都有独立的读写控制电路、地址寄存器和数据寄存器。它们既能并行工作,又能交叉工作。
- 高位交叉编址(顺序)
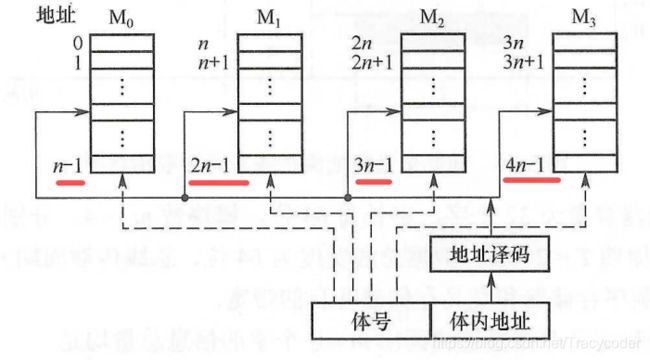
总是按顺序访问存储模块,存储模块不能被并行访问,因而不能提高存储器的吞吐率。仍是顺序存储器。
- 低位交叉编址(流水线)
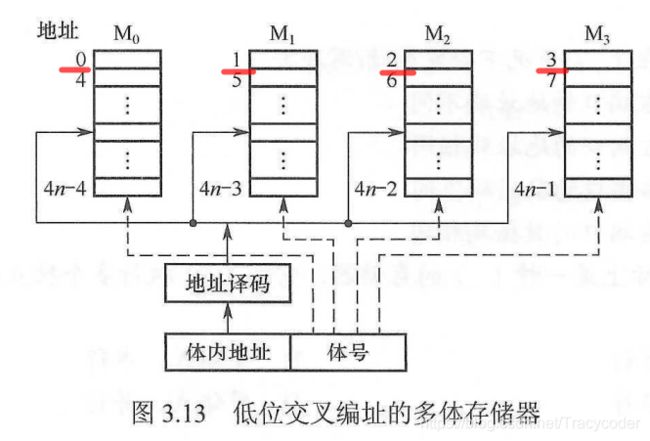
编址后,可在不改变每个模块存取周期的前提下,采用流水线的方式并行存取,提高存储器的带宽。
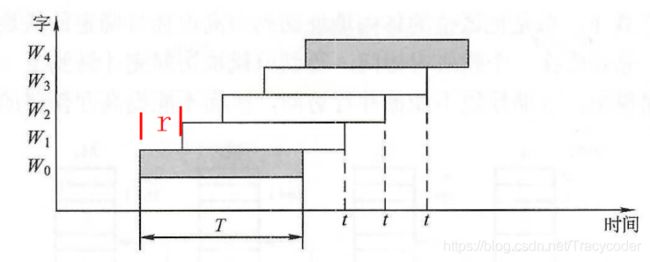
设模块字长等于数据总线宽度,模块存取一个字的存取周期为T,总线传送周期为r,为实现流水线方式存取,存储器交叉模块数应大于等于m=T/r,以保证启动某模块后经过mxr的时间后再次启动该模块时,其上次的存取操作已经完成(流水线不间断)。
四、高速缓存Cache(采用SRAM)
高速缓冲技术就是利用程序访问的局部性原理,把程序中正在使用的部分存放在一个高速的、容量较小的Cache 中,使CPU的访存操作大多数针对Cache 进行,从而大大提高程序的执行速度。
1.工作原理
- Cache由SRAM实现。
- Cache和主存的交换单位是块(又称行,包含多个字节),主存块远多于Cache块;CPU与Cache之间的数据交换以字为单位。
- Cache保存的仅仅是主存块的副本。
- 当CPU发出请求时,先在Cache里面找,不必访存;若未命中,去主存中找,并把这页调入Cache中。
- 如果Cache满了,需要用替换算法替换某页。
2.Cache命中率与平均访问时间
- 命中率:Nc为Cache命中次数,Nm为主存命中次数
![]()
- 平均访问时间:tc为Cache访问时间,tm为主存访问时间
![]()
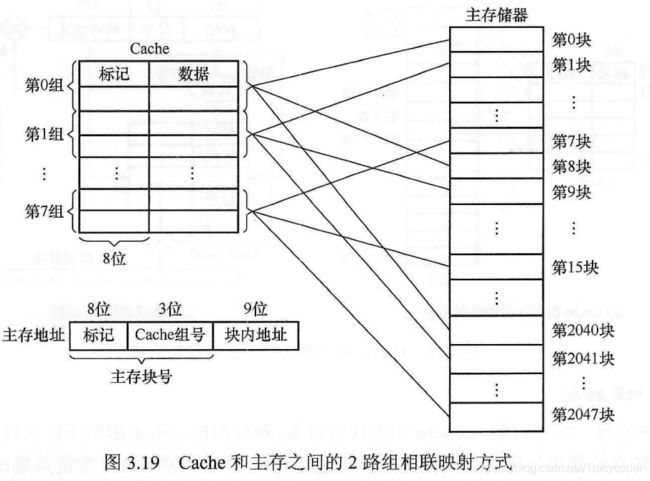
3.Cache和主存的映射方式
- 两个重要概念:
标记:Cache中块是来自主存的哪一块。
有效位:Cache中块/行中的信息是否有效。
(1)方式一: 直接映射
无条件替换,块冲突概率最高,空间利用率最低。
- 地址结构:

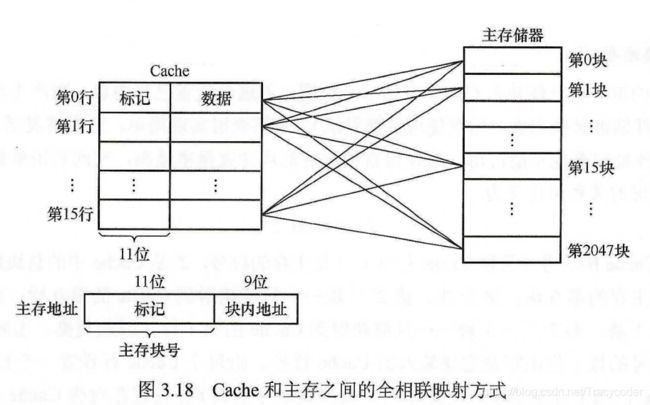
(2)方式二:全相联映射
优点是比较灵活,Cache 块的冲突概率低,空间利用率高,命中率也高。
缺点是标记的比较速度较慢,实现成本较高,通常需采用昂贵的按内容寻址的相联存储器进行地址映射。
(3)方式三:组相联映射
- 组相联映射:
4.Cache中主存块的替换算法
五、虚拟存储器
虚拟存储器利用的是程序的局部性原理。对应用程序员透明的。
Cache是为了解决系统速度,虚拟存储器是为了解决主存容量。
CPU使用虚地址的过程:
- 根据虚地址、实地址的对应关系,判断该虚地址的存储单元是否装入主存中。
- 若存储单元在主存中,访问该单元;
- 若不在主存中,从辅存调入主存;
- 若主存满了,替换调入主存。
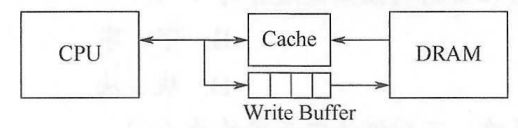
1.Cache写策略
因为Cache 中的内容是主存块副本,当对Cache中的内容进行更新时,就需选用写操作策略使Cache 内容和主存内容保持一致。此时分两种情况:
(1)写命中(要被修改的单元在Cache中)
-
全写法:当CPU 对Cache 写命中时,必须把数据同时写入Cache和主存。当某一块需要替换时,不必把这一块写回主存,用新调入的块直接覆盖即可。实现简单,数据的正确性高,但增加了访存次数。需要写缓冲。
-
写回法:写回法(write-back)。当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。减少了访存次数,但存在不一致的隐患。需要设置标志位/脏位。
(2)写不命中
- 非写分配法:只写入主存,不调块。搭配全写法使用。
- 写分配法:加载主存中的块到Cache 中,然后更新这个Cache 块。需要设置脏位,搭配写回法使用。
2.页式虚拟存储器(基本单位页,定长)
虚拟空间与主存空间都被划分成同样大小的页。
虚拟地址到物理地址由页表(在主存中)转换。
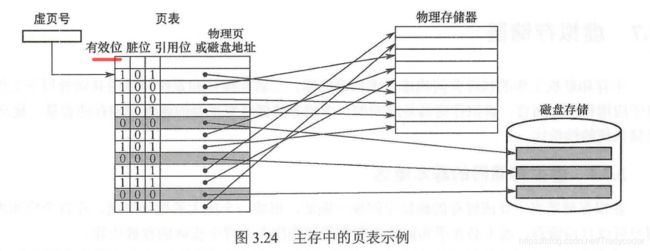
- 有效位:表示是否在主存中。
- 脏位:表示是否修改过。
- 引用位:配合替换策略使用。
优点:页面的长度固定,页表简单,调入方便。
缺点是,由于程序不可能正好是页面的整数倍,最后一页的零头将无法利用而造成浪费,并且页不是逻辑上独立的实体,所以处理、保护和共享都不及段式虚拟存储器方便。
3.快表(减少页虚拟存储器访存次数)
利用局部性原理,把经常访问的页表项放在快表TLB(在Cache里) 中,相应的页表称为慢表。转换时,先找快表,找不到再找慢表。
快表采用相联存储器(全相联、组相联)器件组成,按照查找内容访问,因此速度更快。但快表只是慢表的副本,无法得到更多的搜索结果。
Cache缺失处理由硬件完成;缺页处理由软件完成;而 TLB缺失既可以用硬件又可以用软件来处理。
4.段式虚拟存储器(基本单位段,不定长)
段是按程序的逻辑结构划分的,各个段的长度因程序而异。
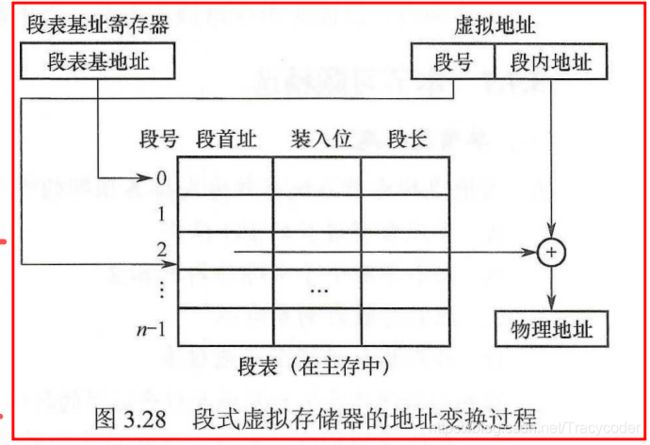
优点是,段的分界与程序的自然分界相对应,因而具有逻辑独立性,使得它易于编译、管理、修改和保护,也便于多道程序的共享。
缺点是因为段长度可变,分配空间不便,容易在段间留下碎片,不好利用,造成浪费。
5.段页式虚拟存储器(基本单位页)
把程序按逻辑结构分段,每段再划分为固定大小的页,主存空间也划分为大小相等的页,程序对主存的调入、调出仍以页为基本传送单位。
在段页式虚拟存储器中,每个程序对应一个段表,每段对应一个页表,段的长度必须是页长的整数倍,段的起点必须是某一页的起点。
段页式虚拟存储器的优点是,兼具页式和段式虚拟存储器的优点,可以按段实现共享和保护。缺点是在地址变换过程中需要两次查表,系统开销较大。
附:王道课后题笔记
1.一SRAM芯片,容量是1024*8位,除电源和接地端外,引脚最小数目是?
地址10根(地址复用技术减半为5),数据8根,读写2根,片选1根(地址复用技术片选为2根),一共21根。
2.一个四体并行低位交叉存储器,每个模块的容量是64K×32位,存取周期为200ns,总线周期为 50ns,在200ns 内,存储器能向CPU提供128位二进制信息。
3.某存储系统中,主存容量是Cache容量的4096倍,Cache被分为64个块,当主存地址和Cache地址采用直接映像方式时,地址映射表的大小应为(64*13位)。(假设不考虑一致维护和替换算法位。)
地址映射表包含标志位和有效位(脏位)。由于Cache一共64块(64行),所以映射表一共64行。由于采用直接映射方式,主存容量是Cache容量的4096倍,所以标志位有12位(24096=12)。脏位1位。所以,容量为64*(12+1)位。
4.有效容量为128KB的Cache,每块16B,采用8路组相联。字节地址为1234567H的单元调入该Cache,则其Tag应为(048DH)。
5.有一主存-Cache层次的存储器,其主存容量为1MB,Cache容量为16KB,每块有8个字,每字32位,采用直接地址映像方式,若主存地址为35301H,且CPU访问Cache 命中,则在Cache的第(152)(十进制表示)字块中。(Cache起始字块为第0字块)
6.采用指令Cache与数据Cache分离的主要目的是(减少指令流水线资源冲突)。
7.某计算机主存地址空间大小为256MB,按字节编址。虚拟地址空间大小为4GB,采用页式存储管理,页面大小为4KB,TLB(快表)采用全相联映射,有4 个页表项,内容如下表所示。则对虚拟地址03FFF180H进行虚实地址变换的结果是(0153180H)。
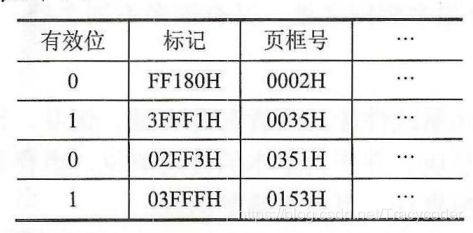
虚拟地址空间大小为4GB,采用页式存储管理,页面大小为4KB,页表的行数=4GB/4KB=1024* 1024。也就是说,页表行数一共有20位。
虚拟地址03FFF180H由两部分组成:页表行号+页内地址。则前20位03FFF是页表行号,查TLB命中且有效,对应页框号也就是实际页地址为0153,虚拟地址03FFF180H剩下的部分180为页内地址。因此虚实地址变换结果为0153180H。