hive之生成唯一id
1.针对没有变话的一张表生成id。(表中数据固定不会增加修改)
ROW_NUMBER ()over() 针对所有数据生成自增id,即使所有数据都相同。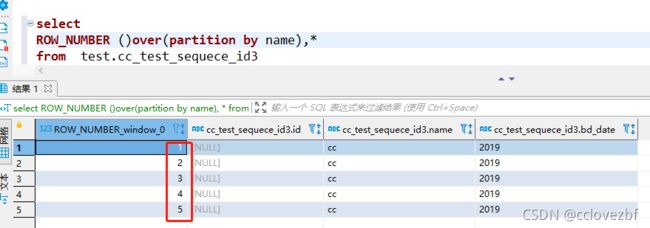
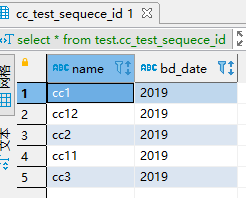
2.针对没有变化的表,根据字段生成自增id 注意cc11 和cc12我故意没按顺序摆放

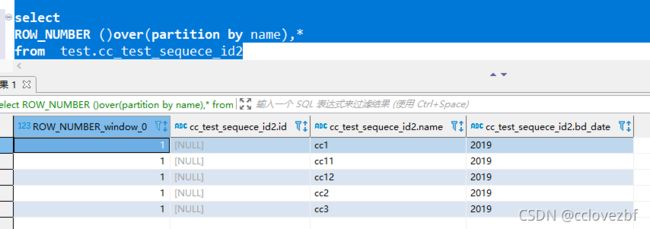
这样做的好处是 生成的id 和name产生了一点联系
3.针对表中数据经常发生变化 可能增加的数据
--原始表
create table test.cc_test_sequece_id(
name string ,
bd_date string
)
--最终结果表
create table test.cc_test_sequece_id(
id string ,
name string ,
bd_date string
)
insert into test.cc_test_sequece_id(name,bd_date)values("cc1","2019"),("cc2","2019"),("cc3","2019")
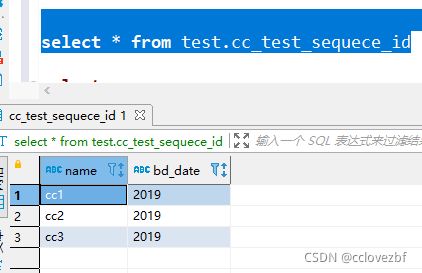
第一次赋予自增id 这里用这个。方便理解。
insert overwrite table test.cc_test_sequece_id_result select ROW_NUMBER ()over(),* from test.cc_test_sequece_id
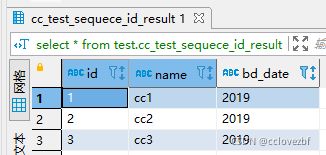
第二次原始表数据变化了
truncate table test.cc_test_sequece_id
insert into test.cc_test_sequece_id(name,bd_date)values("cc1","2019"),("cc12","2019"),("cc2","2019"),("cc11","2019"),("cc3","2019")
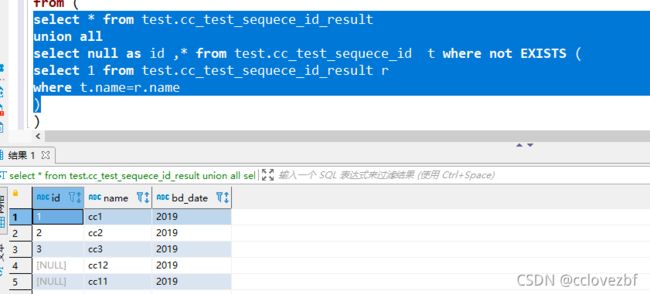
insert overwrite table test.cc_test_sequece_id_result
select
ROW_NUMBER ()over( order by id ) id ,name ,bd_date --然后根据整个表赋值id
from (
select * from test.cc_test_sequece_id_result --上次已经有了id的
union all
select null as id ,* from test.cc_test_sequece_id t --这次数据新增的,用null作为id
where not EXISTS (
select 1 from test.cc_test_sequece_id_result r
where t.name=r.name
)
)t --此时这两个union后有id的会在前面。
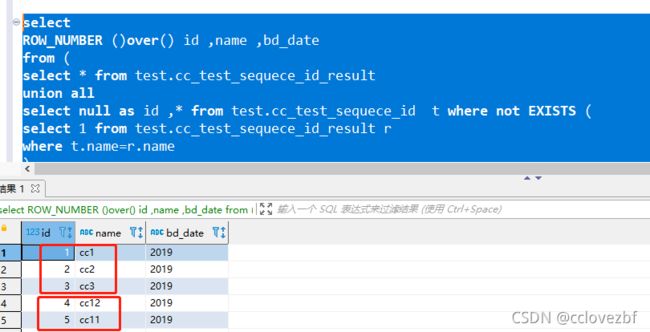
为什么不采用前面的方法直接生成id。那是因为例如cc2在第一次生成主键的时候是2
可是如果数据发生了变化下次他的id就可能是3456这种了。
2021-11-17 今天突然想到这里是有点需要注意。。。
id这个主键字段必须设置为int类型。不要string,不要string,不要string因为string 的排序规则是
1,11,12,13...111,112,113....2,21,22.. 你在order by的时候会打乱顺序的
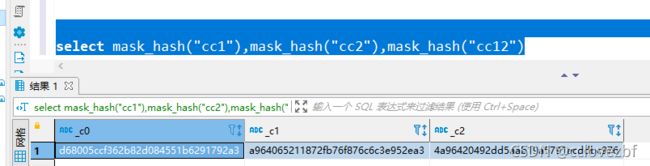
4.通过hash,仅供参考,按照java说的 数据太多的情况下hash值有小部分概率一样,但是可以通过hash多列 来避免,例如hash("c1","c2")
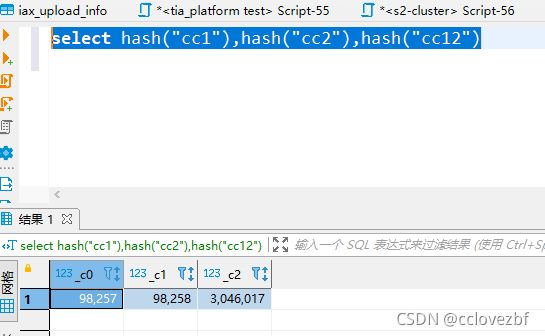
5.通过mask_hash,