每天半小时:入门Python,Pandas库十套练习题带你学会数据分析(一)
习题
- 对应的数据集文件路径查看
- 练习一、开始了解你的数据
-
- 探索Chipotle快餐数据
- 练习二、数据过滤与排序
-
- 探索2012欧洲杯数据
- 练习三、数据分组
-
- 探索酒类消费数据
- 练习四、Apply函数
-
- 探索1960 - 2014 美国犯罪数据
- 练习五、合并
-
- 探索虚拟姓名数据

Pandas是入门Python做数据分析必须要掌握的一个库,是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析的工具。主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。今天就来一起学习。
对应的数据集文件路径查看
ls /home/mw/input/pandas_exercise/pandas_exercise/exercise_data/

练习一、开始了解你的数据
探索Chipotle快餐数据
- 导入必要的库
# 运行以下代码
import pandas as pd
- 从如下地址导入数据集
# 运行以下代码
path1 = "../input/pandas_exercise/pandas_exercise/exercise_data/chipotle.tsv" # chipotle.tsv
- 将数据集存入一个名为chipo的数据框内
# 运行以下代码
chipo = pd.read_csv(path1, sep = '\t')
- 查看前10行内容
# 运行以下代码
chipo.head(10)

- 数据集中有多少个列(columns)
# 运行以下代码
chipo.shape[1]
5
- 打印出全部的列名称
# 运行以下代码
chipo.columns
Index([‘order_id’, ‘quantity’, ‘item_name’, ‘choice_description’,
‘item_price’],
dtype=‘object’)
- 数据集的索引是怎样的
# 运行以下代码
chipo.index
RangeIndex(start=0, stop=4622, step=1)
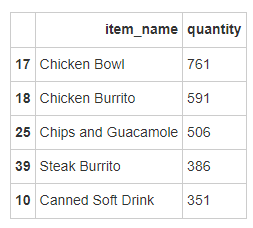
- 被下单数最多商品(item)是什么?
# 运行以下代码,做了修正
c = chipo[['item_name','quantity']].groupby(['item_name'],as_index=False).agg({
'quantity':sum})
c.sort_values(['quantity'],ascending=False,inplace=True)
c.head()
- 在item_name这一列中,一共有多少种商品被下单?
# 运行以下代码
chipo['item_name'].nunique()
50
- 在choice_description中,下单次数最多的商品是什么?
# 运行以下代码,存在一些小问题
chipo['choice_description'].value_counts().head()

- 一共有多少商品被下单?
# 运行以下代码
total_items_orders = chipo['quantity'].sum()
total_items_orders
4972
- 将item_price转换为浮点数
# 运行以下代码
dollarizer = lambda x: float(x[1:-1])
chipo['item_price'] = chipo['item_price'].apply(dollarizer)
- 在该数据集对应的时期内,收入(revenue)是多少
# 运行以下代码,已经做更正
chipo['sub_total'] = round(chipo['item_price'] * chipo['quantity'],2)
chipo['sub_total'].sum()
39237.02
- 在该数据集对应的时期内,一共有多少订单?
# 运行以下代码
chipo['order_id'].nunique()
1834
- 每一单(order)对应的平均总价是多少?
# 运行以下代码,已经做过更正
chipo[['order_id','sub_total']].groupby(by=['order_id']
).agg({
'sub_total':'sum'})['sub_total'].mean()
21.39423118865867
- 一共有多少种不同的商品被售出?
# 运行以下代码
chipo['item_name'].nunique()
50
练习二、数据过滤与排序
探索2012欧洲杯数据
- 导入必要的库
# 运行以下代码
import pandas as pd
- 步骤2 - 从以下地址导入数据集
# 运行以下代码
path2 = "../input/pandas_exercise/exercise_data/Euro2012_stats.csv" # Euro2012_stats.csv
- 将数据集命名为euro12
# 运行以下代码
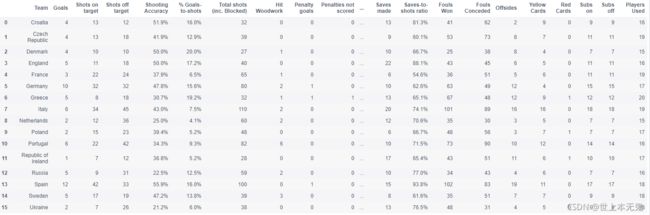
euro12 = pd.read_csv(path2)
euro12
- 只选取 Goals 这一列
# 运行以下代码
euro12.Goals

- 有多少球队参与了2012欧洲杯?
# 运行以下代码
euro12.shape[0]
16
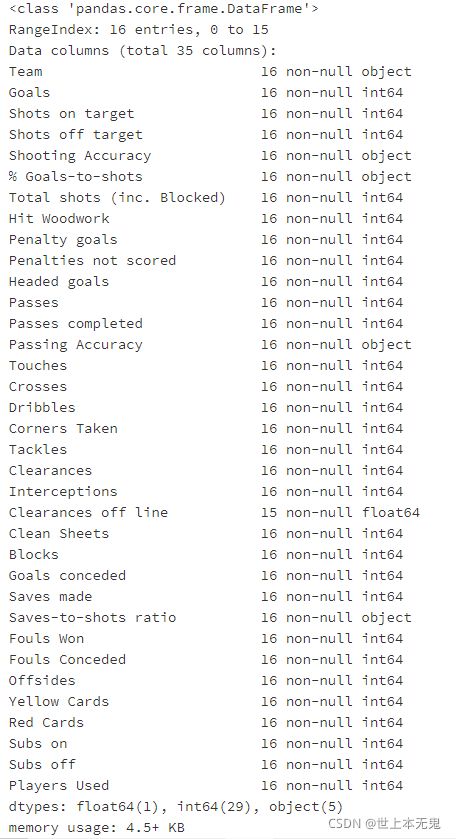
- 该数据集中一共有多少列(columns)?
# 运行以下代码
euro12.info()
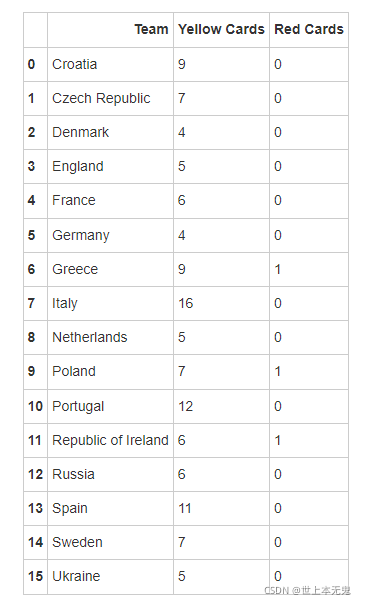
- 将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
# 运行以下代码
discipline = euro12[['Team', 'Yellow Cards', 'Red Cards']]
discipline
- 对数据框discipline按照先Red Cards再Yellow Cards进行排序
# 运行以下代码
discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending = False)

- 计算每个球队拿到的黄牌数的平均值
# 运行以下代码
round(discipline['Yellow Cards'].mean())
7.0
- 找到进球数Goals超过6的球队数据
# 运行以下代码
euro12[euro12.Goals > 6]

- 选取以字母G开头的球队数据
# 运行以下代码
euro12[euro12.Team.str.startswith('G')]

- 选取前7列
# 运行以下代码
euro12.iloc[: , 0:7]

- 选取除了最后3列之外的全部列
# 运行以下代码
euro12.iloc[: , :-3]
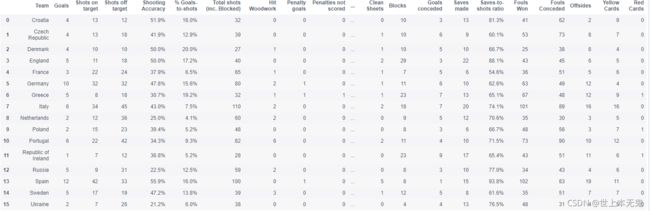
- 找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
# 运行以下代码
euro12.loc[euro12.Team.isin(['England', 'Italy', 'Russia']), ['Team','Shooting Accuracy']]

练习三、数据分组
探索酒类消费数据
- 导入必要的库
# 运行以下代码
import pandas as pd
- 从以下地址导入数据
# 运行以下代码
path3 ='../input/pandas_exercise/pandas_exercise/exercise_data/drinks.csv' #'drinks.csv'
- 将数据框命名为drinks
# 运行以下代码
drinks = pd.read_csv(path3)
drinks.head()

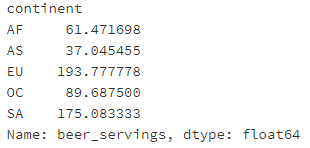
- 哪个大陆(continent)平均消耗的啤酒(beer)更多?
# 运行以下代码
drinks.groupby('continent').beer_servings.mean()
- 打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
# 运行以下代码
drinks.groupby('continent').wine_servings.describe()

- 打印出每个大陆每种酒类别的消耗平均值
# 运行以下代码
drinks.groupby('continent').mean()

- 打印出每个大陆每种酒类别的消耗中位数
# 运行以下代码
drinks.groupby('continent').median()

- 打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
# 运行以下代码
drinks.groupby('continent').spirit_servings.agg(['mean', 'min', 'max'])

练习四、Apply函数
探索1960 - 2014 美国犯罪数据
- 导入必要的库
# 运行以下代码
import numpy as np
import pandas as pd
- 从以下地址导入数据集
# 运行以下代码
path4 = '../input/pandas_exercise/pandas_exercise/exercise_data/US_Crime_Rates_1960_2014.csv' # "US_Crime_Rates_1960_2014.csv"
- 将数据框命名为crime
# 运行以下代码
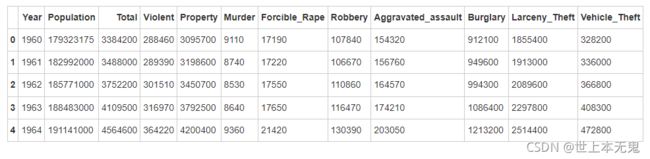
crime = pd.read_csv(path4)
crime.head()
- 每一列(column)的数据类型是什么样的?
# 运行以下代码
crime.info()
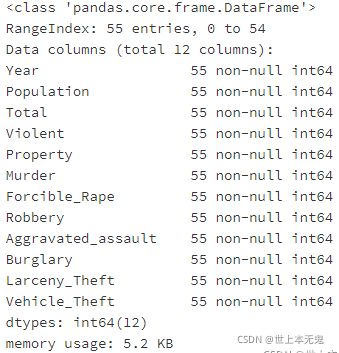
注意到了吗,Year的数据类型为 int64,但是pandas有一个不同的数据类型去处理时间序列(time series),我们现在来看看。
- 将Year的数据类型转换为 datetime64
# 运行以下代码
crime.Year = pd.to_datetime(crime.Year, format='%Y')
crime.info()

- 将列Year设置为数据框的索引
# 运行以下代码
crime = crime.set_index('Year', drop = True)
crime.head()
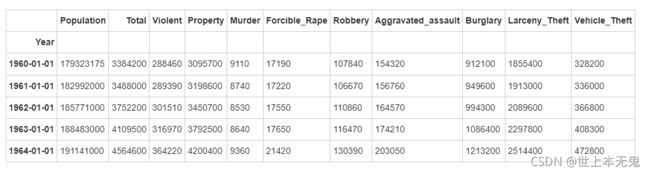
- 删除名为Total的列
# 运行以下代码
del crime['Total']
crime.head()
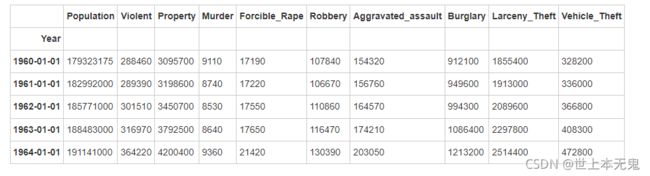
crime.resample('10AS').sum()

- 按照Year对数据框进行分组并求和
注意Population这一列,若直接对其求和,是不正确的
# 更多关于 .resample 的介绍
# (https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.resample.html)
# 更多关于 Offset Aliases的介绍
# (http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases)
# 运行以下代码
crimes = crime.resample('10AS').sum() # resample a time series per decades
# 用resample去得到“Population”列的最大值
population = crime['Population'].resample('10AS').max()
# 更新 "Population"
crimes['Population'] = population
crimes

- 何时是美国历史上生存最危险的年代?
# 运行以下代码
crime.idxmax(0)

练习五、合并
探索虚拟姓名数据
- 导入必要的库
# 运行以下代码
import numpy as np
import pandas as pd
- 按照如下的元数据内容创建数据框
# 运行以下代码
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
- 将上述的数据框分别命名为data1, data2, data3
# 运行以下代码
data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name'])
data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name'])
data3 = pd.DataFrame(raw_data_3, columns = ['subject_id','test_id'])
- 将data1和data2两个数据框按照行的维度进行合并,命名为all_data
# 运行以下代码
all_data = pd.concat([data1, data2])
all_data
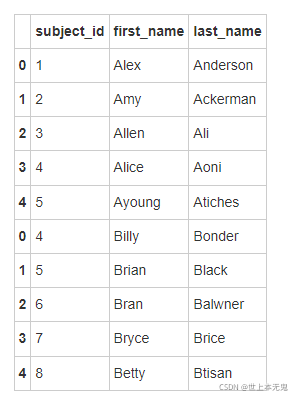
- 将data1和data2两个数据框按照列的维度进行合并,命名为all_data_col
# 运行以下代码
all_data_col = pd.concat([data1, data2], axis = 1)
all_data_col

- 打印data3
# 运行以下代码
data3
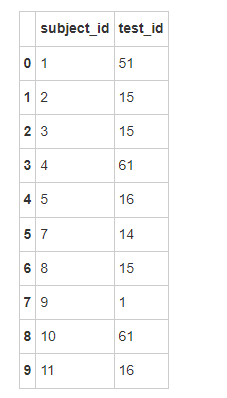
- 按照subject_id的值对all_data和data3作合并
# 运行以下代码
pd.merge(all_data, data3, on='subject_id')
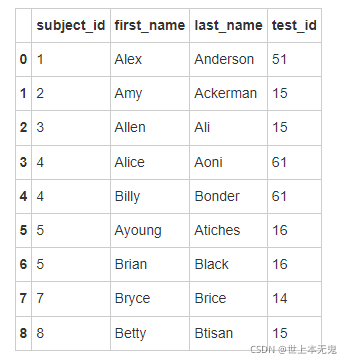
- 对data1和data2按照subject_id作连接
# 运行以下代码
pd.merge(data1, data2, on='subject_id', how='inner')
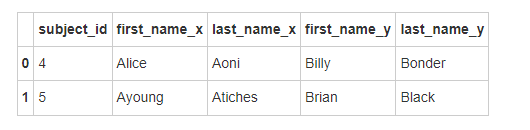
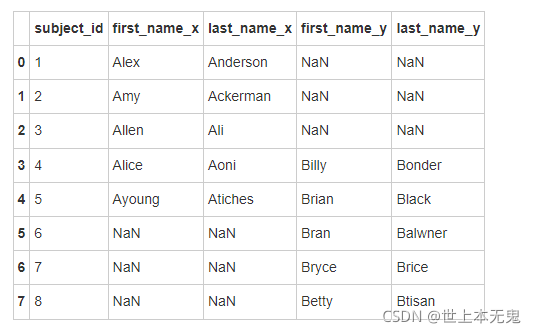
- 找到 data1 和 data2 合并之后的所有匹配结果
# 运行以下代码
pd.merge(data1, data2, on='subject_id', how='outer')
 你们的支持是我持续更新下去的动力,(点赞,关注,评论) 这篇文还未结束,想了解后续的可以关注我,持续更新。
你们的支持是我持续更新下去的动力,(点赞,关注,评论) 这篇文还未结束,想了解后续的可以关注我,持续更新。

点击领取 Q群号: 943192807(纯技术交流和资源共享)以自助拿走。
①行业咨询、专业解答 ②Python开发环境安装教程 ③400集自学视频 ④软件开发常用词汇 ⑤最新学习路线图 ⑥3000多本Python电子书