OpenResty原理剖析及应用
最近在京东零售技术公众号上看到了一篇关于OpenResty原理相关的文章,写的很不错,基本上把OpenResty的原理、优缺点、适用场景都讲清楚了,推荐一下。原文地址:https://mp.weixin.qq.com/s/QwsFADXa0fcZ0njKgaMvMg
1.什么是OpenResty
OpenResty是一个基于Nginx与Lua的高性能Web平台,其内部集成了大量精良的Lua库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
OpenResty通过汇聚各种设计精良的Nginx模块,从而将Nginx有效地变成一个强大的通用Web应用平台。这样,Web开发人员和系统工程师可以使用Lua脚本语言调Nginx支持的各种C以及Lua模块,快速构造出足以胜任10K乃至1000K以上单机并发连接的高性能Web应用系统。
从上面官网的描述信息中,可以看出OpenResty主要包含两方面的技术:
-
Nginx:一款轻量级、高性能、高并发的Web服务器。
-
Lua:一种轻量、小巧、可移植、快速的脚本语言;LuaJIT即时编译器会将频繁执行的Lua代码编译成本地机器码交给CPU直接执行,执行效率更高,OpenResty会默认启用LuaJIT。
工作原理如下图所示:
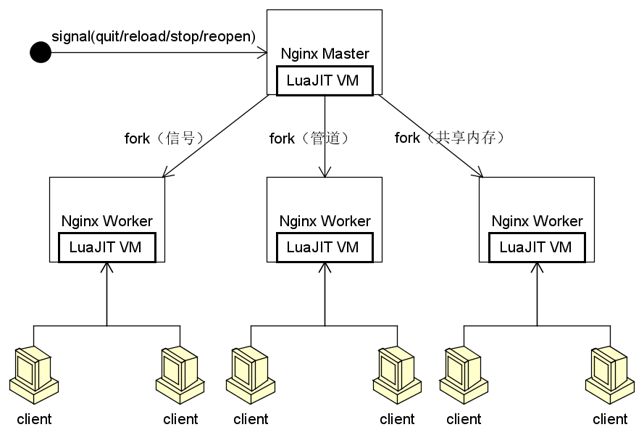
Nginx使用了管理进程+工作进程的设计。管理进程为工作进程的父进程,负责外部指令的接收,工作进程状态的监管,负载均衡等。工作进程负责客户端请求的处理和响应,工作进程一般是按照CPU的核数配置的,并且可以和处理器一一绑定,降低进程间切换的开销。
OpenResty本质上是将LuaJIT的虚拟机嵌入到Nginx的管理进程和工作进程中,同一个进程内的所有协程都会共享这个虚拟机,并在虚拟机中执行Lua代码。在性能上,OpenResty接近或超过Nginx的C模块,而且开发效率更高。下面深入介绍一下OpenResty的原理。
2.OpenResty原理剖析
OpenResty的原理可以从三个方面进行剖析:Lua协程、cosocket、多阶段处理。
2.1 Lua协程
Lua脚本语言用标准的C语言编写并以源代码形式开放,其设计目的是嵌入应用程序中,从而为应用程序提供灵活的扩展和定制服务。目前Lua大量应用于Nginx、嵌入式设备、游戏开发等方面。
协程又称为微线程,是这一种比线程更加轻量级的存在,正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。Lua协程与线程类似,拥有独立的堆栈、独立的局部变量、独立的指令指针,同时又与其他协同程序共享全局变量和其他大部分东西。
线程和协程的主要区别在于,一个具有多个线程的程序可以同时运行几个线程,而协程却需要彼此协作的运行。在任一时刻只有一个协程在运行,并且这个正在运行的协程只有明确的被要求挂起的时候才会被挂起。从这里我们可以看出,协程是不被操作系统内核所管理的,而完全由程序控制(也就是用户态执行),这样带来的好处就是性能得到了极大地提升。进程和线程切换要经过用户态到内核态再到用户态的过程,而协程的切换可以直接在用户态完成,不需要陷入内核态,切换效率高,降低资源消耗。
2.2 cosocket
OpenResty中的核心技术cosocket将Lua协程和Nginx的事件机制结合在一起,最终实现了非阻塞网络IO。不仅和HTTP客户端之间的网络通信是非阻塞的,与MySQL、Memcached以及Redis等众多后端之间的网络通信也是非阻塞的。在OpenResty中调用一个cosocket相关的网络函数,内部关键实现如图所示:
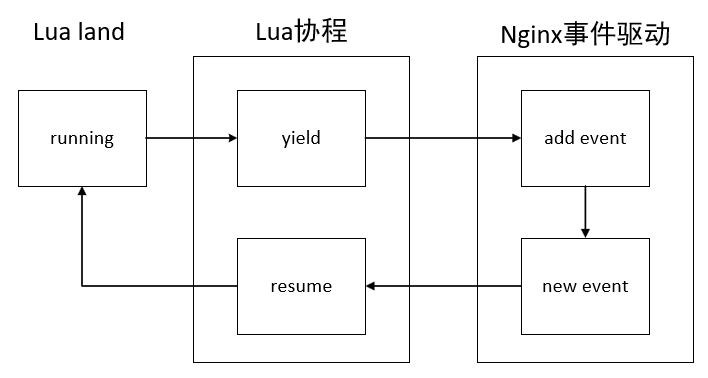
从图中可以看出,用户的Lua脚本每触发一个网络操作,都会有协程的yield和resume。当遇到网络IO时,Lua协程会交出控制权(yield),把网络事件注册到Nginx监听列表中,并把运行权限交给Nginx。当有Nginx注册网络事件到达触发条件时,便唤醒(resume)对应的协程继续处理。这样就可以实现全异步的Nginx机制,不会影响Nginx的高并发处理性能。
2.3 多阶段处理
基于Nginx使用的多模块设计思想,Nginx将HTTP请求的处理过程划分为多个阶段。这样可以使一个HTTP请求的处理过程由很多模块参与处理,每个模块只专注于一个独立而简单的功能处理,可以使性能更好、更稳定,同时拥有更好的扩展性。
OpenResty在HTTP处理阶段基础上分别在Rewrite/Access阶段、Content阶段、Log阶段注册了自己的handler,加上系统初始阶段master的两个阶段,共11个阶段为Lua脚本提供处理介入的能力。下图描述了OpenResty可以使用的主要阶段:
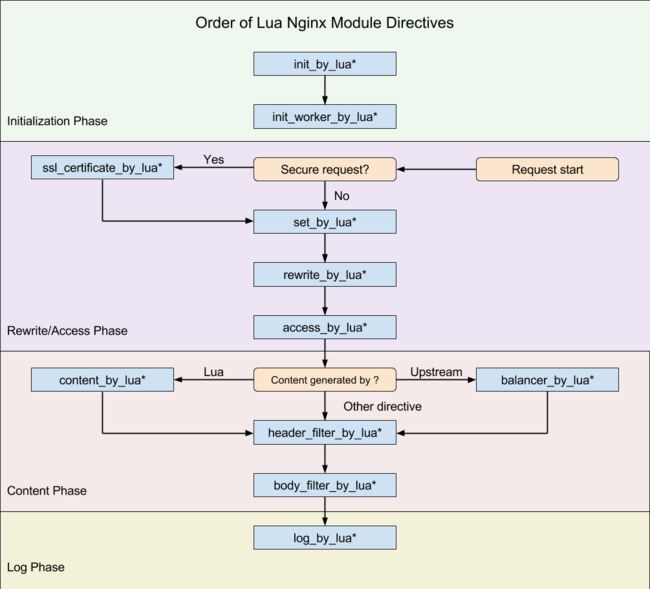
OpenResty将我们编写的Lua代码挂载到不同阶段进行处理,每个阶段分工明确,代码独立。
-
init_by_lua*:Master进程加载Nginx配置文件时运行,一般用来注册全局变量或者预加载Lua模块。
-
init_worker_by_lua*:每个worker进程启动时执行,通常用于定时拉取配置/数据或者进行后端服务的健康检查。
-
set_by_lua*:变量初始化。
-
rewrite_by_lua*:可以实现复杂的转发、重定向逻辑。
-
access_by_lua*:IP准入、接口权限等情况集中处理。
-
content_by_lua*:内容处理器,接收请求处理并输出响应。
-
header_filter_by_lua*:响应头部或者cookie处理
-
body_filter_by_lua*:对响应数据进行过滤,如截断或者替换
-
log_by_lua*:会话完成后,本地异步完成日志记录
2.4 性能对比
OpenResty基于高性能的Nginx,虽然在实现上采用了“小众”的开发语言Lua,但它的开发效率和运行效率都非常高效。下面,以一个简单的测试案例对比目前较为流行的Web开发环境:NodeJs、Java和Python。本次测试各自实现了一个输出“Hello World”的简单HTTP服务,测试工具使用ApacheBench,测试机为1核2G。
压测命令:ab –c 100 –n 10000 http://127.0.0.1:8000/hello
压测结果:
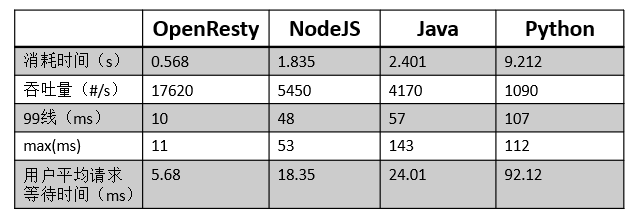
从压测结果中可以看出,OpenResty在各项指标上都更胜一筹。
聊完OpenResty的原理,我们结合自身的业务Jshop活动平台,介绍一下它的具体应用。
3.OpenResty应用
3.1 Jshop活动平台
Jshop活动平台是京东内部一个能够快速搭建店铺和专题活动的平台,帮助商家和运营对活动页面进行可视化装修,通过添加布局、模块来搭建页面。Jshop活动平台核心流程如下图所示:
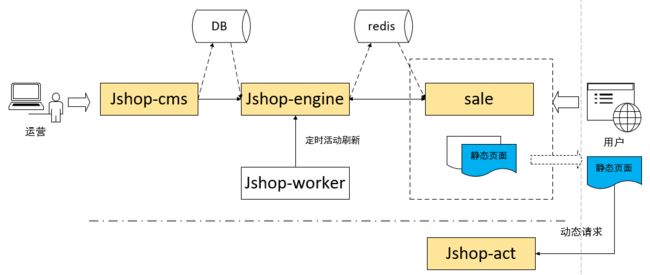
图中涉及到5个应用,分别是:
-
Jshop-cms:商家或运营使用cms系统完成活动页面的装修,除此之外,cms还提供了权限管理和数据魔方。
-
Jshop-engine:Jshop-engine是一个页面渲染引擎,将页面装修所使用的布局、模块和模板渲染成一个完整的静态页面,并将渲染后的页面推送到Redis进行存储。为了防止Redis不可用的情况,也向sale的服务集群推送一份。
-
Jshop-worker:主要是一些定时任务,如活动下线,页面定时渲染等。
-
sale:sale是基于OpenResty构建的Jshop的活动浏览系统,根据客户端请求URL中活动ID,返回对应的页面静态数据。
-
Jshop-act:客户端拿到页面静态数据后,会请求Jshop-act完成页面的动态呈现,例如页面的个性化数据模块、优惠券盖戳、定向投放等。
鉴于本文主要涉及活动浏览相关的内容,sale系统会是接下来我们讨论的重点,首先让我们看一下sale系统为什么采用OpenResty。
3.2 sale系统技术选型
sale系统主要面向的是C端用户,承载618和双11的大促活动流量,因此高并发、高性能和高可用是我们重点关注的内容。另外,sale系统实现的功能比较简单,核心逻辑就是根据用户请求的活动ID,返回对应的页面数据。我们最终选择基于OpenResty构建sale系统,主要是考虑到以下优势:
-
基于成熟的技术Nginx和Lua来搭建,降低入门门槛和学习成本。
-
依托于LuaJIT,执行效率更高。
-
非阻塞的访问网络IO。
-
OpenResty在内存使用率,CPU占用率等方面性能要更好。
-
有完备的缓存机制,不仅支持Redis、Memcached等外部缓存,也在自己的进程内有缓存系统。
-
同步的写代码逻辑,更加符合开发者的思维习惯,无需显式的处理异步回调,调试方便。
-
OpenResty工作在七层网络之上,依托于强大灵活的正则规则,可以针对HTTP应用的域名做一些分流和转发策略,既能做负载又能做反向代理。
3.3 sale部署架构
sale系统的部署架构如下图所示:
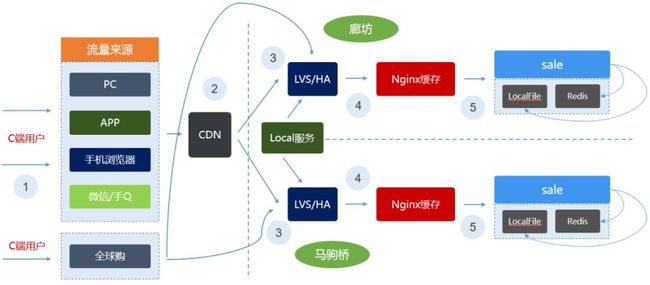
从图中可以看出,我们的请求来源于多个渠道,需要对多端进行适配。为了应对大促期间的流量,在请求到达sale之前还开启了CDN和Nginx缓存。sale系统默认采用的是本地磁盘文件和Redis的模式,Jshop-engine在执行完渲染页面任务后,会同时更新页面内容到Redis和本地磁盘上。这样就能保证极端情况下,Redis不可用时,sale系统依然可以通过本地文件的方式对外提供服务。
3.4 多级缓存
sale系统基于OpenResty实现了多级缓存,一般缓存的设计遵循以下两个原则:
-
缓存越靠近用户的请求越好。比如,能用本地缓存就不用发送HTTP请求,能用CDN缓存的就不要打到源站。所以在sale的部署架构中,我们启用了CDN缓存。
-
尽量使用本进程和本机的缓存。跨进程和机器甚至机房,缓存的网络开销就会非常大,这在高并发的时候会非常明显。
根据这两个原则,设计如下:
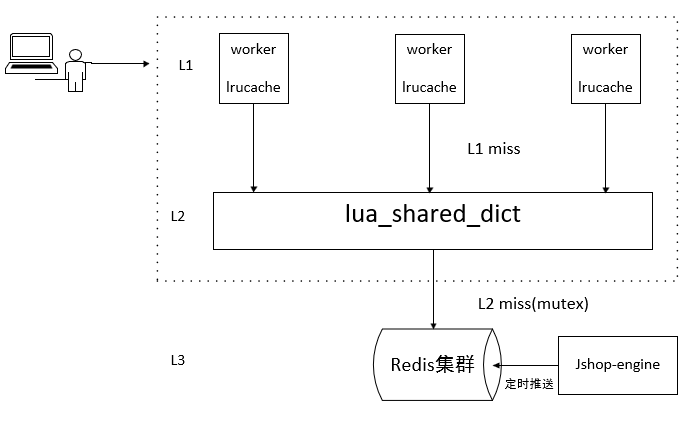
首先利用了lua-resty-lrucache实现了worker进程内的L1缓存,Nginx启用了多少个worker,就会有多少份缓存数据。由于worker独占的特性,不会触发锁,所以非常高效,缺点就是多份缓存占用了较多的内存。
lua_shared_dict实现了L2缓存,缓存的数据有且只有一份,所有的worker都共用这一份缓存数据。L1缓存没有命中的情况下,就会来查询L2缓存。它的内部使用了自旋锁来保证操作的原子性,因此在并发量非常高的时候,可能会存在一些性能问题。
L3缓存使用了Redis,在L2没有命中的情况下,通过回调函数去Redis查询后再缓存到L2中。为了避免缓存风暴,会使用lua-resty-lock来保证只有一个worker去数据源获取数据。如果L3缓存也没有命中,则意味着页面已经过期下线。从整个过程可以看出,缓存的更新是由客户端的请求来被动触发的。
4.总结
OpenResty是一个兼具开发效率和性能的服务端开发平台,虽然它基于Nginx去实现,但其适用范围早已远远超出了反向代理和负载均衡。目前,国内的很多公司都在特定的场景下使用OpenResty,大多用来处理入口流量,比如负载均衡、安全校验、降级、限流、缓存等。
虽然OpenResty是一个广泛应用的技术,但不是一个热门的技术。OpenResty理论上可以实现各种复杂的web应用,但Lua语言是一门小众的语言,不适合业务逻辑比较重的场景,适合一些轻量级的性能高的WEB服务。
参考资料:
OpenResty官网:https://openresty.org/cn/
OpenResty最佳实践:https://moonbingbing.gitbooks.io/openresty-best-practices/content/index.html