python可视化词云图WordCloud
一、WordCloud安装
首先打开命令提示符,输入“pip install wordcloud”安装词云包
问题① 安装包的位置
安装时非常顺利,但是在jupyter notebook里想要引入wordcloud时出现了问题:
——ModuleNotFoundError: No module named 'wordcloud'
也就是没有找到wordcloud这个包。
百度了一下说可能是因为安装路径为电脑默认路径,需要改在Python的安装目录下
这里记录一下检查Python安装路径的方式:
import sys
print(sys.executable)以及更改安装包路径的方式:
在系统中输入cmd命令:
Python安装路径 -m pip install wordcloud
不过这并没有解决我的问题,因为我的安装路径是正确的。在Python文件夹\Lib\site-package中查看,wordcloud待在正确的地方-_-||
后来看其它文章发现,我是在anaconda下打开的jupyter notebook,位置跟本地wordcloud安装包的默认路径不一样。文章里的具体解决方法是在anaconda目录下再下载对应的wordcloud包。
但我的anaconda装的乱七八糟的,根本找不到site-package文件夹,于是干脆在默认路径下重新安装了jupyter notebook。直接输入cmd命令:
pip install jupyter notebook
重新打开jupyter,输入cmd命令:
jupyter notebook
再次引入wordcloud时,就成功了。

二、打开文件
问题② 文件路径
直接打开文件是找不到的,因为并不在当前目录下,会出现下面的提示:
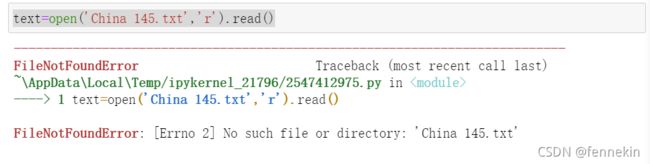
所以要更改目录。首先查看当前目录:
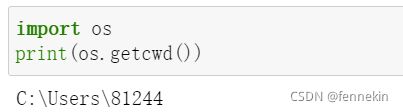
如果不清楚os库里面有什么可调用的函数,可以查看一下:

chdir函数就可以更改当前目录:
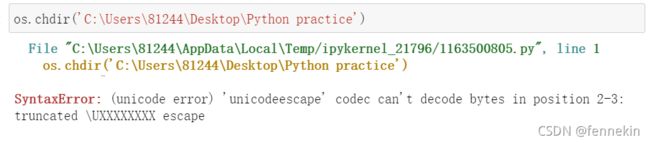
这里又报错,因为在Python的字符串里面\有转义的意思。
可以在前面加入r,来保持字符原始值(或者改成/正斜杠 \\双反斜杠都可以):

再查看一下当前目录:

修改好了,这样就可以找到文件了。
问题③ 文件解码
直接打开文件也是会出现问题的:
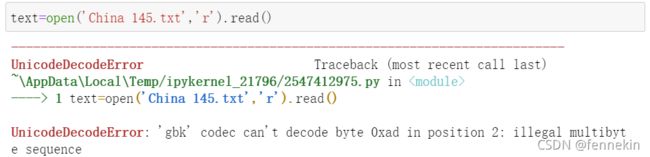
就是说这里面有汉字, 不能直接解码,需要改一下:

三、制作词云
先引入一下matplot库

问题④ 词云乱码
开始做词云:
这里记录一下plt.imshow(对象)和plt.show的区别:
前者负责对图像进行处理并显示其格式,后者是把处理后的图像显示出来
以及plt.axis('off')的意思是“关闭坐标轴”
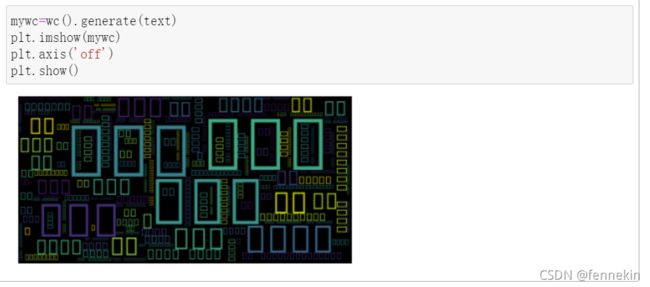
出现这样的情况是因为没有设置用来显示的字体,设置一下就好啦:

四、分词
首先跟wordcloud一样,先下好jieba安装包
问题⑤ with函数:
之前打开文件是用的读文件的模式,即
text=open('文件名称','r'),read
这个方法的问题是:如果文件不存在的话,open函数就会报错;而且文件使用完毕后要用close关闭文件,因为打开的文件会占用操作系统的资源,系统同一时间能打开的文件数量是有限的。
那如果文件读写时报错,后面的close函数就不能执行。所以为了无论是否出错都能正确关闭文件,可以使用try…finally来实现:
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()这样就有点麻烦,所以——
这次在打开用来分析的文本文档时,使用了with函数:

具体with函数的执行原理没看懂,但是
用with语句来操作文件的作用是:打开一个文件,如果一切正常则赋值为f,如果出现异常,该文件仍然会被关闭。
奈斯。
问题⑥ jieba分词

renmin就是要拿来分词的对象, cut_all是分词模式。cut_all=False的意思是精确模式,默认就是False。
1.精确模式是指将句子最精确地切开,适合文本分析:
例:今天天气真好 → 今天天气,真,好
2.cut_all=True可以开启全模式,这个模式能够把句中所有可以成词的词语都扫描出来,速度很快但可能有歧义:
例:今天天气真好 → 今天,今天天气,天天,天气,真好
3.还有一个搜索引擎模式,是在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词:
例:今天天气真好 → 今天,天天,天气,今天天气,真,好
后边就是把分出来的词遍历,放到字典里统计出现次数。
ps:还可以添加自定义词典
jieba.load_userdict('自定义词典.txt')
问题⑦ 分词筛选
如果有的话,可以打开写好的筛选词来筛
还有筛掉出现频数过少or单词长度太短等的词:

问题⑧ 词频排序
先把所有的分词和对应的词频提出来,放到列表里去,方便排序:

然后用自带的sort函数升序排列后逆序,得到需要的降序排列:

再重新建个字典把排好序的分词装进去:

问题⑨ 词云显示
基本跟前边差不多:

但是注意在生成的时候,这次是根据给定的词频制作词云,所以标灰的地方会跟之前有区别:
wc().generate(text)
↓
wc().generate_from_frequencies(text_jieba)
问题⑩ 词云美化
1.改变词云形状
可以用mask遮罩来改变

2.改变词云颜色
从原图中提取颜色

!这里有个尚未解决的问题!
按照说明,词云应当只会在遮罩图片的非透明部分作图,遮罩图片的白色部分会被自动视作透明。
我自己一开始准备了一张蓝色的中国地图,白底和透明底两版。


但是用这两张图做出来的词云依然是长方形


换了一张中国地图,还是不得行


所以我又换了其他的图片,这次就好了
类似的test×3:

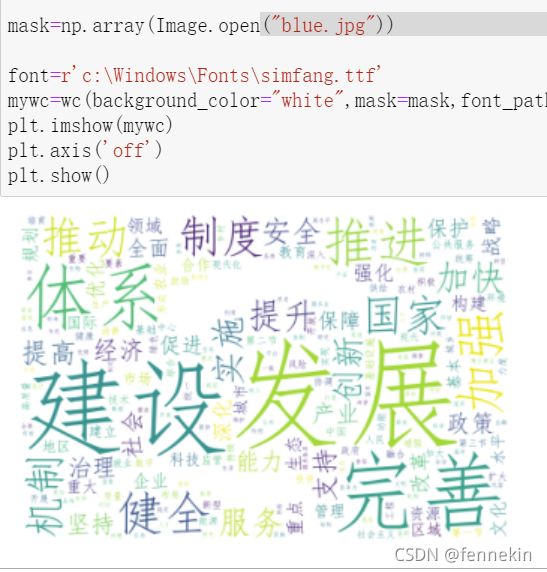
这样看起来有可能是颜色的问题?我重新试了两张蓝色的图片
test1:

test2:

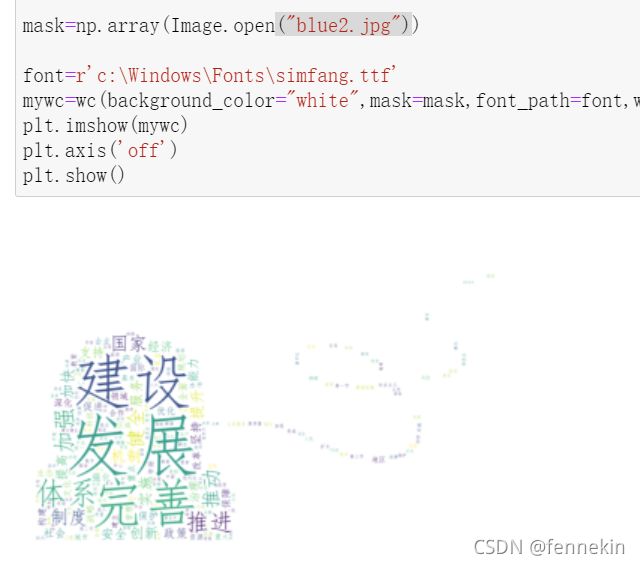
可以看到第一张出现了大面积的识别错误。第二张要好一些,只是阴影处有一点问题。
不过再次查找相关文章,说看上去是白色但不完全是白色的部分也会被识别到,可以解释过去。前面test那张图片底色是灰色,识别失败也可以解释了。
为了排除蓝色的影响,把blue这张图抠图后重新试验一遍:

还是出现识别错误。
最后用一张黄色的中国地图再排除一下其他因素
也成功做出了图:


就目前情况来看,很可能蓝色的图作为遮罩时容易出现错误。不过在网页上没看到相关说明。
目前还未找到解决方法。
目录
一、WordCloud安装
问题① 安装包的位置
二、打开文件
问题② 文件路径
问题③ 文件解码
三、制作词云
问题④ 词云乱码
四、分词
问题⑤ with函数:
问题⑥ jieba分词
问题⑦ 分词筛选
问题⑧ 词频排序
问题⑨ 词云显示
问题⑩ 词云美化
!这里有个尚未解决的问题!