Python数据可视化——词云图
任务:下载一本txt的电子书,对它分词、词频统计,生成电子书的词云图,作为这本书的概览理解
在数据可视化中,词云图是一个比较常用也比较简单的应用。就是将文件输入到程序中,利用中文/英文分词,提取出文本的关键词,根据词频提取每个关键词在这面文章里的重要性权重,在指定的图片中以不重叠的形式显示出来。例如:有一个十九届五中全会公报的文本和一个目标图案,要生成这则公报的词云图。


首先需要安装需要用到的包
系统里输入cmd 打开命令提示符

正常情况下应该是直接安装成功
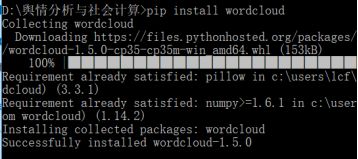
但是我的显然有问题,我也不太懂为啥
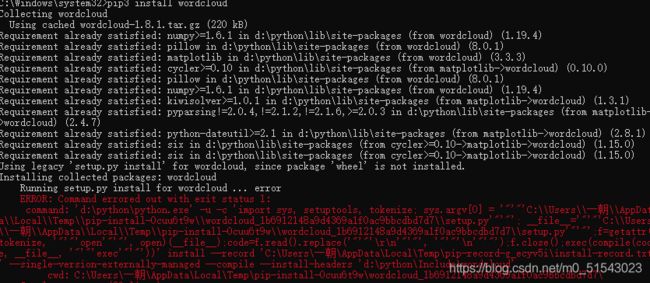
安装失败,中间出现ModuleNotFoundError: No module named ‘pip’
查了一下csdn 更新了pip版本还是不行
首先执行 python -m ensurepip 然后执行 python -m pip install --upgrade pip 即可更新完毕。
如下图所示

所以我决定下一下whl文件
打开whl下载地址
下载对应的whl文件后,在cmd下进入whl所在的文件夹
我之前一直以为cd是换目录结果没想到换不了,问了一下师哥,直接输d:就可以了
最后再输入pip install wordcloud-1.5.0-cp37-cp37m-win32.whl进行安装就可以了。
但是我发现我下的版本不对还是安装不了,因为我的是3.9那个Wordcloud-1.8.1-cp36就是3.6版本的,我决定下一下3.9再试一下
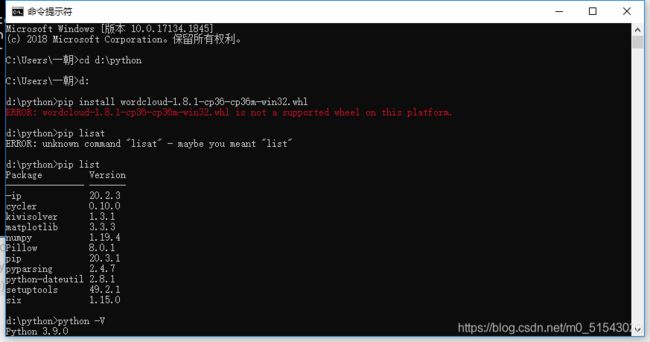
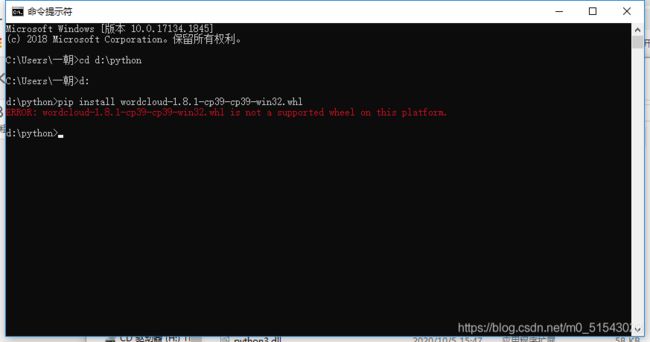
所以我求助了一下师哥,师哥说这个太麻烦了看看能不能不能直接pip install
先看第一个error:也就是说我需要安装一个ms V C++14.0
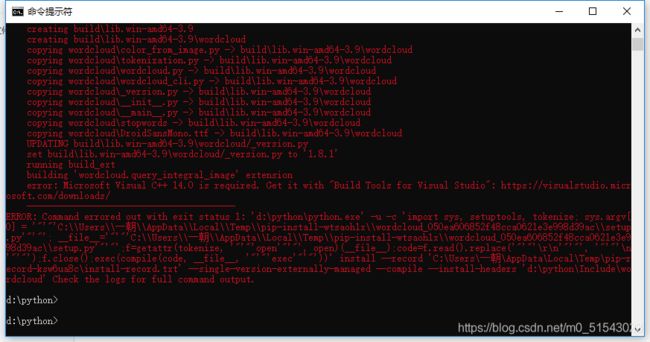
于是我又来csdn一下怎么安装ms V C++14.0
原来:在用pycharm过程中,用pip去安装一些第三方包的时候会出现如下错误,缺少C++编译器,因为有些程序需要使用,没有C++接口会报错,原文地址:Microsoft Visual C++ 14.0 is required解决方法
打开链接下载安装程序: Microsoft Visual C++ Build Tools 2015,双击visualcppbuildtools_full.exe,选择默认即可,点击安装,等待10分钟左右即可完成安装。
如果出现了.Net framework版本过低,小于4.5的最低版本要求:
[如果没出现这个问题,跳过这一步]
重新安装 .Net framework 更高的版本:
https://support.microsoft.com/en-us/help/3151800/the-net-framework-4-6-2-offline-installer-for-windows
再安装Microsoft visual c++ 14.0,
3. 启动电脑,再安装scrapy
pip install scrapy
- 准备代码hello_world.c
我新建了一个空白文本文档复制粘贴这段代码,用vs code 打开另存为.c格式
#include
int main()
{
printf("hello vs build tools.\n");
printf("press any key to exit.\n");
getchar();
return 0;
}
- 编译
1)在开始菜单中选择Visual C++ 2015 x86 Native Tools Command Prompt打开命令行,然后切换到hello_world.c所在目录。
2)执行:cl hello_world.c
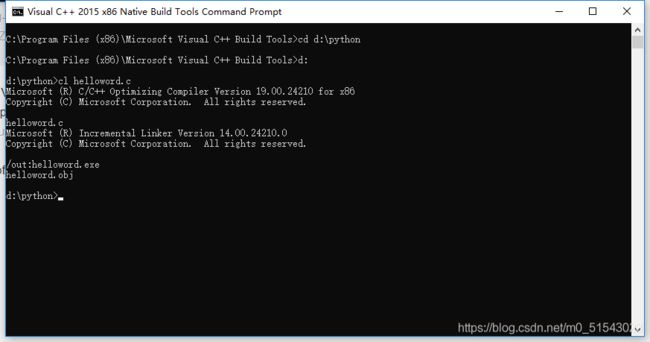
可看到生成两个文件,分别是hello_world.obj和hello_world.exe
- 测试
执行:.\hello_world.exe
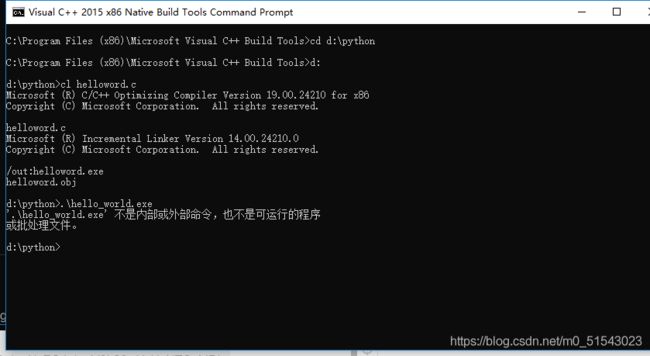
我的不行
或直接双击hello_world.exe执行。
这个应该是可以了,我又试了一下pip install wordcloud

呜呜呜终于好了,喵的搞了半下午
顺便下个beautifulsoup包,结果又出错了,吓我一跳,结果就是名字不对,换成bs4就可以了
终于到了正文部分了
import os
print(os.getcwd())
这个地方其实是为了方便我们看一下我们文件保存的地方,方便查找文件
![]()
/os是一个提供通用的、基本的操作系统交互功能的库,可以进行路径操作、进程管理、环境参数操作等。
常用的操作指令:
路径:
os.path.abspath() 返回当前系统中的绝对路径
os.path,normpath() 归一化path的表现形式
os.path.relpath() 返回当前程序与文件之间的相对路径 relative path
os,path.dirname() 返回path的目录
os.path.basename() 返回path最后的文件名称
os.path.join(path,paths) 组合path和paths返回一个路径字符串
os.path.exists() 判断path对应文件、目录是否存在 返回true 、false
os.path.isfile() 判断是否为已存在的文件 返回true 、false
os.path.isdir() 判断是否为已存在目录 返回true 、false
os.path.getatime() 返回上一次访问时间
os.path.getmtime() 返回上一次修改时间
os.path.getctime() 返回创建时间
os.path.getsize() 返回对应文件大小
进程管理:
os.system(command)
环境参数:
os.chdir() 修改当前和程序的操作路径
os.getcwd() 返回程序的当前路径
os.getlogin() 当前系统登录用户名
os.cpu_count() 当前系统的CPU数量
os.urandom(n) 获得n个字节长度的随机字符串,常用于加解密运算/
from wordcloud import WordCloud
/w=wordcloud.WordCloud(<参数>)
参数:
width
height
min_font_size 默认四号
max_font_size 默认根据高度自动调整
font_step 字体字号步进间隔 默认1
font_path 指定字体文件的路径 默认none
max_words 最大单词量 默认200
stop_words 停用词列表
mask 指定词云形状 默认长方形 需用imread()指定图片
from scipy.misc import imread
mk=imread(“picture.png”)
w=wordcloud.WordCloud(mask=mk)
background_color 背景颜色 默认black/
大家也可以看这个,原文来自于python数据可视化——词云
font_path : string //字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = ‘黑体.ttf’
width : int (default=400) //输出的画布宽度,默认为400像素
height : int (default=200) //输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) //词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
mask : nd-array or None (default=None) //如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread(‘读取一张图片.png’),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。
scale : float (default=1) //按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
min_font_size : int (default=4) //显示的最小的字体大小
font_step : int (default=1) //字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。
max_words : number (default=200) //要显示的词的最大个数
stopwords : set of strings or None //设置需要屏蔽的词,如果为空,则使用内置的STOPWORD
background_color : color value (default=”black”) //背景颜色,如background_color=‘white’,背景颜色为白色。
max_font_size : int or None (default=None) //显示的最大的字体大小
mode : string (default=”RGB”) //当参数为“RGBA”并且background_color不为空时,背景为透明。
relative_scaling : float (default=.5) //词频和字体大小的关联
color_func : callable, default=None //生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) //使用正则表达式分隔输入的文本
collocations : bool, default=True //是否包括两个词的搭配
colormap : string or matplotlib colormap, default=”viridis” //给每个单词随机分配颜色,若指定color_func,则忽略该方法。
import matplotlib.pyplot as plt
plt的教程可以参考官网的文档,说得很清楚:官网地址
text=open(‘会议公报.txt’,‘r’).read()
font=r’c:\Windows\Fonts\simfang.ttf’
wc=WordCloud().generate(text) /继承text传递到词云图中/
plt.imshow(wc) /显示结果/
plt.axis(‘off’) /关掉坐标轴显示/
plt.show()
wc.to_file(‘gb.jpg’)

出现了字体显示不出来的问题,我们回到系统的C:\WINDOWS\FONTS下 查找换一种字体试试,找到一个想要的字体右键点开属性看一下扩展名(这个地方容易出现区分大小写问题)
还是不行,这是因为我们没有指定中文字体,所以将代码有关于字体的部分改成:
font=r’c:\Windows\Fonts\simfang.ttf’ #raw string
wc=WordCloud(font_path=font,width=800,height=600).generate(text)

这样产生的词云图像样一点了,但是很明显这个词云图里的内容是随机的
我们现在想把它按照词频排一下序,让最重要的信息显示的最大
所以我们引入jieba库
import jieba
/*jieba是一个做中文分词的第三方库 cmd中pip install jieba 或者在pycharm的setting中找interpreter左下角有个加号,点开可以加载库
在Jieba工具中,可以在程序中动态修改词典,通过add_word(word, freq=None, tag=None)函数添加新词语,通过del_word(word)函数删除自定义词语,suggest_freq(segment, tune=True)函数调节单个词语的词频
隐马尔可夫模型(Hidden Markov Model, HMM)是一种基于概率的统计分析模型,用来描述一个系统隐性状态的转移和隐性状态的表现概率。到目前为止,HMM模型被认为是解决大多数自然语言处理问题最为快速、有效的方法之一。它成功解决了语义识别、机器翻译等问题。 在Jieba工具中,对于未登录到词库的词,使用了基于汉字成词能力的 HMM 模型和 Viterbi 算法,其大致原理是采用四个隐含状态,分别表示为单字成词、词组的开头、词组的中间和词组的结尾。通过标注好的分词训练集,可以得到 HMM的各个参数,然后使用 Viterbi 算法来解释测试集,得到分词结果。
jieba.cut : 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search : 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut 以及jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) : 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
词性标注(Part-Of-Speech Tagging, POS Tagging)也被称为语法标注(Grammatical Tagging)或词类消疑(Word-category Disambiguation),是将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术。通过词性标注处理,可以将分词得到的词序列中每个单词标注一个正确的词性。
在Jieba工具中,调用jieba.posseg.POSTokenizer(tokenizer=None)函数新建自定义分词器。tokenizer参数可指定内部使用的jieba.Tokenizer分词器,jieba.posseg.dt为默认词性标注分词器。Jieba工具采用和Ictclas 兼容的标记法,标注句子分词后每个词的词性通过循环输出。
具体可见:
https://blog.csdn.net/Yansky58685/article/details/104394074?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160743078019724847198500%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=160743078019724847198500&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-4-104394074.nonecase&utm_term=jieba.load_userdict&spm=1018.2118.3001.4449
*/
with open(‘gb.txt’, ‘r’) as f: /打开文件/
renmin = f.read()
jieba.load_userdict(‘gbDict.txt’)
/load_userdict(f)——该函数只有一个参数,表示载入的自定义词典路径,f 为文件类对象或自定义词典路径下的文件。词典的格式为:一个词占一行,每行分为三部分:word freq word_type
其中,word为对应的词语,freq为词频(可省略),word_type为词性(可省略),中间用空格隔开,顺序不可以改变。注意,文件必须为UTF-8编码。/
seg_list = jieba.cut(renmin, cut_all=False)
/jieba分为三种模式:
精确模式: jieba.lcut(s) 精确切分文本,不存在冗余单词 返回列表类型分词结果 默认模式
全模式: jieba.lcut(s,cut_all=True) 把所有可能的词语都扫描出来,存在冗余
搜索引擎模式:jieba.lcut_for_search(s) 在精确模式上对长词再次切分/
tf = {}
for seg in seg_list:
if seg in tf:
tf[seg] += 1
else:
tf[seg] = 1
ci = list(tf.keys())
/设定一个字典类型,键为词语本身,值为词出现的次数,产生的结果即为词频/
with open(‘stopword.txt’, ‘r’) as ft:
stopword = ft.read()
/设置停用词列表/
for seg in ci:
if tf[seg] < 5 or len(seg) < 2 or seg in stopword or “一” in seg:
tf.pop(seg)
/如果有的词出现的次数少于5,或者词本身是单字词,又或者字典的键里有停用词,尤其是词语里含有一的词语不容易列全,直接就把有这些情况的字典元素删掉/
print(tf)

现在更新我们的代码变成完整版
//
import os
print(os.getcwd())
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
text=open(‘C:\一朝\wordcloudstudy\会议公报.txt’,‘r’).read()
jieba.load_userdict(‘C:\一朝\wordcloudstudy\gbDict.txt’)
seg_list = jieba.cut(text, cut_all=False)
tf = {}
for seg in seg_list:
if seg in tf:
tf[seg] += 1
else:
tf[seg] = 1
ci = list(tf.keys())
with open(‘C:\一朝\wordcloudstudy\stopwords.txt’, ‘r’) as ft:
stopword = ft.read()
for seg in ci:
if tf[seg] < 5 or len(seg) < 2 or seg in stopword or “一” in seg:
tf.pop(seg)
font=r’c:\Windows\Fonts\simfang.ttf’ #raw string
wc=WordCloud(font_path=font,width=800,height=600).generate_from_frequencies(tf)
plt.imshow(wc)
plt.axis(‘off’)
plt.show()
wc.to_file(‘gb.jpg’)
//

这样就可以了,一个能看到重点的词云图就做好啦
但还是不满足,想要让它有个特殊的图形,再把背景颜色变成白色background_color=‘white’
from PIL import Image
import numpy as np
mask=np.array(Image.open(“C:\一朝\wordcloudstudy\pattern.jpg”))
但我想让它的颜色和原图相符就要提取颜色,从wordcloud引入一个图像颜色提取库ImageColorGenerator
from wordcloud import ImageColorGenerator
image_colors=ImageColorGenerator(mask)/图像颜色和遮罩颜色相同/
plt.imshow(wc.recolor(color_func=image_colors))/在显示颜色时将重新指定颜色为遮罩颜色/

这样目前我们提出的需求都完成啦~