EM最大期望算法
EM算法的具体含义在许多书本、网站上都有介绍,现在我用matlab实现了该算法的一个具体应用:混合高斯样本的参数估计(GMM),也就是说现在我们有许多的样本,也知道这些样本取自于多少的高斯分布,但是对于具体的一个样本属于哪种分布、以及每个高斯分布的均值、方差都不知道,而EM算法可以解决这个问题。
EM算法解决GMM问题的程序中有4个函数,前3个分别为CreateSample、calculate、EM,最后是演示函数EM_demo.
%----------------------------------函数1
function [data,weight,mu,sigma]=CreateSample(dim,M,N)
% % % 此代码用来生成满足高斯分布的样本数据
%输入:
% dim :每个样本用一列表示,每一列有dim维,比如我们想要一个2维的样本,可以写成(3,4)';
% M : 代码生成的所有样本均来自M个高斯分布函数
% N : 所有样本的数量
%输出
% data : 大小为dim*N, 表示总共生成了N列样本,每个样本为一列中的dim个数字
% weight :大小为1*M, 表示用来生成所有样本的M个高斯分布,每个高斯分布的权重,权重值越大生成的样本数越多
% mu :大小为dim*M, 这M个高斯分布的均值
% sigma :大小为1:M ,这M个高斯分布的均方差
%首先,按照随机方式生成M个高斯分布的权重、方差、均值
weight=rand(1,M);
weight=weight/norm(weight,1); %对权重进行归一化,保证权重之和等于1
sigma=double(randi(10,1,M)); %高斯分布的均方差在(1,10)之间选取
mu=double(round(randn(dim,M)*100)); %高斯分布的均值,正数或负数
%然后,按照上面权重weight的大小,确定这M个高斯分布包含的样本数量
n=zeros(1,M);
for i=1:1:M
if(i~=M)
n(i)=floor(N*weight(i));
else
n(i)=N-sum(n);
end
end
%最后,逐步构造每个高斯分布的n(i)个样本
data=[];
for i=1:1:M
X=randn(dim,n(i));
X=X.*sigma(i)+repmat(mu(:,i),1,n(i));
data=[X,data];
end
%--------------------------------函数2
function p=calculate(x,mu,sigma)
% % % 此函数在已知输入x、高斯分布的均值mu、方差sigma的情况下计算其高斯分布的输出
[dim,N]=size(x);
p=zeros(1,N);
for i=1:1:N
p(i)=1/(2*pi*abs(det(sigma)))^length((mu)/2)*exp(-0.5*(x(:,i)-mu)'*inv(sigma)*(x(:,i)-mu));
end
%---------------------------------函数3
function [Pw,mu,sigma]=EM(data,K)
% % % EM算法是建立在概率统计的基础上,对于样本data,我们已知这些数据满足K个高斯分布
%但是,这K个高斯分布的具体参数是不知道的
%所以,这个算法的工作就是从样本中来计算每个高斯分布的权重、均值、方差
% % % EM的主要步骤是:Expectation Maxcism
%Exp 的思路是:假设已知M个高斯分布的均值与方差、权重,然后根据已有的样本data,去估算每个样本属于哪一个高斯分布
%Max的思路是:假设已知所有样本data所属的高斯分布,然后由每个高斯分布包含的样本来计算此高斯分布的均值、方差、权重
%以上的Exp、Max步骤交替进行,直到找出最合适的高斯分布参数
[dim,Num]=size(data); %总共有Num个样本,每个样本为一列dim的向量
max_iter=1000;min_improve=0.001; %循环终止条件
%首先使用kmeans算法找到初始的高斯分布参数
[cluster,center]=kmeans(data',K); %cluster表示每个样本对应的聚类编号,center表示每个高斯分布的中心
cluster=cluster';
mu=center';
Pw=zeros(1,K); %存放每个高斯聚类的权重
sigma_cov=zeros(dim,dim,K); %存放M高斯分布中,每个维度之间的协方差
for j=1:1:K %依据上面的得到的每个样本的聚类编号统计出每个聚类的样本空间,计算出每个聚类的权重
gauss_labels=find(cluster==j);
Pw(j)=length(gauss_labels)/length(cluster);
sigma(:,:,j)=diag(std(data(:,gauss_labels),0,2)); %根据所有属于聚类j的样本 ,来计算第j各高斯分布的方差
end
%--------------------------------------------EM算法估计混合高斯分布的参数------------------------------------------------%
if K==1%当所有样本属于同一个高斯分布时
sigma(:,:,1)=sqrtm(cov(data',1));
mu(:,1)=mean(data,2);
else %当所有高斯分布来自不同的高斯分布时
sigma_i=squeeze(sigma(:,:,:));
for iter=1:1:max_iter
%%------------------------------------Exp步骤----------------------------------------%%
sigma_old=sigma_i;
for i=1:1:K
P(:,i)=Pw(i)*calculate(data,squeeze(mu(:,i)),squeeze(sigma_old(:,:,i)));
end
s=sum(P,2); %P的大小是Num*K,表示Num个样本属于K个高斯分布的概率
for j=1:Num
P(j,:)=P(j,:)/s(j);
end
%%-----------------------------------Max步骤-----------------------------------------%%
Pw(1:K)=1/Num*sum(P);%估计每个高斯分布的权重
for i=1:1:K %估计每个高斯分布的均值
sum1=0;
for j=1:1:Num
sum1=sum1+P(j,i).*data(:,j);
end
mu(:,i)=sum1./sum(P(:,i));
end
for i=1:1:K %估计每个高斯分布的方差
sum2=zeros(dim,dim);
for j=1:1:Num
sum2=sum2+P(j,i)*((data(:,j)-mu(:,i))*(data(:,j)-mu(:,i))');
end
sigma_i(:,:,i)=sum2./sum(P(:,i));
end
%判断是否满足终止条件
if((sum(sum(sum(abs(sigma_i-sigma_old))))
end
end
end
%----------------------------函数4
% % % 此代码用来演示EM算法
%首先在二维空间中生成若干个样本,他们来自已知的几种高斯分布
%然后只提供样本data和高斯分布的个数K,用EM算法来预测每个高斯分布的参数
[data,weight0,mu0,sigma0]=CreateSample(2,5,200);
%在二维空间中的5个高斯分布中生成200个数据
%每个高斯分布的真实参数为weight0/mu0/sigma0
[weight,mu,sigma]=EM(data,5);
%使用EM算法得到的高斯分布的参数
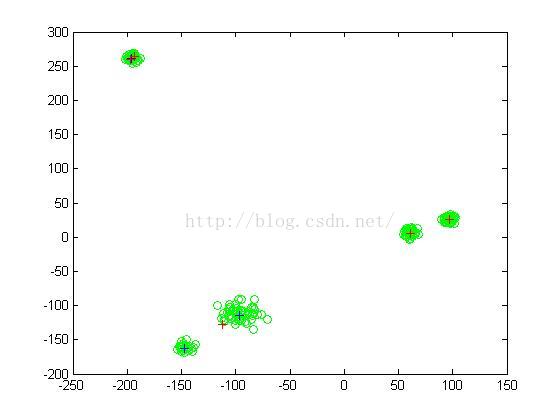
figure(1);clf
plot(data(1,:),data(2,:),'go'); %绘制原始的样本,用绿色圆圈表示
hold on
plot(mu0(1,:),mu0(2,:),'b+'); %绘制真实的K个高斯分布的中心,用蓝色十字表示
hold on
plot(mu(1,:),mu(2,:),'r+'); %绘制EM算法计算的高斯分布中心,用红色十字表示
hold off