NER中的一些编码器与解码器
文章目录
- 参考
- 编码
-
- LR-CNN
- FLAT
- Lex-BERT
- 解码
-
- GlobalPointer
本篇文章是命名实体识别(NER)算法的进一步介绍,主要内容是介绍一些编码器与解码器,作为上一篇内容的补充。
参考
中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT)
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
如何解决transformer对NER效果不佳的问题
1、Sinusoidal位置编码追根溯源
Lex-BERT:超越FLAT的中文NER模型?
中文实体识别最新SOTA算法Lex-Bert算法效果复现
编码
关于编码部分,我想更多的介绍一些中文编码的内容,我们知道中文都是对字进行编码的,如果能够将词汇信息加入到其中,能够提供更为丰富的信息。
对于bert而言,对于中文他是对字进行处理的,可以对句子进行分词,对分词的position进行编码,然后和bert输出的字向量concat,再接上解码器会增加一些效果。但是BERTBERT存在推断慢的问题,因此如果我们面对低延时的要求时,可能需要考虑一下其他的模型。比如在命名实体识别(NER)算法中我们介绍了Lattice LSTM就引入了词汇的信息。
Lattice LSTM中存在一些缺点:
- 计算性能低下,不能batch并行化。原因是每个字符之间的word cell数目不一致。
- 信息损失。只有以该字符为结尾的词汇信息,才会被融入到字符中,也就是说词汇的中间部分是无法获取词汇的表征的。比如:“南京市”,只有 “市” 才可以获取“南京市”的词汇信息,而“京”中不包含“南京市”的信息。而且,由于RNN的特性,采取BiLSTM时其前向和后向的词汇信息不能共享。
LR-CNN
CNN-Based Chinese NER with Lexicon Rethinking。

Lattice LSTM采取RNN结构,无法有效处理信息冲突问题,如上图所示,对于【州】和【长】都无法仅仅根据上文信息得到标签,对于这种冲突问题,我们需要利用全局信息解决。
LR-CNN的结构如下:

首先,有句子 C = { c 1 , c 2 , ⋯ , c M } C=\{c_1,c_2,\cdots,c_M\} C={ c1,c2,⋯,cM},其中的 c i c_i ci表示第 i i i个位置上通过字符embedding得到的结果。在此之上,建立 L L L层CNN层,每一层的感受野均为2,这样对第二层而言就提取了2-gram的特征(第一层为embedding层),且能推出在第 l l l层,得到的是l-gram的特征:

定义 w m l = { c m , ⋯ , c m + l − 1 } w_m^l=\{\ c_m,\cdots,c_{m+l-1}\} wml={ cm,⋯,cm+l−1},且根据(1)可知, C m l C_m^l Cml与 w m l w_m^l wml有关,使用attention将这两者结合起来,得到一个融合的信息:
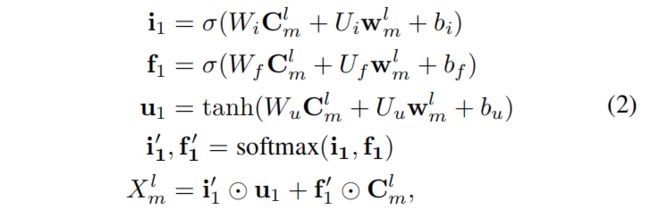
从而,我们可以得到最高层的表征为 X m L X_m^L XmL,这个表征我们可以认为包含尽可能多的全局信息,然后再用这个信息“feedback”给每一层CNN,调整词汇信息的权值,得到每一层新的信息(这一步主要是为了解决信息冲突的问题):
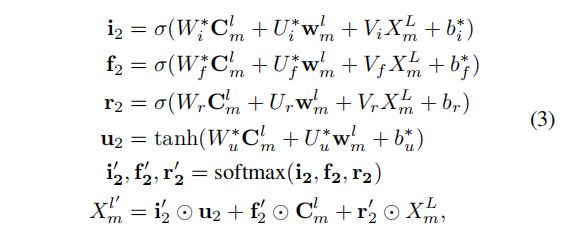
最后跟一个attention层:
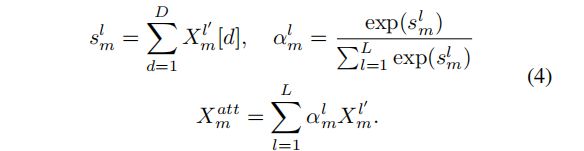
这个结果最终被喂到CRF去解码。
FLAT
Chinese NER Using Flat-Lattice Transformer

tips:
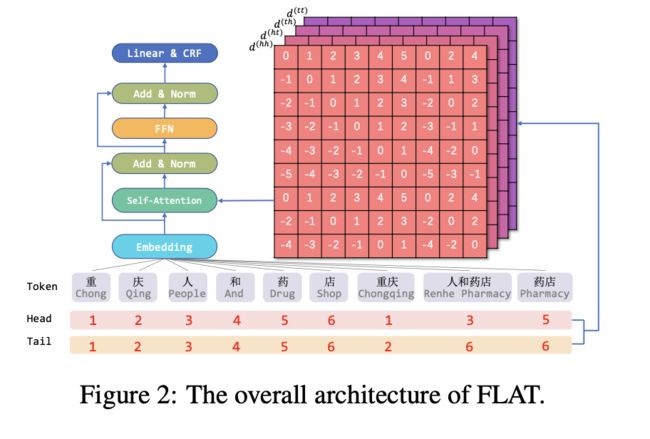
从上图可以看出,FLAT采用的是Transformer,而在之前的博客中提到Transformer不太适合做NER任务。参考如何解决transformer对NER效果不佳的问题 这篇文章。
这里我没太看懂,我的理解是transformer的attention部分是天然对称的,所以他提出了Sinusoidal位置编码 想要打破这种对称性,于是 f ( . . . x n , . . . . x m , . . . ) f(...x_n,....x_m,...) f(...xn,....xm,...)变成了: f ( . . . x n + p n , . . . . x m + p m , . . . ) f(...x_n+p_n,....x_m+p_m,...) f(...xn+pn,....xm+pm,...) 只要每个位置的编码不同,就不具备这种对称性了。
另外,如果我们做到内积部分,将query*key展开,有:
q i k j T = x i W Q W K T x j T + x i W Q W K T p j T + p i W Q W K T x j T + p i W Q W K T p j T {q}_i {k}_j^{T} = {x}_i {W}_Q {W}_K^{T}{x}_j^{T} + {x}_i {W}_Q {W}_K^{T}{p}_j^{T} + {p}_i {W}_Q {W}_K^{T}{x}_j^{T} + {p}_i {W}_Q {W}_K^{T}{p}_j^{T} qikjT=xiWQWKTxjT+xiWQWKTpjT+piWQWKTxjT+piWQWKTpjT
中间两项并没有被证明其对称性。
这一部分,有大神垂帘我一下私信我教教我么,谢谢。
FLAT设计了一种position encoding的方式融合Lattice结构,如上图所示,输入包括三个部分:token,head (position),tail (position);token可以是字符也可以是词,对于字符而言,head=tail,对于词而言,head
而且FLAT改变了原生Transformer位置编码的方式(Sinusoidal 绝对位置编码),而是提出一种新的相对位置编码(一般来说,对于自然语言更依赖相对位置,相对来说,相对位置比绝对位置有更优秀的表现)。
这里的相对距离定义为:

融合:

其中:

最终attention score的计算方式如下:

其有效的原因是:新的相对位置的encoding 有助于定位实体span,引入词汇的word embedding有利于实体type信息的分类。
Lex-BERT
论文原地址找不到了,实在是很奇怪,但是增加实体类型信息的方法可以借鉴一下。
Lex-BERT 引入了 高质量的带有实体类型信息的词表 (如果公司有这个词表的话我觉得可以试试这个方法)。

lex-bert 前提是拥有类型type信息的词汇表。论文作者给出两个版本的Lex-BERT:
- Lex-BERT V1: 将type信息的标识符嵌入到词汇前后;[v][/v] [d][/d]代表的是具体的实体类型。
- Lex-BERT V2: 将type信息的标识符拼接input后,然后与原始word起始的token共享相同的position embedding。

上图为Lex_BERT v2使用的attention mask矩阵。通过这个mask矩阵,可以使得文本token只与文本token做attend,标识符token可以attend所有的token。
论文给出的效果:

解码
GlobalPointer
该解码器是苏神提出的一种可以处理嵌套与非嵌套NER的解码器。更多内容可以参见GlobalPointer:用统一的方式处理嵌套和非嵌套NER

然后,在其中加入相对位置编码,能大幅提升性能:

最后利用将“softmax+交叉熵”推广到多标签分类问题中提到的损失函数,得到其损失为:

其代码链接为: https://github.com/bojone/GlobalPointer