鸽子学Python 之 Pandas数据分析库
本文来自鸽子学Python专栏系列文章,欢迎各位交流。
文章目录
- Pandas介绍
- 第一部分 Pandas基础
-
- 1 Pandas数据结构
-
- 1.1 Series
- 1.2 DataFrame
- 2 数据查看
- 3 数据输入与输出
-
- 3.1 CSV
- 3.2 EXCEL
- 3.3 HDF5
- 3.4 SQL
- 4 数据选取
-
- 4.1 获取数据
- 4.2 标签选择
- 4.3 位置选择
- 4.4 布尔值索引
- 4.5 赋值操作
- 5 数据集成
-
- 5.1 数据串联
- 5.2 数据插入
- 5.3 SQL风格合并
- 6 数据清洗
- 7 数据转换
-
- 7.1 轴和元素转换
- 7.2 map映射元素转变
- 7.3 apply映射元素转变
- 7.4 transform元素转变
- 7.5 重排随机抽样哑变量
- 8 数据重塑
- 第二部分 Pandas高级应用
-
- 1 数学和统计方法
-
- 1.1 简单统计指标
- 1.2 索引标签、位置获取
- 1.3 更多统计指标
- 1.4 高级统计指标
- 2 数据排序
- 3 分箱操作
- 4 分组聚合
-
- 4.1 分组
- 4.2 分组聚合
- 4.3 分组聚合:apply、transform方法
- 4.4 分组聚合:agg方法
- 4.5 分组聚合:透视表
- 5 时间序列
-
- 5.1 时间戳操作
- 5.2 时间戳索引
- 5.3 时间序列常用方法
-
- 5.3.1 数据移动
- 5.3.2 日期移动
- 5.3.3 频率转换
- 5.3.4 重采样
- 5.3.5 DataFrame重采样
- 总结
Pandas介绍
-
Pandas是python的一个数据分析包,最初被作为金融数据分析工具而开发出来。因此,Pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
-
Python在数据处理和准备方面⼀直做得很好,但在数据分析和建模方面就差⼀些。 Pandas帮助填补了这一空白,使您能够在Python中执行整个数据分析工作流程,而不必切换到更特定于领域的语言,如R。
-
与出色的jupyter工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力方面都是卓越的。
-
Pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。 是Python进行数据分析的必备高级⼯具。
-
处理数据⼀般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表, Pandas 是处理数据的理想⼯具。
-
安装Pandas库:在CMD中输入pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
第一部分 Pandas基础
1 Pandas数据结构
Pandas的主要数据结构是Series(⼀维数据)与 DataFrame (⼆维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数案例
1.1 Series
Series是一维的数组,和NumPy数组不一样:Series多了索引
#创建Series,注意Series严格区分大小写
l = np.array([1,2,3,6,9]) # NumPy数组
s1 = pd.Series(data = l) #Series
输出:
array([1, 2, 3, 6, 9]) # NumPy数组
# Series
0 1
1 2
2 3
3 6
4 9
dtype: int32
用数组生成Series,Pandas 默认自动生成整数索引,也可以指定索引 。
# 也可以指定索引创建
s2 = pd.Series(data = l,index = list('ABCDE'))
输出:
A 1
B 2
C 3
D 6
E 9
dtype: int32
也可以用字典创建索引。
# 字典创建
s3 = pd.Series(data = {
'A':149,'B':130,'C':118,'D':99,'E':66})
输出:
A 149
B 130
C 118
D 99
E 66
dtype: int64
1.2 DataFrame
Series是一维的,功能比较少,而DataFrame是由多种类型的列构成的⼆维标签数据结构,类似于 Excel 、SQL表,或者是Series对象构成的字典,多个Series公用索引,从而组成了DataFrame。
# 创建DataFrame,注意DataFrame严格区分大小写
df1 = pd.DataFrame(data = np.random.randint(0,151,size = (10,3)),
index = list('ABCDEFHIJK'), # 行索引
columns=['Python','Math','En'],dtype=np.float16) # 列索引
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 114.0 | 3.0 | 114.0 |
| B | 36.0 | 119.0 | 118.0 |
| C | 66.0 | 85.0 | 18.0 |
| D | 136.0 | 96.0 | 92.0 |
| E | 39.0 | 132.0 | 29.0 |
| F | 104.0 | 89.0 | 32.0 |
| H | 70.0 | 55.0 | 146.0 |
| I | 30.0 | 23.0 | 103.0 |
| J | 38.0 | 18.0 | 103.0 |
| K | 36.0 | 9.0 | 104.0 |
# 字典,key作为列索引,不指定index默认从0开始索引,自动索引一样
df2 = pd.DataFrame(data = {
'Python':[66,99,128],'Math':[88,65,137],'En':[100,121,45]})
输出:
| Python | Math | En | |
|---|---|---|---|
| 0 | 66 | 88 | 100 |
| 1 | 99 | 65 | 121 |
| 2 | 128 | 137 | 45 |
Tips:无论是Numpy中的NaN还是Python中的None在Pandas中都以缺失数据NaN对待 。
2 数据查看
下面是查看Pandas数据的几种方法:
# 数据准备:
df = pd.DataFrame(data = np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
输出:
| Python | Math | En | |
|---|---|---|---|
| 0 | 146 | 120 | 10 |
| 1 | 130 | 120 | 117 |
| 2 | 68 | 101 | 78 |
| 3 | 63 | 2 | 125 |
| 4 | 42 | 137 | 65 |
| ... | ... | ... | ... |
| 95 | 56 | 38 | 68 |
| 96 | 37 | 97 | 135 |
| 97 | 128 | 73 | 96 |
| 98 | 58 | 102 | 71 |
| 99 | 37 | 97 | 74 |
# 查看DataFrame形状
df.shape
输出:(100行,3列)
(100, 3)
# 显示前N行数据,默认N = 5
df.head(n = 3)
输出:
| Python | Math | En | |
|---|---|---|---|
| 0 | 146 | 120 | 10 |
| 1 | 130 | 120 | 117 |
| 2 | 68 | 101 | 78 |
# 显示后N行
df.tail()
输出:
| Python | Math | En | |
|---|---|---|---|
| 95 | 56 | 38 | 68 |
| 96 | 37 | 97 | 135 |
| 97 | 128 | 73 | 96 |
| 98 | 58 | 102 | 71 |
| 99 | 37 | 97 | 74 |
# 查看数据类型
df.dtypes
输出:
Python int32
Math int32
En int32
dtype: object
# 显示详细信息
df.info()
输出:
RangeIndex: 100 entries, 0 to 99
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Python 100 non-null int32
1 Math 100 non-null int32
2 En 100 non-null int32
dtypes: int32(3)
memory usage: 1.3 KB
# 查看描述性统计指标:
# 平均值、标准差、中位数、四等分、最大值,最小值
df.describe()
输出:
| Python | Math | En | |
|---|---|---|---|
| count | 100.000000 | 100.000000 | 100.000000 |
| mean | 74.650000 | 70.850000 | 70.950000 |
| std | 40.278669 | 38.551389 | 40.276412 |
| min | 0.000000 | 2.000000 | 0.000000 |
| 25% | 40.000000 | 39.000000 | 42.000000 |
| 50% | 72.500000 | 69.000000 | 74.000000 |
| 75% | 108.750000 | 100.250000 | 97.500000 |
| max | 148.000000 | 150.000000 | 149.000000 |
# 查看值,返回的是NumPy数组
df.values
输出:
array([[146, 120, 10],
[130, 120, 117],
[ 68, 101, 78],
[ 63, 2, 125],
[ 42, 137, 65],
[ 32, 76, 59],
[ 10, 150, 11],
[ 73, 26, 56],
[ 73, 58, 76],
...
[ 65, 118, 144],
[ 37, 130, 135],
[ 56, 38, 68],
[ 37, 97, 135],
[128, 73, 96],
[ 58, 102, 71],
[ 37, 97, 74]])
# 查看列索引
df.columns
输出:
Index(['Python', 'Math', 'En'], dtype='object')
# 查看行索引
df.index
输出:
RangeIndex(start=0, stop=100, step=1)
3 数据输入与输出
3.1 CSV
将Pandas保存为CSV文件以及读取CSV文件:
# 数据准备
df = pd.DataFrame(data = np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
# 输出df为CSV文件
df.to_csv('./data.csv',sep = ',',
index = True, # 保存行索引
header=True) # 保存列索引
# 输出df为CSV文件,不保存表头
df.to_csv('./data2.csv',sep = ',',
index = False, # 不保存行索引
header=False) # 不保存列索引
# 读取CSV文件
pd.read_csv('./data.csv',
index_col=0) # 第一列作为行索引
# 读取CSV文件,无表头
pd.read_csv('./data2.csv',header =None) # 列索引为空
3.2 EXCEL
存取EXCEL文件需要安装下面的库:
- pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
- pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
存取EXCEL文件数据:
# 输出df为EXCEL文件
df.to_excel('./data.xls')
# 读取EXCEL文件
pd.read_excel('./data.xls',
index_col=0) # 第一列作为行索引
3.3 HDF5
存取HDF5文件需要安装下面的库:
- pip install tables -i https://pypi.tuna.tsinghua.edu.cn/simple
HDF5是一个独特的技术套件,可以管理非常大和复杂的数据收集,它可以存储不同类型数据的文件格式,后缀通常是.h5,它的结构是层次性的。⼀个HDF5文件可以被看作是一个包含了各类不同的数据集。具体就不叙述了,有需要的可以自行百度。
# 输出df为HDF5文件,KEY为score
df.to_hdf('./data.h5',key = 'score')
# 准备数据
df2 = pd.DataFrame(data = np.random.randint(6,100,size = (1000,5)),
columns=['计算机','化工','生物','工程','教师'])
# 输出df为HDF5文件,KEY为salaryy
df2.to_hdf('./data.h5',key = 'salary')
# 读取hdf文件
pd.read_hdf('./data.h5',key = 'salary')
3.4 SQL
构建SQL连接需要安装两个库:
- pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
- pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
# 数据库引擎,构建和数据库的连接
from sqlalchemy import create_engine
# 连接本地数据库
engine = create_engine('mysql+pymysql://root:12345678@localhost/pandas?charset=utf8')
# pymysql://root:12345678@localhost/pandas?charset=utf8'类似网页地址
# root是用户名,12345678是密码,pandas是数据库名
# 将Python中数据DataFrame保存到Mysql
df2.to_sql('salary',engine,index=False)
# salary是表名,engine是上面的连接名
# 直接使用select语句从MYSQL中读取数据
df3 = pd.read_sql('select * from salary limit 50',con = engine)
4 数据选取
4.1 获取数据
获取N列数据的方法:
# 准备数据
df = pd.DataFrame(np.random.randint(0,151,size = (10,3)),
index=list('ABCDEFHIJK'),columns=['Python','Math','En'])
df['Python'] # 获取单列数据,Series格式
输出:
A 132
B 62
C 1
D 72
E 20
F 20
H 46
I 10
J 135
K 67
Name: Python, dtype: int32
# 也引用对象属性,效果同上
df.Python # DataFrame中的列索引表示属性
输出:
A 132
B 62
C 1
D 72
E 20
F 20
H 46
I 10
J 135
K 67
Name: Python, dtype: int32
TIPS:DataFrame中,列索引表示属性,行索引表示索引。
# 获取多列数据
df[['Python','En']]
输出:
| Python | En | |
|---|---|---|
| A | 132 | 9 |
| B | 62 | 56 |
| C | 1 | 5 |
| D | 72 | 5 |
| E | 20 | 147 |
| F | 20 | 46 |
| H | 46 | 111 |
| I | 10 | 118 |
| J | 135 | 15 |
| K | 67 | 88 |
4.2 标签选择
标签就是DataFrame中的行索引
# loc = location 位置
df.loc['A'] # 选择单行
输出:
Python 132
Math 46
En 9
Name: A, dtype: int32
# 选择多行
df.loc[['A','F','K']]
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 132 | 46 | 9 |
| F | 20 | 97 | 46 |
| K | 67 | 64 | 88 |
# 选择指定值
df.loc['A','Python']
输出:
132
# 选择多行单列
df.loc[['A','C','F'],'Python']
输出:
A 132
C 1
F 20
Name: Python, dtype: int32
# 也可以用切片的方法获取
df.loc['A'::2,['Math','En']]
输出:
| Math | En | |
|---|---|---|
| A | 46 | 9 |
| C | 11 | 5 |
| E | 26 | 147 |
| H | 121 | 111 |
| J | 103 | 15 |
# 切片方法
df.loc['A':'D',:]
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 132 | 46 | 9 |
| B | 62 | 29 | 56 |
| C | 1 | 11 | 5 |
| D | 72 | 11 | 5 |
TIPS:loc方法的取值范围都是闭区间,与平时不一致。
4.3 位置选择
loc方法和iloc方法的区别:loc是给标签名,iloc是给位置索引
df.iloc[0] # 返回第1行数据
输出:
Python 132
Math 46
En 9
Name: A, dtype: int32
df.iloc[[0,2,4]] # 返回第1,3,5行数据
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 132 | 46 | 9 |
| C | 1 | 11 | 5 |
| E | 20 | 26 | 147 |
# 切片方法同样可行
df.iloc[0:4,[0,2]]
输出:
| Python | En | |
|---|---|---|
| A | 132 | 9 |
| B | 62 | 56 |
| C | 1 | 5 |
| D | 72 | 5 |
df.iloc[3:8:2] # 也可以设置步长
输出:
| Python | Math | En | |
|---|---|---|---|
| D | 72 | 11 | 5 |
| F | 20 | 97 | 46 |
| I | 10 | 43 | 118 |
4.4 布尔值索引
# 将Python大于80分的成绩获取
cond = df.Python > 80
df[cond] # 根据判断条件查看数据
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 132 | 46 | 9 |
| J | 135 | 103 | 15 |
# 筛选平均分大于75的人
cond = df.mean(axis = 1) > 75
df[cond]
输出:
| Python | Math | En | |
|---|---|---|---|
| H | 46 | 121 | 111 |
| J | 135 | 103 | 15 |
# 筛选Python和数学大于70的人
cond = (df.Python > 70) & (df.Math > 70)
df[cond]
输出:
| Python | Math | En | |
|---|---|---|---|
| J | 135 | 103 | 15 |
cond = df.index.isin(['C','E','H','K']) # 判断数据是否在数组中
df[cond]
输出:
| Python | Math | En | |
|---|---|---|---|
| C | 1 | 11 | 5 |
| E | 20 | 26 | 147 |
| H | 46 | 121 | 111 |
| K | 67 | 64 | 88 |
4.5 赋值操作
df['Python']['A'] = 150 # 修改某个位置的值
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 150 | 46 | 9 |
| B | 62 | 29 | 56 |
| C | 1 | 11 | 5 |
| D | 72 | 11 | 5 |
| E | 20 | 26 | 147 |
| F | 20 | 97 | 46 |
| H | 46 | 121 | 111 |
| I | 10 | 43 | 118 |
| J | 135 | 103 | 15 |
| K | 67 | 64 | 88 |
df['Java'] = np.random.randint(0,151,size = 10) # 新增加一列
输出:
| Python | Math | En | Java | |
|---|---|---|---|---|
| A | 150 | 46 | 9 | 108 |
| B | 62 | 29 | 56 | 98 |
| C | 1 | 11 | 5 | 40 |
| D | 72 | 11 | 5 | 51 |
| E | 20 | 26 | 147 | 113 |
| F | 20 | 97 | 46 | 127 |
| H | 46 | 121 | 111 | 43 |
| I | 10 | 43 | 118 | 52 |
| J | 135 | 103 | 15 | 76 |
| K | 67 | 64 | 88 | 36 |
df.loc[['C','D','E'],'Math'] = 147 # 修改多个人的成绩
输出:
| Python | Math | En | Java | |
|---|---|---|---|---|
| A | 150 | 46 | 9 | 108 |
| B | 62 | 29 | 56 | 98 |
| C | 1 | 147 | 5 | 40 |
| D | 72 | 147 | 5 | 51 |
| E | 20 | 147 | 147 | 113 |
| F | 20 | 97 | 46 | 127 |
| H | 46 | 121 | 111 | 43 |
| I | 10 | 43 | 118 | 52 |
| J | 135 | 103 | 15 | 76 |
| K | 67 | 64 | 88 | 36 |
cond = df < 60
df[cond] = 60 # where条件操作,修改符合条件的值,不符合则不改变
输出:
| Python | Math | En | Java | |
|---|---|---|---|---|
| A | 150 | 60 | 60 | 108 |
| B | 62 | 60 | 60 | 98 |
| C | 60 | 147 | 60 | 60 |
| D | 72 | 147 | 60 | 60 |
| E | 60 | 147 | 147 | 113 |
| F | 60 | 97 | 60 | 127 |
| H | 60 | 121 | 111 | 60 |
| I | 60 | 60 | 118 | 60 |
| J | 135 | 103 | 60 | 76 |
| K | 67 | 64 | 88 | 60 |
# 同样可以用切片方法
df.iloc[3::3,[0,2]] += 100
输出:
| Python | Math | En | Java | |
|---|---|---|---|---|
| A | 150 | 60 | 60 | 108 |
| B | 62 | 60 | 60 | 98 |
| C | 60 | 147 | 60 | 60 |
| D | 172 | 147 | 160 | 60 |
| E | 60 | 147 | 147 | 113 |
| F | 60 | 97 | 60 | 127 |
| H | 160 | 121 | 211 | 60 |
| I | 60 | 60 | 118 | 60 |
| J | 135 | 103 | 60 | 76 |
| K | 167 | 64 | 188 | 60 |
5 数据集成
5.1 数据串联
# 数据准备
df1 = pd.DataFrame(np.random.randint(0,151,size = (10,3)),
columns=['Python','Math','En'],
index = list('ABCDEFHIJK'))
df2 = pd.DataFrame(np.random.randint(0,151,size = (10,3)),
columns = ['Python','Math','En'],
index = list('QWRTUYOPLM'))
df3 = pd.DataFrame(np.random.randint(0,151,size = (10,2)),
columns=['Java','Chinese'],index = list('ABCDEFHIJK'))
pd.concat([df1,df2],axis = 0) # axis = 0 表示行合并
pd.concat([df1,df3],axis = 1) # axis = 1 表示列合并
df1.append(df2) # append追加,在行后面直接进行追加
# 输出数据较多此处省略
df1.append(df3) # 出现空数据,原因在于:df1的列索引和df3列索引不一致
pd.concat([df1,df3],axis = 0) # 效果同上
输出:
| Chinese | En | Java | Math | Python | |
|---|---|---|---|---|---|
| A | NaN | 25.0 | NaN | 69.0 | 81.0 |
| B | NaN | 81.0 | NaN | 21.0 | 121.0 |
| C | NaN | 78.0 | NaN | 46.0 | 34.0 |
| D | NaN | 20.0 | NaN | 130.0 | 149.0 |
| E | NaN | 54.0 | NaN | 125.0 | 41.0 |
| F | NaN | 51.0 | NaN | 96.0 | 37.0 |
| H | NaN | 51.0 | NaN | 109.0 | 58.0 |
| I | NaN | 96.0 | NaN | 98.0 | 110.0 |
| J | NaN | 149.0 | NaN | 40.0 | 101.0 |
| K | NaN | 131.0 | NaN | 48.0 | 147.0 |
| A | 64.0 | NaN | 139.0 | NaN | NaN |
| B | 34.0 | NaN | 79.0 | NaN | NaN |
| C | 53.0 | NaN | 56.0 | NaN | NaN |
| D | 133.0 | NaN | 41.0 | NaN | NaN |
| E | 45.0 | NaN | 6.0 | NaN | NaN |
| F | 116.0 | NaN | 141.0 | NaN | NaN |
| H | 69.0 | NaN | 106.0 | NaN | NaN |
| I | 129.0 | NaN | 102.0 | NaN | NaN |
| J | 73.0 | NaN | 138.0 | NaN | NaN |
| K | 2.0 | NaN | 74.0 | NaN | NaN |
5.2 数据插入
df1 # 原数据
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 81 | 69 | 25 |
| B | 121 | 21 | 81 |
| C | 34 | 46 | 78 |
| D | 149 | 130 | 20 |
| E | 41 | 125 | 54 |
| F | 37 | 96 | 51 |
| H | 58 | 109 | 51 |
| I | 110 | 98 | 96 |
| J | 101 | 40 | 149 |
| K | 147 | 48 | 131 |
# 用Insert方法插入数据
df1.insert(loc = 1, # 插入位置
column='C++', # 插入列的名字
value = np.random.randint(0,151,size = 10)) # 插入列的值
输出:
| Python | C++ | Math | En | |
|---|---|---|---|---|
| A | 81 | 78 | 69 | 25 |
| B | 121 | 98 | 21 | 81 |
| C | 34 | 94 | 46 | 78 |
| D | 149 | 149 | 130 | 20 |
| E | 41 | 31 | 125 | 54 |
| F | 37 | 144 | 96 | 51 |
| H | 58 | 52 | 109 | 51 |
| I | 110 | 139 | 98 | 96 |
| J | 101 | 148 | 40 | 149 |
| K | 147 | 65 | 48 | 131 |
5.3 SQL风格合并
df1 = pd.DataFrame(data = {
'name':['softpo','Brandon','Ella','Daniel','张三'],
'height':[175,180,169,177,168]}) # 身高
df2 = pd.DataFrame(data = {
'name':['softpo','Brandon','Ella','Daniel','李四'],
'weight':[70,65,74,63,88]}) # 体重
df3 = pd.DataFrame(data = {
'名字':['softpo','Brandon','Ella','Daniel','张三'],
'salary':np.random.randint(20,100,size = 5)}) # 薪水
display(df1,df2,df3)
输出:
df1:
| name | height | |
|---|---|---|
| 0 | softpo | 175 |
| 1 | Brandon | 180 |
| 2 | Ella | 169 |
| 3 | Daniel | 177 |
| 4 | 张三 | 168 |
| name | weight | |
|---|---|---|
| 0 | softpo | 70 |
| 1 | Brandon | 65 |
| 2 | Ella | 74 |
| 3 | Daniel | 63 |
| 4 | 李四 | 88 |
| 名字 | salary | |
|---|---|---|
| 0 | softpo | 22 |
| 1 | Brandon | 83 |
| 2 | Ella | 92 |
| 3 | Daniel | 50 |
| 4 | 张三 | 27 |
# 使用concat合并
pd.concat([df1,df2],axis = 1)
输出:(可以看出,concat不会根据共同的属性合并数据,只会根据行标签添加列)
| name | height | name | weight | |
|---|---|---|---|---|
| 0 | softpo | 175 | softpo | 70 |
| 1 | Brandon | 180 | Brandon | 65 |
| 2 | Ella | 169 | Ella | 74 |
| 3 | Daniel | 177 | Daniel | 63 |
| 4 | 张三 | 168 | 李四 | 88 |
使用merge进行SQL风格的合并:
# 根据共同的属性,合并数据。df1和df2共同属性是name
pd.merge(df1,df2,how = 'inner') # inner内合并
输出:
| name | height | weight | |
|---|---|---|---|
| 0 | softpo | 175 | 70 |
| 1 | Brandon | 180 | 65 |
| 2 | Ella | 169 | 74 |
| 3 | Daniel | 177 | 63 |
# 外合并,所有数据保留,填充了空数据
pd.merge(df1,df2,how = 'outer') # outer外合并
输出:
| name | height | weight | |
|---|---|---|---|
| 0 | softpo | 175.0 | 70.0 |
| 1 | Brandon | 180.0 | 65.0 |
| 2 | Ella | 169.0 | 74.0 |
| 3 | Daniel | 177.0 | 63.0 |
| 4 | 张三 | 168.0 | NaN |
| 5 | 李四 | NaN | 88.0 |
# 左合并,保留左边的Name
pd.merge(df1,df2,how = 'left') # left左合并
输出:
| name | height | weight | |
|---|---|---|---|
| 0 | softpo | 175 | 70.0 |
| 1 | Brandon | 180 | 65.0 |
| 2 | Ella | 169 | 74.0 |
| 3 | Daniel | 177 | 63.0 |
| 4 | 张三 | 168 | NaN |
# 不一样的列名,则可以通过指定关键字来合并
pd.merge(df1,df3,left_on='name',right_on='名字') # 默认是内合并
输出:
| name | height | 名字 | salary | |
|---|---|---|---|---|
| 0 | softpo | 175 | softpo | 22 |
| 1 | Brandon | 180 | Brandon | 83 |
| 2 | Ella | 169 | Ella | 92 |
| 3 | Daniel | 177 | Daniel | 50 |
| 4 | 张三 | 168 | 张三 | 27 |
下面我们来看看根据行索引的merge合并
# 数据准备
df4 = pd.DataFrame(data = np.random.randint(0,151,size = (10,3)),
columns=['Python','Math','En'],index = list('ABCDEFHIJK'))
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 129 | 77 | 50 |
| B | 89 | 13 | 146 |
| C | 52 | 39 | 32 |
| D | 69 | 2 | 39 |
| E | 15 | 78 | 50 |
| F | 74 | 150 | 66 |
| H | 129 | 4 | 84 |
| I | 90 | 139 | 149 |
| J | 96 | 55 | 38 |
| K | 84 | 67 | 52 |
score_mean = df4.mean(axis = 1).round(1) # 计算平均分
score_mean.name = '平均分' # 要给列名才能合并
输出:
A 85.3
B 82.7
C 41.0
D 36.7
E 47.7
F 96.7
H 72.3
I 126.0
J 63.0
K 67.7
Name: 平均分, dtype: float64
pd.merge(df5,score_mean,
left_index=True, # 表明左边数据根据行索引合并
right_index=True) # 右边数据也根据行索引合并
输出:
| Python | Math | En | 平均分 | |
|---|---|---|---|---|
| A | 129 | 77 | 50 | 85.3 |
| B | 89 | 13 | 146 | 82.7 |
| C | 52 | 39 | 32 | 41.0 |
| D | 69 | 2 | 39 | 36.7 |
| E | 15 | 78 | 50 | 47.7 |
| F | 74 | 150 | 66 | 96.7 |
| H | 129 | 4 | 84 | 72.3 |
| I | 90 | 139 | 149 | 126.0 |
| J | 96 | 55 | 38 | 63.0 |
| K | 84 | 67 | 52 | 67.7 |
6 数据清洗
# 数据准备
df = pd.DataFrame(data = {
'color':['red','blue','red','green','green','blue',None,np.NaN,'green'],
'price':[20,15,20,18,18,22,30,30,22]})
输出:
| color | price | |
|---|---|---|
| 0 | red | 20 |
| 1 | blue | 15 |
| 2 | red | 20 |
| 3 | green | 18 |
| 4 | green | 18 |
| 5 | blue | 22 |
| 6 | None | 30 |
| 7 | NaN | 30 |
| 8 | green | 22 |
后补,暂无输出
# 计算数组空值数量,第一个sum求每一列空值数,第二个sum求整表空值数
df.isnull().sum().sum()
# str方法能将数据字符串化,数值使用字符串方法前需加
df['列名'].str.字符串方法
# 该方法是判断字符串中是否有子字符串。如果有则返回true,如果没有则返回false。
df['列名'].str.contains()
# all方法,返回是否所有元素都为真
df.all(axis=0, bool_only=None, skipna=True, level=None)
# any方法,返回是否至少一个元素为真
df.any方法(axis=0, bool_only=None, skipna=True, level=None)
# axis: 0、1或None,默认为0。此属性指出哪个轴应该减少。0减少索引,逐列判断,返回索引为原始列标签的Series。1减少列,逐行判断,返回一个索引为原始索引的Series。None减少所有轴,返回一个标量。
# skipna: True或者False,默认 True,排除NA/null值。如果整个row/column为NA,并且skipna为True,那么对于空row/column,结果将为True。如果skipna是False,那么NA就被当作True,因为它们不等于零。
# 函数用于判断给定的参数中是否全部为False,则返回False,如果有一个为True则返回True。
df.isnull().any()
# 函数用于判断给定的参数中所有元素是否都为 TRUE,如果是返回True,否则返回False。
df.isnull().all()
# 重复数据删除,返回非重复数据,不改变原数据
df.drop_duplicates() # 索引6和7是重复数据,None和NaN是一回事
输出:
| color | price | |
|---|---|---|
| 0 | red | 20 |
| 1 | blue | 15 |
| 3 | green | 18 |
| 5 | blue | 22 |
| 6 | None | 30 |
| 8 | green | 22 |
df.drop_duplicates(subset=['A','B'],keep='first',inplace=True)
# subset对应的值是列名,表示只考虑这两列,将这两列对应值相同的行进行去重。默认值为subset=None表示考虑所有列。
# keep='first'表示保留第一次出现的重复行,是默认值。keep另外两个取值为"last"和False,分别表示保留最后一次出现的重复行和去除所有重复行。
# inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。
df = df.drop_duplicates(subset=None,keep='first',inplace=False)
# 这一行代码与文章开头提到的那行代码效果等效,但是如果在该DataFrame上新增一列时,会报错“A value is trying to be set on a copy of a slice from a DataFrame”,原因是操作的数据不是原始数据,而是原始数据的副本。所以如果想对DataFrame去重,最好采用开头提到的那行代码。
# 空数据过滤
df.dropna()
输出:
| color | price | |
|---|---|---|
| 0 | red | 20 |
| 1 | blue | 15 |
| 2 | red | 20 |
| 3 | green | 18 |
| 4 | green | 18 |
| 5 | blue | 22 |
| 8 | green | 22 |
# 删除行,或者列
df.drop(labels=[2,4,6,8]) # 默认情况下删除行
输出:
| color | price | |
|---|---|---|
| 0 | red | 20 |
| 1 | blue | 15 |
| 3 | green | 18 |
| 5 | blue | 22 |
| 7 | NaN | 30 |
# 删除指定的列,axis = 1删除列
df.drop(labels='color',axis = 1)
输出:
| price | |
|---|---|
| 0 | 20 |
| 1 | 15 |
| 2 | 20 |
| 3 | 18 |
| 4 | 18 |
| 5 | 22 |
| 6 | 30 |
| 7 | 30 |
| 8 | 22 |
# 保留属性price的数据,删除其他数据
df.filter(items=['price'])
输出:
| price | |
|---|---|
| 0 | 20 |
| 1 | 15 |
| 2 | 20 |
| 3 | 18 |
| 4 | 18 |
| 5 | 22 |
| 6 | 30 |
| 7 | 30 |
| 8 | 22 |
# pandas的广播功能
df['size'] = 1024
输出:
| color | price | size | |
|---|---|---|---|
| 0 | red | 20 | 1024 |
| 1 | blue | 15 | 1024 |
| 2 | red | 20 | 1024 |
| 3 | green | 18 | 1024 |
| 4 | green | 18 | 1024 |
| 5 | blue | 22 | 1024 |
| 6 | None | 30 | 1024 |
| 7 | NaN | 30 | 1024 |
| 8 | green | 22 | 1024 |
# 模糊匹配,保留了带有i这个字母的索引
df.filter(like = 'i')
输出:
| price | size | |
|---|---|---|
| 0 | 20 | 1024 |
| 1 | 15 | 1024 |
| 2 | 20 | 1024 |
| 3 | 18 | 1024 |
| 4 | 18 | 1024 |
| 5 | 22 | 1024 |
| 6 | 30 | 1024 |
| 7 | 30 | 1024 |
| 8 | 22 | 1024 |
df['hello'] = 512 # 再加一列
df.filter(regex = 'e$') # 正则表达式,限制e必须在最后
输出:
| price | size | |
|---|---|---|
| 0 | 20 | 1024 |
| 1 | 15 | 1024 |
| 2 | 20 | 1024 |
| 3 | 18 | 1024 |
| 4 | 18 | 1024 |
| 5 | 22 | 1024 |
| 6 | 30 | 1024 |
| 7 | 30 | 1024 |
| 8 | 22 | 1024 |
df.filter(regex='e') # 只要带有e全部选出来
输出:
| price | size | hello | |
|---|---|---|---|
| 0 | 20 | 1024 | 512 |
| 1 | 15 | 1024 | 512 |
| 2 | 20 | 1024 | 512 |
| 3 | 18 | 1024 | 512 |
| 4 | 18 | 1024 | 512 |
| 5 | 22 | 1024 | 512 |
| 6 | 30 | 1024 | 512 |
| 7 | 30 | 1024 | 512 |
| 8 | 22 | 1024 | 512 |
# 异常值过滤,数据准备
a = np.random.randint(0,1000,size = 200)
输出:
array([453, 427, 221, 706, 241, 138, 209, 140, 313, 403, 319, 622, 135,
105, 647, 174, 859, 188, 731, 646, 506, 318, 394, 351, 592, 185,
717, 901, 533, 433, 222, 847, 125, 600, 99, 596, 367, 778, 741,
522, 231, 55, 430, 388, 370, 223, 595, 573, 868, 364, 365, 574,
868, 703, 197, 78, 397, 141, 822, 258, 975, 598, 80, 761, 402,
785, 71, 201, 186, 169, 311, 558, 427, 310, 654, 189, 31, 444,
31, 186, 987, 472, 504, 415, 13, 729, 425, 125, 867, 263, 365,
442, 210, 336, 499, 519, 981, 291, 120, 64, 775, 674, 892, 78,
932, 829, 42, 843, 730, 659, 172, 963, 217, 284, 39, 277, 310,
83, 553, 517, 883, 273, 364, 815, 428, 598, 710, 387, 25, 706,
570, 868, 79, 32, 941, 273, 604, 911, 883, 705, 569, 556, 69,
557, 436, 99, 404, 514, 635, 931, 823, 372, 991, 623, 748, 386,
551, 277, 949, 407, 792, 989, 316, 920, 513, 7, 939, 176, 645,
940, 46, 543, 424, 349, 149, 260, 100, 314, 677, 904, 903, 149,
163, 695, 654, 524, 44, 532, 624, 387, 615, 778, 627, 167, 637,
754, 129, 91, 137, 911])
# 异常值,大于800,小于 100算作异常,认为定义的。根据实际情况。
cond = (a <=800) & (a >=100) # &等于and
a[cond]
输出:
array([453, 427, 221, 706, 241, 138, 209, 140, 313, 403, 319, 622, 135,
105, 647, 174, 188, 731, 646, 506, 318, 394, 351, 592, 185, 717,
533, 433, 222, 125, 600, 596, 367, 778, 741, 522, 231, 430, 388,
370, 223, 595, 573, 364, 365, 574, 703, 197, 397, 141, 258, 598,
761, 402, 785, 201, 186, 169, 311, 558, 427, 310, 654, 189, 444,
186, 472, 504, 415, 729, 425, 125, 263, 365, 442, 210, 336, 499,
519, 291, 120, 775, 674, 730, 659, 172, 217, 284, 277, 310, 553,
517, 273, 364, 428, 598, 710, 387, 706, 570, 273, 604, 705, 569,
556, 557, 436, 404, 514, 635, 372, 623, 748, 386, 551, 277, 407,
792, 316, 513, 176, 645, 543, 424, 349, 149, 260, 100, 314, 677,
149, 163, 695, 654, 524, 532, 624, 387, 615, 778, 627, 167, 637,
754, 129, 137])
# 正态分布,平均值是0,标准差是1
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3*1 # 异常值
b[cond]
7 数据转换
7.1 轴和元素转换
df = pd.DataFrame(data = np.random.randint(0,10,size = (10,3)),
columns=['Python','Tensorflow','Keras'],
index = list('ABCDEFHIJK'))
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| A | 9 | 3 | 9 |
| B | 2 | 3 | 6 |
| C | 2 | 8 | 2 |
| D | 1 | 7 | 7 |
| E | 6 | 3 | 2 |
| F | 8 | 1 | 0 |
| H | 9 | 2 | 6 |
| I | 5 | 6 | 0 |
| J | 2 | 5 | 6 |
| K | 2 | 3 | 7 |
df.rename(index = {
'A':'X','K':'Y'}, # 行索引A改成X,K改成Y
columns={
'Python':'人工智能'}, # 列索引修改
inplace=True) # 是否替换原数据
输出:
| 人工智能 | Tensorflow | Keras | |
|---|---|---|---|
| X | 9 | 3 | 9 |
| B | 2 | 3 | 6 |
| C | 2 | 8 | 2 |
| D | 1 | 7 | 7 |
| E | 6 | 3 | 2 |
| F | 8 | 1 | 0 |
| H | 9 | 2 | 6 |
| I | 5 | 6 | 0 |
| J | 2 | 5 | 6 |
| Y | 2 | 3 | 7 |
# 5修改成50
df.replace(5,50,inplace=True) # 是否修改原数据
输出:
| 人工智能 | Tensorflow | Keras | |
|---|---|---|---|
| X | 9 | 3 | 9 |
| B | 2 | 3 | 6 |
| C | 2 | 8 | 2 |
| D | 1 | 7 | 7 |
| E | 6 | 3 | 2 |
| F | 8 | 1 | 0 |
| H | 9 | 2 | 6 |
| I | 50 | 6 | 0 |
| J | 2 | 50 | 6 |
| Y | 2 | 3 | 7 |
# 2和7修改成1024
df.replace([2,7],1024,inplace=True)
输出:
| 人工智能 | Tensorflow | Keras | |
|---|---|---|---|
| X | 9 | 3 | 9 |
| B | 1024 | 3 | 6 |
| C | 1024 | 8 | 1024 |
| D | 1 | 1024 | 1024 |
| E | 6 | 3 | 1024 |
| F | 8 | 1 | 0 |
| H | 9 | 1024 | 6 |
| I | 50 | 6 | 0 |
| J | 1024 | 50 | 6 |
| Y | 1024 | 3 | 1024 |
# 5行3列修改成空数据
df.iloc[4,2] = np.NaN
输出:
| 人工智能 | Tensorflow | Keras | |
|---|---|---|---|
| X | 9 | 3 | 9.0 |
| B | 1024 | 3 | 6.0 |
| C | 1024 | 8 | 1024.0 |
| D | 1 | 1024 | 1024.0 |
| E | 6 | 3 | NaN |
| F | 8 | 1 | 0.0 |
| H | 9 | 1024 | 6.0 |
| I | 50 | 6 | 0.0 |
| J | 1024 | 50 | 6.0 |
| Y | 1024 | 3 | 1024.0 |
# 0修改成2048,nan修改成-100
df.replace({
0:2048,np.nan:-100},inplace=True)
输出:
| 人工智能 | Tensorflow | Keras | |
|---|---|---|---|
| X | 9 | 3 | 9.0 |
| B | 1024 | 3 | 6.0 |
| C | 1024 | 8 | 1024.0 |
| D | 1 | 1024 | 1024.0 |
| E | 6 | 3 | -100.0 |
| F | 8 | 1 | 2048.0 |
| H | 9 | 1024 | 6.0 |
| I | 50 | 6 | 2048.0 |
| J | 1024 | 50 | 6.0 |
| Y | 1024 | 3 | 1024.0 |
# 指定某一列进行数据替换
df.replace({
'Tensorflow':1024},-1024)
输出:
| 人工智能 | Tensorflow | Keras | |
|---|---|---|---|
| X | 9 | 3 | 9.0 |
| B | 1024 | 3 | 6.0 |
| C | 1024 | 8 | 1024.0 |
| D | 1 | -1024 | 1024.0 |
| E | 6 | 3 | -100.0 |
| F | 8 | 1 | 2048.0 |
| H | 9 | -1024 | 6.0 |
| I | 50 | 6 | 2048.0 |
| J | 1024 | 50 | 6.0 |
| Y | 1024 | 3 | 1024.0 |
7.2 map映射元素转变
map方法只能操作一列,即Series
# 跟据字典对数据进行改变,如果没有对应数据则返回空数据
df['人工智能'].map({
1024:3.14,2048:2.718,6:1108})
输出:
X NaN
B 3.14
C 3.14
D NaN
E 1108.00
F NaN
H NaN
I NaN
J 3.14
Y 3.14
Name: 人工智能, dtype: float64
# map方法里面也可以调用函数,逐个元素调用
df['Keras'].map(lambda x :True if x > 0 else False)
输出:
X True
B True
C True
D True
E False
F True
H True
I True
J True
Y True
Name: Keras, dtype: bool
# map就是映射,映射Tensorflow列中每一个数据,将数据传递到函数中
def convert(x):
if x >= 1024:
return True
else:
return False
df['level'] = df['Tensorflow'].map(convert)
输出:
| 人工智能 | Tensorflow | Keras | level | |
|---|---|---|---|---|
| X | 9 | 3 | 9.0 | False |
| B | 1024 | 3 | 6.0 | False |
| C | 1024 | 8 | 1024.0 | False |
| D | 1 | 1024 | 1024.0 | True |
| E | 6 | 3 | -100.0 | False |
| F | 8 | 1 | 2048.0 | False |
| H | 9 | 1024 | 6.0 | True |
| I | 50 | 6 | 2048.0 | False |
| J | 1024 | 50 | 6.0 | False |
| Y | 1024 | 3 | 1024.0 | False |
7.3 apply映射元素转变
apply方法既可以操作Series又可以操作DataFrame
# 操作Series
df['人工智能'].apply(lambda x : x + 100)
输出:
X 109
B 1124
C 1124
D 101
E 106
F 108
H 109
I 150
J 1124
Y 1124
Name: 人工智能, dtype: int64
# apply对DataFrame所有的数据进行映射
df.apply(lambda x : x + 1000)
输出:
| 人工智能 | Tensorflow | Keras | level | |
|---|---|---|---|---|
| X | 1009 | 1003 | 1009.0 | 1000 |
| B | 2024 | 1003 | 1006.0 | 1000 |
| C | 2024 | 1008 | 2024.0 | 1000 |
| D | 1001 | 2024 | 2024.0 | 1001 |
| E | 1006 | 1003 | 900.0 | 1000 |
| F | 1008 | 1001 | 3048.0 | 1000 |
| H | 1009 | 2024 | 1006.0 | 1001 |
| I | 1050 | 1006 | 3048.0 | 1000 |
| J | 2024 | 1050 | 1006.0 | 1000 |
| Y | 2024 | 1003 | 2024.0 | 1000 |
def convert(x):
return (x.median(),x.count(),x.min(),x.max(),x.std()) # 返回中位数,返回的是计数
df.apply(convert)# 默认操作列数据
输出:(这里df的随机数被我重新生成了,与上面的df数据不一致,结果不用深究)
| 人工智能 | Tensorflow | Keras | level | |
|---|---|---|---|---|
| 0 | 29.0 | 1024.0 | 7.0 | 1 |
| 1 | 10.0 | 10.0 | 10.0 | 10 |
| 2 | 4.0 | 4.0 | -100.0 | False |
| 3 | 2048.0 | 2048.0 | 2048.0 | True |
| 4 | 717.8 | 800.4 | 694.9 | 0.516398 |
df.apply(convert,axis = 1) # 操作行数据
输出:
X (6.0, 4, False, 9, 4.5)
B (4.5, 4, False, 1024, 510.50587655775325)
C (516.0, 4, False, 1024, 588.9063309785918)
D (512.5, 4, 1, 1024, 590.6293253809872)
E (1.5, 4, -100.0, 6, 51.55821951929683)
F (4.5, 4, False, 2048.0, 1022.5061939502698)
H (7.5, 4, True, 1024, 509.344022575443)
I (28.0, 4, False, 2048.0, 1014.9114903937847)
J (28.0, 4, False, 1024, 503.1606767889028)
Y (513.5, 4, False, 1024, 590.3419206979404)
dtype: object
7.4 transform元素转变
transform方法与apply方法基本一致
# 数据准备
df = pd.DataFrame(np.random.randint(0,10,size = (10,3)),
columns=['Python','Tensorflow','Keras'],
index = list('ABCDEFHIJK'))
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| A | 6 | 1 | 7 |
| B | 4 | 5 | 6 |
| C | 7 | 0 | 6 |
| D | 9 | 5 | 9 |
| E | 5 | 6 | 2 |
| F | 4 | 8 | 6 |
| H | 6 | 5 | 2 |
| I | 3 | 1 | 3 |
| J | 5 | 3 | 1 |
| K | 3 | 1 | 8 |
# 可以针对Series进行操作,和map、apply类似
df['Python'].transform(lambda x : 1024 if x > 5 else -1024)
输出:
A 1024
B -1024
C 1024
D 1024
E -1024
F -1024
H 1024
I -1024
J -1024
K -1024
Name: Python, dtype: int64
# 也可以针对一列进行不同的操作
df['Tensorflow'].transform([np.sqrt,np.square,np.cumsum])
# apply方法一样可以
df['Tensorflow'].apply([np.sqrt,np.square,np.cumsum])
输出:
| sqrt | square | cumsum | |
|---|---|---|---|
| A | 1.000000 | 1 | 1 |
| B | 2.236068 | 25 | 6 |
| C | 0.000000 | 0 | 6 |
| D | 2.236068 | 25 | 11 |
| E | 2.449490 | 36 | 17 |
| F | 2.828427 | 64 | 25 |
| H | 2.236068 | 25 | 30 |
| I | 1.000000 | 1 | 31 |
| J | 1.732051 | 9 | 34 |
| K | 1.000000 | 1 | 35 |
# 也可以针对DataFrame进行操作
def convert(x):
if x > 5:
return True
else:
return False
# 对不同的列执行不同的操作
df.transform({
'Python':np.cumsum,'Tensorflow':np.square,'Keras':convert})
# apply一样可以
df.apply({
'Python':np.cumsum,'Tensorflow':np.square,'Keras':convert})
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| A | 6 | 1 | True |
| B | 10 | 25 | True |
| C | 17 | 0 | True |
| D | 26 | 25 | True |
| E | 31 | 36 | False |
| F | 35 | 64 | True |
| H | 41 | 25 | False |
| I | 44 | 1 | False |
| J | 49 | 9 | False |
| K | 52 | 1 | True |
7.5 重排随机抽样哑变量
df # 准备数据
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| A | 6 | 1 | 7 |
| B | 4 | 5 | 6 |
| C | 7 | 0 | 6 |
| D | 9 | 5 | 9 |
| E | 5 | 6 | 2 |
| F | 4 | 8 | 6 |
| H | 6 | 5 | 2 |
| I | 3 | 1 | 3 |
| J | 5 | 3 | 1 |
| K | 3 | 1 | 8 |
# 从大量数据中随机抽取数据
df.take(np.random.randint(0,10,size = 20)) # 随机抽样20个数据
# df.take() 按括号里的数字作为索引,取出相应的df数据
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| I | 3 | 1 | 3 |
| I | 3 | 1 | 3 |
| B | 4 | 5 | 6 |
| I | 3 | 1 | 3 |
| I | 3 | 1 | 3 |
| K | 3 | 1 | 8 |
| J | 5 | 3 | 1 |
| B | 4 | 5 | 6 |
| J | 5 | 3 | 1 |
| C | 7 | 0 | 6 |
| C | 7 | 0 | 6 |
| A | 6 | 1 | 7 |
| D | 9 | 5 | 9 |
| C | 7 | 0 | 6 |
| H | 6 | 5 | 2 |
| K | 3 | 1 | 8 |
| C | 7 | 0 | 6 |
| K | 3 | 1 | 8 |
| H | 6 | 5 | 2 |
| H | 6 | 5 | 2 |
# 生成df2
df2 = pd.DataFrame(data = {
'key':['a','b','a','b','c','b','c']})
输出:
| key | |
|---|---|
| 0 | a |
| 1 | b |
| 2 | a |
| 3 | b |
| 4 | c |
| 5 | b |
| 6 | c |
# one-hot,哑变量
# str类型数据,经过哑变量变换可以使用数字表示
pd.get_dummies(df2,prefix='',prefix_sep='') # 1表示,有;0表示,没有
输出:
| a | b | c | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 0 | 1 | 0 |
| 4 | 0 | 0 | 1 |
| 5 | 0 | 1 | 0 |
| 6 | 0 | 0 | 1 |
8 数据重塑
df.T # 转置,行变列,列变行
输出:
| A | B | C | D | E | F | H | I | J | K | |
|---|---|---|---|---|---|---|---|---|---|---|
| Python | 6 | 4 | 7 | 9 | 5 | 4 | 6 | 3 | 5 | 3 |
| Tensorflow | 1 | 5 | 0 | 5 | 6 | 8 | 5 | 1 | 3 | 1 |
| Keras | 7 | 6 | 6 | 9 | 2 | 6 | 2 | 3 | 1 | 8 |
# 数据准备
df2 = pd.DataFrame(np.random.randint(0,10,size = (20,3)),
columns=['Python','Math','En'],
index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),
['期中','期末']])) # 多层索引
输出:
| Python | Math | En | ||
|---|---|---|---|---|
| A | 期中 | 4 | 1 | 9 |
| 期末 | 4 | 9 | 4 | |
| B | 期中 | 4 | 8 | 2 |
| 期末 | 8 | 0 | 5 | |
| C | 期中 | 5 | 9 | 9 |
| 期末 | 5 | 5 | 9 | |
| D | 期中 | 3 | 7 | 8 |
| 期末 | 3 | 1 | 3 | |
| E | 期中 | 2 | 7 | 1 |
| 期末 | 0 | 8 | 1 | |
| F | 期中 | 0 | 9 | 9 |
| 期末 | 6 | 9 | 2 | |
| H | 期中 | 9 | 3 | 8 |
| 期末 | 7 | 7 | 0 | |
| I | 期中 | 3 | 0 | 8 |
| 期末 | 6 | 4 | 2 | |
| J | 期中 | 2 | 8 | 1 |
| 期末 | 0 | 5 | 4 | |
| K | 期中 | 0 | 7 | 3 |
| 期末 | 0 | 3 | 1 |
# 将行索引变成列索引
df2.unstack(level = 1)
输出:
| Python | Math | En | ||||
|---|---|---|---|---|---|---|
| 期中 | 期末 | 期中 | 期末 | 期中 | 期末 | |
| A | 4 | 4 | 1 | 9 | 9 | 4 |
| B | 4 | 8 | 8 | 0 | 2 | 5 |
| C | 5 | 5 | 9 | 5 | 9 | 9 |
| D | 3 | 3 | 7 | 1 | 8 | 3 |
| E | 2 | 0 | 7 | 8 | 1 | 1 |
| F | 0 | 6 | 9 | 9 | 9 | 2 |
| H | 9 | 7 | 3 | 7 | 8 | 0 |
| I | 3 | 6 | 0 | 4 | 8 | 2 |
| J | 2 | 0 | 8 | 5 | 1 | 4 |
| K | 0 | 0 | 7 | 3 | 3 | 1 |
# 将行索引变成列索引,-1表示最后一层
df2.unstack(level = -1) # 默认-1
输出:
| Python | Math | En | ||||
|---|---|---|---|---|---|---|
| 期中 | 期末 | 期中 | 期末 | 期中 | 期末 | |
| A | 4 | 4 | 1 | 9 | 9 | 4 |
| B | 4 | 8 | 8 | 0 | 2 | 5 |
| C | 5 | 5 | 9 | 5 | 9 | 9 |
| D | 3 | 3 | 7 | 1 | 8 | 3 |
| E | 2 | 0 | 7 | 8 | 1 | 1 |
| F | 0 | 6 | 9 | 9 | 9 | 2 |
| H | 9 | 7 | 3 | 7 | 8 | 0 |
| I | 3 | 6 | 0 | 4 | 8 | 2 |
| J | 2 | 0 | 8 | 5 | 1 | 4 |
| K | 0 | 0 | 7 | 3 | 3 | 1 |
# 列变行,变成1维
df2.stack()
输出:
A 期中 Python 4
Math 1
En 9
期末 Python 4
Math 9
En 4
B 期中 Python 4
Math 8
En 2
期末 Python 8
Math 0
En 5
C 期中 Python 5
Math 9
En 9
期末 Python 5
Math 5
En 9
D 期中 Python 3
Math 7
En 8
期末 Python 3
Math 1
En 3
E 期中 Python 2
Math 7
En 1
期末 Python 0
Math 8
En 1
F 期中 Python 0
Math 9
En 9
期末 Python 6
Math 9
En 2
H 期中 Python 9
Math 3
En 8
期末 Python 7
Math 7
En 0
I 期中 Python 3
Math 0
En 8
期末 Python 6
Math 4
En 2
J 期中 Python 2
Math 8
En 1
期末 Python 0
Math 5
En 4
K 期中 Python 0
Math 7
En 3
期末 Python 0
Math 3
En 1
dtype: int32
# 先将期中期末变成列标签,再把第一层列标签变行标签
df2.unstack().stack(level = 0)
输出:
| 期中 | 期末 | ||
|---|---|---|---|
| A | En | 9 | 4 |
| Math | 1 | 9 | |
| Python | 4 | 4 | |
| B | En | 2 | 5 |
| Math | 8 | 0 | |
| Python | 4 | 8 | |
| C | En | 9 | 9 |
| Math | 9 | 5 | |
| Python | 5 | 5 | |
| D | En | 8 | 3 |
| Math | 7 | 1 | |
| Python | 3 | 3 | |
| E | En | 1 | 1 |
| Math | 7 | 8 | |
| Python | 2 | 0 | |
| F | En | 9 | 2 |
| Math | 9 | 9 | |
| Python | 0 | 6 | |
| H | En | 8 | 0 |
| Math | 3 | 7 | |
| Python | 9 | 7 | |
| I | En | 8 | 2 |
| Math | 0 | 4 | |
| Python | 3 | 6 | |
| J | En | 1 | 4 |
| Math | 8 | 5 | |
| Python | 2 | 0 | |
| K | En | 3 | 1 |
| Math | 7 | 3 | |
| Python | 0 | 0 |
df2.mean() # 计算的是列
输出:
Python 3.55
Math 5.50
En 4.45
dtype: float64
df2.mean(axis = 1) # 计算的是行
输出:
A 期中 4.666667
期末 5.666667
B 期中 4.666667
期末 4.333333
C 期中 7.666667
期末 6.333333
D 期中 6.000000
期末 2.333333
E 期中 3.333333
期末 3.000000
F 期中 6.000000
期末 5.666667
H 期中 6.666667
期末 4.666667
I 期中 3.666667
期末 4.000000
J 期中 3.666667
期末 3.000000
K 期中 3.333333
期末 1.333333
dtype: float64
# 计算期中期末所有学生的平均分
df2.mean(level=1)
# 注意level和上面axis的区别
输出:
| Python | Math | En | |
|---|---|---|---|
| 期中 | 3.2 | 5.9 | 5.8 |
| 期末 | 3.9 | 5.1 | 3.1 |
# 计算每位学生期中和期末平均分
df2.mean(level = 0)
输出:
| Python | Math | En | |
|---|---|---|---|
| A | 4.0 | 5.0 | 6.5 |
| B | 6.0 | 4.0 | 3.5 |
| C | 5.0 | 7.0 | 9.0 |
| D | 3.0 | 4.0 | 5.5 |
| E | 1.0 | 7.5 | 1.0 |
| F | 3.0 | 9.0 | 5.5 |
| H | 8.0 | 5.0 | 4.0 |
| I | 4.5 | 2.0 | 5.0 |
| J | 1.0 | 6.5 | 2.5 |
| K | 0.0 | 5.0 | 2.0 |
第二部分 Pandas高级应用
1 数学和统计方法
Pandas对象拥有⼀组常用的数学和统计方法。它们属于汇总统计,对Series汇总计算获取mean、max值或者对DataFrame⾏、列汇总计算返回⼀个Series。
1.1 简单统计指标
# 数据准备
df = pd.DataFrame(np.random.randint(0,10,size = (20,3)),
columns=['Python','Math','En'],
index = list('QWERTYUIOPASDFGHJKLZ'))
df.iloc[6,2] = np.NAN
输出:
| Python | Math | En | |
|---|---|---|---|
| Q | 8 | 4 | 3.0 |
| W | 7 | 4 | 7.0 |
| E | 0 | 0 | 3.0 |
| R | 9 | 4 | 1.0 |
| T | 9 | 3 | 4.0 |
| Y | 7 | 1 | 5.0 |
| U | 5 | 2 | NaN |
| I | 5 | 6 | 7.0 |
| O | 5 | 6 | 5.0 |
| P | 3 | 1 | 7.0 |
| A | 9 | 2 | 0.0 |
| S | 9 | 6 | 7.0 |
| D | 4 | 8 | 4.0 |
| F | 8 | 6 | 4.0 |
| G | 8 | 5 | 3.0 |
| H | 3 | 0 | 3.0 |
| J | 0 | 1 | 9.0 |
| K | 7 | 3 | 9.0 |
| L | 5 | 8 | 0.0 |
| Z | 4 | 2 | 3.0 |
下面的函数比较简单,就不输出结果了
df.count() # 统计非空数据数量,默认返回各列的数量
df['列名'].value_counts() # 返回各个值的数量
df.mean() # 平均值
df.median() # 中位数
df.min() # 最小值
df.max() # 最大值
df['Python'].unique() # 去除重复数据
输出:
array([8, 7, 0, 9, 5, 3, 4])
# 统计各个值出现的频次
df['Math'].value_counts()
输出:
6 4
1 3
2 3
4 3
0 2
3 2
8 2
5 1
Name: Math, dtype: int64
# 百分位数
df.quantile(q = [0,0.25,0.5,0.75,1])
输出:
| Python | Math | En | |
|---|---|---|---|
| 0.00 | 0.0 | 0.00 | 0.0 |
| 0.25 | 4.0 | 1.75 | 3.0 |
| 0.50 | 6.0 | 3.50 | 4.0 |
| 0.75 | 8.0 | 6.00 | 7.0 |
| 1.00 | 9.0 | 8.00 | 9.0 |
# 各列的描述性统计指标
df.describe().round(1)
输出:
| Python | Math | En | |
|---|---|---|---|
| count | 20.0 | 20.0 | 19.0 |
| mean | 5.8 | 3.6 | 4.4 |
| std | 2.8 | 2.5 | 2.7 |
| min | 0.0 | 0.0 | 0.0 |
| 25% | 4.0 | 1.8 | 3.0 |
| 50% | 6.0 | 3.5 | 4.0 |
| 75% | 8.0 | 6.0 | 7.0 |
| max | 9.0 | 8.0 | 9.0 |
1.2 索引标签、位置获取
下面的函数比较简单,就不输出结果了
# 返回行索引序号,数据必须是Series
df['Python'].argmax() # 返回最大值索引(行标签序号)
df['En'].argmin() # 最小值索引
# 返回行索引标签,数据可以是DataFrame
df.idxmax() # 返回最大值的标签(行标签名字)
df.idxmin() # 返回最小值标签
1.3 更多统计指标
下面的函数比较简单,就不输出结果了
df.cumsum() # 累加和
df.cumprod() # 累乘和
df.cummin() # 累计最小值
df.cummax() # 累计最大值
df.std() # 标准差
df.var() # 方差
df.diff() # 差分,即当前数据减去上一个数的差值
df.pct_change().round(3) # 计算当前数据对比上一个数据的百分比变化
1.4 高级统计指标
# 协方差:自己和别人计算
df.cov()
输出:
| Python | Math | En | |
|---|---|---|---|
| Python | 7.986842 | 2.631579 | -1.850877 |
| Math | 2.631579 | 6.252632 | -0.804094 |
| En | -1.850877 | -0.804094 | 7.257310 |
# 方差: 自己和自己计算
df.var()
输出:
Python 7.986842
Math 6.252632
En 7.257310
dtype: float64
# 指定两列数据的协方差
df['Python'].cov(df['Math'])
输出:
2.631578947368421
# 相关性系数
df.corr()
输出:
| Python | Math | En | |
|---|---|---|---|
| Python | 1.000000 | 0.372390 | -0.237089 |
| Math | 0.372390 | 1.000000 | -0.117525 |
| En | -0.237089 | -0.117525 | 1.000000 |
# 某一列与其他列的相关性系数
df.corrwith(df['En'])
输出:
Python -0.237089
Math -0.117525
En 1.000000
dtype: float64
2 数据排序
# 数据准备
df = pd.DataFrame(np.random.randint(0,20,size = (20,3)),
columns=['Python','Tensorflow','Keras'],index = list('QWERTYUIOPASDFGHJKLZ'))
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| Q | 6 | 5 | 6 |
| W | 6 | 5 | 7 |
| E | 13 | 10 | 0 |
| R | 10 | 11 | 13 |
| T | 7 | 3 | 2 |
| Y | 0 | 3 | 8 |
| U | 16 | 10 | 13 |
| I | 13 | 9 | 5 |
| O | 0 | 11 | 17 |
| P | 9 | 9 | 7 |
| A | 4 | 16 | 16 |
| S | 5 | 1 | 9 |
| D | 9 | 4 | 8 |
| F | 4 | 11 | 2 |
| G | 13 | 12 | 14 |
| H | 15 | 15 | 4 |
| J | 3 | 8 | 13 |
| K | 15 | 0 | 8 |
| L | 9 | 17 | 1 |
| Z | 1 | 3 | 1 |
# 根据索引排序
df.sort_index(axis = 0,ascending=False) # False降序
df.sort_index(ascending=True) # True升序
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| A | 4 | 16 | 16 |
| D | 9 | 4 | 8 |
| E | 13 | 10 | 0 |
| F | 4 | 11 | 2 |
| G | 13 | 12 | 14 |
| H | 15 | 15 | 4 |
| I | 13 | 9 | 5 |
| J | 3 | 8 | 13 |
| K | 15 | 0 | 8 |
| L | 9 | 17 | 1 |
| O | 0 | 11 | 17 |
| P | 9 | 9 | 7 |
| Q | 6 | 5 | 6 |
| R | 10 | 11 | 13 |
| S | 5 | 1 | 9 |
| T | 7 | 3 | 2 |
| U | 16 | 10 | 13 |
| W | 6 | 5 | 7 |
| Y | 0 | 3 | 8 |
| Z | 1 | 3 | 1 |
# 根据Python属性进行升序排列
df.sort_values(by = 'Python',ascending=True)
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| Y | 0 | 3 | 8 |
| O | 0 | 11 | 17 |
| Z | 1 | 3 | 1 |
| J | 3 | 8 | 13 |
| F | 4 | 11 | 2 |
| A | 4 | 16 | 16 |
| S | 5 | 1 | 9 |
| Q | 6 | 5 | 6 |
| W | 6 | 5 | 7 |
| T | 7 | 3 | 2 |
| L | 9 | 17 | 1 |
| D | 9 | 4 | 8 |
| P | 9 | 9 | 7 |
| R | 10 | 11 | 13 |
| E | 13 | 10 | 0 |
| G | 13 | 12 | 14 |
| I | 13 | 9 | 5 |
| H | 15 | 15 | 4 |
| K | 15 | 0 | 8 |
| U | 16 | 10 | 13 |
# 先根据Python进行排序,如果相等再根据Tensorflow排序
df.sort_values(by = ['Python','Tensorflow'],ascending=True)
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| Y | 0 | 3 | 8 |
| O | 0 | 11 | 17 |
| Z | 1 | 3 | 1 |
| J | 3 | 8 | 13 |
| F | 4 | 11 | 2 |
| A | 4 | 16 | 16 |
| S | 5 | 1 | 9 |
| Q | 6 | 5 | 6 |
| W | 6 | 5 | 7 |
| T | 7 | 3 | 2 |
| D | 9 | 4 | 8 |
| P | 9 | 9 | 7 |
| L | 9 | 17 | 1 |
| R | 10 | 11 | 13 |
| I | 13 | 9 | 5 |
| E | 13 | 10 | 0 |
| G | 13 | 12 | 14 |
| K | 15 | 0 | 8 |
| H | 15 | 15 | 4 |
| U | 16 | 10 | 13 |
# 根据Python进行排序,获取最大的5个数值
df.nlargest(n = 5,columns='Python')
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| U | 16 | 10 | 13 |
| H | 15 | 15 | 4 |
| K | 15 | 0 | 8 |
| E | 13 | 10 | 0 |
| I | 13 | 9 | 5 |
# 根据Keras进行排序,获取最小的5个
df.nsmallest(5,columns='Keras')
输出:
| Python | Tensorflow | Keras | |
|---|---|---|---|
| E | 13 | 10 | 0 |
| L | 9 | 17 | 1 |
| Z | 1 | 3 | 1 |
| T | 7 | 3 | 2 |
| F | 4 | 11 | 2 |
3 分箱操作
分箱操作就是将连续数据转换为分类对应物的过程。比如将连续的身高数据划分为:矮中高。
分箱操作分为等距分箱和等频分箱。
分箱操作也叫面元划分或者离散化。
# 数据准备
df = pd.DataFrame(np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
输出:
| Python | Math | En | |
|---|---|---|---|
| 0 | 97 | 62 | 9 |
| 1 | 0 | 92 | 113 |
| 2 | 34 | 60 | 35 |
| 3 | 122 | 114 | 130 |
| 4 | 35 | 107 | 34 |
| 5 | 44 | 89 | 32 |
| 6 | 90 | 1 | 75 |
| 7 | 57 | 120 | 36 |
| 8 | 32 | 143 | 127 |
| 9 | 66 | 98 | 115 |
| 10 | 62 | 130 | 19 |
| ... | ... | ... | ... |
| 81 | 24 | 40 | 82 |
| 82 | 19 | 25 | 69 |
| 83 | 127 | 142 | 66 |
| 84 | 132 | 131 | 60 |
| 85 | 105 | 80 | 21 |
| 86 | 129 | 10 | 17 |
| 87 | 18 | 54 | 45 |
| 88 | 136 | 41 | 77 |
| 89 | 23 | 65 | 88 |
| 90 | 64 | 66 | 95 |
| 91 | 114 | 32 | 108 |
| 92 | 64 | 82 | 11 |
| 93 | 125 | 77 | 110 |
| 94 | 134 | 84 | 145 |
| 95 | 93 | 56 | 37 |
| 96 | 37 | 12 | 34 |
| 97 | 146 | 131 | 64 |
| 98 | 77 | 116 | 123 |
| 99 | 8 | 81 | 74 |
# 等宽
pd.cut(df.Python,
bins = 4, # 等宽分成四份
labels=['不及格','及格','中等','优秀'], # 区间名字
right = True) # 右边是否为闭区间
输出:
0 中等
1 不及格
2 不及格
3 优秀
4 不及格
5 及格
6 中等
7 及格
8 不及格
9 及格
10 及格
...
81 不及格
82 不及格
83 优秀
84 优秀
85 中等
86 优秀
87 不及格
88 优秀
89 不及格
90 及格
91 优秀
92 及格
93 优秀
94 优秀
95 中等
96 不及格
97 优秀
98 中等
99 不及格
Name: Python, Length: 100, dtype: category
Categories (4, object): [不及格 < 及格 < 中等 < 优秀]
# 等宽
df['等级'] = pd.cut(df.Python,
bins = [0,30,60,90,120,150], # 直接指定区间
labels=['极差','不及格','及格','中等','优秀']) # 区间名字
输出:
| Python | Math | En | 等级 | |
|---|---|---|---|---|
| 0 | 97 | 62 | 9 | 中等 |
| 1 | 0 | 92 | 113 | NaN |
| 2 | 34 | 60 | 35 | 不及格 |
| 3 | 122 | 114 | 130 | 优秀 |
| 4 | 35 | 107 | 34 | 不及格 |
| 5 | 44 | 89 | 32 | 不及格 |
| 6 | 90 | 1 | 75 | 及格 |
| 7 | 57 | 120 | 36 | 不及格 |
| 8 | 32 | 143 | 127 | 不及格 |
| 9 | 66 | 98 | 115 | 及格 |
| 10 | 62 | 130 | 19 | 及格 |
| ... | ... | ... | ... | ... |
| 81 | 24 | 40 | 82 | 极差 |
| 82 | 19 | 25 | 69 | 极差 |
| 83 | 127 | 142 | 66 | 优秀 |
| 84 | 132 | 131 | 60 | 优秀 |
| 85 | 105 | 80 | 21 | 中等 |
| 86 | 129 | 10 | 17 | 优秀 |
| 87 | 18 | 54 | 45 | 极差 |
| 88 | 136 | 41 | 77 | 优秀 |
| 89 | 23 | 65 | 88 | 极差 |
| 90 | 64 | 66 | 95 | 及格 |
| 91 | 114 | 32 | 108 | 中等 |
| 92 | 64 | 82 | 11 | 及格 |
| 93 | 125 | 77 | 110 | 优秀 |
| 94 | 134 | 84 | 145 | 优秀 |
| 95 | 93 | 56 | 37 | 中等 |
| 96 | 37 | 12 | 34 | 不及格 |
| 97 | 146 | 131 | 64 | 优秀 |
| 98 | 77 | 116 | 123 | 及格 |
| 99 | 8 | 81 | 74 | 极差 |
# 等频
pd.qcut(df.Python,q = 4,labels=['不及格','及格','中等','优秀']) # 按值出现的频率分区间
pd.qcut(df.Python,q = 4,labels=['不及格','及格','中等','优秀']).value_counts() # 每一个区间的值数量基本一致
输出:
不及格 26
优秀 25
中等 25
及格 24
Name: Python, dtype: int64
4 分组聚合
类似于SQL语句中的Groupby操作,过程拆解如下图所示:
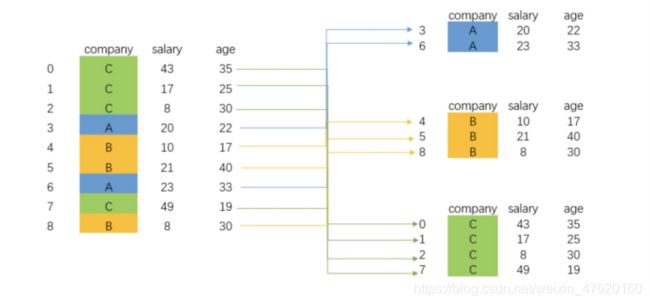
4.1 分组
# 数据准备
df = pd.DataFrame(data = {
'sex':np.random.randint(0,2,size = 300),
'class':np.random.randint(1,9,size = 300),
'Python':np.random.randint(0,151,size = 300),
'Math':np.random.randint(0,151,size = 300),
'En':np.random.randint(0,151,size = 300)})
df['sex'] = df['sex'].map({
0:'男',1:'女'}) # 把0和1改成性别
输出:
| sex | class | Python | Math | En | |
|---|---|---|---|---|---|
| 0 | 男 | 4 | 57 | 99 | 35 |
| 1 | 男 | 5 | 13 | 112 | 30 |
| 2 | 男 | 3 | 62 | 142 | 29 |
| 3 | 女 | 5 | 99 | 132 | 88 |
| 4 | 女 | 3 | 58 | 1 | 123 |
| ... | ... | ... | ... | ... | ... |
| 295 | 女 | 3 | 42 | 18 | 81 |
| 296 | 女 | 4 | 148 | 20 | 117 |
| 297 | 女 | 4 | 129 | 28 | 29 |
| 298 | 女 | 6 | 100 | 41 | 129 |
| 299 | 男 | 3 | 6 | 75 | 28 |
# 单分组
df.groupby(by = 'sex') # 按sex分两组
for name,group in df.groupby(by = 'sex'):
print(name) # 分组名字
print(group) # 分组具体数字
输出:
女
sex class Python Math En
3 女 5 99 132 88
4 女 3 58 1 123
8 女 2 37 141 21
10 女 6 71 64 41
11 女 7 35 66 77
.. .. ... ... ... ...
294 女 1 146 41 117
295 女 3 42 18 81
296 女 4 148 20 117
297 女 4 129 28 29
298 女 6 100 41 129
[158 rows x 5 columns]
男
sex class Python Math En
0 男 4 57 99 35
1 男 5 13 112 30
2 男 3 62 142 29
5 男 5 144 147 8
6 男 5 143 107 93
.. .. ... ... ... ...
286 男 2 54 93 42
288 男 1 42 115 28
290 男 4 125 114 94
291 男 2 35 17 136
299 男 3 6 75 28
[142 rows x 5 columns]
# 多分组
df.groupby(by = ['sex','class']) # 按sex 2,class 8,分16组
for name ,group in df.groupby(by = ['sex','class']):
print(name)
print(group)
输出:
('女', 1)
sex class Python Math En
23 女 1 40 73 86
42 女 1 101 79 40
44 女 1 43 90 86
53 女 1 99 86 18
65 女 1 50 69 134
104 女 1 94 109 38
120 女 1 109 48 93
140 女 1 122 73 142
152 女 1 128 139 119
156 女 1 58 101 127
176 女 1 76 123 97
239 女 1 90 47 1
242 女 1 80 84 136
244 女 1 136 146 105
256 女 1 107 69 107
257 女 1 3 88 78
264 女 1 104 145 34
270 女 1 32 64 24
278 女 1 70 61 120
294 女 1 146 41 117
('女', 2)
sex class Python Math En
8 女 2 37 141 21
21 女 2 69 104 1
22 女 2 144 12 131
27 女 2 16 115 148
43 女 2 25 103 116
46 女 2 33 42 46
56 女 2 13 15 39
83 女 2 95 35 57
97 女 2 17 96 38
126 女 2 91 1 26
127 女 2 119 48 106
130 女 2 123 51 100
146 女 2 5 46 65
153 女 2 16 14 98
161 女 2 83 3 41
188 女 2 134 138 98
190 女 2 2 51 125
198 女 2 46 80 101
213 女 2 60 150 57
225 女 2 133 110 146
......
('男', 7)
sex class Python Math En
30 男 7 10 63 70
67 男 7 110 42 79
78 男 7 114 133 8
79 男 7 105 43 116
117 男 7 142 121 126
118 男 7 55 48 125
134 男 7 73 120 22
182 男 7 120 23 66
204 男 7 10 28 38
212 男 7 32 110 58
214 男 7 109 149 77
241 男 7 62 19 18
251 男 7 81 49 51
255 男 7 133 86 132
265 男 7 79 6 63
266 男 7 145 77 11
268 男 7 3 27 118
('男', 8)
sex class Python Math En
69 男 8 134 141 19
81 男 8 114 20 102
89 男 8 67 72 96
106 男 8 42 119 115
137 男 8 137 111 116
151 男 8 102 8 48
154 男 8 75 56 147
179 男 8 19 95 48
189 男 8 94 109 33
200 男 8 135 10 122
205 男 8 86 86 82
211 男 8 64 18 9
227 男 8 122 147 74
258 男 8 99 22 146
279 男 8 124 83 36
# 筛选列后按sex单分组
df[['Python','Math']].groupby(by = df['sex'])
for name ,group in df[['Python','Math']].groupby(by = df['sex']):
print(name)
print(group)
输出:
女
Python Math
3 99 132
4 58 1
8 37 141
10 71 64
11 35 66
.. ... ...
294 146 41
295 42 18
296 148 20
297 129 28
298 100 41
[158 rows x 2 columns]
男
Python Math
0 57 99
1 13 112
2 62 142
5 144 147
6 143 107
.. ... ...
286 54 93
288 42 115
290 125 114
291 35 17
299 6 75
[142 rows x 2 columns]
# 筛选列后按sex,class多分组
df[['Python','Math']].groupby(by = [df['sex'],df['class']])
for name ,group in df[['Python','Math']].groupby(by = [df['sex'],df['class']]):
print(name)
print(group)
输出:
('女', 1)
Python Math
23 40 73
42 101 79
44 43 90
53 99 86
65 50 69
104 94 109
120 109 48
140 122 73
152 128 139
156 58 101
176 76 123
239 90 47
242 80 84
244 136 146
256 107 69
257 3 88
264 104 145
270 32 64
278 70 61
294 146 41
('女', 2)
Python Math
8 37 141
21 69 104
22 144 12
27 16 115
43 25 103
46 33 42
56 13 15
83 95 35
97 17 96
126 91 1
127 119 48
130 123 51
146 5 46
153 16 14
161 83 3
188 134 138
190 2 51
198 46 80
213 60 150
225 133 110
......
('男', 7)
Python Math
30 10 63
67 110 42
78 114 133
79 105 43
117 142 121
118 55 48
134 73 120
182 120 23
204 10 28
212 32 110
214 109 149
241 62 19
251 81 49
255 133 86
265 79 6
266 145 77
268 3 27
('男', 8)
Python Math
69 134 141
81 114 20
89 67 72
106 42 119
137 137 111
151 102 8
154 75 56
179 19 95
189 94 109
200 135 10
205 86 86
211 64 18
227 122 147
258 99 22
279 124 83
#根据数据类型进行分组
df.dtypes # 生成列属性对应的Series,指明列名之间的关系
df.groupby(df.dtypes,axis = 1)
for name,group in df.groupby(df.dtypes,axis = 1): # 按列来分组
print(name,group)
输出:
int32 class Python Math En
0 4 57 99 35
1 5 13 112 30
2 3 62 142 29
3 5 99 132 88
4 3 58 1 123
.. ... ... ... ...
295 3 42 18 81
296 4 148 20 117
297 4 129 28 29
298 6 100 41 129
299 3 6 75 28
[300 rows x 4 columns]
object sex
0 男
1 男
2 男
3 女
4 女
.. ..
295 女
296 女
297 女
298 女
299 男
[300 rows x 1 columns]
# 生成列属性对应的字典,指明列名之间的关系
mapping={
'sex':'red','class':'red','Python':'blue','Math':'blue','En':'red'}
df.groupby(mapping,axis=1)
for name,group in df.groupby(mapping,axis=1): # 按列来分组
print(name,group)
输出:
blue
Python Math
0 57 99
1 13 112
2 62 142
3 99 132
4 58 1
.. ... ...
295 42 18
296 148 20
297 129 28
298 100 41
299 6 75
[300 rows x 2 columns]
red
sex class En
0 男 4 35
1 男 5 30
2 男 3 29
3 女 5 88
4 女 3 123
.. .. ... ...
295 女 3 81
296 女 4 117
297 女 4 29
298 女 6 129
299 男 3 28
[300 rows x 3 columns]
# 生成列属性对应的Series,指明列名之间的关系
map_series=pd.Series(mapping)
df.groupby(map_series,axis=1)
for name,group in df.groupby(mapping,axis=1): # 按列来分组
print(name,group)
输出:
blue Python Math
0 57 99
1 13 112
2 62 142
3 99 132
4 58 1
.. ... ...
295 42 18
296 148 20
297 129 28
298 100 41
299 6 75
[300 rows x 2 columns]
red sex class En
0 男 4 35
1 男 5 30
2 男 3 29
3 女 5 88
4 女 3 123
.. .. ... ...
295 女 3 81
296 女 4 117
297 女 4 29
298 女 6 129
299 男 3 28
[300 rows x 3 columns]
# 下面两段语句功能一样(代码糖)
df.groupby('sex')['Python']
df['Python'].groupby(df['sex'])
for name,group in df.groupby('sex')['Python']:
print(name,group)
for name,group in df['Python'].groupby(df['sex']):
print(name,group)
输出:
女 3 99
4 58
8 37
10 71
11 35
...
294 146
295 42
296 148
297 129
298 100
Name: Python, Length: 158, dtype: int32
男 0 57
1 13
2 62
5 144
6 143
...
286 54
288 42
290 125
291 35
299 6
Name: Python, Length: 142, dtype: int32
女 3 99
4 58
8 37
10 71
11 35
...
294 146
295 42
296 148
297 129
298 100
Name: Python, Length: 158, dtype: int32
男 0 57
1 13
2 62
5 144
6 143
...
286 54
288 42
290 125
291 35
299 6
Name: Python, Length: 142, dtype: int32
4.2 分组聚合
# Math,Python根据性别分组后的最大值
df.groupby(by = 'sex')[['Python','Math']].max()
输出:
| Python | Math | |
|---|---|---|
| sex | ||
| 女 | 150 | 150 |
| 男 | 145 | 149 |
# 统计各班的平均分
df.groupby(by = ['sex','class']).mean().round(1)
输出:
| Python | Math | En | ||
|---|---|---|---|---|
| sex | class | |||
| 女 | 1 | 84.4 | 86.8 | 85.1 |
| 2 | 63.0 | 67.8 | 78.0 | |
| 3 | 85.4 | 77.0 | 65.5 | |
| 4 | 82.4 | 68.0 | 74.3 | |
| 5 | 72.0 | 75.0 | 72.0 | |
| 6 | 65.2 | 65.4 | 67.4 | |
| 7 | 80.3 | 61.2 | 61.4 | |
| 8 | 85.7 | 63.4 | 67.9 | |
| 男 | 1 | 73.8 | 73.8 | 80.1 |
| 2 | 80.8 | 70.7 | 82.6 | |
| 3 | 68.8 | 57.1 | 62.5 | |
| 4 | 59.2 | 71.0 | 69.0 | |
| 5 | 84.3 | 83.2 | 74.0 | |
| 6 | 72.1 | 85.1 | 67.9 | |
| 7 | 81.4 | 67.3 | 69.3 | |
| 8 | 94.3 | 73.1 | 79.5 |
# 统计各个班级男女人数
df11 = df.groupby(by = ['sex','class']).size() # 显示元素个数,包含NaN值
# 统计各列的元素个数,需指定列后才能与.size一致,不包含NaN值
df22 = df.groupby(by = ['sex','class'])['Python'].count()
输出df11:
sex class
女 1 20
2 20
3 21
4 22
5 23
6 16
7 18
8 18
男 1 22
2 18
3 14
4 20
5 18
6 18
7 17
8 15
dtype: int64
输出df22:
sex class
女 1 20
2 20
3 21
4 22
5 23
6 16
7 18
8 18
男 1 22
2 18
3 14
4 20
5 18
6 18
7 17
8 15
Name: Python, dtype: int64
# 之前学的描述性统计方法也可直接运用
df.groupby(by = ['sex','class']).describe().round(1)
输出:
| Python | Math | En | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | count | mean | ... | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | ||
| sex | class | |||||||||||||||||||||
| 女 | 1 | 20.0 | 84.4 | 37.8 | 3.0 | 56.0 | 92.0 | 107.5 | 146.0 | 20.0 | 86.8 | ... | 103.0 | 146.0 | 20.0 | 85.1 | 43.9 | 1.0 | 39.5 | 95.0 | 119.2 | 142.0 |
| 2 | 20.0 | 63.0 | 48.6 | 2.0 | 16.8 | 53.0 | 101.0 | 144.0 | 20.0 | 67.8 | ... | 105.5 | 150.0 | 20.0 | 78.0 | 44.1 | 1.0 | 40.5 | 81.5 | 108.5 | 148.0 | |
| 3 | 21.0 | 85.4 | 37.8 | 16.0 | 58.0 | 75.0 | 123.0 | 145.0 | 21.0 | 77.0 | ... | 114.0 | 149.0 | 21.0 | 65.5 | 43.3 | 3.0 | 28.0 | 75.0 | 90.0 | 146.0 | |
| 4 | 22.0 | 82.4 | 52.4 | 4.0 | 30.2 | 77.5 | 132.5 | 148.0 | 22.0 | 68.0 | ... | 89.8 | 147.0 | 22.0 | 74.3 | 47.8 | 4.0 | 34.5 | 74.5 | 114.5 | 148.0 | |
| 5 | 23.0 | 72.0 | 42.7 | 5.0 | 37.0 | 76.0 | 99.5 | 150.0 | 23.0 | 75.0 | ... | 102.5 | 149.0 | 23.0 | 72.0 | 37.4 | 15.0 | 42.0 | 74.0 | 95.5 | 133.0 | |
| 6 | 16.0 | 65.2 | 36.8 | 0.0 | 42.2 | 71.0 | 85.0 | 128.0 | 16.0 | 65.4 | ... | 88.8 | 149.0 | 16.0 | 67.4 | 41.2 | 3.0 | 35.8 | 71.5 | 100.2 | 129.0 | |
| 7 | 18.0 | 80.3 | 29.8 | 22.0 | 60.8 | 76.0 | 105.2 | 133.0 | 18.0 | 61.2 | ... | 91.5 | 150.0 | 18.0 | 61.4 | 42.7 | 5.0 | 22.2 | 53.5 | 83.5 | 136.0 | |
| 8 | 18.0 | 85.7 | 43.4 | 8.0 | 49.5 | 92.5 | 118.8 | 140.0 | 18.0 | 63.4 | ... | 94.0 | 133.0 | 18.0 | 67.9 | 41.5 | 4.0 | 35.5 | 52.5 | 94.5 | 136.0 | |
| 男 | 1 | 22.0 | 73.8 | 36.1 | 10.0 | 44.0 | 75.0 | 104.8 | 134.0 | 22.0 | 73.8 | ... | 114.2 | 141.0 | 22.0 | 80.1 | 40.6 | 12.0 | 43.5 | 86.5 | 112.8 | 136.0 |
| 2 | 18.0 | 80.8 | 42.0 | 9.0 | 50.5 | 69.0 | 125.2 | 140.0 | 18.0 | 70.7 | ... | 110.2 | 147.0 | 18.0 | 82.6 | 38.6 | 12.0 | 57.2 | 87.5 | 115.0 | 136.0 | |
| 3 | 14.0 | 68.8 | 46.7 | 0.0 | 36.2 | 72.0 | 108.8 | 134.0 | 14.0 | 57.1 | ... | 72.0 | 142.0 | 14.0 | 62.5 | 49.5 | 8.0 | 19.0 | 46.5 | 100.2 | 143.0 | |
| 4 | 20.0 | 59.2 | 39.6 | 0.0 | 25.8 | 58.5 | 88.0 | 125.0 | 20.0 | 71.0 | ... | 106.0 | 114.0 | 20.0 | 69.0 | 43.7 | 1.0 | 28.8 | 68.5 | 94.2 | 140.0 | |
| 5 | 18.0 | 84.3 | 49.4 | 1.0 | 56.2 | 96.0 | 122.0 | 145.0 | 18.0 | 83.2 | ... | 115.0 | 147.0 | 18.0 | 74.0 | 49.0 | 8.0 | 32.2 | 82.5 | 104.2 | 147.0 | |
| 6 | 18.0 | 72.1 | 49.9 | 0.0 | 33.0 | 63.5 | 126.0 | 143.0 | 18.0 | 85.1 | ... | 119.8 | 146.0 | 18.0 | 67.9 | 41.4 | 3.0 | 45.2 | 65.0 | 93.8 | 144.0 | |
| 7 | 17.0 | 81.4 | 46.8 | 3.0 | 55.0 | 81.0 | 114.0 | 145.0 | 17.0 | 67.3 | ... | 110.0 | 149.0 | 17.0 | 69.3 | 42.2 | 8.0 | 38.0 | 66.0 | 116.0 | 132.0 | |
| 8 | 15.0 | 94.3 | 35.5 | 19.0 | 71.0 | 99.0 | 123.0 | 137.0 | 15.0 | 73.1 | ... | 110.0 | 147.0 | 15.0 | 79.5 | 45.4 | 9.0 | 42.0 | 82.0 | 115.5 | 147.0 | |
16 rows × 24 columns
# TIPS:
# as_index=False:把index的标题位置上移,即对齐列名与索引名,为实现后续的工作提供了基础。
df5=df.groupby(by = 'sex').sum()
df6=df.groupby(by = 'sex',as_index=False).sum()
df6=df.groupby(by = 'sex').sum().reset_index() # 代码糖,效果同上
输出df5:
| class | Python | Math | En | |
|---|---|---|---|---|
| sex | ||||
| 女 | 692 | 12243 | 11219 | 11336 |
| 男 | 617 | 10837 | 10385 | 10429 |
输出df6:
| sex | class | Python | Math | En | |
|---|---|---|---|---|---|
| 0 | 女 | 692 | 12243 | 11219 | 11336 |
| 1 | 男 | 617 | 10837 | 10385 | 10429 |
4.3 分组聚合:apply、transform方法
apply聚合后数据量变少,transform聚合后数据量不变,具体过程入下图:

# apply聚合结果,同一个索引值保留一个值
df.groupby(by = ['sex','class'])[['Python','En']].apply(np.mean).round(1)
输出:
| Python | En | ||
|---|---|---|---|
| sex | class | ||
| 女 | 1 | 84.4 | 85.1 |
| 2 | 63.0 | 78.0 | |
| 3 | 85.4 | 65.5 | |
| 4 | 82.4 | 74.3 | |
| 5 | 72.0 | 72.0 | |
| 6 | 65.2 | 67.4 | |
| 7 | 80.3 | 61.4 | |
| 8 | 85.7 | 67.9 | |
| 男 | 1 | 73.8 | 80.1 |
| 2 | 80.8 | 82.6 | |
| 3 | 68.8 | 62.5 | |
| 4 | 59.2 | 69.0 | |
| 5 | 84.3 | 74.0 | |
| 6 | 72.1 | 67.9 | |
| 7 | 81.4 | 69.3 | |
| 8 | 94.3 | 79.5 |
# transform 计算,返回的结果还是原来的数据长度
df.groupby(by = ['sex','class'])[['Python','En']].transform(np.mean).round(1)
输出:
| Python | En | |
|---|---|---|
| 0 | 59.2 | 69.0 |
| 1 | 84.3 | 74.0 |
| 2 | 68.8 | 62.5 |
| 3 | 72.0 | 72.0 |
| 4 | 85.4 | 65.5 |
| ... | ... | ... |
| 295 | 85.4 | 65.5 |
| 296 | 82.4 | 74.3 |
| 297 | 82.4 | 74.3 |
| 298 | 65.2 | 67.4 |
| 299 | 68.8 | 62.5 |
300 rows × 2 columns
4.4 分组聚合:agg方法
# 同一个数据可以用不同的聚合方法
df.groupby(by = ['sex','class']).agg([np.mean,np.max,np.min]).round(1)
输出:
| Python | Math | En | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mean | amax | amin | mean | amax | amin | mean | amax | amin | ||
| sex | class | |||||||||
| 女 | 1 | 84.4 | 146 | 3 | 86.8 | 146 | 41 | 85.1 | 142 | 1 |
| 2 | 63.0 | 144 | 2 | 67.8 | 150 | 1 | 78.0 | 148 | 1 | |
| 3 | 85.4 | 145 | 16 | 77.0 | 149 | 1 | 65.5 | 146 | 3 | |
| 4 | 82.4 | 148 | 4 | 68.0 | 147 | 1 | 74.3 | 148 | 4 | |
| 5 | 72.0 | 150 | 5 | 75.0 | 149 | 3 | 72.0 | 133 | 15 | |
| 6 | 65.2 | 128 | 0 | 65.4 | 149 | 9 | 67.4 | 129 | 3 | |
| 7 | 80.3 | 133 | 22 | 61.2 | 150 | 4 | 61.4 | 136 | 5 | |
| 8 | 85.7 | 140 | 8 | 63.4 | 133 | 5 | 67.9 | 136 | 4 | |
| 男 | 1 | 73.8 | 134 | 10 | 73.8 | 141 | 2 | 80.1 | 136 | 12 |
| 2 | 80.8 | 140 | 9 | 70.7 | 147 | 1 | 82.6 | 136 | 12 | |
| 3 | 68.8 | 134 | 0 | 57.1 | 142 | 2 | 62.5 | 143 | 8 | |
| 4 | 59.2 | 125 | 0 | 71.0 | 114 | 0 | 69.0 | 140 | 1 | |
| 5 | 84.3 | 145 | 1 | 83.2 | 147 | 0 | 74.0 | 147 | 8 | |
| 6 | 72.1 | 143 | 0 | 85.1 | 146 | 12 | 67.9 | 144 | 3 | |
| 7 | 81.4 | 145 | 3 | 67.3 | 149 | 6 | 69.3 | 132 | 8 | |
| 8 | 94.3 | 137 | 19 | 73.1 | 147 | 8 | 79.5 | 147 | 9 | |
# 可以给方法起别名
df.groupby(by = ['sex','class']).agg([('平均值',np.mean),('最大值',np.max),('最小值',np.min)]).round(1)
输出:
| Python | Math | En | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 平均值 | 最大值 | 最小值 | 平均值 | 最大值 | 最小值 | 平均值 | 最大值 | 最小值 | ||
| sex | class | |||||||||
| 女 | 1 | 84.4 | 146 | 3 | 86.8 | 146 | 41 | 85.1 | 142 | 1 |
| 2 | 63.0 | 144 | 2 | 67.8 | 150 | 1 | 78.0 | 148 | 1 | |
| 3 | 85.4 | 145 | 16 | 77.0 | 149 | 1 | 65.5 | 146 | 3 | |
| 4 | 82.4 | 148 | 4 | 68.0 | 147 | 1 | 74.3 | 148 | 4 | |
| 5 | 72.0 | 150 | 5 | 75.0 | 149 | 3 | 72.0 | 133 | 15 | |
| 6 | 65.2 | 128 | 0 | 65.4 | 149 | 9 | 67.4 | 129 | 3 | |
| 7 | 80.3 | 133 | 22 | 61.2 | 150 | 4 | 61.4 | 136 | 5 | |
| 8 | 85.7 | 140 | 8 | 63.4 | 133 | 5 | 67.9 | 136 | 4 | |
| 男 | 1 | 73.8 | 134 | 10 | 73.8 | 141 | 2 | 80.1 | 136 | 12 |
| 2 | 80.8 | 140 | 9 | 70.7 | 147 | 1 | 82.6 | 136 | 12 | |
| 3 | 68.8 | 134 | 0 | 57.1 | 142 | 2 | 62.5 | 143 | 8 | |
| 4 | 59.2 | 125 | 0 | 71.0 | 114 | 0 | 69.0 | 140 | 1 | |
| 5 | 84.3 | 145 | 1 | 83.2 | 147 | 0 | 74.0 | 147 | 8 | |
| 6 | 72.1 | 143 | 0 | 85.1 | 146 | 12 | 67.9 | 144 | 3 | |
| 7 | 81.4 | 145 | 3 | 67.3 | 149 | 6 | 69.3 | 132 | 8 | |
| 8 | 94.3 | 137 | 19 | 73.1 | 147 | 8 | 79.5 | 147 | 9 | |
# 可以对不同列进行不同计算
df.groupby(by = ['sex','class']).agg({
'Python':np.max,'Math':np.min,'En':np.mean}).round(1)
输出:
| Python | Math | En | ||
|---|---|---|---|---|
| sex | class | |||
| 女 | 1 | 146 | 41 | 85.1 |
| 2 | 144 | 1 | 78.0 | |
| 3 | 145 | 1 | 65.5 | |
| 4 | 148 | 1 | 74.3 | |
| 5 | 150 | 3 | 72.0 | |
| 6 | 128 | 9 | 67.4 | |
| 7 | 133 | 4 | 61.4 | |
| 8 | 140 | 5 | 67.9 | |
| 男 | 1 | 134 | 2 | 80.1 |
| 2 | 140 | 1 | 82.6 | |
| 3 | 134 | 2 | 62.5 | |
| 4 | 125 | 0 | 69.0 | |
| 5 | 145 | 0 | 74.0 | |
| 6 | 143 | 12 | 67.9 | |
| 7 | 145 | 6 | 69.3 | |
| 8 | 137 | 8 | 79.5 |
4.5 分组聚合:透视表
# 创建透视表,此效果与上面apply方法一致
df.pivot_table(values=['Python','En'],index = ['sex','class'],aggfunc='mean').round(1)
输出:
| En | Python | ||
|---|---|---|---|
| sex | class | ||
| 女 | 1 | 85.1 | 84.4 |
| 2 | 78.0 | 63.0 | |
| 3 | 65.5 | 85.4 | |
| 4 | 74.3 | 82.4 | |
| 5 | 72.0 | 72.0 | |
| 6 | 67.4 | 65.2 | |
| 7 | 61.4 | 80.3 | |
| 8 | 67.9 | 85.7 | |
| 男 | 1 | 80.1 | 73.8 |
| 2 | 82.6 | 80.8 | |
| 3 | 62.5 | 68.8 | |
| 4 | 69.0 | 59.2 | |
| 5 | 74.0 | 84.3 | |
| 6 | 67.9 | 72.1 | |
| 7 | 69.3 | 81.4 | |
| 8 | 79.5 | 94.3 |
# 多方法透视
df.pivot_table(values=['Python','Math','En'], # 要透视的值
index = ['sex','class'], # 索引,根据什么进行透视,即分组
aggfunc={
'Python':[('平均值',np.mean)], #透视的方法
'Math':[('最小值',np.min),('最大值',np.max)],
'En':[('标准差',np.std),('方差',np.var),('计数',np.size)]}).round(1)
输出:
| En | Math | Python | |||||
|---|---|---|---|---|---|---|---|
| 方差 | 标准差 | 计数 | 最大值 | 最小值 | 平均值 | ||
| sex | class | ||||||
| 女 | 1 | 1929.7 | 43.9 | 20.0 | 146 | 41 | 84.4 |
| 2 | 1948.9 | 44.1 | 20.0 | 150 | 1 | 63.0 | |
| 3 | 1878.3 | 43.3 | 21.0 | 149 | 1 | 85.4 | |
| 4 | 2282.4 | 47.8 | 22.0 | 147 | 1 | 82.4 | |
| 5 | 1401.6 | 37.4 | 23.0 | 149 | 3 | 72.0 | |
| 6 | 1694.9 | 41.2 | 16.0 | 149 | 9 | 65.2 | |
| 7 | 1819.8 | 42.7 | 18.0 | 150 | 4 | 80.3 | |
| 8 | 1724.3 | 41.5 | 18.0 | 133 | 5 | 85.7 | |
| 男 | 1 | 1648.8 | 40.6 | 22.0 | 141 | 2 | 73.8 |
| 2 | 1490.0 | 38.6 | 18.0 | 147 | 1 | 80.8 | |
| 3 | 2445.7 | 49.5 | 14.0 | 142 | 2 | 68.8 | |
| 4 | 1911.3 | 43.7 | 20.0 | 114 | 0 | 59.2 | |
| 5 | 2397.8 | 49.0 | 18.0 | 147 | 0 | 84.3 | |
| 6 | 1711.9 | 41.4 | 18.0 | 146 | 12 | 72.1 | |
| 7 | 1779.6 | 42.2 | 17.0 | 149 | 6 | 81.4 | |
| 8 | 2061.6 | 45.4 | 15.0 | 147 | 8 | 94.3 | |
# agg方法与上述透视表效果一致
df.groupby(by = ['sex','class']).agg({
'Python':[('平均值',np.mean)],
'Math':[('最小值',np.min),('最大值',np.max)],
'En':[('标准差',np.std),('方差',np.var),('计数',np.size)]}).round(1)
输出:
| Python | Math | En | |||||
|---|---|---|---|---|---|---|---|
| 平均值 | 最小值 | 最大值 | 标准差 | 方差 | 计数 | ||
| sex | class | ||||||
| 女 | 1 | 84.4 | 41 | 146 | 43.9 | 1929.7 | 20 |
| 2 | 63.0 | 1 | 150 | 44.1 | 1948.9 | 20 | |
| 3 | 85.4 | 1 | 149 | 43.3 | 1878.3 | 21 | |
| 4 | 82.4 | 1 | 147 | 47.8 | 2282.4 | 22 | |
| 5 | 72.0 | 3 | 149 | 37.4 | 1401.6 | 23 | |
| 6 | 65.2 | 9 | 149 | 41.2 | 1694.9 | 16 | |
| 7 | 80.3 | 4 | 150 | 42.7 | 1819.8 | 18 | |
| 8 | 85.7 | 5 | 133 | 41.5 | 1724.3 | 18 | |
| 男 | 1 | 73.8 | 2 | 141 | 40.6 | 1648.8 | 22 |
| 2 | 80.8 | 1 | 147 | 38.6 | 1490.0 | 18 | |
| 3 | 68.8 | 2 | 142 | 49.5 | 2445.7 | 14 | |
| 4 | 59.2 | 0 | 114 | 43.7 | 1911.3 | 20 | |
| 5 | 84.3 | 0 | 147 | 49.0 | 2397.8 | 18 | |
| 6 | 72.1 | 12 | 146 | 41.4 | 1711.9 | 18 | |
| 7 | 81.4 | 6 | 149 | 42.2 | 1779.6 | 17 | |
| 8 | 94.3 | 8 | 147 | 45.4 | 2061.6 | 15 | |
5 时间序列
5.1 时间戳操作
import numpy as np
import pandas as pd
import time
# 时刻数据,表示某一个时间点
pd.Timestamp('2020.09.15 20')
pd.Timestamp('2020-09-15 20')
输出:
Timestamp('2020-09-15 20:00:00')
# 时期数据,表示一段时间
pd.Period('2020.9.15',freq = 'M')
输出:
Period('2020-09', 'M')
# 生成10个日期数据,类型为dtype='datetime64[ns]',以纳秒为单位
index = pd.date_range('2020.09.15',freq='D',periods=10)
输出:
DatetimeIndex(['2020-09-15', '2020-09-16', '2020-09-17', '2020-09-18',
'2020-09-19', '2020-09-20', '2020-09-21', '2020-09-22',
'2020-09-23', '2020-09-24'],
dtype='datetime64[ns]', freq='D')
# 同样生成10个日期数据,类型为dtype='period[D]',以天为单位
pd.period_range('2020.09.15',periods=10)
输出:
PeriodIndex(['2020-09-15', '2020-09-16', '2020-09-17', '2020-09-18',
'2020-09-19', '2020-09-20', '2020-09-21', '2020-09-22',
'2020-09-23', '2020-09-24'],
dtype='period[D]', freq='D')
# 以日期为Series索引
pd.Series(np.random.randint(0,10,size = 10),index = index)
输出:
2020-09-15 3
2020-09-16 0
2020-09-17 3
2020-09-18 6
2020-09-19 0
2020-09-20 1
2020-09-21 0
2020-09-22 6
2020-09-23 6
2020-09-24 2
Freq: D, dtype: int32
# 时间戳的转换,将时间转换成统一格式
pd.to_datetime(['2020.09.15','2020-09-15','2020/09/15','15/09/2020'])
输出:
DatetimeIndex(['2020-09-15', '2020-09-15', '2020-09-15', '2020-09-15'], dtype='datetime64[ns]', freq=None)
# 将秒转换为日期时间
time.time() # 当前世界标准时间为:1617090027.0997424
pd.to_datetime(1617090027,unit='s')
输出:
Timestamp('2021-03-30 07:40:27')
# 将毫秒转换为日期时间
# 世界标准时间
dt = pd.to_datetime(1617090027099,unit='ms')
输出:
Timestamp('2021-03-30 07:40:27.099000')
# 将世界标准时间转换为北京时间
bj = dt + pd.DateOffset(hours = 8)
输出:
Timestamp('2021-03-30 15:40:27.099000')
# 100天之后的日期
bj + pd.DateOffset(days = 100)
输出:
Timestamp('2021-07-08 15:40:27.099000')
5.2 时间戳索引
# 数据准备
ts = pd.Series(np.random.randint(0,300,size = 200),
index=pd.date_range('2020-09-15',freq='D',periods=200))
输出:
2020-09-15 1
2020-09-16 84
2020-09-17 207
2020-09-18 292
2020-09-19 282
2020-09-20 146
2020-09-21 65
2020-09-22 6
2020-09-23 71
2020-09-24 19
2020-09-25 174
2020-09-26 261
2020-09-27 48
2020-09-28 184
2020-09-29 7
2020-09-30 167
...
2021-03-21 27
2021-03-22 80
2021-03-23 40
2021-03-24 83
2021-03-25 20
2021-03-26 17
2021-03-27 196
2021-03-28 253
2021-03-29 222
2021-03-30 21
2021-03-31 265
2021-04-01 270
2021-04-02 60
Freq: D, Length: 200, dtype: int32
# 对ts进行索引
ts['2020/09/18']
输出:
292
# 对ts进行切片操作
ts['2020/09/15':'2020.09.20']
输出:
2020-09-15 1
2020-09-16 84
2020-09-17 207
2020-09-18 292
2020-09-19 282
2020-09-20 146
Freq: D, dtype: int32
# 获取9月份的数据
ts['2020/09']
输出:
2020-09-15 1
2020-09-16 84
2020-09-17 207
2020-09-18 292
2020-09-19 282
2020-09-20 146
2020-09-21 65
2020-09-22 6
2020-09-23 71
2020-09-24 19
2020-09-25 174
2020-09-26 261
2020-09-27 48
2020-09-28 184
2020-09-29 7
2020-09-30 167
Freq: D, dtype: int32
# 获取2021年的数据
ts['2021']
输出:
2021-01-01 61
2021-01-02 278
2021-01-03 295
2021-01-04 180
2021-01-05 30
2021-01-06 15
2021-01-07 212
2021-01-08 291
2021-01-09 250
2021-01-10 261
2021-01-11 50
2021-01-12 82
2021-01-13 198
2021-01-14 72
2021-01-15 154
...
2021-03-21 27
2021-03-22 80
2021-03-23 40
2021-03-24 83
2021-03-25 20
2021-03-26 17
2021-03-27 196
2021-03-28 253
2021-03-29 222
2021-03-30 21
2021-03-31 265
2021-04-01 270
2021-04-02 60
Freq: D, Length: 92, dtype: int32
# 不同的用法实现的效果一致
ts[pd.Timestamp('2020.09.15')]
ts['2020.09.15']
输出:
1
# 不同的用法实现的效果一致
ts[pd.Timestamp('2020.09.15'):pd.Timestamp('2020.09.20')]
ts['2020/09/15':'2020.09.20']
输出:
2020-09-15 1
2020-09-16 84
2020-09-17 207
2020-09-18 292
2020-09-19 282
2020-09-20 146
Freq: D, dtype: int32
# 有间隔的切片
ts[pd.Timestamp('2021.3.1')::3]
输出:
2021-03-01 238
2021-03-04 192
2021-03-07 256
2021-03-10 61
2021-03-13 7
2021-03-16 250
2021-03-19 98
2021-03-22 80
2021-03-25 20
2021-03-28 253
2021-03-31 265
Freq: 3D, dtype: int32
# 切片的另一种方法
ts[pd.date_range('2020.09.15',freq='D',periods=15)]
输出:
2020-09-15 1
2020-09-16 84
2020-09-17 207
2020-09-18 292
2020-09-19 282
2020-09-20 146
2020-09-21 65
2020-09-22 6
2020-09-23 71
2020-09-24 19
2020-09-25 174
2020-09-26 261
2020-09-27 48
2020-09-28 184
2020-09-29 7
Freq: D, dtype: int32
# 获取索引的年份
ts.index.year
输出:
Int64Index([2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020,
...
2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021],
dtype='int64', length=200)
# dayofyear表示这一年的第多少天
ts.index.dayofyear
输出:
Int64Index([259, 260, 261, 262, 263, 264, 265, 266, 267, 268,
...
83, 84, 85, 86, 87, 88, 89, 90, 91, 92],
dtype='int64', length=200)
# weekofyear表示这一年中第多少周
ts.index.weekofyear
输出:
Int64Index([38, 38, 38, 38, 38, 38, 39, 39, 39, 39,
...
12, 12, 12, 12, 12, 13, 13, 13, 13, 13],
dtype='int64', length=200)
5.3 时间序列常用方法
在做时间序列相关的⼯作时,经常要对时间做⼀些移动、滞后、频率转换、采样等相关操作,我们来看下这些操作如何使用。
# 数据准备
ts = pd.Series(np.random.randint(0,1024,size = 366),
index = pd.date_range('2020/1/1',freq='D',periods=366))
输出:
2020-01-01 766
2020-01-02 969
2020-01-03 85
2020-01-04 621
2020-01-05 679
2020-01-06 69
2020-01-07 433
2020-01-08 932
2020-01-09 919
2020-01-10 322
2020-01-11 907
2020-01-12 568
2020-01-13 221
2020-01-14 485
2020-01-15 252
...
2020-12-21 279
2020-12-22 192
2020-12-23 36
2020-12-24 412
2020-12-25 286
2020-12-26 0
2020-12-27 351
2020-12-28 602
2020-12-29 272
2020-12-30 325
2020-12-31 379
Freq: D, Length: 366, dtype: int32
5.3.1 数据移动
# 数据向后移动2行
ts.shift(periods=2)
输出:
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 766.0
2020-01-04 969.0
2020-01-05 85.0
2020-01-06 621.0
2020-01-07 679.0
2020-01-08 69.0
2020-01-09 433.0
2020-01-10 932.0
2020-01-11 919.0
2020-01-12 322.0
2020-01-13 907.0
2020-01-14 568.0
2020-01-15 221.0
...
2020-12-21 683.0
2020-12-22 733.0
2020-12-23 279.0
2020-12-24 192.0
2020-12-25 36.0
2020-12-26 412.0
2020-12-27 286.0
2020-12-28 0.0
2020-12-29 351.0
2020-12-30 602.0
2020-12-31 272.0
Freq: D, Length: 366, dtype: float64
# 数据向前移动2行
ts.shift(periods=-2)
输出:
2020-01-01 85.0
2020-01-02 621.0
2020-01-03 679.0
2020-01-04 69.0
2020-01-05 433.0
2020-01-06 932.0
2020-01-07 919.0
2020-01-08 322.0
2020-01-09 907.0
2020-01-10 568.0
2020-01-11 221.0
2020-01-12 485.0
2020-01-13 252.0
2020-01-14 445.0
2020-01-15 585.0
...
2020-12-21 36.0
2020-12-22 412.0
2020-12-23 286.0
2020-12-24 0.0
2020-12-25 351.0
2020-12-26 602.0
2020-12-27 272.0
2020-12-28 325.0
2020-12-29 379.0
2020-12-30 NaN
2020-12-31 NaN
Freq: D, Length: 366, dtype: float64
5.3.2 日期移动
# 第一个索引日期加5天,如果是负数则减
ts.shift(periods=5,freq=pd.tseries.offsets.Day())
输出:
2020-01-06 766
2020-01-07 969
2020-01-08 85
2020-01-09 621
2020-01-10 679
2020-01-11 69
2020-01-12 433
2020-01-13 932
2020-01-14 919
2020-01-15 322
2020-01-16 907
2020-01-17 568
2020-01-18 221
2020-01-19 485
2020-01-20 252
...
2020-12-21 0
2020-12-22 473
2020-12-23 359
2020-12-24 683
2020-12-25 733
2020-12-26 279
2020-12-27 192
2020-12-28 36
2020-12-29 412
2020-12-30 286
2020-12-31 0
2021-01-01 351
2021-01-02 602
2021-01-03 272
2021-01-04 325
2021-01-05 379
Freq: D, Length: 366, dtype: int32
# 时间后移5行,如果是负数则前移
ts.shift(periods=-5,freq=pd.tseries.offsets.MonthOffset())
输出:
2019-08-01 766
2019-08-02 969
2019-08-03 85
2019-08-04 621
2019-08-05 679
2019-08-06 69
2019-08-07 433
2019-08-08 932
2019-08-09 919
2019-08-10 322
2019-08-11 907
2019-08-12 568
2019-08-13 221
2019-08-14 485
2019-08-15 252
...
2020-07-21 279
2020-07-22 192
2020-07-23 36
2020-07-24 412
2020-07-25 286
2020-07-26 0
2020-07-27 351
2020-07-28 602
2020-07-29 272
2020-07-30 325
2020-07-31 379
Freq: D, Length: 366, dtype: int32
5.3.3 频率转换
# 频率由365天转换成12月,数据变少
# 数据仅取对应日期的数据
ts.asfreq(pd.tseries.offsets.MonthEnd())
输出:
2020-01-31 847
2020-02-29 640
2020-03-31 563
2020-04-30 13
2020-05-31 913
2020-06-30 369
2020-07-31 543
2020-08-31 842
2020-09-30 684
2020-10-31 640
2020-11-30 242
2020-12-31 379
Freq: M, dtype: int32
# 频率由天转换成周
ts.asfreq(pd.tseries.offsets.Week())
输出:
2020-01-01 766
2020-01-08 932
2020-01-15 252
2020-01-22 376
2020-01-29 647
...
2020-12-02 438
2020-12-09 139
2020-12-16 0
2020-12-23 36
2020-12-30 325
Freq: W, dtype: int32
# 时间频率转换由天变换为小时,
# 数据变多,存在空数据
ts.asfreq(pd.tseries.offsets.Hour(),fill_value=0)
输出:
2020-01-01 00:00:00 766
2020-01-01 01:00:00 0
2020-01-01 02:00:00 0
2020-01-01 03:00:00 0
2020-01-01 04:00:00 0
2020-01-01 05:00:00 0
2020-01-01 06:00:00 0
2020-01-01 07:00:00 0
2020-01-01 08:00:00 0
2020-01-01 09:00:00 0
2020-01-01 10:00:00 0
2020-01-01 11:00:00 0
2020-01-01 12:00:00 0
2020-01-01 13:00:00 0
2020-01-01 14:00:00 0
2020-01-01 15:00:00 0
2020-01-01 16:00:00 0
2020-01-01 17:00:00 0
2020-01-01 18:00:00 0
2020-01-01 19:00:00 0
2020-01-01 20:00:00 0
2020-01-01 21:00:00 0
2020-01-01 22:00:00 0
2020-01-01 23:00:00 0
2020-01-02 00:00:00 969
...
2020-12-30 15:00:00 0
2020-12-30 16:00:00 0
2020-12-30 17:00:00 0
2020-12-30 18:00:00 0
2020-12-30 19:00:00 0
2020-12-30 20:00:00 0
2020-12-30 21:00:00 0
2020-12-30 22:00:00 0
2020-12-30 23:00:00 0
2020-12-31 00:00:00 379
Freq: H, Length: 8761, dtype: int32
5.3.4 重采样
# 时间序列重采样,类似于之前的分组聚合
ts.resample(rule = 'M').agg(np.sum)
输出:
2020-01-31 16407
2020-02-29 16444
2020-03-31 15621
2020-04-30 15164
2020-05-31 14816
2020-06-30 13568
2020-07-31 13389
2020-08-31 14710
2020-09-30 17079
2020-10-31 17749
2020-11-30 14309
2020-12-31 13552
Freq: M, dtype: int32
# 按季度进行重采样累加计算
ts.resample(rule='3M').agg(np.sum).cumsum()
输出:
2020-01-31 16407
2020-04-30 63636
2020-07-31 105409
2020-10-31 154947
2021-01-31 182808
Freq: 3M, dtype: int32
5.3.5 DataFrame重采样
# 数据准备
df = pd.DataFrame(data = {
'price':np.random.randint(0,100,size = 365),
'volume':np.random.randint(0,100,size = 365),
'time':pd.date_range('2020.09.15',periods=365)})
输出:
| price | volume | time | |
|---|---|---|---|
| 0 | 37 | 93 | 2020-09-15 |
| 1 | 89 | 15 | 2020-09-16 |
| 2 | 15 | 79 | 2020-09-17 |
| 3 | 32 | 0 | 2020-09-18 |
| 4 | 12 | 42 | 2020-09-19 |
| 5 | 2 | 18 | 2020-09-20 |
| 6 | 16 | 11 | 2020-09-21 |
| 7 | 53 | 97 | 2020-09-22 |
| 8 | 19 | 95 | 2020-09-23 |
| 9 | 51 | 68 | 2020-09-24 |
| 10 | 77 | 12 | 2020-09-25 |
| 11 | 64 | 20 | 2020-09-26 |
| 12 | 52 | 7 | 2020-09-27 |
| 13 | 72 | 49 | 2020-09-28 |
| 14 | 61 | 77 | 2020-09-29 |
| 15 | 68 | 48 | 2020-09-30 |
| 16 | 24 | 7 | 2020-10-01 |
| 17 | 70 | 55 | 2020-10-02 |
| 18 | 3 | 7 | 2020-10-03 |
| 19 | 36 | 70 | 2020-10-04 |
| 20 | 59 | 62 | 2020-10-05 |
| 21 | 67 | 3 | 2020-10-06 |
| 22 | 78 | 0 | 2020-10-07 |
| 23 | 36 | 35 | 2020-10-08 |
| 24 | 28 | 35 | 2020-10-09 |
| 25 | 59 | 86 | 2020-10-10 |
| 26 | 53 | 56 | 2020-10-11 |
| 27 | 52 | 39 | 2020-10-12 |
| 28 | 47 | 55 | 2020-10-13 |
| 29 | 31 | 29 | 2020-10-14 |
| ... | ... | ... | ... |
| 335 | 79 | 31 | 2021-08-16 |
| 336 | 8 | 82 | 2021-08-17 |
| 337 | 66 | 4 | 2021-08-18 |
| 338 | 41 | 10 | 2021-08-19 |
| 339 | 97 | 37 | 2021-08-20 |
| 340 | 37 | 38 | 2021-08-21 |
| 341 | 42 | 36 | 2021-08-22 |
| 342 | 27 | 26 | 2021-08-23 |
| 343 | 49 | 94 | 2021-08-24 |
| 344 | 30 | 65 | 2021-08-25 |
| 345 | 91 | 93 | 2021-08-26 |
| 346 | 28 | 34 | 2021-08-27 |
| 347 | 58 | 61 | 2021-08-28 |
| 348 | 76 | 90 | 2021-08-29 |
| 349 | 34 | 40 | 2021-08-30 |
| 350 | 32 | 40 | 2021-08-31 |
| 351 | 90 | 11 | 2021-09-01 |
| 352 | 56 | 26 | 2021-09-02 |
| 353 | 8 | 76 | 2021-09-03 |
| 354 | 88 | 44 | 2021-09-04 |
| 355 | 75 | 58 | 2021-09-05 |
| 356 | 15 | 13 | 2021-09-06 |
| 357 | 2 | 16 | 2021-09-07 |
| 358 | 24 | 76 | 2021-09-08 |
| 359 | 51 | 10 | 2021-09-09 |
| 360 | 79 | 57 | 2021-09-10 |
| 361 | 20 | 18 | 2021-09-11 |
| 362 | 42 | 7 | 2021-09-12 |
| 363 | 43 | 7 | 2021-09-13 |
| 364 | 28 | 96 | 2021-09-14 |
# 根据time列进行数据的重采样,基本和分组聚合一致
df.resample(rule = 'M',on = 'time').sum()
# 上述重采样方法和下面之前学过的分组聚合方法得出的结果一致
df.resample(rule = 'M',on = 'time').apply(np.sum)
df.resample(rule = 'M',on = 'time').transform(np.sum)
输出:
| price | volume | |
|---|---|---|
| time | ||
| 2020-09-30 | 720 | 731 |
| 2020-10-31 | 1683 | 1089 |
| 2020-11-30 | 1562 | 1360 |
| 2020-12-31 | 1625 | 1199 |
| 2021-01-31 | 1792 | 1555 |
| 2021-02-28 | 1162 | 1412 |
| 2021-03-31 | 1612 | 1331 |
| 2021-04-30 | 1347 | 1380 |
| 2021-05-31 | 1428 | 1532 |
| 2021-06-30 | 1378 | 1431 |
| 2021-07-31 | 1392 | 1541 |
| 2021-08-31 | 1566 | 1249 |
| 2021-09-30 | 621 | 515 |
总结
Pandas库的亮点:
- 一个快速、高效的DataFrame对象,用于数据操作和综合索引;
- 用于在内存数据结构和不同格式之间读写数据的工具:CSV和文本⽂件、Microsoft Excel、SQL数据库和快速HDF5格式;
- 智能数据对齐和丢失数据的综合处理:在计算中获得基于标签的自动对齐,并轻松地将凌乱的数据操作为有序的形式;
- 数据集的灵活调整和旋转;
- 基于智能标签的切片、花式索引和大型数据集的子集;
- 可以从数据结构中插入和删除列,以实现大小可变;
- 通过在强大的引擎中聚合或转换数据,允许对数据集进行拆分应用组合操作;
- 数据集的高性能合并和连接;
- 层次轴索引提供了在低维数据结构中处理高维数据的直观方法;
- 时间序列-功能:日期范围生成和频率转换、移动窗口统计、移动窗口线性回归、日期转换和滞后。甚至在不丢失数据的情况下创建特定领域的时间偏移和加入时间序列;
- 对性能进行了高度优化,用Cython或C语言编写了关键代码路径;
- Python与Pandas在广泛的学术和商业领域中都有使用,包括金融,神经科学,经济学,统计学,广告,网络分析等。