前言
- 默认读者已经对三级页表的结构有基本的了解;
- 以下所有的内容都可以在 xv6 book、实验指导书和 xv6 源码中找到原始出处;
- 发现有错误或改进的地方时,请不要吝啬您的键盘。

一、准备工作
1、内核内存布局

左边是 Kernel 的虚拟内存布局,右边是映射过去的物理内存布局。系统内的所有进程(包括 Kenel 和用户进程)都坐落在 KERNBASE 到 PHYSTOP 地址之间。Kernel 的 end 地址在 Kernel Data 的结束或是 Free memory 的开始。可以看到,整个 Kernel 的虚拟地址是直接映射在 RAM 上的,并且因此 Trampoline page 和 kernel stack page 发生了两次映射,这是为了 Kernel 方便访问这两处地方。
注意到右边物理内存的布局的最高地址值为 2^56-1,最低为 0,这意味着右边这幅图涵盖了系统内的所有物理内存,说明 Kernel 能够访问绝大部分的地址(说绝大部分是因为虚拟地址总数 2^39 要比物理地址总数小)。用户进程一定会在 RAM 内,Kernel 可以直接映射访问到。
值得一提的是,xv6 并没有用到全部 39 位的虚拟地址。它把最高位舍弃,只用到了剩余 38 位,具体原因好像是和数值类型有关,自己还不太清楚相关细节。
/* kernel/riscv.h */
...
// one beyond the highest possible virtual address.
// MAXVA is actually one bit less than the max allowed by
// Sv39, to avoid having to sign-extend virtual addresses
// that have the high bit set.
#define MAXVA (1L << (9 + 9 + 9 + 12 - 1))2、sbrk()
我们将从 sbrk() 这个系统调用来引出一系列函数。sbrk() 用来增加或减小用户进程的可用的 heap 大小。它的函数调用树是这样的:

int growproc(int n):pagetable_t类型指针会直接指向顶级页表地址;- 如果 $n>0$,调用
uvmalloc()分配内存让用户进程内存增长n/PGSIZE个 Page(PGSIZE=4096B); - 如果 $s<0$,调用
uvmdealloc()分配内存让用户进程内存缩小n/PGSIZE个 Page。
void * kalloc(void):分配一个 page 大小的物理内存- 所有的 free page 都被记录在
stuct kmem当中; struct run是个循环定义的结构体,将 RAM 内的 free page 以链表的形式记录。
- 所有的 free page 都被记录在
void kfree(void *pa):释放一个 page,并将它追加到kmem.freelist的表头中- 我们可以从
kfree的源码中窥探到一些东西:
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree");- 这说明 Kernel 不愿去释放 kernel text 和 data,至少它不能调用
kfree()去这么做。
- 我们可以从
pte_t * walk(pagetable_t pagetable, uint64 va, int alloc):- 在虚拟地址的翻译工作是交给硬件 MMU 去完成的,而 xv6 新增
walk函数去模拟这个过程,这是页表部分最核心的函数之一:
- 在虚拟地址的翻译工作是交给硬件 MMU 去完成的,而 xv6 新增
// 一些必要的宏定义
// 获取该物理地址对应的 PTE(Flags 字段全零)
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
// 获取该 PTE 指向的的页表物理地址
#define PTE2PA(pte) (((pte) >> 10) << 12)
// 截断低 10 位获得 PTE 的 PPN 字段
#define PTE_FLAGS(pte) ((pte) & 0x3FF)
#define PXMASK 0x1FF // 9 bits
#define PXSHIFT(level) (PGSHIFT+(9*(level)))
// 获取该虚拟地址在 level 级的索引号
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
// one beyond the highest possible virtual address.
// MAXVA is actually one bit less than the max allowed by
// Sv39, to avoid having to sign-extend virtual addresses
// that have the high bit set.
#define MAXVA (1L << (9 + 9 + 9 + 12 - 1))
// 返回虚拟地址 va 在 pagetable 下对应的 PTE 的地址
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
// 循环遍历前两级页表
for(int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
// 若当前 PTE 是可用的
if(*pte & PTE_V) {
// 更新成下一级页表的物理地址
pagetable = (pagetable_t)PTE2PA(*pte);
// 若不可用就根据 alloc 参数来决定是否新分配一个下一级页表
// 一个页表的大小为 512×(44+10)/8=27×2^7B
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
// 初始化新分配的页表
memset(pagetable, 0, PGSIZE);
// 更新当前页表的 PTE 字段内容
*pte = PA2PTE(pagetable) | PTE_V;
}
}
// 返回最后一级的页表中的 va 所对应的 PTE 的地址
return &pagetable[PX(0, va)];
}int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm):- 将从
pa开始的连续pa/PGSIZE个 page 映射到给定页表的虚拟地址中去(被映射的虚拟地址必须要是~PTE_V)。
- 将从
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
// 向下取整到一个 page 的大小
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for(;;){
// 创建当前虚拟地址在最后一级页表中对应的 PTE
if((pte = walk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("remap");
// 用当前物理 page 的地址设置当前虚拟地址对应的 PTE 的字段
*pte = PA2PTE(pa) | perm | PTE_V;
if(a == last)
break;
// 虚拟地址和物理地址都递增一个 PGSIZE
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}3、main()
在 main() 函数里,我们暂且先关注与页表有关的这几个调用:
...
kinit(); // physical page allocator
kvminit(); // create kernel page table
kvminithart(); // turn on paging
procinit(); // process table
...
注意这几个地址大小关系(至上而下依次增大,以 xv6 源码为准):
- KERNBASE:
0x0000000080000000 - etext:
0x0000000080008000 - end:
0x0000000080027020 - PHYSTOP:
0x0000000088000000
kinit():将RAM清空并将其中的所有 page 逐一追加进kmem.freelist中;- 这是调用
freerange(end, (void*)PHYSTOP);来实现这一点的,调用完后kmem.freelist链表中会有 32728 个 page,之后kalloc()都会Free memory这里面拿 page;
- 这是调用
kvminit():初始化 kernel 的页表,依照 kernel 的页表布局依次调用相应的kvmmap()函数即可;kvmmap()函数是对mappages()函数的一层简单的包装,因此只会在分配新的页表时才会消耗kmem.list中的 page;
其中有一行代码可以稍微留意一下:
// map kernel data and the physical RAM we'll make use of.
- `etext` 是 kernel `text` 的结尾地址,这个调用还意味着 `RAM` 中的所有 page 都被直接映射过去了。kvminithart():设置satp寄存器位为 kernel page,然后清空TLB缓存,此后所有代码中出现的地址都将会是 kernel 页表下的虚拟地址;procinit():为以后的NPROC个用户进程的 kernel stack 预先分配空间,并映射进 kernel 的虚拟内存布局中对应的位置。这是通过以下三行代码来完成的:char *pa = kalloc(); uint64 va = KSTACK((int) (p - proc));
4、trampoline
trampoline 包含 uservec 和 userret 函数(/kernel/trampoline.S),它们是处理中断时所要执行的函数。
xv6 中的中断有三类:
- 系统调用;
- 运行错误(如除零、使用不该用的虚拟地址);
- 设备可屏蔽中断(如读写返回)。
在机组中学过,中断响应、中断处理和中断响应是由硬件去完成的,而中断处理时的现场保护是由软件去完成的。现在,这个软件就是操作系统。中断发生时,硬件(RISC-V)和软件(xv6's kernel)需要共同维护这么几个控制寄存器:
stevec:kernel 在这里保存uservec(针对从 user space 来的中断)或kernelvec(针对从 kernel space 来的中断);sepc:RISC-V 在这里保存当前的程序计数器,方便中断返回;scause:RISC-V 在这里保存中断发生的原因;sscratch:kernel 会将trapframe page的地址保存在这里;sstatus:若 kernel 清空 SIE 位,则 RISC-V 关中断。SPP 位代表当前中断的来源是 user mode 还是 supervisor mode,方便返回至对应的 mode。
中断发生时,硬件要做以下几件事:
- 若是设备中断,并且当前
sstatus的 SIE 位被清空,RISC-V 会无视这个中断,否则继续执行下面几步; - 清空 SIE 位,表示关闭可屏蔽中断;
- 将当前
pc的值赋给sepc; - 保存当前 mode 信息至
sstatus的 SSP 位; - 设置
scause; - 设置当前 mode 位 supervisor mode;
- 将
stvec赋给pc; - 执行中断处理程序。
中断发生时,软件一般要做以下几件事:
- 设置 kernel page table 的地址至
satp寄存器; - 设置 kernel stack 的地址至
sp寄存器; - ……
之所以是一般,是因为每个操作系统内核在这块儿的设计上都会有各自的小心思,lab 3 就是拿这里展开做文章的。
对于来自 user space 的中断,一条清晰的函数调用链是 uservec -> usertrap -> usertrapret -> userret。我们需要在 uservec 中从用户页表切换至内核页表。为了在切换前后,使函数代码能够继续执行,需要满足以下两个必要条件:
逻辑地址不要变;
pc寄存器通过不断地自增,来执行后续的指令,因此代码虚拟地址不能变。
物理地址也不要变。
- 当然,通过 PTE 映射到的物理地址变掉了,那显然是个错误。
所以 trampoline 大家(包括 kernel)都同样设在虚拟地址空间的最上面,在初始化每个进程的页表时再通过 mappages() 函数来保证 PTE 的一致性。

5、uservec()
uservec 的任务就是将 satp 寄存器设置为 kernel pagetable,并且保存寄存器中的值到 trapframe 中。在初始化 user 的页表时候,trapframe 就被映射在了用户虚拟地址空间中,并且就在 trampoline 的正下方,因此我们可以在 satp = user pagetable 时,就轻松地将寄存器的值保存到 trapframe 中。但后面切换为了 kernel pagetable 后,kernel 怎么去访问 user's trapframe 呢?这个其实在初始化进程的页表完后,直接 p->trapframe 就可以访问到了:
// Create a user page table for a given process,
// with no user memory, but with trampoline pages.
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// An empty page table.
pagetable = uvmcreate();
if(pagetable == 0)
return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
return pagetable;
}在将寄存器值复制到 trapframe 之前,需要注意一处细节。RISC-V 有 32 个整数寄存器,它们是 x0~x31;其中 x1~x31 都是通用寄存器,在汇编代码中使用它们时需要使用它们的 ABI 别名。想要把这 31 个通用寄存器的值复制到 trapframe,就需要有寄存器腾出位置来(有点类似于数字华容道),RISC-V 就是通过 sscratch 寄存器配合 csrrw 指令来做到这一点的:
uservec:
#
# sscratch points to where the process's p->trapframe is
# mapped into user space, at TRAPFRAME.
#
# swap a0 and sscratch
# so that a0 is TRAPFRAME
csrrw a0, sscratch, a0
# save the user registers in TRAPFRAME
sd ra, 40(a0)
...
sd t6, 280(a0)
# save the user a0 in p->trapframe->a0
csrr t0, sscratch
sd t0, 112(a0)
...接下来就是将 trapframe 中的一些重要字段放心地赋值给寄存器啦。执行完后页表就是 kernel pagetable:
struct trapframe {
/* 0 */ uint64 kernel_satp; // kernel page table
/* 8 */ uint64 kernel_sp; // top of process's kernel stack
/* 16 */ uint64 kernel_trap; // usertrap()
/* 24 */ uint64 epc; // saved user program counter
/* 32 */ uint64 kernel_hartid; // saved kernel tp
...
};uservec:
# restore kernel stack pointer from p->trapframe->kernel_sp
ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid
ld tp, 32(a0)
# load the address of usertrap(), p->trapframe->kernel_trap
ld t0, 16(a0)
# restore kernel page table from p->trapframe->kernel_satp
ld t1, 0(a0)
csrw satp, t1
sfence.vma zero, zero
# a0 is no longer valid, since the kernel page
# table does not specially map p->tf.
...应该会有人问那么原来在 trapframe 这些字段的值是什么时候被初始化的呢?答案是在分配并初始化用户进程的最后调用 usertrapret 函数来实现的,调用完后即可返回用户空间。调用链是 fork()->allocproc()->forkret()->usertrapret(),逻辑比较清晰简单,所以自己翻 usertrapret 的实现看看吧。从这也可以看到,系统中的所有用户进程,除了 init 进程以外,其他进程都是通过调用 fork 函数生成的。
6、usertrap()
/* /kernel/trap.c */
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
if(p->killed)
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}usertrap 函数是中断处理的核心函数,但理解不难,所以简要提几个细节:
- 再一次地保存
pc至用户进程的trapframe。这是因为考虑到嵌套会覆盖掉sepc寄存器内容,最后在调用usertrapret的时候再赋给它就好了; - 如果是系统调用,那么就去执行它,在那之前
pc要记得加 4,因为我们肯定不希望中断返回后再一次地执行 ECALL 指令,而 ECALL 指令的长度就为 4 字节; - 如果是个异常,直接 kill 整个错误进程,即
exit(-1); - 结合
Scheduler函数的实现,现在 xv6 调度算法应该是时间片轮转(Round Robin)调度算法,通过设备 timer 来产生中断进行 CPU 的让出。
二、Lab 3
有了这些前置知识,再来看下 xv6 book 第四章结尾的原文:
The need for special trampoline pages could be eliminated if kernel memory were mapped into every process’s user page table (with appropriate PTE permission flags). That would also eliminate the need for a page table switch when trapping from user space into the kernel. That in turn would allow system call implementations in the kernel to take advantage of the current process’s user memory being mapped, allowing kernel code to directly dereference user pointers. Many operating systems have used these ideas to increase efficiency. Xv6 avoids them in order to reduce the chances of security bugs in the kernel due to inadvertent use of user pointers, and to reduce some complexity that would be required to ensure that user and kernel virtual addresses don’t overlap.
以上就是 Lab3 要做的。
我们需要让每个用户进程都拥有一份独立的内核页表的拷贝。这张页表可以看作是用户页表和内核页表和结合。这样做的好处在实验指导的最后也提及一些:
Linux uses a technique similar to what you have implemented. Until a few years ago many kernels used the same per-process page table in both user and kernel space, with mappings for both user and kernel addresses, to avoid having to switch page tables when switching between user and kernel space. However, that setup allowed side-channel attacks such as Meltdown and Spectre.
第一次做实验的时候不要想太多,先把三个 Exercise 分别是干什么的都好好想清楚,防止出现跟空气斗智斗勇的情况出现,基本上跟着实验指导上的提示跟着做就可以了。我不展示自己的 code,一是因为自己的 coding 太臭了,网上的实现要多少有多少;二是因为我自己在 Exercise 3 的实现总会报 kerneltrap 的异常中断,排查了几圈最后放弃了,只拿了前两个练习的分。
总结
脚踏实地,不要多想。
其它
page-fault 异常的妙用
相信肯定有人会觉得在调用 fork() 中马上调用 exec() 是一种资源的浪费,因为子进程复制父进程的内存的内容就没意义了,这是 xv6 设计上的短板。所以在真实 OS 上,有人设计出来了 COW(copy-on-write) fork 函数。这个函数的机制是这样的:
- 首先创建子进程时,先不要复制全部的内存,而是将父进程的最后一级页表所有 PTE 设置为 read-only,然后将子进程复制父进程的页表。
- 子父进程在读的时候还好,但一旦有一方打算写,就会引发一个 page-fault 异常,由内核来处理这个异常中断。
- 如果是 xv6,内核会毫不留情地直接 kill 这个进程。但在这里,内核会拷贝引发异常的 PTE 所指向的 page,并将其映射到子进程的页表中,并将两者的 PTE 设置为 writable。
了解过线段树的人应该很快能体会这个机制所带来的好处,不就是懒修改嘛。类似地,但凡是跟 paging 相关的功能,配合 page-fault 都能有效提高它的资源利用率,像是 lazy allocation, paging from disk, automatically extending stacks 和 memory-mapped files。
进程切换
在只考虑单核心的 CPU 的运行模型下,在 scheduler() 调用 swtch() 开始,到定时器产生中断,yield() 出 CPU 时调用 swtch() 结束这期间,CPU context 与内存交互的情况大致如下:
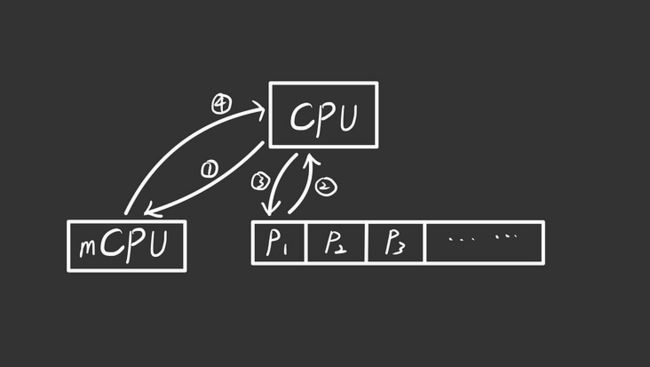
在 main() 函数中 userinit() 初始化 init 进程后,接着会被 scheduler 调度运行。来看一下调度时发生的一些细节。scheduler 找到 init 进程后,会执行 swtch(&c->context, &p->context)。这个 swtch() 调用就是执行上图的 ①② 步。
/* kernel/swtch.S */
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
...
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
...
ld s11, 104(a1)
retswtch() 主要交换 callee saved 寄存器,发现并没有设置最关键的程序计数器和用户页表,那该怎么执行用户进程的指令呢?答案是通断中断返回来设置程序计数器。ld ra, 0(a1) 指令的意思是将 p->context.ra 的值赋给 ra 寄存器(return address 寄存器)。我们 allocproc() 函数中找到了这个字段的初始值:
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;所以当 swtch 执行 ret 指令后,程序计数器就设置为 forkret 函数的位置,开始执行中断返回指令。
参考链接
- xv6: a simple, Unix-like teaching operating system, by Russ Cox, Frans Kaashoek, Rober Morris
- [ARM Linux] 每个进程的内核页表为什么单独分配存储空间?
- GDB调试命令详解
- Fall2020/6.S081-如何在 QEMU 中使用 gdb
- gdb调试的layout使用