前文
- 一、CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式
- 二、JAVA API实现HDFS
- 三、MapReduce编程实例
Zookeeper安装
@
- 前文
- Zookeeper安装
- 前言
- 下载[Apache ZooKeeper]
- 解压安装包
- 进入conf目录
- 修改zoo_sample.cfg并重命名zoo.cfg
- 配置环境变量
- 环境变量生效
- 启动zookeeper服务
前言
ZooKeeper是用Java编写的,运行在Java环境上,因此,在部署zk的机器上需要安装Java运行环境。为了正常运行zk,我们需要JRE1.6或者以上的版本。
对于集群模式下的ZooKeeper部署,3个ZooKeeper服务进程是建议的最小进程数量,而且不同的服务进程建议部署在不同的物理机器上面,以减少机器宕机带来的风险,以实现ZooKeeper集群的高可用。
ZooKeeper对于机器的硬件配置没有太大的要求。例如,在Yahoo!内部,ZooKeeper部署的机器其配置通常如下:双核处理器,2GB内存,80GB硬盘。
由于已有Hadoop集群,所以可省略一些步骤,比如hosts文件内容防火墙等
CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式)
下载[Apache ZooKeeper]
自己用的3.7
或者使用镜像下载
#wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/{选择版本}
wget https://mirror.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz --no-check-certificate
--no-check-certificate :使用“–no-check-certificate”选项, 以不安全的方式连接
解压安装包
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /export/servers/
#tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C 自定义目录
进入conf目录
cd /export/servers/apache-zookeeper-3.7.0-bin/conf
修改zoo_sample.cfg并重命名zoo.cfg
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加修改一下设置
#设置初始通信时限
initLimit=10
#设置同步通信时限
syncLimit=5
#设置数据目录+数据此计划路径/
dataDir=/export/servers/data/zookeeper/zkdata
#设置数据日志
dataLogDir=/export/servers/data/zookeeper/logs
#设置客户端连接的端口号
clientPort=2181
# 配置zookeeper集群的服务器编号以及对应的主机名、通信端口号(心跳端口号)和选举端口号
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
在设置的dataDir目录下,创建zkdata文件夹
mkdir -p /export/data/zookeeper/zkdata
并在zkdata文件夹下创建myid文件。
myid指明自己的id,对应上面zoo.cfg中server.后的数字,第一台hadoop1的内容为1,第二台hadoop2的内容为2,以此类推,内容如下
hadoop1$ cat /export/data/zookeeper/zkdata/myid
1
hadoop2$ cat /export/data/zookeeper/zkdata/myid
2
配置环境变量
vi /etc/profile
添加zookeeper环境变量
export ZK_HOME=/export/servers/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK_HOME/bin
首先将zookeeper安装目录分发至hadoop2和hadoop3服务器上
scp -r /export/servers/{zookeeper解压目录}/ hadoop2:/export/servers/
scp -r /export/servers/{zookeeper解压目录}/ hadoop3:/export/servers/
其次将myid的文件分发至hadoop2和hadoop3
scp -r /export/data/zookeeper/ hadoop2:/export/servers/
scp -r /export/data/zookeeper/ hadoop3:/export/servers/
最后将profile文件也分发至hadoop2和hadoop3服务器上
scp /etc/profile hadoop2:/etc/profile
scp /etc/profile hadoop3:/etc/profile
环境变量生效
分别刷新
source /etc/profile
启动zookeeper服务
由于我们是集群方式配置
所以三台必须全部启动才能看得到Leader角色和Follower角色
如果集群只启动一台直接查看会得到如下图

分别在Hadoop1,hadoop2,hadoop3执行
zkServer.sh start
此时我们再次查看
zkServer.sh status
#启动命令会在hadoop看到leader,其余两个看到follower
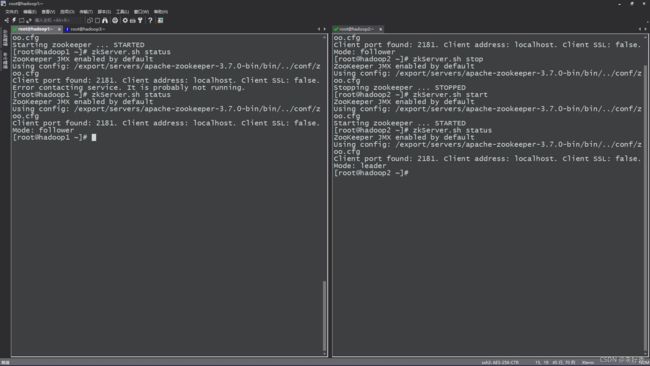
三个都启动

如果启动失败,运行下方命令,查看原因
zkServer.sh start-foreground