pandas查漏补缺
contents,多图预警!!
- pandas 数据的创建
-
- 设置
- 创建series
- 创建dataframe
- Panel
- Dataframe添加列
- pandas索引
-
- 多层次索引
-
- series的多层索引
- dataframe的多层索引
- dataframe多层索引的交换和排序
- 按照索引级别进行统计
- 索引与列的转换
- pandas查询函数
- 丢弃部分数据
- 函数应用
- pandas排序
-
- 对标签
- 对值排序和排名
- pandas数据访问的高效方式
- pandas修改元素
- pandas过滤元素
- pandas处理带缺失值的表格
-
- 直接删除或填补
- 判断是否带有空数据
- dataframe和等行的序列相减
- series的统计
- 列表合并
- 分类统计
-
- 对 Series 进行分组
- 对分组进行迭代
- 对 dataframe 进行分组
-
- 按列分组
- 通过字典进行分组
- 通过函数来分组
- 多级索引数据根据索引级别来分组
- 交叉表
- 数据聚合
- stack 行列索引转换
- 数据透视表
- pandas处理时间序列
-
- 时间差
- 数字(时间戳)和时间的转换
- 字符串和 datetime 转换
- Pandas 创建时间序列
- 时期及算术运算
- 创建时期序列
- 时期的频率转换 asfreq
-
- 季度时间频率
- Timestamp 和 Period 相互转换
- 重采样
-
- 降采样
- 升采样和插值
- 其他的重采样
- 时期重采样
-
- 时期降采样
- 时期升采样
- pandas自动解析时间日期
- pandas自定义解析时间日期
- 时间运算
- category数据
- one-hot编码
- 画图
-
- series画图
- dataframe画图
-
- 线形图
-
- 多列的dataframe直接df.plot()
- 增加参数subplots=True画子图
- 指定x,y轴
- 柱状图
-
- df.plot.bar()
- 是否堆叠
- 画水平的柱状图
- 直方图
-
- df.plot.hist(bins=20)
- 是否堆叠
- 密度图
-
- df.plot.kde()
- 散布图
-
- df.plot.scatter()
- 饼图
-
- df.plot.pie()
- 数据io
-
- 读取文件
-
- pd.read_csv('data.csv', index_col=0,header=None, names=['a','b','c'],na_values=['NA', 'NULL'],nrows=10)
- pd.read_table('data.csv', sep='::', engine='python')
- 逐块读取数据
- 保存文本数据
- 其他格式文件的操作
- pandas使用 numpy 函数
pandas 数据的创建
设置
| 作用 | 代码 |
|---|---|
| 显示所有列 | pd.set_option(‘display.max_columns’, None) |
| 显示所有行 | pd.set_option(‘display.max_rows’, None) |
| 设置每行显示的长度 | pd.set_option(‘display.width’, 200) |
创建series
s = pd.Series(data, index=index)
其中 index 是一个列表,用来作为数据的标签。data 可以是不同的数据类型:Python 字典,ndarray 对象,一个标量值
note:
- Series 是类 ndarray 对象,就可以切片,用索引等当做np中的数组来操作操作
- Series 是字典对象,就可以当做字典来用s.get(‘f’)
- 进行标签对齐操作

创建dataframe
(2维的,就有行标签和列标签,支持自动索引对齐)
f = pd.DataFrame(data, index=index, columns=columns)
其中 index 是行标签,columns 是列标签,data 可以是下面的数据:
- 由一维 numpy 数组,list,Series 构成的字典(list长度一定要相同,series长度可以不同,缺失会nan补上)
- 二维 numpy 数组
- 一个 Series
- 另外的 DataFrame 对象
note:
dateframe会从data中自动搜索索引,若先前是有索引的,则在创建时会在指定的索引中寻找对应数据(索引对齐操作),不存在会用Nan填补
具体放法1:
dates=pd.date_range('20210101',periods=6)
datas=pd.DataFrame(np.random.random((6,4)),index=dates,columns=list('ABCD'))
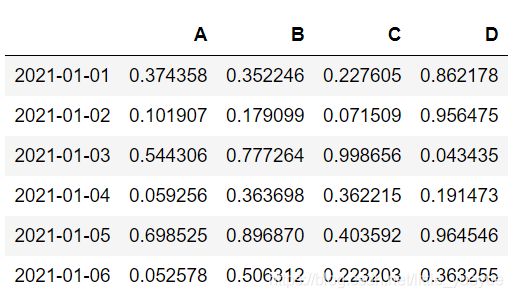
法2:
d={
'A':0,'B':range(4),'C':pd.Timestamp('20210101')}
datas=pd.DataFrame(d)

Panel
Panel 是三维带标签的数组。实际上,Pandas 的名称由来就是由 Panel 演进的,即 pan(el)-da(ta)-s。Panel 比较少用,但依然是最重要的基础数据结构之一。
items: 坐标轴 0,索引对应的元素是一个 DataFrame
major_axis: 坐标轴 1, DataFrame 里的行标签
minor_axis: 坐标轴 2, DataFrame 里的列标签
Dataframe添加列
-
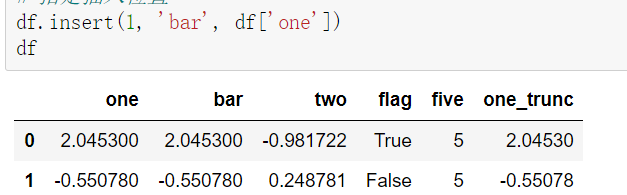
df.insert(1, ‘bar’, df[‘one’])
第一个为添加的位置,第二个是标签名,第三个是数据
-
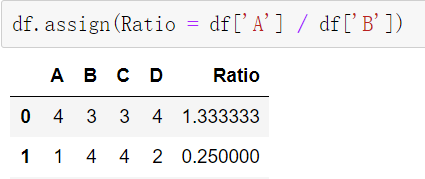
df.assign(Ratio = df[‘A’] / df[‘B’]) #实际的df没有变,是通过复制返回了一个新的dataframe
列名=data的操作,可以是函数,例如df.assign(AB_Ratio = lambda x: x.A / x.B)
pandas索引
- 重新索引
s.reindex(list(‘abcdefgh’)) #新增加的索引没有值为Nan,
也可用s.reindex(list(‘abcdefgh’), fill_value=0) #fill_value赋予默认值,也可用参数method=‘ffill’,‘bfill’,ffill是用前面的数填充,bfill使用后面的数填充。dataframe中method只对行有效。

3. 给索引命名
对series:s.index.name = ‘alpha’
对dataframe:df.index.name=‘row’,df.columns.name=‘col’

-
查询索引的类
pd.*Index? -
查询是否有重复的索引: s.index.is_unique
返回有索引唯一值的索引列表: s.index.unique()
可用grouby来根据具体需要处理重复索引,例如s.groupby(s.index).sum() #还有.mean()等等
多层次索引
可以使数据在一个轴上有多个索引级别。即可以用二维的数据表达更高维度的数据,使数据组织方式更清晰。它使用 pd.MultiIndex 类来表示。
series的多层索引

dataframe的多层索引

dataframe多层索引的交换和排序
df2 = df.swaplevel(‘row-1’, ‘row-2’)

df.sortlevel(0) #括号中的数字表示对几级索引进行排序

按照索引级别进行统计
df.sum(level=0) #.sum表示使用的函数,level表示按照几级索引的值进行操作

索引与列的转换
df.set_index(‘c’) #将索引为c的这列设置层索引

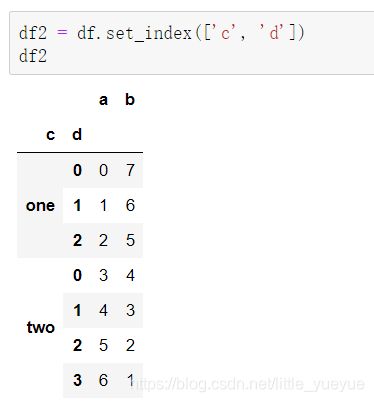
df2.reset_index() #则将df的索引变为列名,索引变为默认的0,1,2…
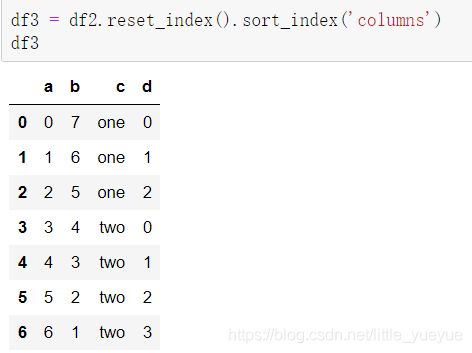
pandas查询函数
df.query()
| 参数 | 说明 |
|---|---|
| expr | 要评估的查询字符串; 可以在环境中引用变量,在变量前面加上@字符(@a+b); 也可以通过在反引号中将空格或运算符括起来来引用它们 |
| inplace=False | 查询是应该修改数据还是返回修改后的副本 |
丢弃部分数据
df2 = df.drop([‘two’, ‘four’], axis=1) #返回一个丢弃[‘two’, ‘four’]两列的dataframe,axis默认是0.
函数应用
-
apply: 这里有大佬的讲解连接:map、apply、applymap详解
(1). 将数据按行或列进行计算,默认axis=0是按列,设置axis=1可按行
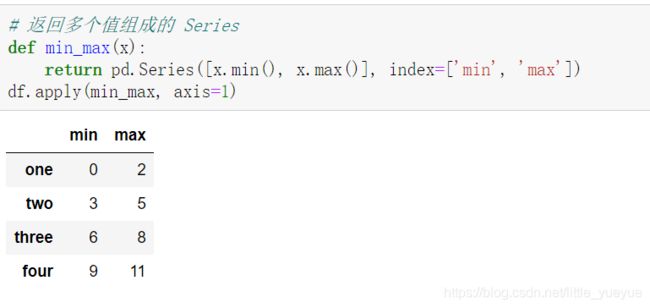
(2). GroupBy 的 apply 函数对每个分组进行计算,
groupby(‘分组关键字’).apply(函数名,函数的参数1,函数的参数2,…)
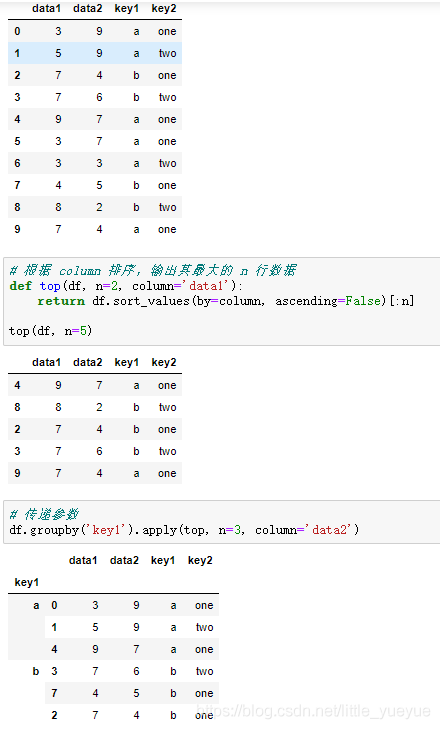
下方示例为应用groupby,来用各分组的平均值去填充Nan

-
applymap: 将数据按元素为进行计算

pandas排序
对标签
datas.sort_index(axis=1,ascending=False) #axis=1也课用‘columns’替换
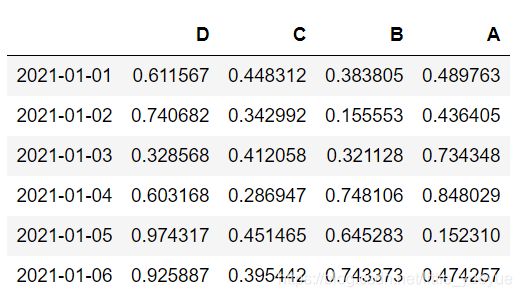
axis=1对列标签,0对行标签,False降序,默认为True升序
对值排序和排名
datas.sort_values(by=‘A’,ascending=False)
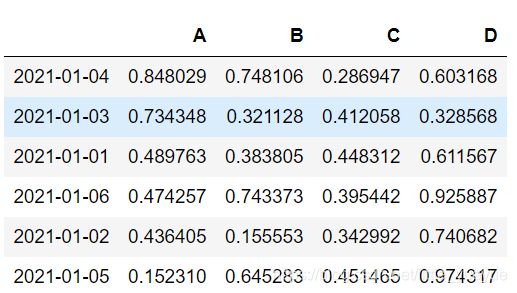
对series进行排名,method='first’表示先出现的先排名,dataframe中类似,df.rank()
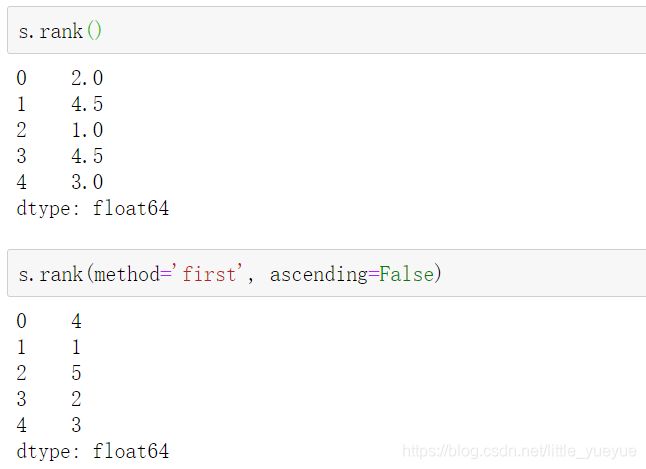
pandas数据访问的高效方式
datas.loc[:,[‘B’,‘D’]]
datas.at[pd.Timestamp(‘20210101’),‘B’] #这里一定要写原先的数据结构
datas.iloc[:,[1,3]]
datas.iat[1,1]#直接写位置来访问
pandas修改元素
用标量可以把整个列(行)改成同一个值
datas.B=2

不是标量的话,长度一定要匹配
pandas过滤元素
datas[datas.A>0.5]#若两个条件要分别括号括起来用&连接
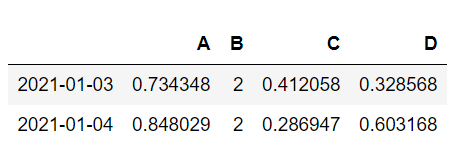
datas[datas.tag.isin([‘a’,‘c’])]
pandas处理带缺失值的表格

直接删除或填补
df.dropna()
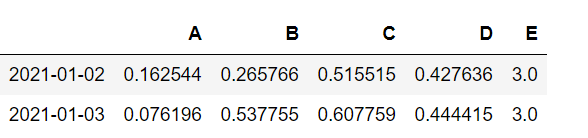
df.fillna(value=4)
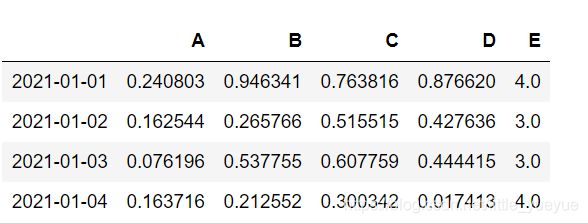
判断是否带有空数据
pd.isnull(df)#以表格形式展现

pd.isnull(df).any()#以列形式展现

pd.isnull(df).any().any()
![]()
选出某属性缺失值对应的行
data.loc[(data.关注的属性.isnull()), '关注的属性']
note: 空数据是不参与运算的
按条件修改元素df.loc[‘属性’==条件,属性]=a
dataframe和等行的序列相减
自动将序列扩充成和dataframe相同的列的表再相减
series的统计
s=pd.Series(np.random.randint(1,10,size=10))
s.mode() #返回众数
s.value_counts() #返回计数
s.isin([1]) #判断值series是否在给定列表中
列表合并
- pd.concat([ df.iloc[:2], df.iloc[3:4] ])#这里要是写df.iloc[3]就不对,单个列的时候要括号写成df.iloc[[3]]
- pd.merge(df1,df2)
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。https://blog.csdn.net/missyougoon/article/details/83819473
on通过哪些关键字合并,同时传入两个Key,此时会进行以[‘key1’,‘key2’]列表的形式进行对应 https://blog.csdn.net/brucewong0516/article/details/82707492 - s=pd.Series(np.random.randint(1,10,size=5),index=list(‘ABCDE’))
df1.append(s,ignore_index=True)
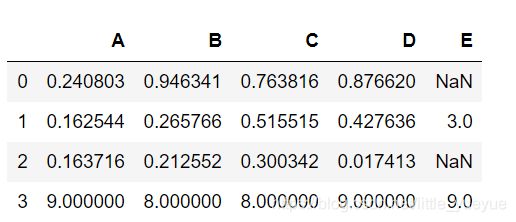
ps:
(df1==df.iloc[[0,1,3],:]).all()#按列看元素是否相同

(df1==df.iloc[[0,1,3],:]).all().all()
![]()
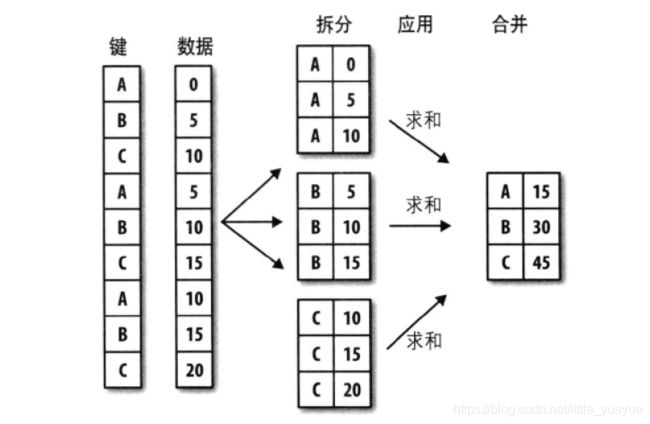
分类统计
分组计算三步曲:拆分 -> 应用 -> 合并
| 三步 | 意义 |
|---|---|
| 拆分 | 根据什么进行分组? |
| 应用 | 每个分组进行什么样的计算? |
| 合并 | 把每个分组的计算结果合并起来。 |
对 Series 进行分组
s.groupby([数组]) #返回的是按照数组里元素进行分组的groupby对象(,进一步用.sum()等操作,才返回series
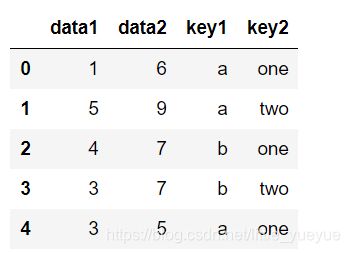

将上图进行 .unstack() 可转换成dataframe

对分组进行迭代
.groupby([数组]) #返回的是按照数组里元素进行分组的groupby对象,可进行迭代 ,从而可转换成很多类型


对 dataframe 进行分组
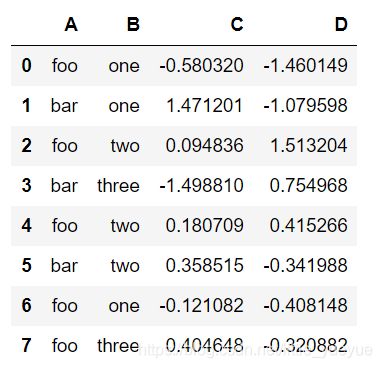
df.groupby([‘A’, ‘B’]).sum() #可以根据A,B顺序不同进行不同分组 .sum() 可换成有需要的函数,如.size(),.mean()

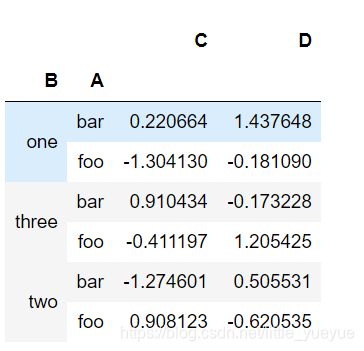
按列分组

通过字典进行分组
Nan缺失值当做 0来处理

通过函数来分组
当函数作为分组依据时,数据表里的每个索引(可以是行索引,也可以是列索引)都会调用一次函数,函数的返回值作为分组的索引,即相同的返回值分在同一组。
例如,按搜索引的长度进行分组
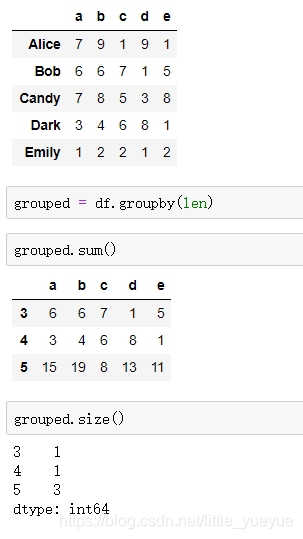
多级索引数据根据索引级别来分组
df.groupby(level=‘country’, axis=1).count() # leve参数选择哪个索引进行分组,对列进行分组时,一定要写axis=1,否则会报错,因为默认是对行,此时行索引名不为country

交叉表
pd.crosstab(df[‘属性1’],df['属性2’])即可做出对属性一为行索引,属性2为列索引,值为属性2出现的次数的表
数据聚合
- 分组运算,先根据一定规则拆分后的数据,然后对数据进行聚合运算,如 mean(), sum() 等。
- 聚合时,拆分后的第一个索引指定的数据都会依次传给聚合函数进行运算。最后再把运算结果合并起来,生成最终结果。
- 聚合函数除了内置的 sum(), min(), max(), mean() 等等之外,还可以自定义聚合函数。自定义聚合函数时,使用 agg() 或 aggregate() 函数。

- 应用多个聚合函数,使用 agg([函数名1,函数名2,…]) #若要给聚合后的列取名,则将函数改为(‘列名’,‘函数名’)
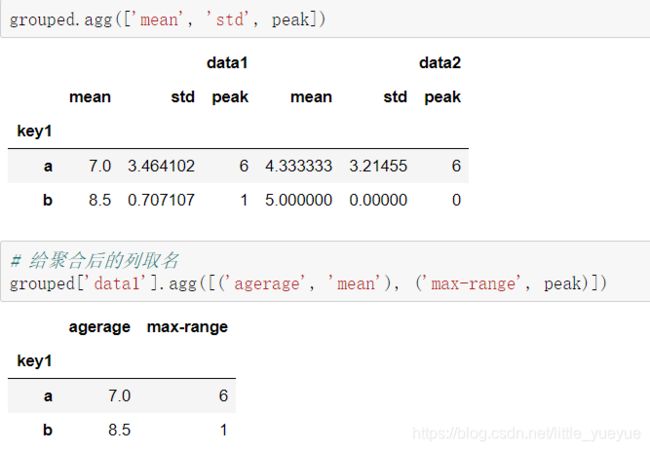
- 给不同的列应用不同的聚合函数
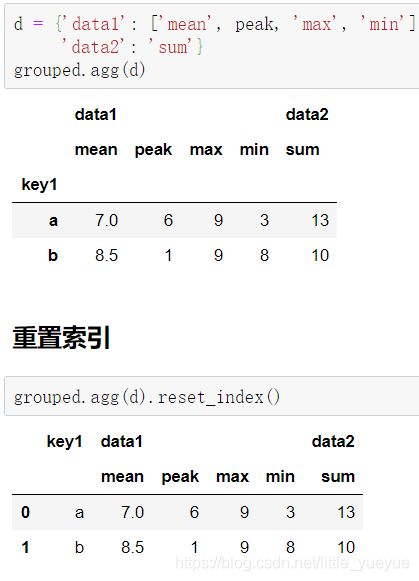
使用 dict 作为参数来实现,
若想分组的标准不作为索引而是列,1. 则使用.reset_index();2. 在groupby分组时就使用参数as_index=False,例如df.groupby(‘key1’, as_index=False).agg(d)
- 将两表进行连接
(1)用merge
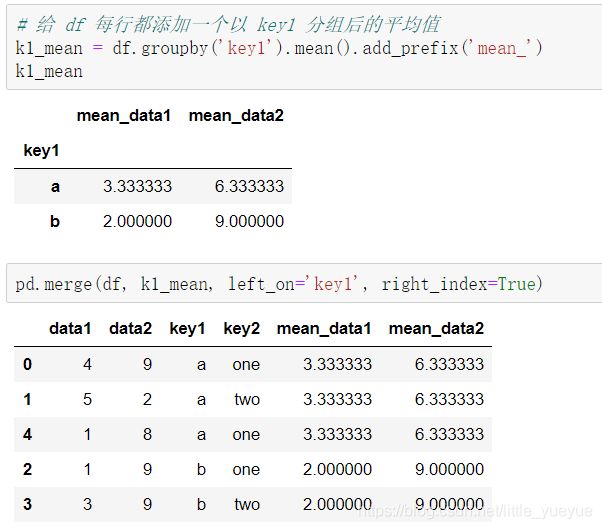
(2)用transform生成数据,在连接
例如:k1_mean = df.groupby(‘key1’).transform(np.mean).add_prefix(‘mean_’) #transform后面的括号放函数,add_prefix(‘列名前缀’)

stack 行列索引转换
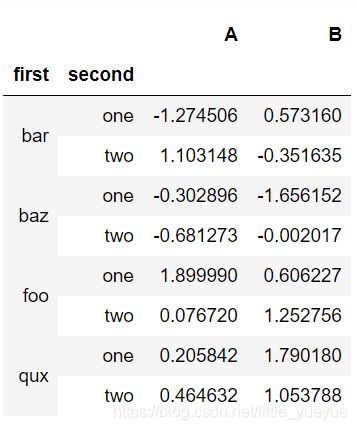
全转换成行索引
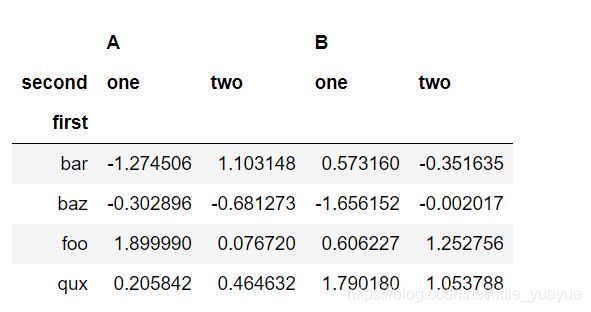
stacked=df.stack()
stacked
#返回成原来的样子则stcaked.unstack()

unstacked=df.unstack()#转化一层索引到列索引
unstacked
#unstacked=df.unstack().unstack()是将所有索引转化到列索引
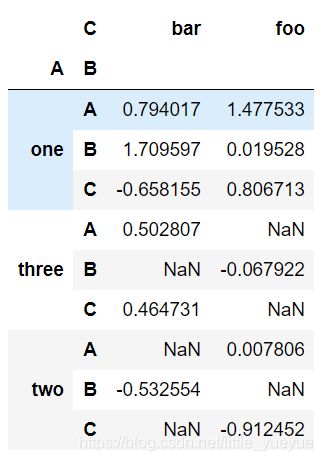
数据透视表
pivot table/轴向旋转表

pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
#or
df.pivot_table(values='D', index=['A', 'B'], columns=['C'])
数据为D,index是将其作为行索引,columns是作为列索引
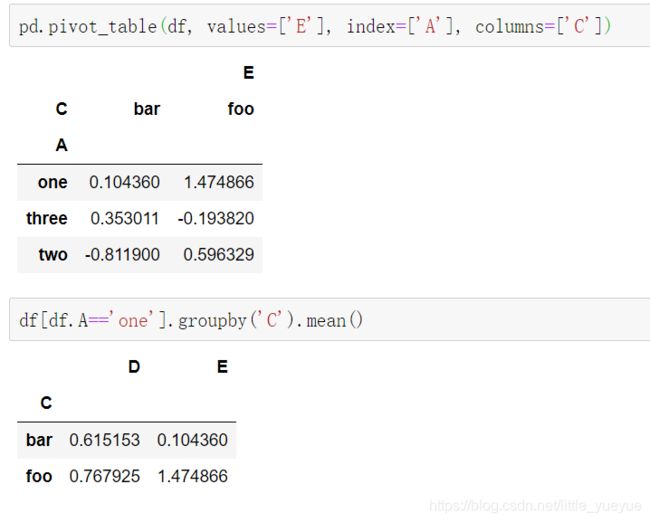
转换后的透视表缺失值显示NaN,多个值的时候显示平均值,也可以通过aggfunc='mean’来设置
pandas处理时间序列
时间日期
- 时间戳 tiimestamp:固定的时刻 -> pd.Timestamp
- 固定时期 period:比如 2016年3月份,再如2015年销售额 -> pd.Period
- 时间间隔 interval:由起始时间和结束时间来表示,固定时期是时间间隔的一个特殊
from datetime import datetime
from datetime import timedelta
now = datetime.now()
now
#datetime.datetime(2021, 2, 7, 10, 20, 37, 473245)
now.year, now.month, now.day, now.hour
#(2021, 2, 7, 10)
时间差
timedelta的参数可为days, seconds, microseconds, milliseconds, minutes, hours, weeks
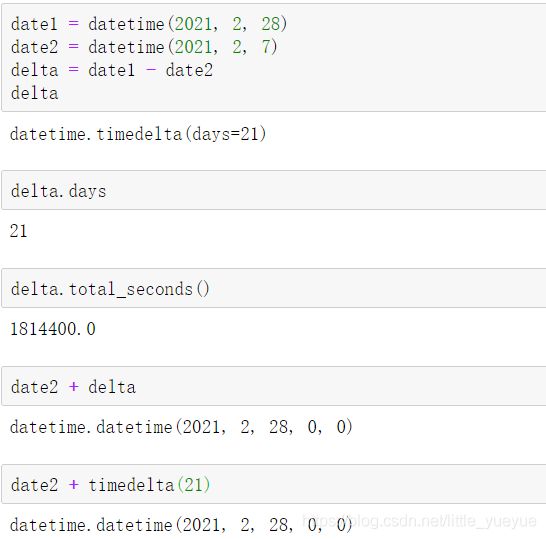
数字(时间戳)和时间的转换
- 数字(时间戳)转换为时间格式 pd.to_datetime
time_value=pd.to_datetime(数字型时间戳 , unit=‘s’) - pd.DatetimeIndex把日期转化为字典格式,通过键即可获得相应的年月日时分秒等
time_value=pd.DatetimeIndex(time_value)
time_value.day # 获取日序列
字符串和 datetime 转换
- 时间转为字符串
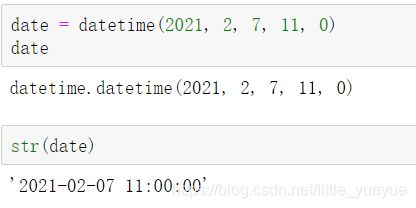
也可用date.strftime(’%Y-%m-%d %H:%M:%S’) 导出我们想要格式化样式的字符串,小写y输出是两位数的年份

- 字符串到时间
datetime.strptime(‘2016-03-20 09:30’, ‘%Y-%m-%d %H:%M’)

# 实例1:日期时间的字符串
pd.Timestamp('2019-01-01T12') # Timestamp('2019-01-01 12:00:00')
pd.Timestamp('2019-01-16 20:22:2')# Timestamp('2019-01-16 20:22:02')
# 实例2:以秒为单位转换表示Unix纪元的浮点数
pd.Timestamp(1513393355.5, unit='s')# Timestamp('2019-12-16 03:02:35.500000')
pd.Timestamp(1513393355, unit='s', tz='US/Pacific')#特定时区
# Timestamp('2019-12-15 19:02:35-0800', tz='US/Pacific')
#实例3:模仿datetime.datetime:通过位置或关键字,不能两者混合
pd.Timestamp(2019, 1, 16, 20,26,30) #Timestamp('2019-01-16 20:26:30')
pd.Timestamp(year=2019, month=1, day=16, hour=20,
minute=28, second=30, microsecond=30)#Timestamp('2019-01-16 20:28:30.000030')
Pandas 创建时间序列
- 用列表
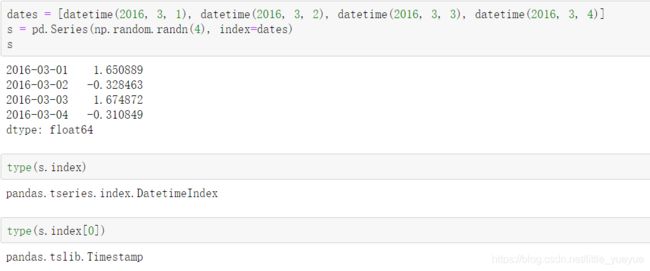
pandas内部会把时间储存成Timestamp来保存
- rng = pd.date_range(‘20160301’, periods=600, freq=‘s’)
periods 表示采样多少个,freq表示采样的单位,s是秒,D是天,W是星期,BM是每个月的最后一个工作日,4H这类以多少小时,Q是季度(rng.to_timestamp()可将季度等转化为具体日期),还可以通过normalize=True将时间正则化 - pd.date_range(‘20160320’, ‘20160331’, freq=‘D’) #通过两个日期生成一串时间,freq默认为’D’
- 制作时间序列样本
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
时期及算术运算
pd.Period 表示时期(一段连续的时间),比如几日,月或几个月等。比如用来统计每个月的销售额,就可以用时期作为单位。

创建时期序列
- 用pd.period_range()
- 字符串+pd.PeriodIndex([字符串])

时期的频率转换 asfreq
A-DEC: 以 12 月份作为结束的年时期
A-NOV: 以 11 月份作为结束的年时期
Q-DEC: 以 12 月份作为结束的季度时期

季度时间频率
Pandas 支持 12 种季度型频率,从 Q-JAN 到 Q-DEC
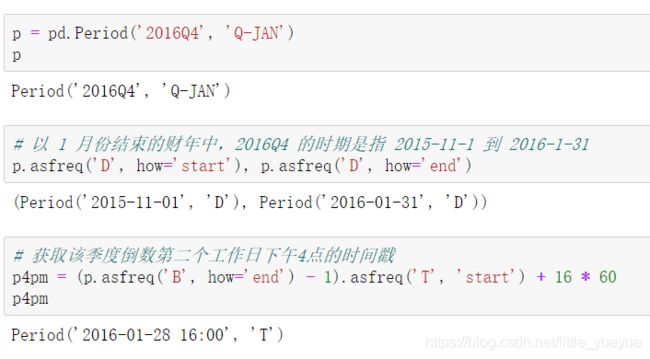
Timestamp 和 Period 相互转换
step1: 生成一个时间戳的时间序列
\qquad ts = pd.Series(np.random.randn(5), index = pd.date_range(‘2016-12-29’, periods=5, freq=‘D’))
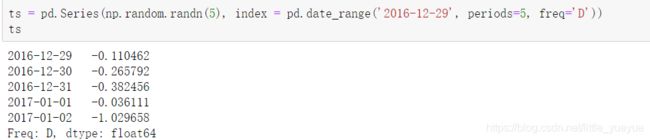
step2: ts .to_period() 默认以创建时间戳时的freq为频率转为相应的时期

step3: 时期转换为时间戳,细部时间会丢失
\qquad pts.to_timestamp(how=‘end’) #how参数设置缺失时间的填补

重采样
高频率 -> 低频率 -> 降采样:5 分钟股票交易数据转换为日交易数据
低频率 -> 高频率 -> 升采样
其他重采样:每周三 (W-WED) 转换为每周五 (W-FRI)
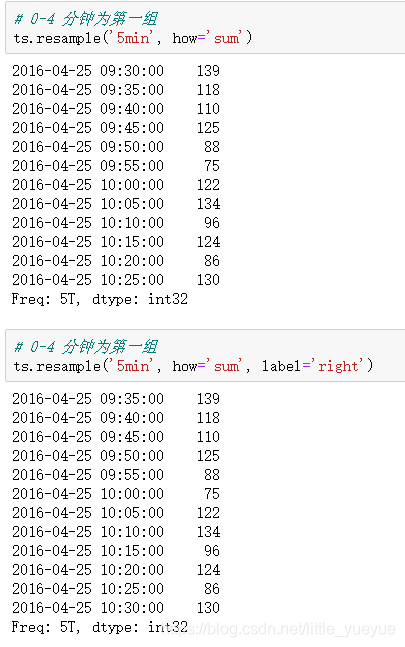
降采样
-
ts . resample (rule=‘2Min’, how=‘sum’, label=‘right’)
rule为新采样周期。
how采样样本值函数结果,sum表示采样周期中的值求和,ohlc表示open,high,low,close,其他常用的值由:‘first’、‘last’、‘median’、‘max’、‘min’。
label表示哪一侧时间为行索引left是开始时间,right表示结束时间 。
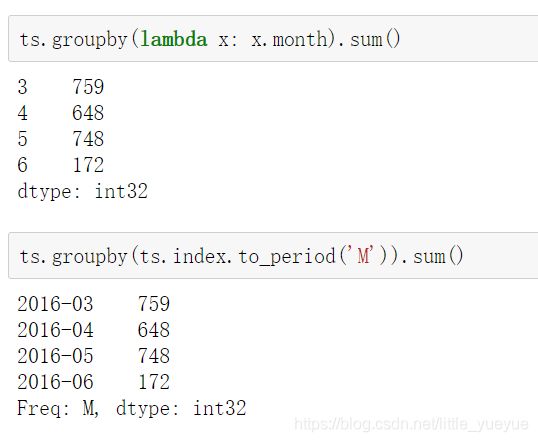
-
按月份重采样的两个示例
升采样和插值
-
以周为单位,每周五采样
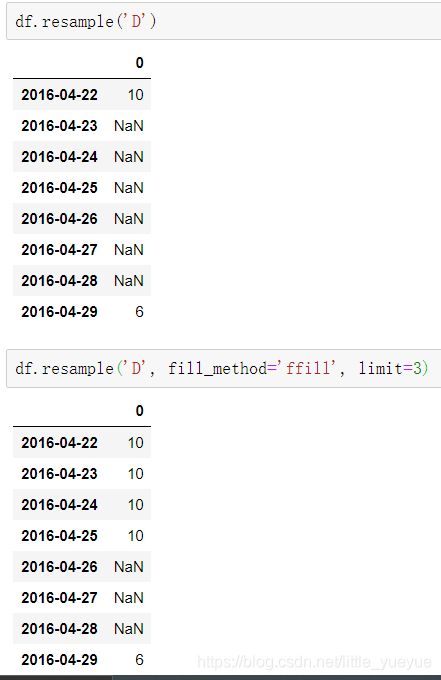
df = pd.DataFrame(np.random.randint(1, 50, 2), index=pd.date_range(‘2016-04-22’, periods=2, freq=‘W-FRI’))

-
df.resample(‘D’),以天采样,缺失值自动用Nan填补
df.resample(‘D’, fill_method=‘ffill’, limit=3) #fill_method缺失值填补的方式,lim表示每次插值最多的量。
其他的重采样
这里从‘W-FRI’到’W-MON’,一定要写fill_method,不然会显示NaN

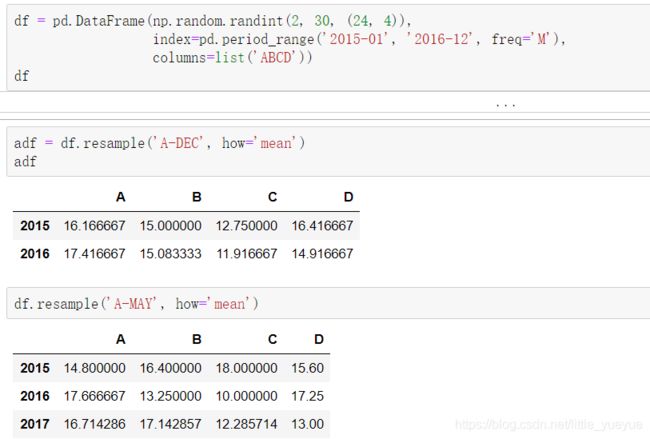
时期重采样
时期降采样
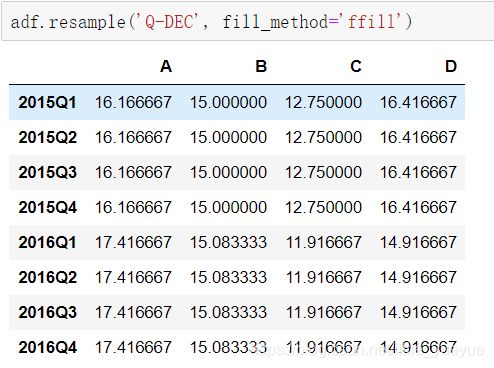
时期升采样

pandas自动解析时间日期
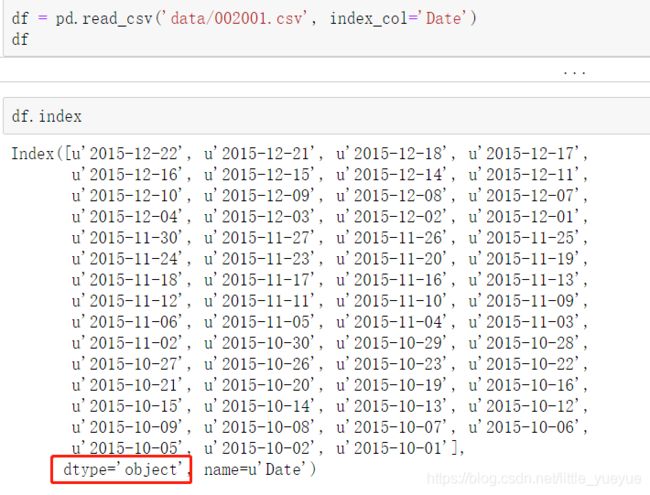
df = pd.read_csv(‘data/002001.csv’, index_col=‘Date’)#这样读出的索引类型是object
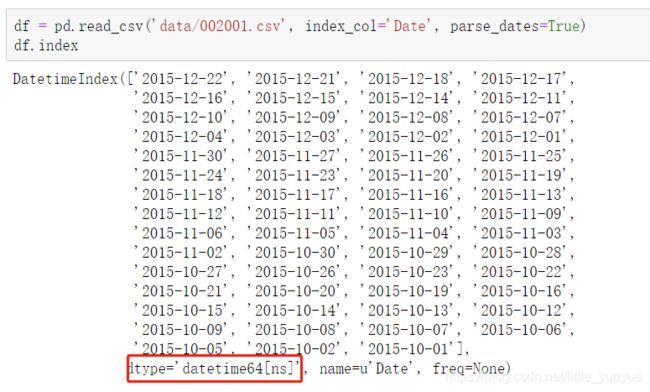
df = pd.read_csv(‘data/002001.csv’, index_col=‘Date’, parse_dates=True)#添加上参数parse_dates=True,日期索引就会变为python日期的类型
(ps:也可以直接parse_dates=[‘列名称’]指定该列为日期类型)
讲索引日期转化后就可用时间序列的方法处理,例如
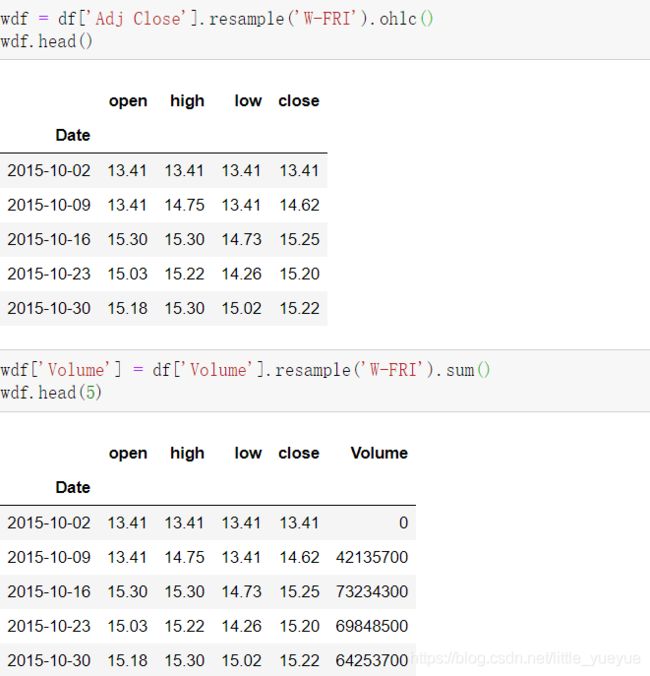
pandas自定义解析时间日期
通过date_parser参数导入解析日期的函数

时间运算
- pd.Timestamp(‘20210228’)-pd.Timestamp(‘20210205’)

- pd.Timestamp(‘20210228’)+pd.Timedelta(days=5)

category数据
df = pd.DataFrame({“id”:[1,2,3,4,5,6], “raw_grade”:[‘a’, ‘b’, ‘b’, ‘a’, ‘a’, ‘e’]})
- 创建category数据
df[“grade”] = df[“raw_grade”].astype(“category”)
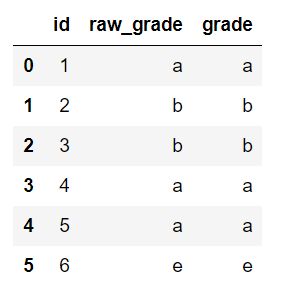
- 显示类别
df[“grade”].cat.categories

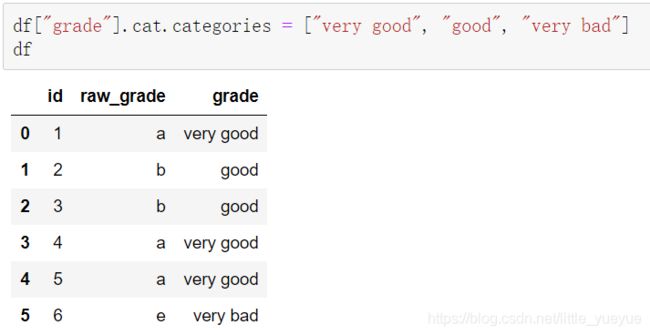
- 类别重命名
df[“grade”].cat.categories = [“very good”, “good”, “very bad”]
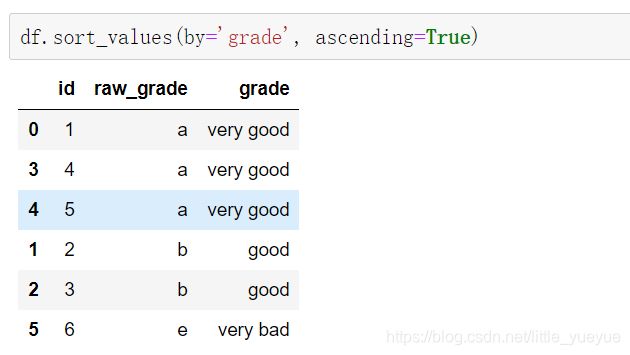
- 按类别排序(实际是按照原始的a,b,c,不是very good,good,bad)
df.sort_values(by=‘grade’, ascending=True)
one-hot编码
for col in columns[:-1]: #'需要编码的索引列位置'
t = pd.get_dummies(data[col])
t = t.rename(columns=lambda x: col+'_'+str(x)) #给重编码的列重命名,默认是列的不同属性名
x = pd.concat((x, t), axis=1)
画图
Pandas 的数据可视化使用 matplotlib 为基础组件。
%matplotlib inline #将图片画在jupyter的网页里
import pandas as pd
import numpy as np
series画图
ts.plot(title=‘cumsum’, style=‘r-’, ylim=[-30, 30], figsize=(4, 3));
- title表示图标题,style是线的种类,ylim是y轴的显示范围,figsize是图的大小
- 结尾加上;不会显示图这个对象
- 带密度估计的规格化直方图
ts.plot.hist(bins=100, alpha=0.5, normed=True)
s.plot.kde(style=‘r-’)
| 图 | 代码 |
|---|---|
| 折线图 | ts.plot() |
| 饼图 | ts.plot.pie() |
| 直方图 | ts.plot.hist() |
| 柱状图 | ts.plot(kind=‘bar’) |
| 密度图 | ts.plot.kde() |
dataframe画图
| 参数 | 示例 | 意义 |
|---|---|---|
| subplot | subplot=True | 以多个子图的形式展示数据 |
| xshare.yshare | xshare=True | 表示共享x轴 |
| grid | grid=True | 表示带网格 |
| fontsize | fontsize=20 | 字体大小为20 |
| figsize | figsize=(6, 6) | 图片大小为6*6 |
线形图
多列的dataframe直接df.plot()
增加参数subplots=True画子图
df.plot(title=‘DataFrame cumsum’, figsize=(4, 12), subplots=True, sharex=True, sharey=True);

指定x,y轴
柱状图
df.plot.bar()
若添加subplot=True的参数,则会产生多个子图
是否堆叠
stacked=True
画水平的柱状图
直方图
df.plot.hist(bins=20)
bins表示x轴等分成几分,alpha是直方图的透明度
是否堆叠
stacked=True
密度图
df.plot.kde()
散布图
df.plot.scatter()
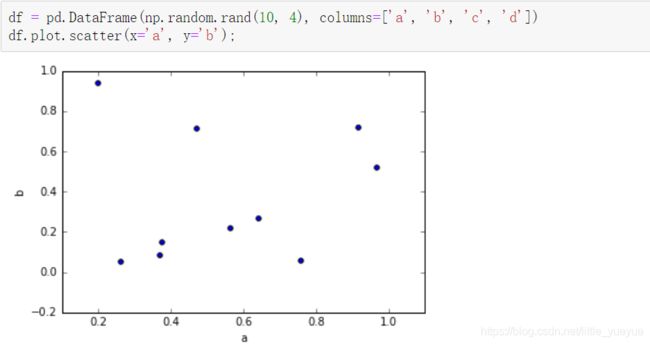
饼图
df.plot.pie()
df.plot.pie(labels=[‘AA’, ‘BB’, ‘CC’, ‘DD’], colors=[‘r’, ‘g’, ‘b’, ‘c’],autopct=’%.2f’, fontsize=20, figsize=(6, 6))
- labels表示标签
- color对应每个部分的颜色
- autopct格式化每个部分的百分比的数据格式
数据io
%more 文件名.文件格式 # 可查看文件内容
读取文件
- 索引:将一个列或多个列读取出来构成 DataFrame,其中涉及是否从文件中读取索引以及列名
- 类型推断和数据转换:包括用户自定义的转换以及缺失值标记
- 日期解析
- 迭代:针对大文件进行逐块迭代。这个是Pandas和Python原生的csv库的最大区别
不规整数据问题:跳过一些行,或注释等等
pd.read_csv(‘data.csv’, index_col=0,header=None, names=[‘a’,‘b’,‘c’],na_values=[‘NA’, ‘NULL’],nrows=10)
- index_col可指定行索引为哪一列,可以设置多级行索引,导入索引列表即可index_col=[‘a’,‘c’]。若未指定,则通过导入的数据自动识别,若无多出来的一列,则索引值默认为0,1,2,…
- 若不指定列索引,则会自动将第一行记为列索引,如需指定则为行数,例如header=3,需要指明没有列名称用header=None,另外可用names来指定列名。
- na_values可指定把哪些值当做缺失值。甚至可指定不同列的缺失值,需用字典。例如:na_values={‘message’: [ ‘NA’,‘NULL’], ‘a’: [‘0’]}
- nrows参数是读取的行数
pd.read_table(‘data.csv’, sep=’::’, engine=‘python’)
需要指定分隔符,分隔符可为正则表达式,如sep=’\s+'表示多个空格,可以解决空格数量不一致导致数据不能很好划分的问题
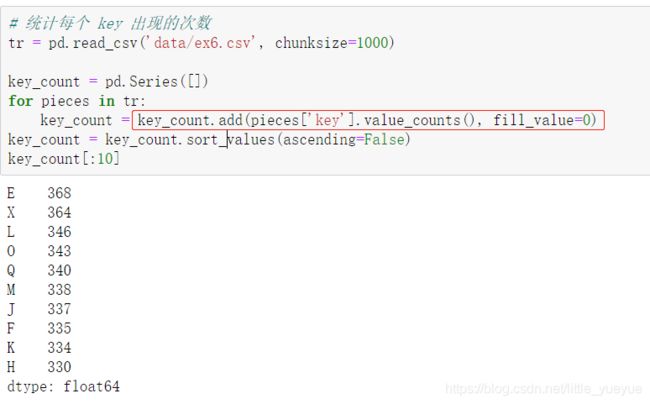
逐块读取数据
tr = pd.read_csv(‘data/ex6.csv’, chunksize=1000)
chunksize表示每次读的行数,整个返回的是一个解析器支持迭代
保存文本数据
df.to_csv(‘data/ex5_out.csv’, index=False)
- 通过index=False指定保存是不保存索引值
- 通过header=None可以指定不写列标签
- 通过columns=[‘列名1’,‘列名2’,…]指定保存的列
- 通过sep=’,'指定分隔符
其他格式文件的操作
- HDF5: HDF5是个C语言实现的库,可以高效地读取磁盘上的二进制存储的科学数据。
- Excel文件: pd.read_excel/pd.ExcelFile/pd.ExcelWriter
- JSON: 通过 json 模块转换为字典,再转换为 DataFrame
- SQL 数据库:通过 pd.io.sql 模块来从数据库读取数据
- NoSQL (MongoDB) 数据库:需要结合相应的数据库模块,如 pymongo 。再通过游标把数据读出来,转换为 DataFrame
pandas使用 numpy 函数
Pandas 与 numpy 在核心数据结构上是完全兼容的