太赞了!英伟达又一突破,输入关键词就可以生成直逼摄影师的大片

整理 | 禾木木
出品 | AI科技大本营(ID:rgznai100)
英伟达又一次突破了,这么逼真的照片竟然不是来自摄影师或是设计师!
近日,英伟达官方推出 GauGAN2 的人工智能系统,它是其 GauGAN 模型的继承者,它不仅能根据字词生成逼真的风景图像,还能实时用文字P图!
GauGAN2 将分割映射、修复和文本到图像生成等技术结合在一个工具中,通过输入文字和简单的绘图来创建逼真的图像。
Isha Salian 表示“与类似的图像生成模型相比,GauGAN2 的神经网络能够产生更多种类和更高质量的图像。”
英伟达的企业传播团队在一篇博客文章中写道。“用户无需绘制想象场景的每个元素,只需输入一个简短的短语即可快速生成图像的关键特征和主题,例如雪山山脉。然后可以用草图定制这个起点,使特定的山更高,或在前景中添加几棵树,或在天空中添加云彩。”
例如输入海浪打在岩石上,模型会根据生成的内容逐渐进行相应的调整,以生成与描述匹配的逼真图像。

GauGAN2 的生成模式
GauGAN2 有三种绘制模式,可以从不同的输入生成逼真的图像。
模式1:用涂鸦生成风景照
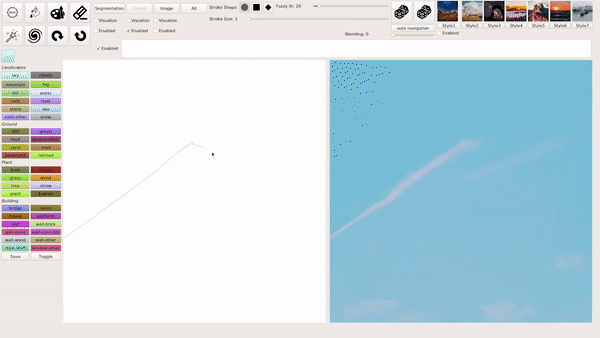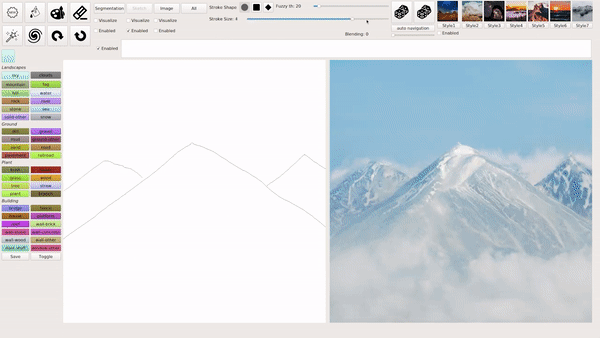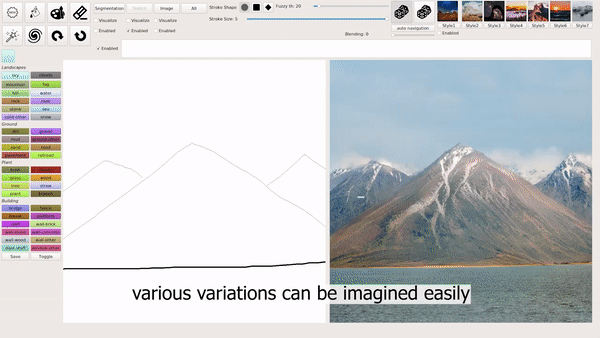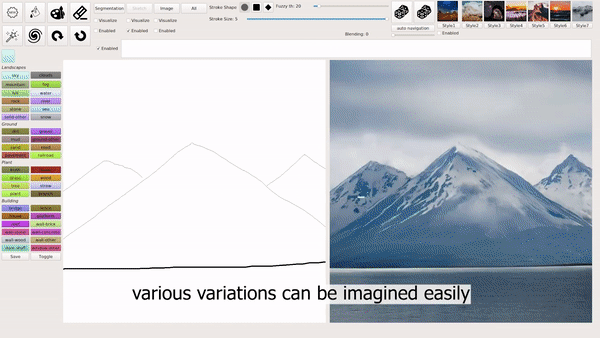
模式2:输入文本生成图片
这种输入文本生成匹配图像的模式也是 GauGAN2 主要的创新,生成的图像会根据逐渐输入的文本不断发生变化,最终生成和文本匹配最佳的图像。
例如在下图的示例中,文本首先输入 sunshine(阳光),生成的图像中就只出现了一个太阳;之后继续输入 a tall tree(高树),图像中就出现了树(且为顶部树枝,匹配高树);最后,输入的全部文本是 sunshine in a tall tree forest ,意为透过森林的阳光,GauGAN2 最终生成的图像与之相匹配:
模式 3:输入图像并编辑部分内容
如果想要抹掉移除的内容,在生成的图像中会保留剩余的部分,并自动补全出多种新的完整图像:
这三种模式也可以混合叠加使用,例如在用涂鸦绘画等生成图像后,输入文本进行相应的修改,在下图中就生成了一座浮在空中的城堡就出现了。
像像外媒ZDNet就恶搞出来了一种神奇的玩法,在已有的风景上画个人头—,画人头:
在生成这一系列逼真的图像背后用了什么原理呢?

如何实现?
从 2019 年开始,英伟达改进 GauGAN 系统,该系统由超过一百万个公共 Flickr 图像的训练而成。与 GauGAN 一样,GauGAN2 可以理解雪、树、水、花、灌木、丘陵和山脉等物体之间的关系,例如降水类型随季节而变化的事实。
GauGAN2 是一种称为生成对抗网络 (GAN) 的系统,由生成器和判别器组成。生成器用于获取样本,例如获取与文本配对的图像,并预测哪些数据(单词)对应于其他数据(风景图片的元素)。生成器试图通过欺骗鉴别器来进行训练,鉴别器则用于评估预测结果是否现实。虽然 GAN 的转换最初的质量很差,但随着鉴别器的反馈二不断改善。
与 GauGAN 不同的是,GauGAN2 是在 1000 万张图像上训练而成——可以将自然语言描述成风景图像。输入诸如“海滩日落”之类的短语会生成场景,而添加诸如“岩石海滩日落”之类的形容词或将“日落”替换为“下午”或“下雨天”等形容词会立即修改画面。
GauGAN2 用户可以生成分割图,显示场景中对象位置的高级轮廓。从那里,他们可以切换到绘图,使用“天空”、“树”、“岩石”和“河流”等标签通过粗略的草图调整场景,并允许工具的画笔将涂鸦融入图像。
这是属于更新迭代的过程,用户在文本框中键入的每个词都会为 AI 创建的图像添加更多内容,因而 GauGAN2 才能随着输入文本而不断变换图像。

结语
GauGAN2 与 OpenAI 的 DALL-E 没有什么不同。
不过,这两个模型生成的内容其实不太一样。
GauGAN2 专注于生成风景照,DALL·E 则更多地生成具体的物体,例如一把椅子或者一个闹钟等。
英伟达声称,GauGAN 的第一个版本已经被用于为电影和视频游戏创作概念艺术。与它一样,英伟达 计划在 GitHub 上提供 GauGAN2 的代码,同时在 Playground 上提供交互式演示,Playground 是 英伟达人工智能和深度学习研究的网络中心。
像 GauGAN2 这样的生成模型的一个缺点是存在偏差的可能性。例如在 DALL-E 的案例中,OpenAI 使用了一种 CLIP 模型来提高生成图像质量,但在一项研究中发现,CLIP 对黑人照片的错误分类率更高,并且存在种族和性别偏见问题。
英伟达暂不会对 GauGAN2 是否存在偏见给出回应。英伟达发言人表示:“该模型有超过 1 亿个参数,训练时间不到一个月(还在 demo 阶段),训练图像来自专有的风景图像数据集。因此 GauGAN2 只专注于风景,研究团队还对图像进行审核以确保图片中没有包含人的场景。”这将有助于减少 GauGAN2 的偏见。
目前,GauGAN2 已经可以试完,有使用过或是想要去体验的可以在留言区谈论体验感受呦~
参考链接:
https://venturebeat.com/2021/11/22/nvidias-latest-ai-tech-translates-text-into-landscape-images/
https://www.zdnet.com/article/the-absurd-beauty-of-hacking-nvidias-gaugan-2-ai-image-machine/

在评论区留言你对本文的观点
AI科技大本营将选出两名优质留言
携手【北京大学出版社】送出
《人工智能数学基础与Python机器学习实战》一本
截至11月29日14:00点


往
期
回
顾
资讯
OpenAI真的open了,更加开放
资讯
人工智能监考VS传统方式监考
资讯
Meta研发触觉手套助力元宇宙
资讯
马斯克公开支持上班“摸鱼”

分享
![]()
点收藏

点点赞

点在看