MapReduce笔记 —— shuffle阶段的运行原理
这张图片是我从林子雨老师的ppt上面截下来的
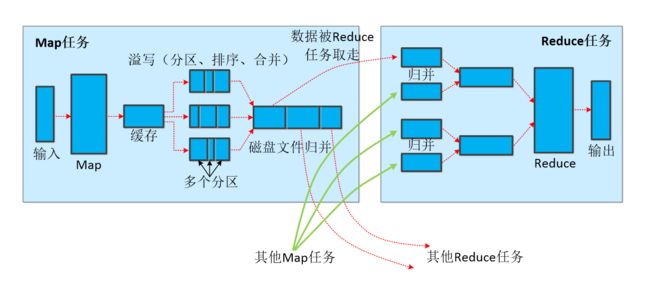
- 输入:框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,通常默认是每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个
注1:k1就是行偏移量,v1就是一行的内容。
- Map:这阶段是进行Map任务,也就是程序中的Mapper实现类。接收上一步的
注:这之后就是看reduce任务是否存在,通常默认有一个reduceTask,存在则进行shuffle阶段,将数据
- 缓存:一个inputSplit对应一个mapTask,一个mapTask对应一个位于内存中的环形缓冲区,用来存储mapTask的输出(也就是第二步的输出结果
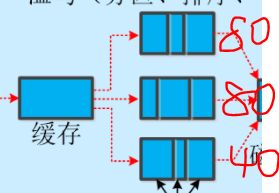
注1:将缓冲区中的数据临时写入磁盘,然后重新利用环形缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写
注2:当缓冲区快满的时候需要将缓冲区的数据以一个临时文件(也就是我上面说的溢写文件)的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
注3:溢写过程时单独启用一个线程来完成,不会影响map继续往缓冲区写入结果
注4:整个环形内存缓冲区就是一个字节数组,但是这个数字是个环形数据结构,前后相接。数组阈值为0.8,数据占比达到阈值就开始溢写也就是往磁盘写。剩下预留的20M空间会在缓冲区溢写时继续接收maptask的输出。如果80M还没有溢写完成,20M的预留空间就写完了,这个时候线程处于阻塞状态,直到80M溢写完成
在写入磁盘之前,还会经历三个阶段,即图上的分区,排序,合并
-
分区 partition (时间在Map结束后,写入缓冲区之前,key/value对以及Partition的结果都会被写入缓冲区)
对于map输出的每一个键值对,系统都会给定一个partition,partition值默认是根据 key的hashcode码 % reduceTask数量 得到,partition决定这个键值对由哪个reduceTask来接收,假如partition值为0,则交给第一个reduce处理
如果reduceTask只有一个或者没有,那么partition将不起作用
-
排序 sort(时间在溢写线程启动后)
在溢写文件中,根据key值对键值对进行排序,相同key的键值对会被放在一个区域内。像下图这样,一部分key都为a,一部分的key都为b。三个方格的大小也不相同,因为一个溢写文件中不同key的键值对数量并不相同
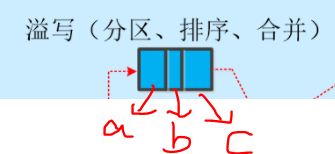
比如
- combine (时间在sort排序之后)
将key值相同的键值对的value加起来,从而减少溢写到磁盘的数据量
比如
注1:即使没有定义Combiner函数,shuffle过程也会把具有相同key的键值对归并为一个键值对,但是里面的形式为
注2:combine不应该改变最终的结果,因此只适用于部分场景。比如要求每个键值对的value值的平方值之和,假设键值对为
所以combine一般用在等幂的计算之中,比如求和求差求对最大值等
注3:
- combine可以理解为是在map端的reduce的操作,对单个map任务的输出结果数据进行合并的操作
- combine是对一个map的,而reduce合并的对象是对于多个map
比如一个mapTask的结果有100个< a,1>,一共有十个mapTask,那么reduce里面要对value-list进行遍历的数量多不说,还会在map端传入reduce端时占用网络的传输资源,增加磁盘的IO负载。因此可以在map端用combine做一次合并操作,一个mapTask将结果文件合成为
- merge:归并排序。将多个溢写文件合并成一个大的溢出文件
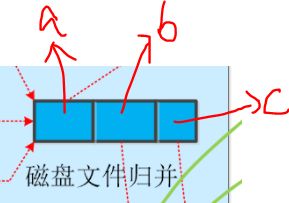
这样一个mapTask任务产生的键值对结果,会这样按顺序存放在一个溢出文件中
注1:不同的溢写文件中也会出现相同key的键值对,所以如果定义了combiner函数,也会在这里使用combine来合并相同key的键值对。同样的,如果不合并就是
至此,map端的shuffle阶段结束,文件被保存在了磁盘之中。之后就是reduce端的shuffle阶段
-
copy:reduce会启动一些专门的数据copy线程到指定位置拉取文件,也就是从map端领取自己要处理的键值对。
注1:根据之前设置的partition来设置哪些键值对到哪个reduceTask中
-
merge:reduceTask会领取到不同mapTask输出的结果文件,然后将这些结果文件再一次进行merge归并排序
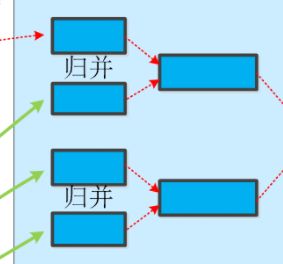
上图是假设一个reduceTask中,需要处理两个键值对,分别是key为a的键值对,以及key为b的键值对。
需要进行归并排序的原因:
(1)数据来源不同,reduce的数据来源可能来自内存,也可能来自磁盘。我们希望的是数据存放于内存中,直接作为Reducer的输入,但mapTask结果文件默认是保存在磁盘中
(2)多个mapTask的结果混杂在一起,一个mapTask中没有重复的key,而多个mapTask的结果文件中会出现相同的key,这些key值相同的键值对会根据partition到同一个reduceTask中,由Reducer函数进行处理。
因此在交给Reducer处理前,还需要将这些相同key的键值对归并在一起。另外由于不同key的partition值可能相同,所以一个reduce会处理不同key的键值对,所以归并之后还会有一个排序。
如果没有combine的话,最后到了reduce中的数据会是
- reduce函数运行结束,向hdfs中写入结果文件
至此,整个mapreduce程序结束
在学习的过程中,以下几篇博客帮助我理解了很多内容,建议看一看
第一篇
MapReduce shuffle过程详解
第二篇
MapReduce的Shuffle机制
第三篇(这一篇博客是转载,感兴趣的朋友可以在里面找到源地址)
mapreduce里的shuffle 里的 sort merge 和combine
第四篇
MapReduce之combine