Spark运行原理及任务调度源码解析(基于Spark3.0)
Spark运行模式
- 可以在本地多线程运行
- 伪分布式运行
- Yarn运行模式
- Mesos运行模式
基本概念
1.application
也就是API用户编写的程序,这个程序是分为两部分执行的,一部分是放在Driver端执行的,用于驱动整个程序运行的逻辑,还有一部分是放在各个节点上,让集群协同计算的部分
2.Driver
Driver在Spark中是用户定义在main方法中,驱动整个Spark程序运行创建SparkContext,为Spark的运行创建环境,负责计算资源的申请,销毁,任务的监控分配
3.Executor
运行在worker节点上的一个进程,可以创建多个线程,运行多个Task,系那个中间结果存在本地磁盘或者内存中,运行的时候从线程池中找一个空闲线程运行task,并行度取决去CPU的逻辑核心数
4.ClusterManger,也就是调度资源的服务,Yarn,standalone,Mesos等
5.Task
Excutor运行的最小单元,由Driver端生成,通过序列化发送到Worker,反序列化之后运行,一个Job可以呗划分为多个阶段,Task的数量取决于父RDD的分区数量,一个JOB可以有多个stage,每个stage可以有多个分区,每个分区对应一个Task,Task由TaskScheduler负责
6.JOB
通过Action触发,一个APP中可以由多个job,运行完一个之后可以再启动一个job,通常我们写的都是一个
7.Stage
也就是任务划分的阶段,一个JOB被划分成很多的Task,Stage有ShuffleMapStage(非最终stage),和ResultStage(结果结点),Stage的切分就在shuffle发生的地方,每次shuffle都会将任务一刀两断
8.RDD
Spark最核心的东西,是对分区有序数据的抽象,里面记录的是描述信息(哪个文件,这些文件其实是分布在不同机器上的,序列化的,不可变,容错弹性的),RDD就是这些文件的抽象集合,让我们操作的时候不用关心怎么整合各个分区的文件之类的繁琐
9.共享变量
1.广播变量,也就是每个结点都有一个
2.累加变量,多个结点共同操作的一个变量
10,宽依赖,
宽依赖是Shuffle的根源,
11窄依赖,
窄依赖不需要shuffle,因为他只有一个父依赖,直接一个task就可以完成了,不需要划分另外的阶段,也不需要shuffle
12.DAGscheduler
DAG是根据stage和RDD之间的依赖关系构建出来的执行顺序,DAGSheduler通过DAG调度任务(stage)执行顺序
13TaskScheduler
将TaskSet提交给Worker运行,每个Worker运行什么Task通过他进行分配
任务调度原理
任务调度最重要的两个部分,即DAGSheduler和TaskSheduler,负责将用户提交的任务生成执行关系(DAG),划分为不同的阶段,提交到集群中进行最终的计算,整个过程如下图:
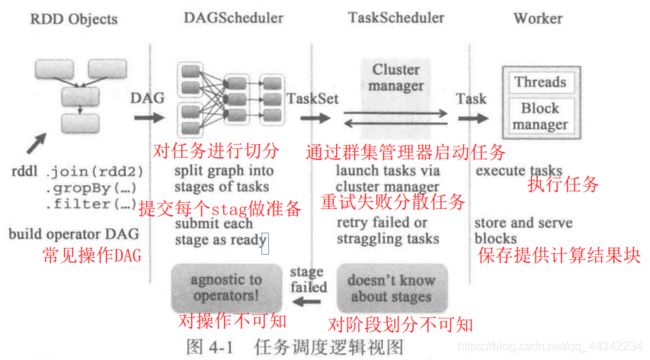
DAGScheduler和TaskSche中传输的是TaskSet,TackSche和Worker中间传输的是Task
1.通过用户的操作,创建DAG,生成DAG后发送给DAGScheduler,TaskShed这里对任务进行切分,切分成不同的stage,将每个stage中的TaskSet发送给TaskScher
2.TaskShe通过ClusterManager发送Task给Worker结点的Executor,Executor将开启线程进行计算执行,并且保存任务到本地或者回传到Driver端
TaskScheduler
为SparkContext调度任务,从不同的DAGscheduler(不同的任务),接收不同的Stage向集群提交任务,备份任务,他会调用schedulerBackend(在新任务提交的时候,任务执行失败,计算结点挂掉了,执行过慢重新分配任务)
schedulerBackend
对Exechutor分配任务Task,并且在Executor上执行Task
有多个TaskSheduler,也有多个schedilerbackend,他们是一对一的关系,并且都被SparkContext持有
调度总览
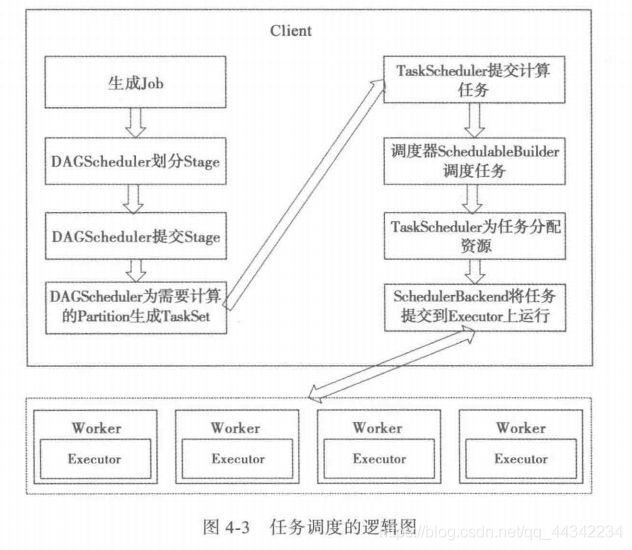
DAGScheduler实现
DAGScheduler主要负责对应用进行划分阶段,为什么划分阶段?应为程序是放在集群中运行的,一个阶段依赖于另一个阶段的结果,并且执行是有先后顺序的,所以要划分
划分出来的stage是放在集群中运行的,其中每个stage有多个task,每个task的逻辑都是一样的,只是对应的分区是不相同,
这多个task被分布在不同的机器上并发执行.
不同的资源调度框架,yarn,或者是mesos,local等生成的DAG是完全一样的,可以跨平台运行保证结果
DAGScheduler随着sparkContext的创建而创建,
RunJob函数,SparkContext类的这个方法是所有程序运行的入口
/**
*在RDD中的给定分区集上运行函数,并将结果传递给给定的
*处理程序函数。这是Spark中所有操作的主要入口点。
*
*运行任务的@param rdd target rdd
*@param func在RDD的每个分区上运行的函数
*@param partitions要在其上运行的分区集;某些作业可能不希望在所有分区上进行计算
*目标RDD的分区,例如用于“first()之类的操作`
*@param resultHandler 回调函数
**/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}DAGScheduler的创建
private[spark] class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())MapOutputTrackerMaster,是运行在Driver端管理ShuffleMapTask的输出的,下游可以通过他获取shuffle的输出位置
BlockManagerMaster,管理整个job的block信息
还会初始化一个Actor通信,用来接收外部的信息,提供服务0
Job的提交
以RDD.count方法为例
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum调用了Runjob
/**
*在RDD中的所有分区上运行一个作业,并在数组中返回结果。
*
*运行任务的@param rdd target rdd
*@param func在RDD的每个分区上运行的函数
*@return in memory collection和作业的结果(每个collection元素将包含
*一个分区的结果)
*/
def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
runJob(rdd, func, 0 until rdd.partitions.length)
}Runjob调用了
DAGScheduler.runjob/**
*在RDD中的给定分区集上运行函数,并将结果传递给给定的
*处理程序函数。这是Spark中所有操作的主要入口点。
*
*运行任务的@param rdd target rdd
*@param func在RDD的每个分区上运行的函数
*@param partitions要在其上运行的分区集;某些作业可能不希望在所有分区上进行计算
*目标RDD的分区,例如用于“first()之类的操作`
*@param resultHandler回调以将每个结果传递给
*/
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}其中最关键的 def submitJob[T, U]()的调用
/**
*在RDD中的给定分区集上运行函数,并将结果传递给给定的
*处理程序函数。这是Spark中所有操作的主要入口点。
*
*运行任务的@param rdd target rdd
*@param func在RDD的每个分区上运行的函数
*@param partitions要在其上运行的分区集;某些作业可能不希望在所有分区上进行计算
*目标RDD的分区,例如用于“first()之类的操作`
*@param resultHandler回调以将每个结果传递给
*/
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.isEmpty) {
val clonedProperties = Utils.cloneProperties(properties)
if (sc.getLocalProperty(SparkContext.SPARK_JOB_DESCRIPTION) == null) {
clonedProperties.setProperty(SparkContext.SPARK_JOB_DESCRIPTION, callSite.shortForm)
}
val time = clock.getTimeMillis()
listenerBus.post(
SparkListenerJobStart(jobId, time, Seq.empty, clonedProperties))
listenerBus.post(
SparkListenerJobEnd(jobId, time, JobSucceeded))
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.nonEmpty)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
启动一个Job等待者,将生成的jobid和分区数量,等作为参数,并且将这个时间放入事件池中,返回等待结果
val waiter = new JobWaiter[U](this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
Utils.cloneProperties(properties)))
waiter
}启动一个Job等待者,将生成的jobid和分区数量,等作为参数,并且将这个时间放入事件池中,返回等待结果
后面就交给事件监听者处理了,
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)这个类定义了很多的监听事件
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, workerLost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}经过对前面事件的处理,放入到处理队列中等待结果的返回,前面的JobWaiter会监听Job的执行状态,
下面我们来详细看一下是怎样处理任务执行结果的
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
var finalStage: ResultStage = null
try {
//如果执行的文件缺失了,会报错
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
//匹配
case e: BarrierJobSlotsNumberCheckFailed =>
// 如果jobid不存在了,就在Int:0的基础上+1
val numCheckFailures = barrierJobIdToNumTasksCheckFailures.compute(jobId,
(_: Int, value: Int) => value + 1)
//如果失败次数小于最大失败次数,就开启一个线程,再次发送到处理队列
if (numCheckFailures <= maxFailureNumTasksCheck) {
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(JobSubmitted(jobId, finalRDD, func,
partitions, callSite, listener, properties))
},
timeIntervalNumTasksCheck,
TimeUnit.SECONDS
)
return
} else {
//否则就认定作业失败,清楚内部数据,发送失败消息
barrierJobIdToNumTasksCheckFailures.remove(jobId)
listener.jobFailed(e)
return
}
//最大的错误兜底
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// 再次清楚
barrierJobIdToNumTasksCheckFailures.remove(jobId)
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
//发送具体的任务到任务消费者
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}这个方法会创建 createResultStage 然后创建 val job = new ActiveJob(jobId, finalStage, callSite, listener, properties) 通过listenerBus.post(...)提交资源
Stage的划分
为什么需要stage上面已经提到了这里再来详细的讨论一下
划分Stage的原因是由于任务类型的不一致,有的任务只依赖于一个父的RDD,所以可以和父RDD放到同一task中执行,构成一个阶段,但是有的任务(例如reduce,group)等,需要的是全局数据,依赖于多个分区的处理结果,所以只等等待前面的执行,这就有了先后顺序(Stage)
每个stage由多个task组成,这些task在任务逻辑上是一致的只是对应不同的分区,Partition的数量和同一任务逻辑的Task的数量是一致的,也就是说一个分区会被对应的stage的一个task处理,而多个Executor争抢,如果计算资源充足,一个Exe执行一个,不足会计算多个task
如果不知道什么是宽窄依赖,可以看前面的博客[Spark实战学习]
宽依赖是DAG的分界线,也是stage的分界线
stage的划分是从最后RDD一个开始的,也就是触发action的RDD
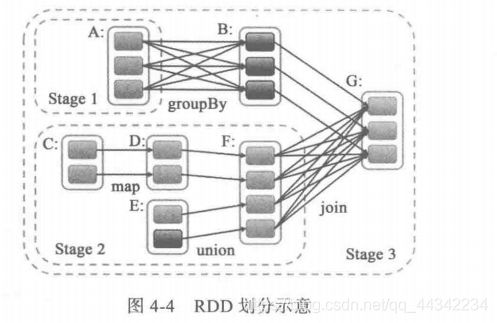
handleJobSubmitted开始stage的划分,从G开始,G依赖于B,F,先处理B还是F是随机的,由于B是G的窄依赖,所以GB在同一个stage中,而对于F是G的宽依赖,中间存在Shuffle,只能在F执行完才能执行G,所以F比G早一个stage,AB之间也是宽依赖,所以B跟A不能是同一个阶段,A单独一个阶段,所以BG所在的stage3有两个父依赖阶段,
stage1和2是独立的,可以并发,但是他们对于stage3来说是要等待其执行结果的
实现源码
submitMapStage,调用了stage的创建doOnReceive中定义了消息监听,来创建map阶段的stagecase MapStageSubmitted(jobId, dependency, callSite, listener, properties) => dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
private[scheduler] def handleMapStageSubmitted(jobId: Int,
dependency: ShuffleDependency[_, _, _],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
// Submitting this map stage might still require the creation of some parent stages, so make
// sure that happens.
var finalStage: ShuffleMapStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = getOrCreateShuffleMapStage(dependency, jobId)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got map stage job %s (%s) with %d output partitions".format(
jobId, callSite.shortForm, dependency.rdd.partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.addActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
// If the whole stage has already finished, tell the listener and remove it
if (finalStage.isAvailable) {
markMapStageJobAsFinished(job, mapOutputTracker.getStatistics(dependency))
}
} /**
* Create a ResultStage associated with the provided jobId.
*/
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}其中最重要的是
finalStage = getOrCreateShuffleMapStage(dependency, jobId)getOrCreateShuffleMapStage是个递归方法
/**
*获取shuffleIdToMapStage中存在的shuffle映射阶段。否则,如果
*shuffle map stage不存在,此方法将在中创建shuffle map stage
*除了任何丢失的祖先洗牌地图阶段。
*/
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage
case None =>
//为所有丢失的祖先洗牌依赖项创建阶段。
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
//即使getMissingAncestorShuffleDependencies只返回shuffle依赖项
//在shuffleIdToMapStage中还没有出现,可能在我们
//在foreach循环中获取一个特定的依赖项,它被添加到
//shuffleIdToMapStage由早期依赖项的阶段创建过程执行。看到了吗
//SPARK-13902了解更多信息。
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// Finally, create a stage for the given shuffle dependency.
createShuffleMapStage(shuffleDep, firstJobId)
}
}查找shuffled的stage,如果没有就创建,所以
提交stage,将所有没有提交的parentstage提交运行,然后提交当前stage
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage): Unit = {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug(s"submitStage($stage (name=${stage.name};" +
s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}只有父stage提交了才能提交,这里对顺序进行了控制,submitmissingTask,会将最后的工作提交
submitmissingTask里面进行了Task的创建
如果找不到父Stag说明是最开始的,也就是触发action的RDD
/**查找尚未在shuffleToMapStage中注册的祖先shuffle依赖项*/
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): ListBuffer[ShuffleDependency[_, _, _]] = {
val ancestors = new ListBuffer[ShuffleDependency[_, _, _]]
//存祖先依赖
val visited = new HashSet[RDD[_]]
//存RDD的set集合
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new ListBuffer[RDD[_]]
waitingForVisit += rdd
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {
visited += toVisit
getShuffleDependencies(toVisit).foreach { shuffleDep =>
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
ancestors.prepend(shuffleDep)//往前添加依赖,从后往前
waitingForVisit.prepend(shuffleDep.rdd)
} // Otherwise, the dependency and its ancestors have already been registered.
}
}
}
ancestors
}
getShuffleMapStage就是获取shuffle所依赖的stafe
MapOutPutTrancker保存了map阶段结果的元数据信息,后面的task通过元数据获取数据
到这里DAGScheduler就完成了使命,等待这TaskScheduler对任务进行提交,过程中DAG还是会接收到任务执行的消息
主要参考SparkContext和DAGScheduler
举例WordCount的执行流程
Task有两类,
一种是不产生结果的,shuffleMapTask用来生成中间结果的任务,可以通过设置分区控制数量
还有一种是产生结果的,也叫做ResultTask,可以通过设置调整结果的处理数量
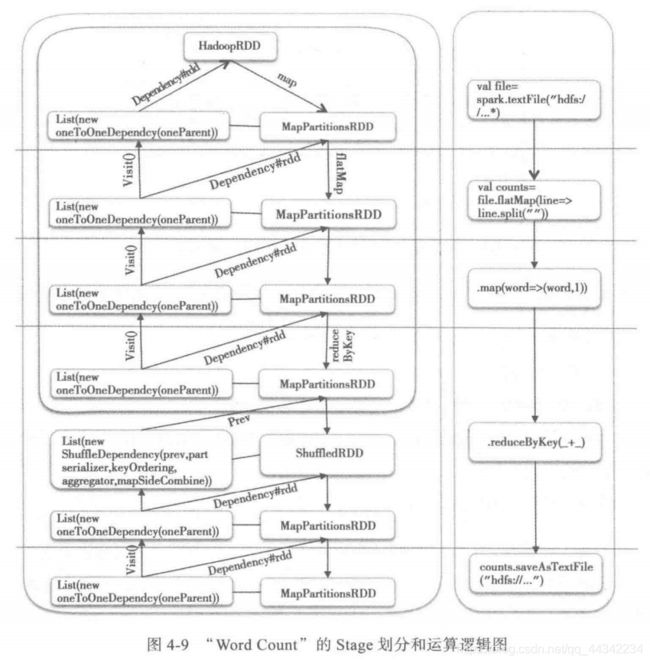
前三个RDD都是一个stage,依赖类型都是一对一的窄依赖,不用shuffle可以并行执行,直到reduceByKey()
这个方法,会将各个分区的同一个key的结果汇总(HashPartitioner)到一个同一个分区的同一个excutor的同一个task里面进行汇总
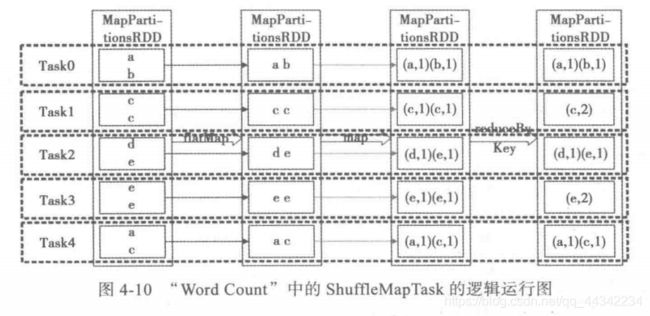
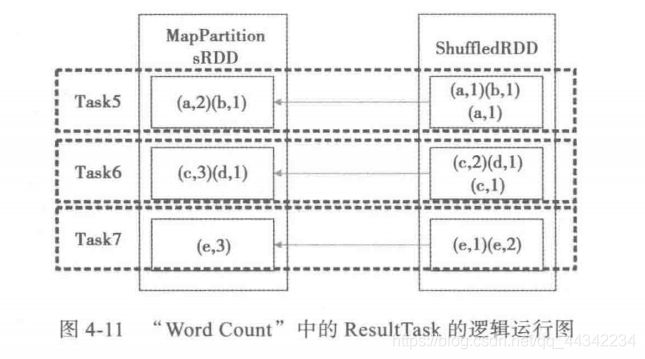
前面设置了5个task,所以会在shuffleMapTask阶段生成5个任务并行化执行,但是在ResultMap阶段会运行三个,这三个会去拉取block块,然后继续执行,将shuffleMapTask生成的结果,进行汇总,然后输出
如何将用户逻辑转化为并行执行的任务?
如何实现移动运算优于移动数据?
如何实现shuffle?及数据传递到指定的任务?
如何分配计算资源?
留坑