hadoop核心组件
Social media usage is one of the most popular online activities. Safe to say you use at least a social media platform, be it Facebook, Instagram, Twitter, Snapchat, WhatsApp, Tiktok; the list is endless. One common denominator to all these platforms is data generation. While using any of the aforementioned platforms, we generate a lot of data through comments, uploads, clicks, likes, retweets, downloads, swipes, etc. The time spent, login location, personal information, etc are also some examples of data generated. In 2018, Forbes stated 2.5 quintillion bytes of data were generated every day. As of January 2019, the internet reaches 56.1% of the world population which represents 4.49 billion people a 9% increase from January 2018. With the Pandemic in 2020, the use of the internet and the generation of data has increased tremendously.
社交媒体的使用是最受欢迎的在线活动之一。 可以肯定地说,您至少使用社交媒体平台,例如Facebook,Instagram,Twitter,Snapchat,WhatsApp,Tiktok; 列表是无止境的。 所有这些平台的一个共同点是数据生成。 在使用上述任何平台时,我们都会通过评论,上传,点击,喜欢,转推,下载,滑动等方式生成大量数据。花费的时间,登录位置,个人信息等也是生成数据的一些示例。 《福布斯》在2018年表示,每天产生2.5亿字节的数据。 截至2019年1月, 互联网已达到世界人口的56.1% ,代表着44.9亿人,比2018年1月增加了9%。随着2020年的大流行,互联网的使用和数据的产生已大大增加。
This article focuses on introducing you to big data and to the core component of Hadoop which is the main technology behind Big Data.
本文重点介绍大数据和Hadoop的核心组件,后者是大数据背后的主要技术。
Before we continue, we need to understand what Big Data really is and some concepts in Big Data.
在继续之前,我们需要了解什么是大数据以及大数据中的一些概念。
According to Wikipedia Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. In lame man’s words, Big Data is a way of analyzing and processing this large amount of data generated every day. For example, Facebook processes and analyses data about us to show us personalized advertisements.
根据Wikipedia的介绍,大数据是一个领域,用于分析方法,系统地从中提取信息或以其他方式处理太大或过于复杂而无法由传统数据处理应用程序处理的数据集。 用la脚的话来说,大数据是一种分析和处理每天生成的大量数据的方法。 例如,Facebook处理和分析有关我们的数据以向我们显示个性化广告。
To fully understand the importance of Big data, we need to understand the 5 Vs of big data.
为了充分理解大数据的重要性,我们需要了解大数据的5个优势。
5 Vs大数据 (5 Vs of big data)
Volume is the size of data being generated. As explained earlier we generated a large amount of data every day. These data are obtained from smart(IoT) devices, social media platforms, business transactions, etc.
卷是所生成数据的大小 。 如前所述,我们每天都会生成大量数据。 这些数据是从智能(IoT)设备,社交媒体平台,业务交易等获得的。
Velocity has defined in physics, is the rate of change, that is how something changes with respect to time. In Big Data, velocity is the rate at which new data is generated, in other words, the speed at which data is generated. With an increase in the population of people using the internet coupled with the ability to do anything from the comfort of our home, the velocity at which data is generated has seen an unprecedented increase every year.
速度在物理学中已定义为变化率,即事物随时间变化的方式。 在大数据中,速度是生成新数据的速率,换句话说,就是生成数据的速度 。 随着使用互联网的人口的增加以及在我们舒适的家中做任何事情的能力,数据生成的速度每年都以前所未有的速度增长。
Variety involves the type of data. Data can be structured, semi-structured, and unstructured. Structured data are well defined, that is storing the data has some constraints. For instance, each column in the storage is well defined. An example is a relational database storing the bio of consumers. Semi-structured data have a few definitions like organization properties, examples are XML and JSON files. Unstructured data have no definitions. Examples are data generated by an IoT device, social media posts, etc. Another form of variety could also be the format of the data. Format of images (PNG, JPEG, JPG, etc), videos (3GP, MP4, MKV, AVI, etc), audio (MP3, AAC, WAV, etc), text (DOCX, TXT, DOC, PDF, etc), and so on.
多样性涉及数据的类型 。 数据可以是结构化,半结构化和非结构化的。 结构化数据定义良好,也就是说存储数据有一些约束。 例如,存储中的每一列都定义明确。 一个示例是存储消费者个人资料的关系数据库。 半结构化数据具有一些定义,例如组织属性,例如XML和JSON文件。 非结构化数据没有定义。 例如,物联网设备,社交媒体帖子等生成的数据。另一种形式的变化也可以是数据的格式。 图片格式(PNG,JPEG,JPG等),视频(3GP,MP4,MKV,AVI等),音频(MP3,AAC,WAV等),文本(DOCX,TXT,DOC,PDF等)等等。
Veracity focuses on the accuracy and quality of the data. That is the inconsistency and uncertainty in the data. Since data is gotten from different sources, it is difficult to control the quality and accuracy of the data. For instance, my address on Facebook can be saved as Berlin Germany but I already moved to New York, USA.
准确性侧重于数据的准确性和质量 。 那就是数据的不一致和不确定性。 由于数据是从不同来源获取的,因此很难控制数据的质量和准确性。 例如,我在Facebook上的地址可以保存为德国柏林,但是我已经搬到美国纽约。
Value focuses on what we can gain from the data. That is the insight that can be obtained from the data. The useful information that can be extracted from the data.
价值重点在于我们可以从数据中获得什么。 那就是可以从数据中获得的见解。 可以从数据中提取的有用信息。
So much about Big Data, let us dive into the technologies behind Big Data. It is fundamental to know that the major technology behind big data is Hadoop.
关于大数据,那么让我们深入探讨大数据背后的技术。 知道大数据背后的主要技术是Hadoop是至关重要的。
Hadoop的历史 (History of Hadoop)

Hadoop core components source
Hadoop核心组件 源
As the volume, velocity, and variety of data increase, the problem of storing and processing data increase. In 2003 Google introduced the term “Google File System(GFS)” and “MapReduce”. Google File System(GFS) inspired distributed storage, while MapReduce inspired distributed processing. GFS provides efficient and reliable access to data. It also divides a large file to small chunks, each chunk is stored and processed by different computers, and the output from each computer is accumulated together to give the final result. GFS inspired Hadoop. Hadoop started out as a project called “Nutch” in Yahoo by Doug Cutting and Tom White in 2006. The name “Hadoop” was derived from Doug Cutting kid’s toy - a stuffed yellow elephant.
随着数据量,速度和种类的增加,存储和处理数据的问题也增加。 Google在2003年引入了术语“ Google File System(GFS)”和“ MapReduce”。 Google文件系统(GFS)启发了分布式存储,而MapReduce启发了分布式处理。 GFS提供了有效而可靠的数据访问。 它还将一个大文件分为几个小块,每个块由不同的计算机存储和处理,并且将每台计算机的输出累加在一起以得到最终结果。 GFS启发了Hadoop。 Hadoop最初是由Doug Cutting和Tom White于2006年在Yahoo发起的一个名为“ Nutch”的项目。“ Hadoop”的名称源自Doug Cutting孩子的玩具-毛绒的黄色大象。
Hadoop is an open-source software platform for distributed storage(managed by Hapood File System)(HTFS))and distributed processing(managed by MapReduce) of very large datasets on computer clusters built from commodity hardware — Hortonworks
Hadoop是一个开源软件平台,用于分布式存储(由Hapood文件系统管理)和由商品硬件构建的计算机集群上的超大型数据集的分布式处理(由MapReduce管理)— Hortonworks
Hadoop核心组件 (Hadoop Core Components)
数据存储 (Data storage)
Hadoop File System(HDFS) is an advancement from Google File System(GFS). It is the storage layer of Hadoop that stores data in smaller chunks on multiple data nodes in a distributed manner. It also maintains redundant copies of files to avoid complete loss of files. HDFS is similar to other distributed systems but its advantage is its high tolerance and use of low-cost hardware. It contains NameNode and DataNodes.
Hadoop文件系统(HDFS)是Google文件系统(GFS)的改进。 正是Hadoop的存储层以分布式方式将数据以较小的块存储在多个数据节点上。 它还维护文件的冗余副本,以避免完全丢失文件。 HDFS与其他分布式系统相似,但其优势在于其高容忍度和使用低成本硬件。 它包含NameNode和DataNodes。
数据处理 (Data Processing)

Mapreduce is a programming technique in Hadoop used for processing large amounts of data in parallel. MapReduce is divided into two phases, first is the map phase where Mappers transform data across computing clusters and second is the reduce phase where reducers aggregate the data together.
Mapreduce是Hadoop中的一种编程技术,用于并行处理大量数据。 MapReduce分为两个阶段,第一阶段是地图阶段,在此阶段Mappers跨计算集群转换数据,第二阶段是化简阶段,在此阶段,化简器将数据聚合在一起。
集群资源管理 (Cluster Resource Management)
Yet Another Resource Negotiator (YARN) — is used for managing resources of clusters of computers. This is the major difference between Hadoop 1.0 and Hadoop 2.0, it is the cluster manager for Hadoop 2.0. Its advantage is separating MapReduce from resource management and job scheduling.
另一个资源协商器(YARN) –用于管理计算机群集的资源。 这是Hadoop 1.0和Hadoop 2.0之间的主要区别,它是Hadoop 2.0的集群管理器。 它的优点是将MapReduce与资源管理和作业计划分开。

Mesos is used for handling workload in a distributed environment through dynamic resource sharing and isolation. It is used for managing the entire data center.
Mesos用于通过动态资源共享和隔离来处理分布式环境中的工作负载。 它用于管理整个数据中心。
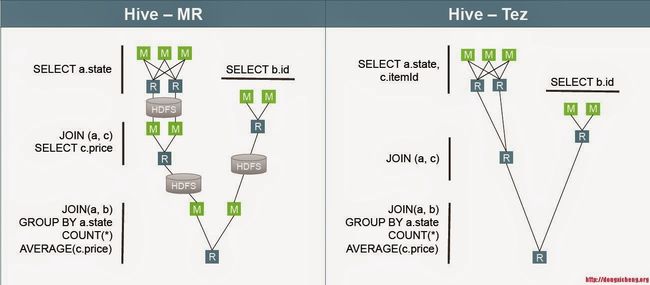
Tez is used for building high-performance batch and interactive data processing applications coordinated by YARN in Hadoop. It allows complex Directed Acyclic Graph(DAG). It can be used to run Hives queries and Pig Latin scripts.
Tez用于在Hadoop中构建由YARN协调的高性能批处理和交互式数据处理应用程序。 它允许复杂的有向无环图(DAG)。 它可以用于运行Hives查询和Pig Latin脚本。
脚本编写 (Scripting)

Pig is a high-level API that is used for writing simple scripts that looks like SQL instead of writing in python or Java. It runs on Apache Hadoop and executes Hadoop jobs in Map Reduce, Apache Tez, or Apache Spark. Pig contains a Pig Latin script language and runtime engine.
猪 是高级API,用于编写类似于SQL的简单脚本,而不是用python或Java编写。 它在Apache Hadoop上运行,并在Map Reduce,Apache Tez或Apache Spark中执行Hadoop作业。 Pig包含Pig拉丁脚本语言和运行时引擎。
询问 (Query)
Hive is a data warehouse software built on Apache Hadoop, this is similar to PIG. It helps in reading, writing, and managing large datasets in a distributed storage using SQL like queries called HQL(Hive Query Language). It is not designed for online transaction processing(OLTP), it is only used for Online Analytical.
Hive是基于Apache Hadoop构建的数据仓库软件,类似于PIG。 它有助于使用SQL之类的称为HQL(Hive查询语言)的查询来读取,写入和管理分布式存储中的大型数据集。 它不是为联机事务处理(OLTP)设计的,仅用于联机分析。

Drill is a distributed interactive SQL query engine for Big data exploration. It queries any kind of structured and unstructured data in any file system. The core component of Drill is Drillbit.
Drill是用于大数据探索的分布式交互式SQL查询引擎。 它查询任何文件系统中的任何类型的结构化和非结构化数据。 Drill的核心组件是Drillbit。

Impala is an MPP(Massive Parallel Processing) SQL query engine for processing large amounts of data. It provides high performance and low latency compared to other SQL engines for Hadoop.
Impala是用于处理大量数据的MPP(大规模并行处理)SQL查询引擎。 与其他用于HadoopSQL引擎相比,它提供了高性能和低延迟。

Hue is an interactive query editor then provides a platform to interact with data warehouses.
Hue是一个交互式查询编辑器,然后提供了一个与数据仓库进行交互的平台。
NoSQL (NoSQL)

HBase is an open-source column-oriented non-relational distributed(NoSQL) database modeled for real-time read/write access to big data. It is based on top of HDFS, it is used for exposing data on clusters to transactional platforms.
HBase是一个开源的面向列的非关系分布式(NoSQL)数据库,其建模目的是对大数据进行实时读写访问。 它基于HDFS,用于将群集中的数据公开给事务性平台。
流媒体 (Streaming)

Flink is an open-source stream processing framework, it is a distributed streaming dataflow engine. It is a stateful computation over data streams. It integrated query optimization, concepts from database systems, and efficient parallel in-memory and out of core algorithms with the MapReduce framework.
Flink是一个开源流处理框架,它是一个分布式流数据流引擎。 它是对数据流的有状态计算。 它使用MapReduce框架集成了查询优化,数据库系统的概念以及高效的并行内存和核心算法。

Storm is a system for processing streaming data in real-time. It has the capability of high ingestion rate. It is very fast and processes over a million records per second per node on a cluster of modest size. It contains core components called spout and bolt.
Storm是用于实时处理流数据的系统。 它具有高摄取率的能力。 它非常快,并且在中等大小的群集上每个节点每秒处理超过一百万条记录。 它包含称为喷口和螺栓的核心组件。
Kafka is also a real-time streaming data architecture that provides real-time analytics. It is a public-subscribe messaging system that allows the exchange of data between applications. It is also called a distributed event log.
Kafka还是一种实时流数据架构,可提供实时分析。 它是一个公共订阅消息系统,允许在应用程序之间交换数据。 它也称为分布式事件日志。
内存中处理 (In-memory processing)

Ignite is a horizontally scalable, fault-tolerant distributed in-memory computing platform for building real-time applications that can process terabytes of data with in-memory speed. Ignite distribute and cache data across multiple servers in RAM to provide unprecedented processing speed and massive application scalability.
Ignite是一种水平可伸缩,容错的分布式内存计算平台,用于构建可以以内存速度处理数TB数据的实时应用程序。 Ignite在RAM中的多个服务器之间分配和缓存数据,以提供空前的处理速度和大规模的应用程序可伸缩性。

Spark is an analytics engine for large -scale data processing.It creates a Resilient Distributed Dataset(RDD) which helps it to process data fast. RRDs are fault tolerance collections of elements that can be distributed and processed in parallel across multiple nodes in a cluster.
Spark是用于大规模数据处理的分析引擎,它创建了弹性分布式数据集(RDD),可帮助其快速处理数据。 RRD是元素的容错集合,可以在群集中的多个节点之间并行分布和处理这些元素。
工作流程和计划程序 (Workflow and Schedulers)
Oozie is a workflow scheduler for Hadoop, it is used for managing Hadoop jobs in parallel. Its major components are workflow engine for creating Directed Acyclic Graphs(DAG) for workflow jobs and coordinator engine used for running workflow jobs.
Oozie是Hadoop的工作流调度程序,用于并行管理Hadoop作业。 它的主要组件是用于为工作流作业创建有向非循环图(DAG)的工作流引擎,以及用于运行工作流作业的协调器引擎。
Airflow is a workflow management platform, it is used to create, manage, and monitor workflow. It also uses a Directed Acyclic Graph(DAG).
Airflow是一个工作流管理平台,用于创建,管理和监视工作流。 它还使用有向无环图(DAG)。
资料撷取 (Data Ingestion)

Nifi is used for automating the movement of data between disparate data sources.
Nifi用于自动化不同数据源之间的数据移动。

Sqoop is used for transferring data between Hadoop systems and a relational database. It is a connector between Hadoop and legacy databases. http://new.skytekservices.com/sqoop
Sqoop用于在Hadoop系统和关系数据库之间传输数据。 它是Hadoop与旧数据库之间的连接器。 http://new.skytekservices.com/sqoop

Flume is used for data ingestion in HDFS, it is used to collect, aggregate and transport large amounts of streaming data to HDFS. https://flume.apache.org/
Flume用于HDFS中的数据摄取,它用于收集,聚集和传输大量流数据到HDFS。 https://flume.apache.org/
协调 (Coordination)

Zookeeper is used for coordinating and managing services in a distributed environment, it is used for tracking nodes.
Zookeeper用于在分布式环境中协调和管理服务,用于跟踪节点。
管理与监控 (Management and Monitoring)
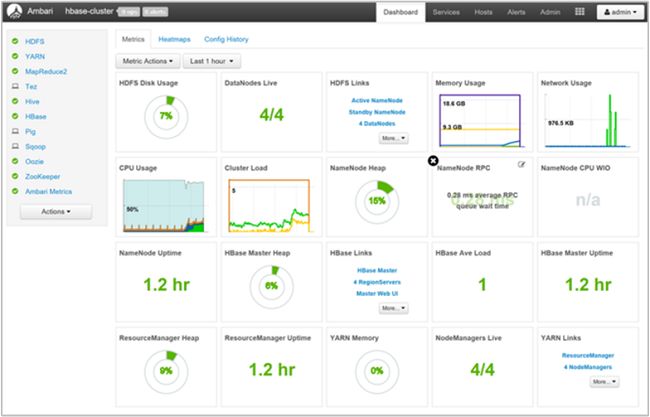
Ambari shows an overview of a cluster. It gives a visualization of what is running on the clusters, the resources used on the clusters, and a UI to execute queries.
安巴里 显示集群的概述。 它提供了集群上正在运行的内容,集群上使用的资源以及执行查询的UI的可视化。
机器学习 (Machine Learning)

Madlib used for scaling in database analytics, it is used to provide parallel implementation to run machine learning and deep learning workloads.
Madlib用于扩展数据库分析,它用于提供并行实施以运行机器学习和深度学习工作负载。
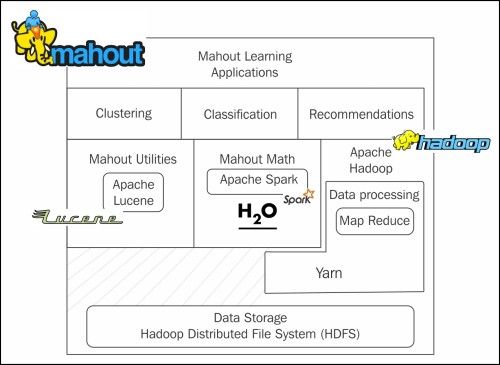
Mahout is a distributed linear algebra framework and mathematically expressive Scala DSL design to quickly implement algorithms. It integrates scalable machine learning algorithms to big data.
Mahout是一个分布式线性代数框架,具有数学表达能力的Scala DSL设计可快速实现算法。 它将可扩展的机器学习算法集成到大数据中。
Spark MLLiB solves the complexities surrounding distributed data used in machine learning. It simplifies the development and deployment of scalable machine learning pipelines
Spark MLLiB解决了机器学习中使用的分布式数据的复杂性。 它简化了可扩展机器学习管道的开发和部署
安全 (Security)

Ranger is used for monitoring and managing data security across Hadoop platforms. It provides a centralized security administration, access control, and detailed auditing for user access with Hadoop systems.
Ranger用于跨Hadoop平台监视和管理数据安全性。 它为Hadoop系统的用户访问提供了集中的安全管理,访问控制和详细的审核。
Phew, a lot of names, concepts, and technologies. I am positive you have been able to get an overview of the major components of Hadoop ecosystem. In the subsequent series, we will dive into the major components with real-life hands-on examples.
ew,很多名称,概念和技术。 我很肯定您已经获得Hadoop生态系统主要组件的概述。 在随后的系列中,我们将通过实际操作示例深入探讨主要组件。
Originally published at https://trojrobert.github.io on September 10, 2020.
最初于 2020年9月10日 发布在 https://trojrobert.github.io 。
翻译自: https://medium.com/@trojrobert/introduction-to-big-data-technologies-1-hadoop-core-components-9b184d80f87b
hadoop核心组件